引言:什么是Spring框架与循环依赖?
在Spring框架中,循环依赖是指两个或多个bean相互依赖对方以完成自己的初始化。这种依赖关系形成了一个闭环,导致无法顺利完成依赖注入。比如,如果Bean A在其构造函数中需要Bean B,而Bean B同样在其构造函数中需要Bean A,Spring容器在初始化这两个Bean时就会陷入困境,因为它无法确定应该先初始化哪一个Bean。
循环依赖不仅会导致应用程序启动失败,还可能导致运行时异常,因此理解并解决此问题对于保障Spring应用的健壮性至关重要。
循环依赖的常见表现和影响
在Spring中,如果A Bean依赖B Bean,而B Bean同时依赖A Bean,就形成了一个循环依赖。这种情况在使用构造函数注入时尤为明显,因为每个Bean在构造时就需要依赖的Bean完全实例化。
循环依赖不仅影响应用启动,还可能隐藏代码设计上的问题,比如过度耦合。例如,在一个电商应用中,订单管理(OrderManager)依赖库存服务(InventoryService),而库存服务又依赖订单管理来处理库存锁定,这种设计就可能引发循环依赖问题。
解决循环依赖的方法和技巧
构造函数注入 vs. Setter注入
- 构造函数注入:由于在构造函数注入时,需要在构造器调用前解析所有依赖,这种方法不支持循环依赖。
- Setter注入:通过Setter注入依赖,可以在对象创建之后,完成属性的赋值,从而支持循环依赖的解决。
以下是一个简单的Spring Boot应用示例,展示如何使用Setter注入来解决循环依赖:
@SpringBootApplication
public class CircularDependencyApplication {public static void main(String[] args) {SpringApplication.run(CircularDependencyApplication.class, args);}@Beanpublic ClassA classA() {return new ClassA();}@Beanpublic ClassB classB() {return new ClassB();}
}@Component
class ClassA {@Autowiredprivate ClassB classB;public void setClassB(ClassB classB) {this.classB = classB;}
}@Component
class ClassB {@Autowiredprivate ClassA classA;public void setClassA(ClassA classA) {this.classA = classA;}
}使用@Lazy注解
@Lazy注解延迟Bean的加载时机。例如,在其中一个Bean的依赖中加入@Lazy,Spring将在首次使用这个Bean时才创建和注入,从而打破循环依赖。
@Component
public class ClassA {private final ClassB classB;@Autowiredpublic ClassA(@Lazy ClassB classB) {this.classB = classB;}
}@Component
public class ClassB {private final ClassA classA;@Autowiredpublic ClassB(ClassA classA) {this.classA = classA;}
}三级缓存的概念及其原理
三级缓存是Spring用来解决循环依赖的一个机制。在Spring的bean生命周期中,容器通过使用三个缓存来管理bean的实例化过程,这些缓存分别是:
- 一级缓存(singletonObjects):存放完全初始化好的bean。
