一、背景
业务反馈客服消息列表查询速度慢,有时候甚至要差不多20秒,急需优化提升速度。
二、方案
引入
首先,体验系统,发现查询慢的正是消息列表查询接口。
接着去看代码的设计,流程比较长,但从代码逻辑上设计没有问题什么大问题。
接着拿到查库的主SQL,发现连接的表比较多,然后在测试库看索引,索引缺了一些。加上索引,然后确定确实走了预期的索引之后就给正式库加上了索引。速度确实有了较大提升。能够进入十秒内,但因为数据量大,还是需要4~5秒左右。
不过,业务对这个已经比较满意了,但还是提出能否速度更快。优化完索引之后,可以试试上缓存,但细看了一下数据,变化频率不低,不太适合缓存。
接着就想到了本文的主角-----Elastic Search。支持高性能检索,倒排索引的机制,也更适合大数据量的场景。于是就以测试库来尝试,做引入ES的探索。
选型
ES和数据库作为不同的系统,要查询效果一致,首先就要考虑数据的同步问题。
首先对于数据库已有的数据,做全量同步。这个是没有异议的。
但对于增量数据如何处理就引出了几种常用的方案。
方案一
数据库更新的时候,直接同步更新ES。这种方式实现简单,数据同步也及时,但每处更新数据库都要加上更新ES的操作,在后续开发中,很容易会遗漏。(某些时候可能需要用SQL改数据库数据,这种操作无法更新ES)
方案二
数据库更新的时候,就将更新的操作发送到MQ,让MQ异步去更新ES。这种方案相比第一种复用性更高,可维护性更强一些,但还是有缺漏的风险。(某些时候可能需要用SQL改数据库数据,这种操作无法更新ES)
方案三
监听数据库binlog日志,只要有变更记录的操作,就同步更新ES。这种方案实现起来较复杂,但基本写完一套之后,后续基本不需要再变动。
综合考虑下来,我觉得第三种方案是最好的。在之前的学习中,我尝试了给项目引入Easy ES框架来实现ES的引入。
springboot整合easy-es实现数据的增删改查_easy es-CSDN博客
接下来就差数据的全量同步和增量同步了。全量同步可以直接通过工具来实现,而增量同步就需要工具结合代码来实现了。本文就是打算用阿里的canal来实现监听MySQL数据库的binlog日志。
三、原理
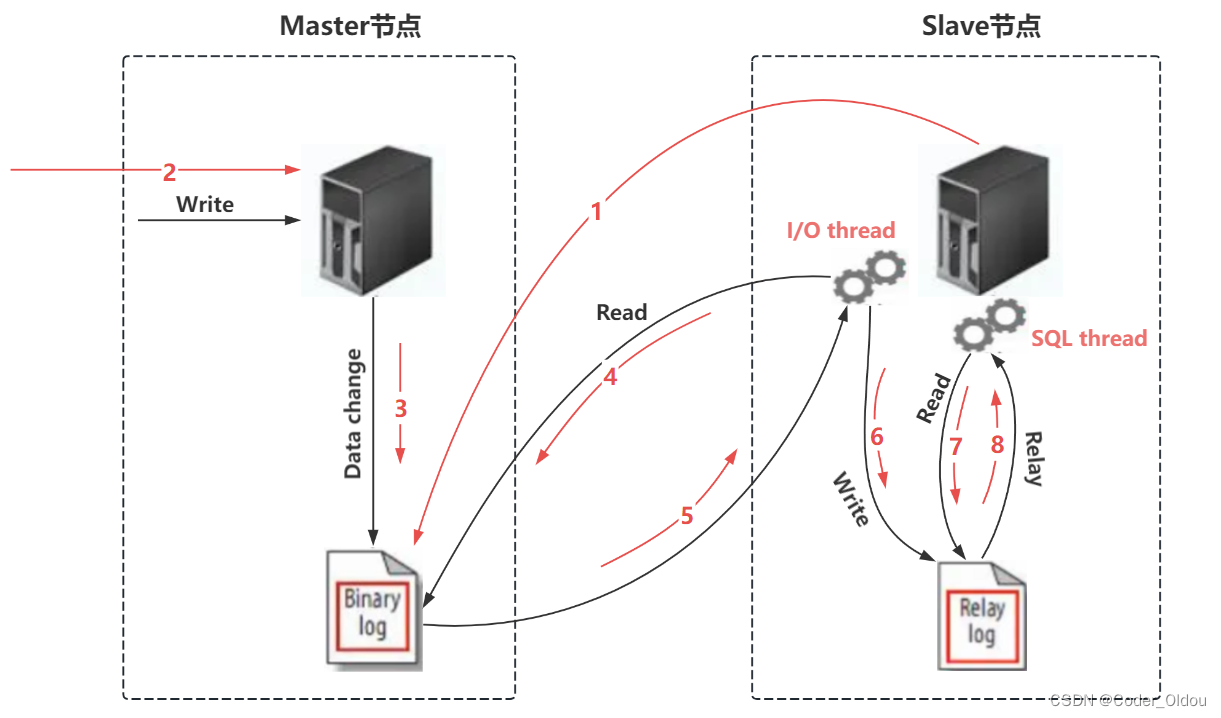
MySQL的分布式是基于主从架构实现的。一般情况下是一主多从,其中一个数据库作为主节点,其他数据库作为从节点,主从节点之间通过订阅binlog的方式实现数据同步。
canal的数据增量同步底层就是利用MySQL的主从同步机制实现的。将canal伪装成master的一个slave节点,向master节点发起dump协议,master节点在接收到dump协议之后,就会将binlog日志推送给canal,canal拿到binlog日志之后执行相应的操作从而实现数据同步。
四、配置流程
官方教程
4.1、配置MySQL
