本次课程由西北工业大学博士生、书生·浦源挑战赛冠军队伍队长、第一期书生·浦语大模型实战营优秀学员【安泓郡】讲解【OpenCompass 大模型评测实战】课程
课程视频:https://www.bilibili.com/video/BV1tr421x75B/
课程文档:https://github.com/InternLM/Tutorial/blob/camp2/lmdeploy/README.md


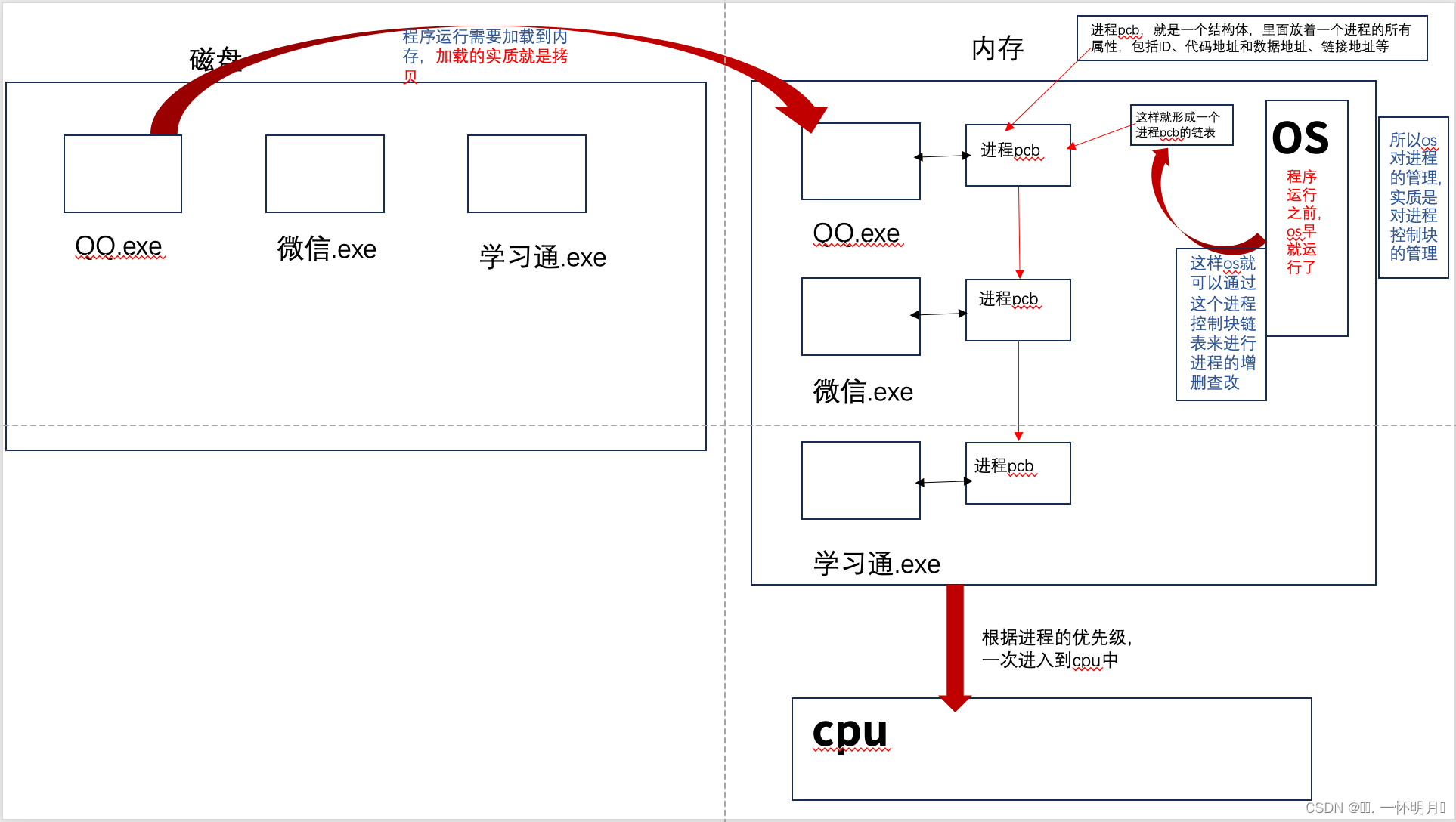