- 二级缓存(earlySingletonObjects):存放原始的bean实例(尚未填充属性)。
- 三级缓存(singletonFactories):存放用于生成bean的工厂对象。
当Spring容器创建一个bean时,它会首先检查一级缓存,如果没有找到,它将创建一个新的bean实例,并将一个工厂对象放入三级缓存中。这个工厂对象负责生成和配置bean。如果在bean的初始化过程中需要依赖另一个bean(比如B依赖A),Spring容器会再次走这个创建过程。
如果A也需要B来完成其初始化,此时B的实例化可能还未完成,但通过三级缓存中的工厂对象,可以提前暴露一个原始的B实例给A使用,从而避免死锁。一旦B初始化完成,它就会从三级缓存移动到二级缓存,最终到达一级缓存。
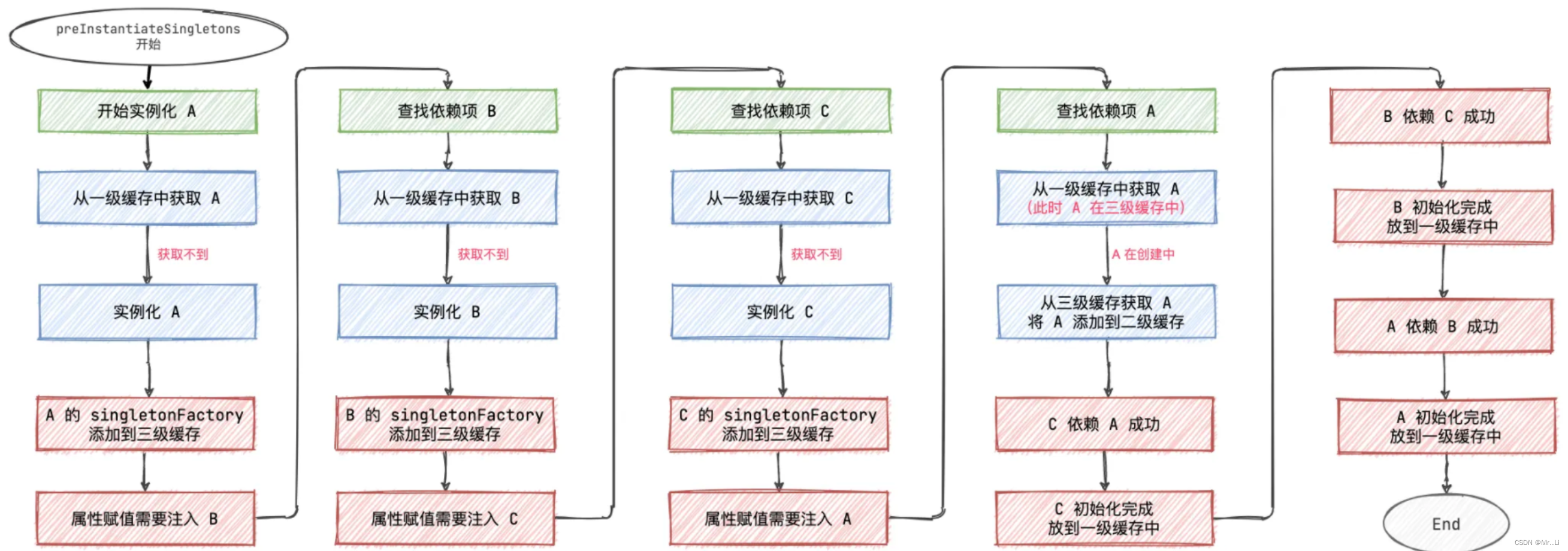
三级缓存创建Bean的详细过程
步骤 1: 创建 Bean A
- 当 Spring 容器开始创建 Bean A 时,首先检查 Bean A 是否已经存在于一级缓存中。如果不存在,Spring 容器开始创建 Bean A 的实例。
- 在 Bean A 的完整属性注入和初始化之前,Spring 容器将一个用于创建 Bean A 的工厂对象放入三级缓存中。
步骤 2: Bean A 需要 Bean B
- 在 Bean A 的初始化过程中,发现需要注入 Bean B。
- Spring 容器此时开始创建 Bean B。与创建 Bean A 的过程类似,Spring 首先检查一级缓存。如果 Bean B 也不存在,容器继续进行创建。
步骤 3: 创建 Bean B
- 在创建 Bean B 的过程中,容器同样将一个生成 Bean B 的工厂对象放入三级缓存中。
- 如果 Bean B 的初始化同样需要依赖 Bean A,此时 Bean A 尚未完全初始化完成,因此不能从一级缓存中获取。
步骤 4: 循环依赖检测与解决
- Bean B 在初始化过程中请求 Bean A。Spring 容器检查一级缓存未发现 Bean A,然后检查三级缓存。
- 从三级缓存中找到生成 Bean A 的工厂对象,通过这个工厂对象提前暴露一个还未完全初始化的 Bean A 的引用,并将这个早期引用移至二级缓存。
- Bean B 完成对 Bean A 的引用注入后,继续自己的初始化过程。一旦 Bean B 初始化完成,Bean B 的实例会被移至一级缓存,并从二级和三级缓存中清除。
步骤 5: 完成 Bean A 的初始化
- 一旦 Bean B 完全初始化并存放在一级缓存中,Spring 容器回到 Bean A 的初始化过程。此时 Bean A 可以解析其对 Bean B 的依赖,因为 Bean B 已经在一级缓存中可用。
- Bean A 完成所有依赖注入后,它的初始化也完成,然后它被移至一级缓存。
通过这种方式,Spring 的三级缓存机制有效地处理了循环依赖,允许两个互相依赖的 Bean 可以被正确地初始化和注入,避免了在依赖注入过程中发生的死锁或者缺失依赖的问题。这个机制是 Spring 容器高效处理复杂依赖关系的关键所在。下面提供一张示意图,帮助大家更好的理解三级缓存的初始化过程。
三级缓存的优势和适用场景
三级缓存提供了以下几个优势:
- 解决循环依赖:允许在bean的依赖中引用尚未完全初始化的bean。
- 提高灵活性:开发者可以设计更为复杂的bean依赖关系,不必过于担心初始化顺序。
- 增强稳定性:减少因循环依赖引起的应用启动失败。
结论与最佳实践
在使用三级缓存时,开发者应该遵循以下最佳实践:
- 避免不必要的依赖:尽管有三级缓存,也应尽量设计松耦合的系统。
- 使用接口隔离:通过接口而非直接依赖具体类来减少代码之间的直接依赖。
- 定期重构:随着应用的发展,应定期审视和重构代码,解决因历史原因形成的复杂依赖关系。