查看源MySQL的binlog配置,确保MySQL开启了binlog日志。
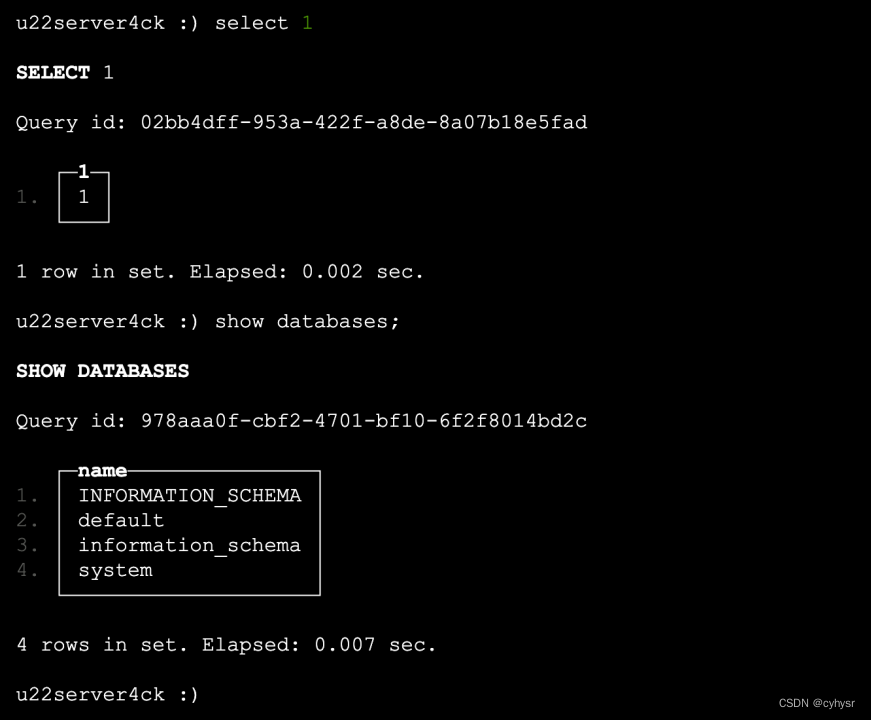
SHOW VARIABLES LIKE "%bin%"
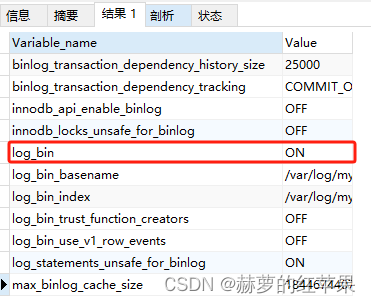
日志的格式为ROW
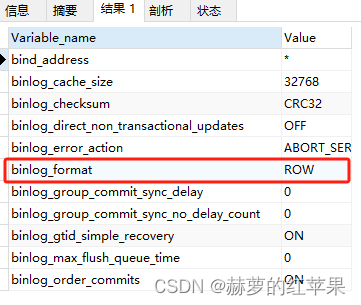
查看源MySQL的server_id
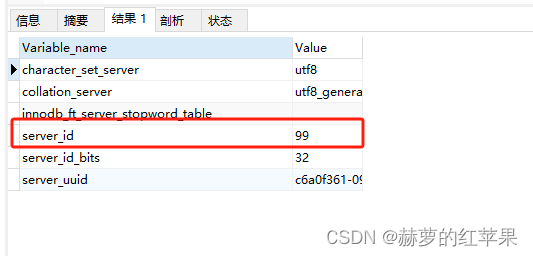
准备好一个拥有slave权限的MySQL账号。
4.2、配置canal
1.下载canal![]() https://github.com/alibaba/canal/releases
https://github.com/alibaba/canal/releases
2.解压,配置canal,修改文件conf/example/instance.properties
配置canal的server_id,注意要和上面查看的源MySQL的不一样。

配置源MySQL的ip+端口

配置源MySQL的账号密码

3.启动项目
在bin目录下找到对应系统的启动文件,双击启动。
/bin/startup.bat(window)
/bin/startup.sh(linux)
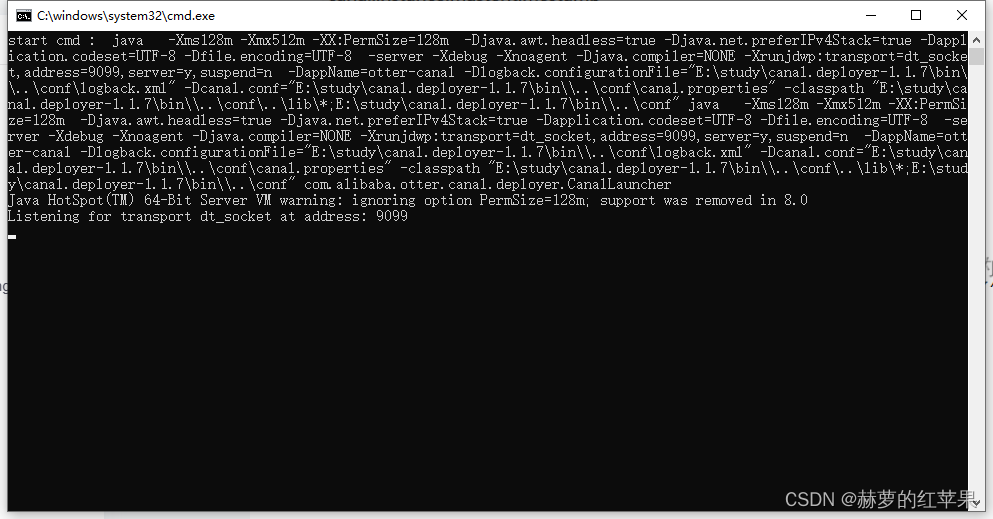
查看日志文件,检查是否启动成功。logs/canal/canal.log和logs/example/example.log
服务启动成功


4.3、canal集成到springboot
添加依赖
<dependency><groupId>com.alibaba.otter</groupId><artifactId>canal.client</artifactId><version>1.1.4</version></dependency>直接用官方的测试代码验证(不需要更改,如果canal安装在本地的话)
package org.jeecg.modules.admin.assignImClassTeacher;import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.common.utils.AddressUtils;
import com.alibaba.otter.canal.protocol.CanalEntry.*;
import com.alibaba.otter.canal.protocol.Message;import java.net.InetSocketAddress;