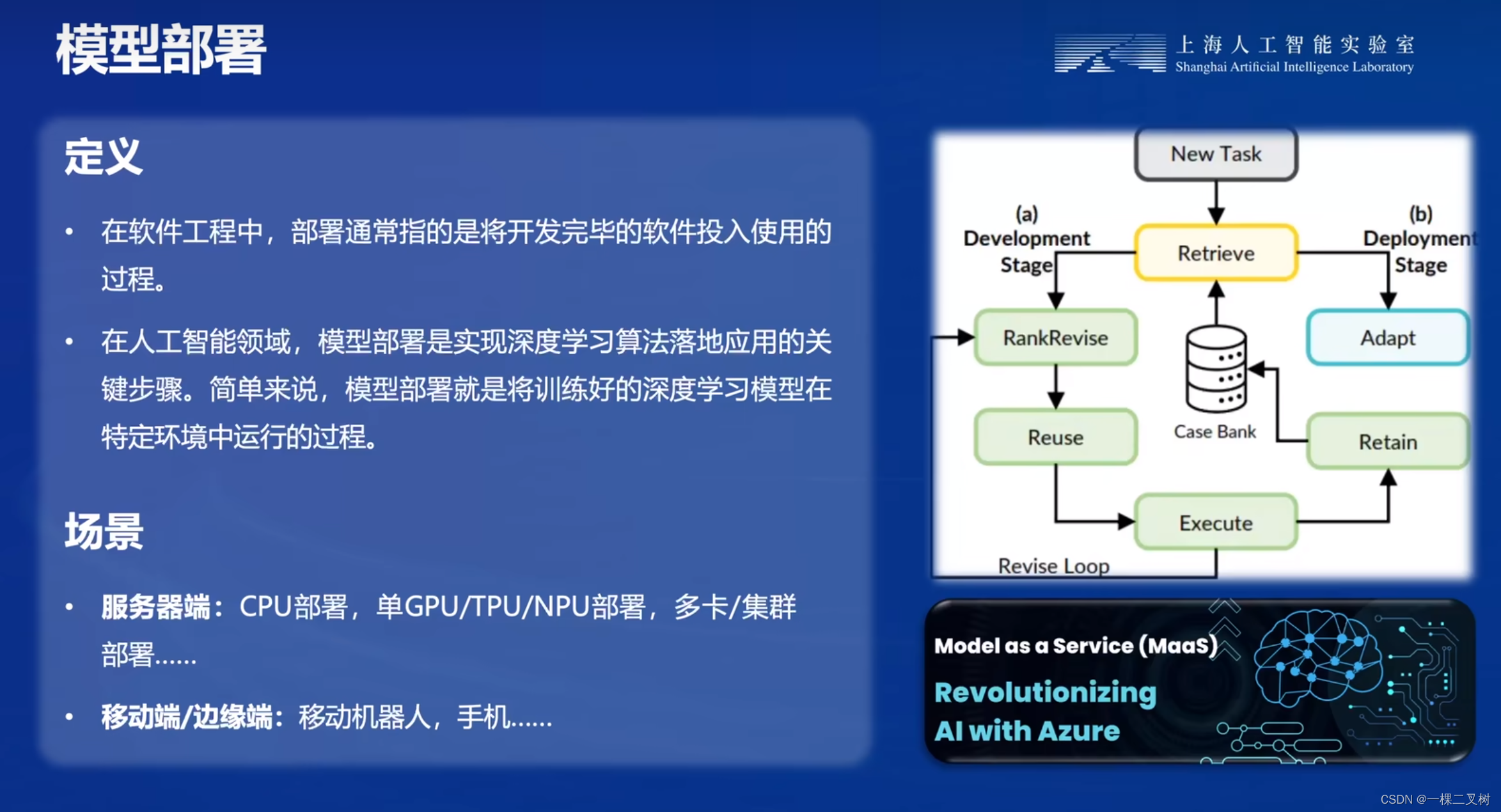
模型部署
- 在软件工程中,部署通常指的是将开发完毕的软件投入使用的过程。
- 在人工智能领域,模型部署是实现深度学习算法落地应用的关键步骤。简单来说,模型部署就是将训练好的深度学习模型在特定环境中运行的过程。
 大模型部署挑战一:计算量巨大
大模型部署挑战一:计算量巨大

大模型部署挑战二:内存开销巨大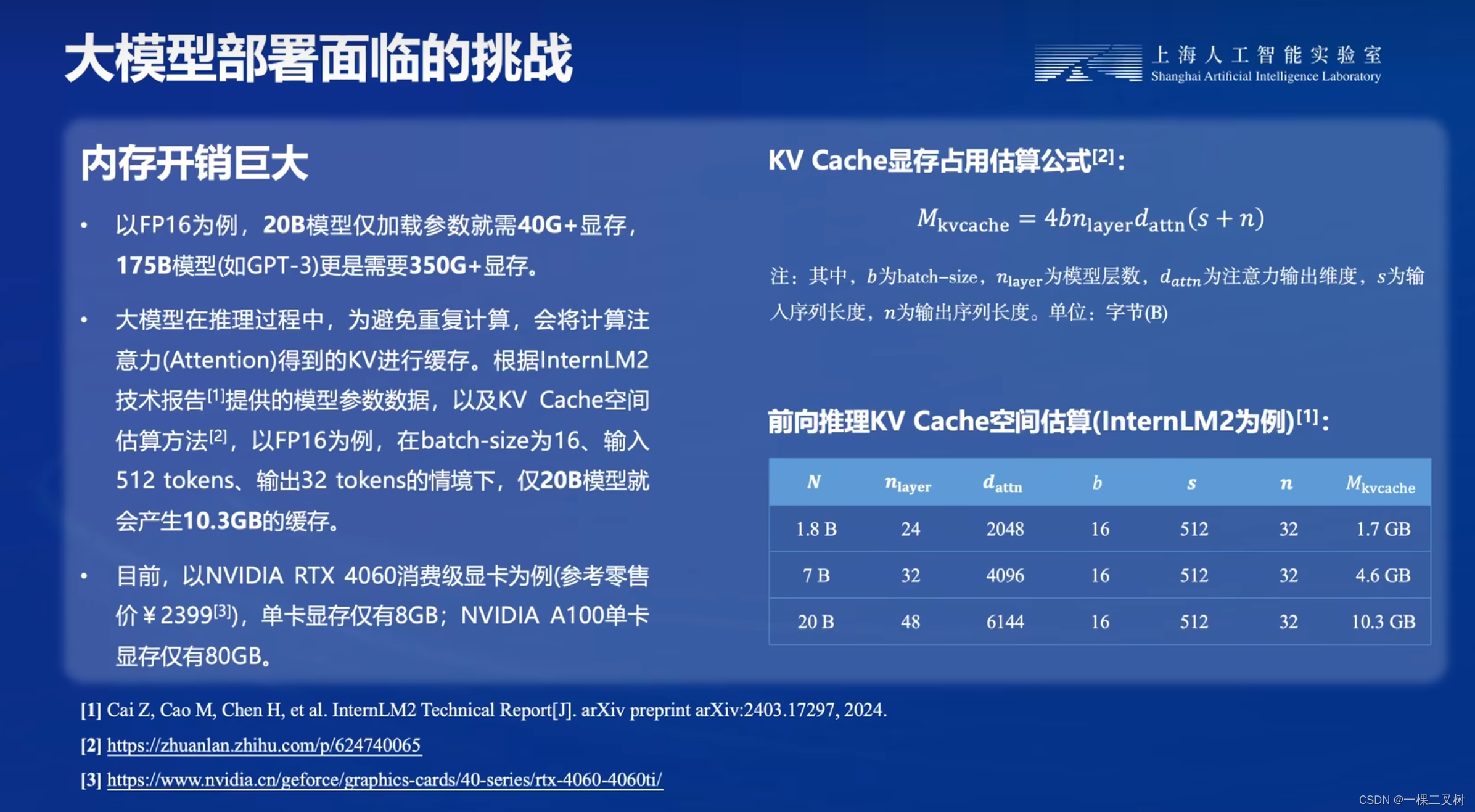
大模型部署挑战三:访存瓶颈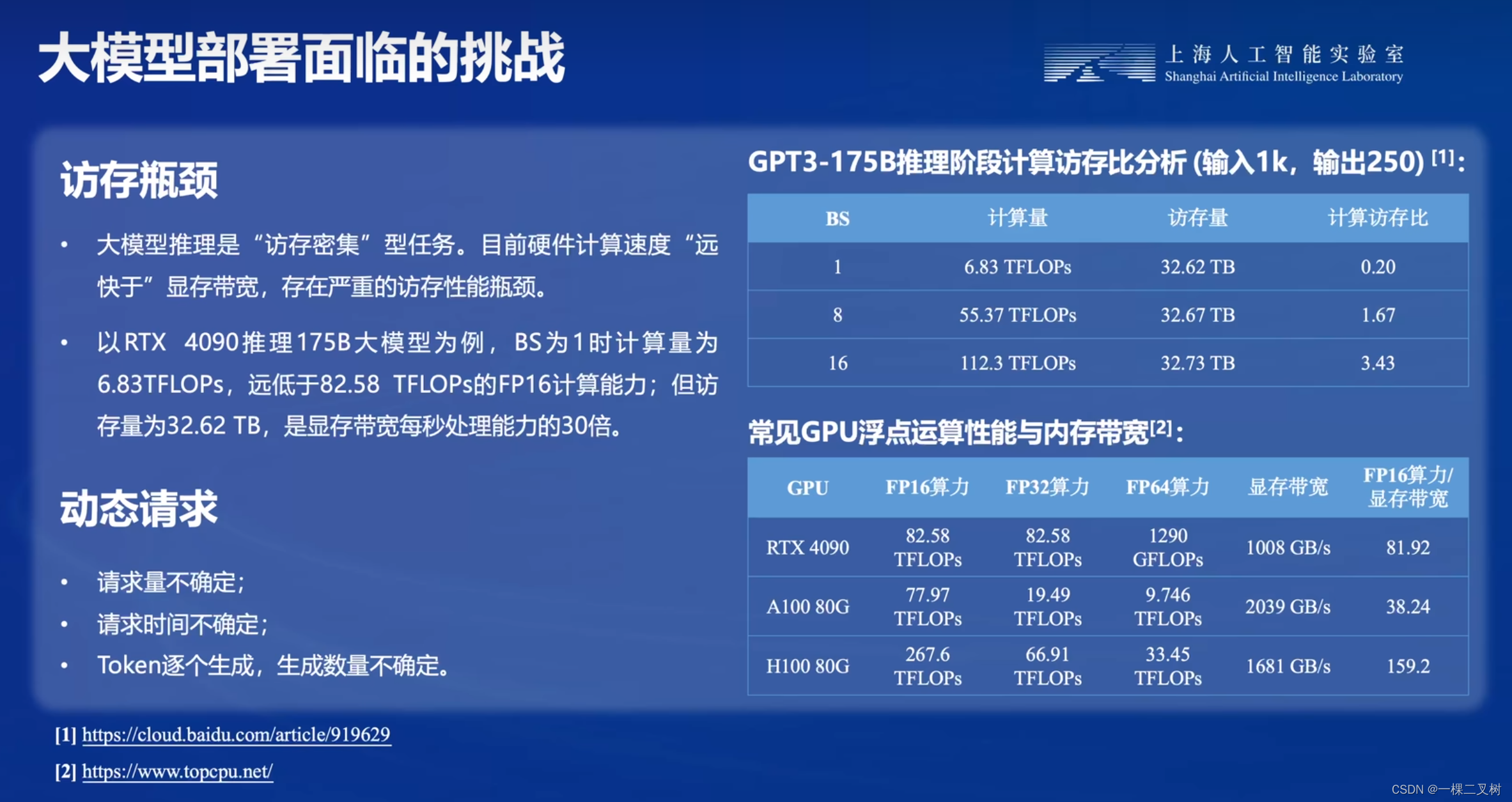

