执行本文之前,先搭建好spark的开发环境,我目前只搭建了standalone模式,参考链接 : Spark Standalone模式部署-CSDN博客
1. 安装sbt
1)下载sbt
网址:https://www.scala-sbt.org/download.html ,下载sbt-1.8.3.tgz。
2)将下载好的安装包拷贝到共享文件夹,
cd /mnt/hgfs/Ubuntu_share
3)解压到/usr/local
sudo tar -zxvf sbt-1.8.3.tgz -C /usr/local
4)修改权限
sudo chown -R wang:wang /usr/local/sbt
5)将bin目录下的sbt-launch.jar复制到sbt的安装目录下
cd /usr/local/sbt
sudo cp ./bin/sbt-launch.jar ./
6) 创建脚本/usr/local/sbt/sbt,添加如下内容:
sudo vim /usr/local/sbt/sbt
#!/bin/bash
SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M"
java $SBT_OPTS -jar `dirname $0`/sbt-launch.jar "$@"7) 修改权限
sudo chmod u+x /usr/local/sbt/sbt
8) 检验 sbt 是否可用
sudo ./sbt sbtVersion
出现如下画面,则sbt安装成功。
2. 编写scala应用程序
1)创建应用程序根目录
mkdir ~/sparkcode
cd ~/sparkcode/
mkdir -p ./src/main/scala
2)新建测试程序
cd src/main/scala/
vim SimpleApp.scala
输入如下内容,该程序计算 testspark.txt 文件中包含 "a" 的行数 和包含 "b" 的行数。
/* SimpleApp.scala */
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object SimpleApp {def main(args: Array[String]) {val logFile = "file:///usr/local/testspark.txt" // Should be some file on your systemval conf = new SparkConf().setAppName("Simple Application")val sc = new SparkContext(conf)val logData = sc.textFile(logFile, 2).cache()val numAs = logData.filter(line => line.contains("a")).count()val numBs = logData.filter(line => line.contains("b")).count()println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))}
}
3. 使用 sbt 打包 Scala 程序
1)新建文件simple.sbt
vim ~/sparkcode/simple.sbt
2)添加内容如下
name := "Simple Project"
version := "1.0"
scalaVersion := "2.12.17"
libraryDependencies += "org.apache.spark" %% "spark-core" % "3.3.0"3)将整个应用程序打包成 JAR:
sudo /usr/local/sbt/sbt package
出现如下内容,打包成功。