import java.util.List;public class SimpleCanalClientExample {public static void main(String args[]) {// 创建链接CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(AddressUtils.getHostIp(),11111), "example", "", "");int batchSize = 1000;int emptyCount = 0;try {connector.connect();connector.subscribe(".*\\..*");connector.rollback();int totalEmptyCount = 120;while (emptyCount < totalEmptyCount) {Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据long batchId = message.getId();int size = message.getEntries().size();if (batchId == -1 || size == 0) {emptyCount++;System.out.println("empty count : " + emptyCount);try {Thread.sleep(1000);} catch (InterruptedException e) {}} else {emptyCount = 0;// System.out.printf("message[batchId=%s,size=%s] \n", batchId, size);printEntry(message.getEntries());}connector.ack(batchId); // 提交确认// connector.rollback(batchId); // 处理失败, 回滚数据}System.out.println("empty too many times, exit");} finally {connector.disconnect();}}/*** 打印canal server解析binlog获得的实体类信息*/private static void printEntry(List<Entry> entrys) {for (Entry entry : entrys) {if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {//开启/关闭事务的实体类型,跳过continue;}//RowChange对象,包含了一行数据变化的所有特征//比如isDdl 是否是ddl变更操作 sql 具体的ddl sql beforeColumns afterColumns 变更前后的数据字段等等RowChange rowChage;try {rowChage = RowChange.parseFrom(entry.getStoreValue());} catch (Exception e) {throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(), e);}//获取操作类型:insert/update/delete类型EventType eventType = rowChage.getEventType();//打印Header信息System.out.println(String.format("================》; binlog[%s:%s] , name[%s,%s] , eventType : %s",entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),eventType));//判断是否是DDL语句if (rowChage.getIsDdl()) {System.out.println("================》;isDdl: true,sql:" + rowChage.getSql());}//获取RowChange对象里的每一行数据,打印出来for (RowData rowData : rowChage.getRowDatasList()) {//如果是删除语句if (eventType == EventType.DELETE) {printColumn(rowData.getBeforeColumnsList());//如果是新增语句} else if (eventType == EventType.INSERT) {printColumn(rowData.getAfterColumnsList());//如果是更新的语句} else {//变更前的数据System.out.println("------->; before");printColumn(rowData.getBeforeColumnsList());//变更后的数据System.out.println("------->; after");printColumn(rowData.getAfterColumnsList());}}}}private static void printColumn(List<Column> columns) {for (Column column : columns) {System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());}}}
运行main方法
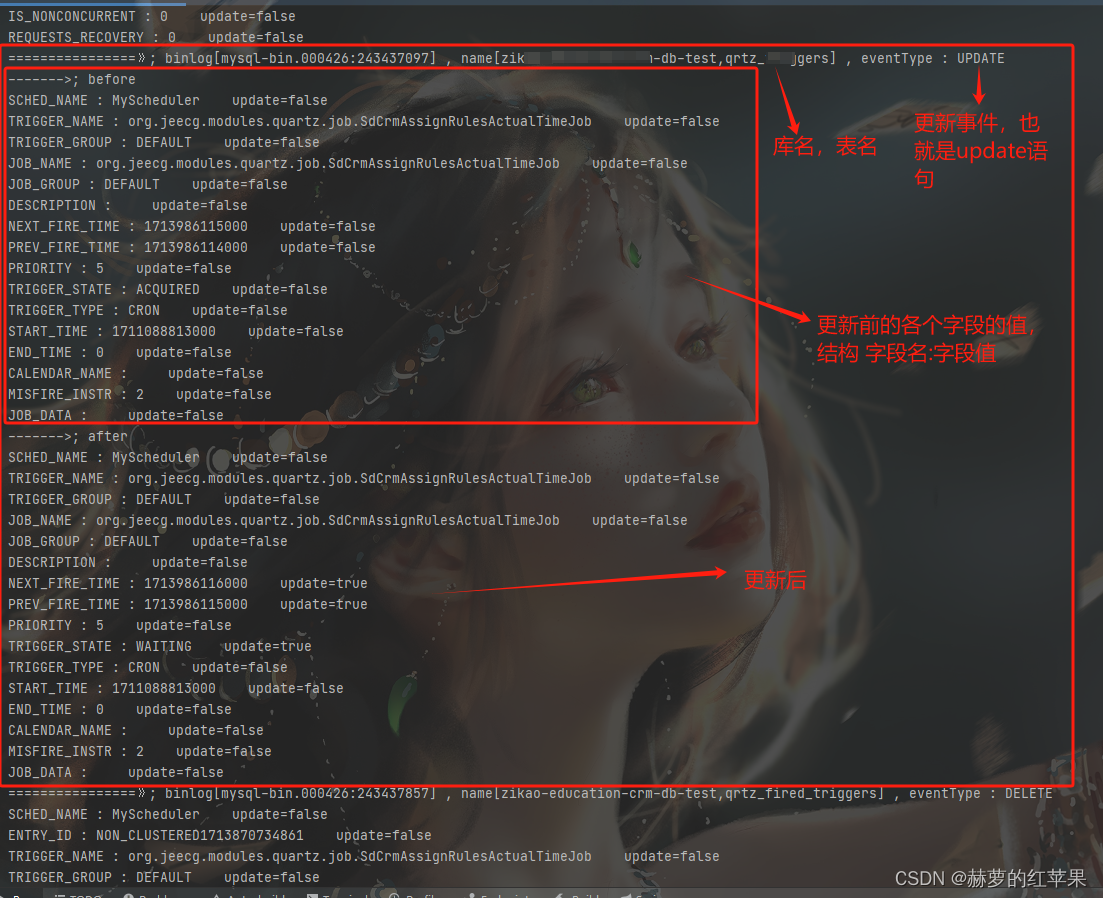
在更新后,每个字段都有一个update字段,如果值为true代表这个字段更新了,为false代表没更新。
拿到这些涉及数据库变更的事件之后,就可以根据需要去做数据的增量同步了。