大模型部署方法:
- 模型剪枝:剪枝指移除模型中不必要或多余的组件,比如参数,以使模型更加高效。通过对模型中贡献有限的兄余参数进行剪枝,在保证性能最低下降的同时,可以减小存储需求、提高计算效率。
- 知识蒸馏: 知识蒸馏是一种经典的模型压缩方法,核心思想是通过引导轻量化的学生模型“模仿”性能更好、结构更复杂的教师模型,在不改变学生模型结构的情况下提高其性能。
- 量化:量化技术将传统的表示方法中的浮点数转换为整数或其他离散形式,以减轻深度学习模型的存储和计算负担。




LMDeploy简介:
LMDeploy 由 MMDeploy 和 MMRazor 团队联合开发是涵盖了 LLM 任务的全套轻量化、部署和服务解决方案。核心功能包括高效推理、可靠量化、便捷服务和有状态推理。
功点:
- 高效推理
- 可靠的量化
- 便捷的服务
- 有状态推理

核心功能:模型高效推理、模型量化压缩、服务化部署

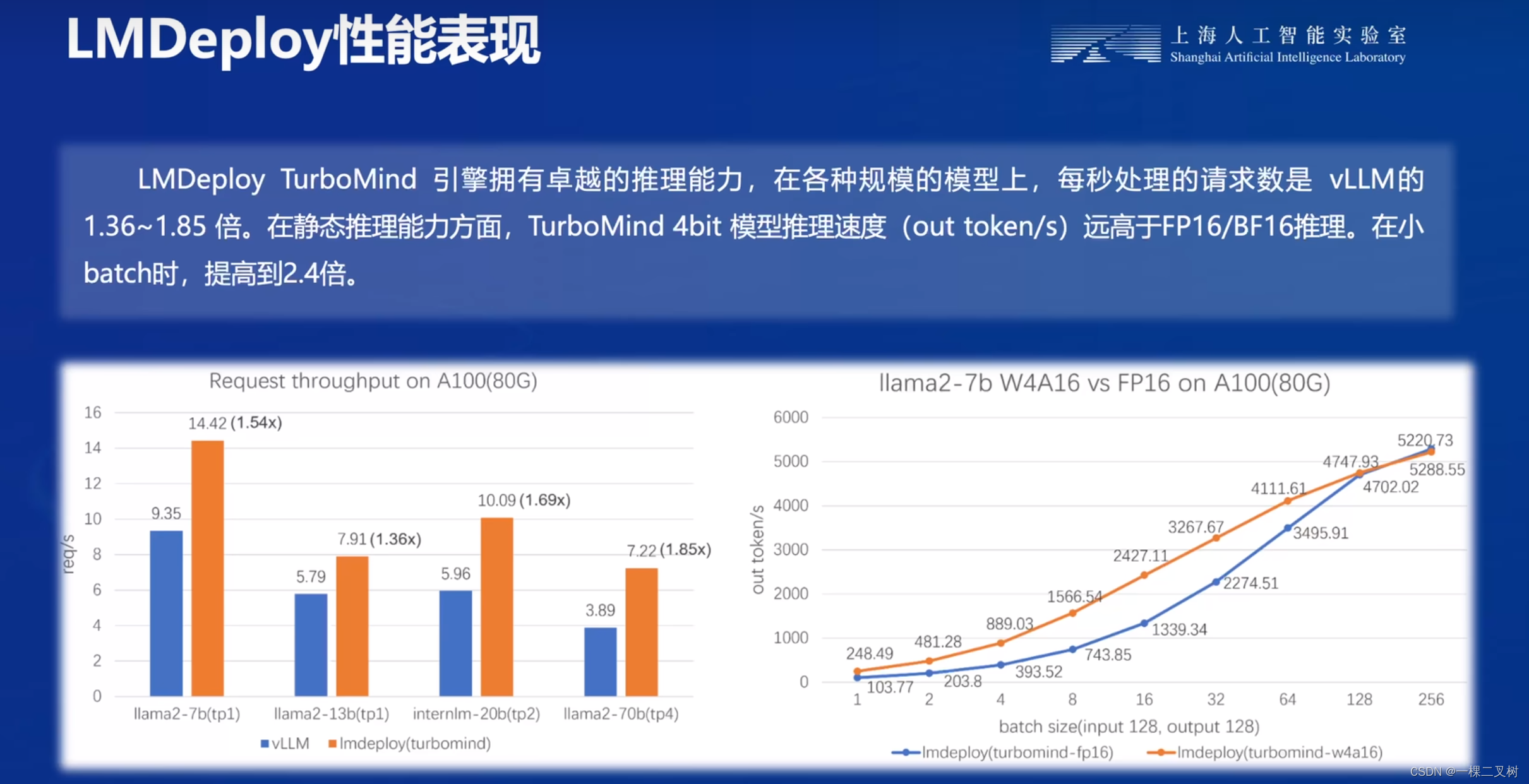
LMDeploy性能表现:
LMDeploy TurboMind 引擎拥有卓越的推理能力,在各种规模的模型上,每秒处理的请求数是 vLLM的1.36~1.85 倍。在静态推理能力方面,TurboMind 4bit 模型推理速度(out token/s)远高于FP16/BF16推理。在小batch时,提高到2.4倍。



动手实践部分见:LMDeploy量化部署LLM&VLM实践-作业五

![[Java EE] 多线程(四):线程安全问题(下)](https://img-blog.csdnimg.cn/direct/12d6660fd251483898dba6ebb23a7a0e.png)