jar包路径:~/sparkcode/target/scala-2.12/simple-project_2.12-1.0.jar
4)通过 spark-submit 运行程序
/usr/local/spark-3.3.0-bin-hadoop3/bin/spark-submit --class "SimpleApp" ~/sparkcode/target/scala-2.12/simple-project_2.12-1.0.jar
/usr/local/spark-3.3.0-bin-hadoop3/bin/spark-submit --class "SimpleApp" ~/sparkcode/target/scala-2.12/simple-project_2.12-1.0.jar 2>&1 | grep "Lines with a:"第二条可以过滤信息,最终得到结果: ![]()
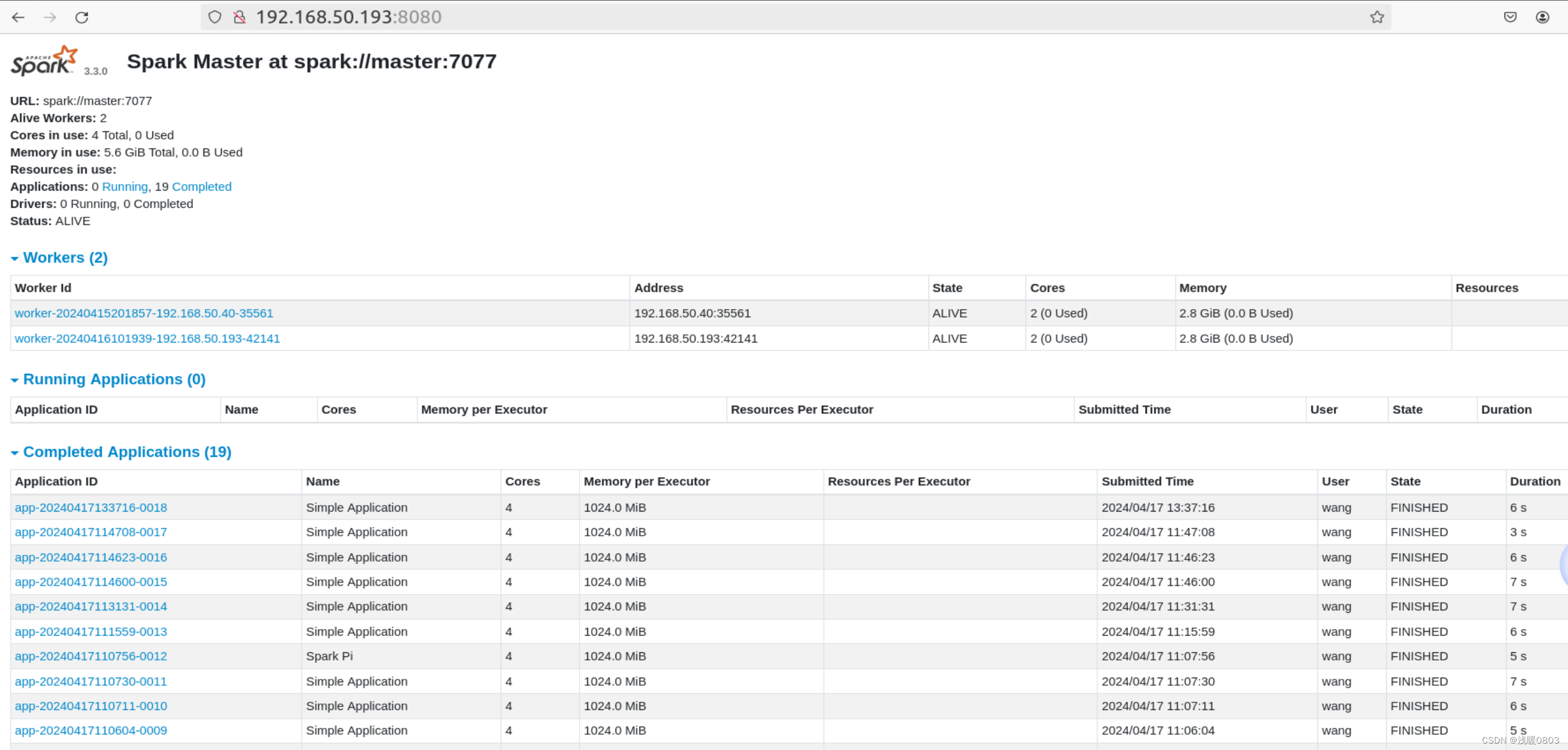
5)在浏览器中可查看运行状态
我运行了多次,故出现了很多个SimpleApp。
4. 遇到的问题
执行/usr/local/spark-3.3.0-bin-hadoop3/bin/spark-submit --class "SimpleApp" ~/sparkcode/target/scala-2.12/simple-project_2.12-1.0.jar
第一次执行成功了,在执行报了一堆错误,筛选了一下,主要是如下错误
Job aborted due to stage failure: Task 1 in stage 0.0 failed 4 times, most recent failure: Lost task 1.3 in stage 0.0 (TID 7) (192.168.50.40 executor 0): java.io.FileNotFoundException: File file:/usr/local/testspark.txt does not exist
这个文件在master中是存在的,192.168.50.40是slave1的地址,猜想应该是slave1缺少该文件,遂在slave1新建/usr/local/testspark.txt。
再次执行,错误变成下面
ResultStage 0 (count at SimpleApp.scala:11) failed in 3.144 s due to Job aborted due to stage failure: Task 1 in stage 0.0 failed 4 times, most recent failure: Lost task 1.3 in stage 0.0 (TID 4) (192.168.50.40 executor 0): java.io.EOFException: Cannot seek after EOF
百度查到应该是master和slave1的testspark.txt数据不一致引起的,于是将master的testspark.txt发送到slave1,再执行,成功。
以上问题虽然解决,但感觉这样必须所有节点都保存一份testsparl.txt,不应该是这么处理。参考文章spark读取不了本地文件_spark 无法读取读取本地文件-CSDN博客,决定将该文件上传到hdfs中
文章地址:上传文件到HDFS-CSDN博客
上传成功后更改SimpleApp.scala中的内容如下,

再次按上文流程,打包运行程序,成功。

文章参考:Spark安装和使用_厦大数据库实验室博客 (xmu.edu.cn)