论文地址:https://arxiv.org/abs/2404.11202
代码地址:https://github.com/huawei-noah/Efficient-AI-Backbones
解决了什么问题?
对于边端设备,人们特别设计了一些精简的神经网络,这些网络推理速度更快、表现适中。MobileNetV1 提出了深度可分离卷积,降低了计算开支。MobileNetV2 使用了残差连接,MobileNetV3 通过神经结构搜索技术进一步优化了架构配置,提升了模型表现。GhostNet 利用特征的冗余性,通过一些低成本的操作复用部分特征通道。GhostNetV2 进一步融合了硬件友好的注意力模块,获取远距离像素之间的关系,效果优异。但是这些网络的训练策略仍借鉴于传统的模型,这就忽视了它们在模型性能上的差异,可能制约精简模型的表现。
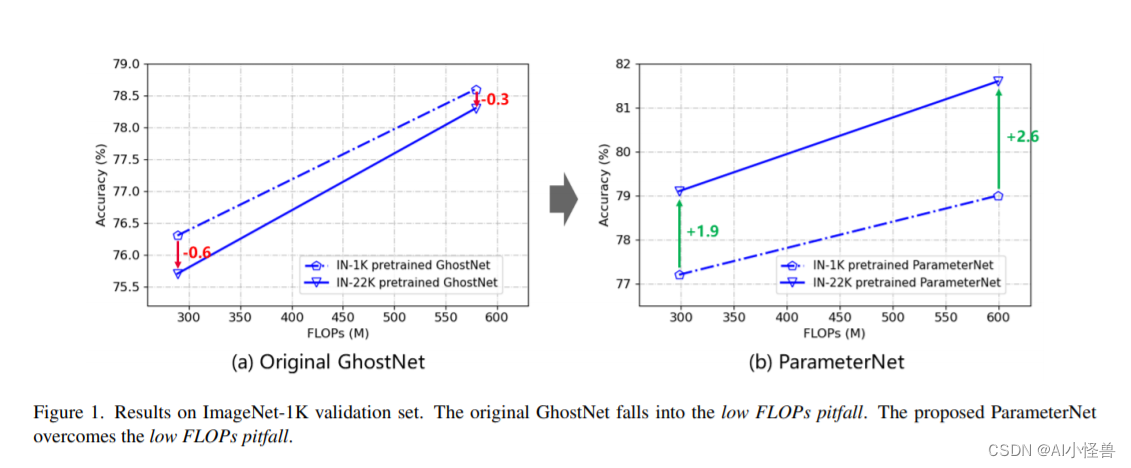
除了模型架构,适当的训练策略也至关重要。Wightman 等人通过优化器和数据增强方法将 ResNet-50 在 ImageNet-1K 的准确率从 76.1 % 76.1\% 76.1%提升到了 80.4 % 80.4\% 80.4%。但是,人们提出的训练策略很多是针对传统模型的,很少有针对精简模型的。不同性能的模型有不同的学习偏好。直接将传统模型的训练策略照搬在精简模型上是不恰当的。
重参数化
因为深度卷积和 1 × 1 1\times 1 1×1卷积的内存占用和计算量很小,经常用在精简模型架构。受到传统模型训练的启发,作者对这两个模块使用了重参数化,实现更好的表现。当训练精简模型时,作者在深度卷积和 1 × 1 1\times 1 1×1卷积中引入了线性平行的分支。训练完成后,对这些额外的分支做重参数化,推理时不会增加任何的开销。为了平衡整体的训练开销和表现增益,作者比较了不同数量分支的影响。此外,发现 1 × 1 1\times 1 1×1 深度卷积分支对 3 × 3 3\times 3 3×3 深度卷积的重参数化有正向作用。
知识蒸馏
由于模型能力有限,精简模型要想取得和传统模型一样的效果就很困难。知识蒸馏让一个更大的网络作为教师,指导精简模型的学习,能够提升表现。作者研究了对精简模型做知识蒸馏训练的几个因素,如教师模型的选取、超参数设定。结果表明,适当的教师模型能够极大地提升精简模型的表现。
学习策略和数据增强
作者比较了多个精简模型的训练策略,包括学习率、weight decay、指数滑动平均(EMA) 和数据增强。不是所有的策略都适合精简模型。例如,一些常用的数据增强方法如 Mixup 和 CutMix 会损害模型的表现。于是作者提出了适合精简模型训练的策略。
提出了什么方法?
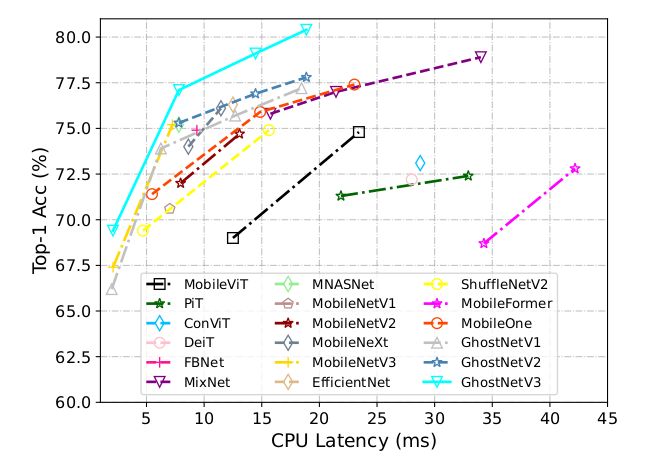
本文系统地研究了不同训练要素的影响,提出了一个适合精简模型的训练策略。作者在 ImageNet-1K 数据集上的实验证明,该策略适合用于不同的架构,包括 GhostNetV3、MobileNetV2 和 ShuffleNetV2。在移动设备上,GhostNetV3 1.3 × 1.3\times 1.3× 取得了 79.1 % 79.1\% 79.1% 的 top-1 准确率,计算量只有 269M FLOPs,延迟为 14.46 毫秒。
GhostNets 在移动设备上取得了 SOTA 表现,核心模块就是 Ghost 模块,通过低成本操作产生更多的特征图,从而替代原有的特征图。传统卷积的输出特征图 Y Y Y 是通过 Y = X ∗ W Y=X\ast W Y=X∗W 实现,其中 W ∈ R c o u t × c i n × k × k W\in \mathbb{R}^{c_{out}\times c_{in} \times k\times k} W∈Rcout×cin×k×k 是卷积核, X X X 是输入特征图。 c i n c_{in} cin 和 c o u t c_{out} cout 是输入和输出通道维度。 k k k 是卷积核大小, ∗ \ast ∗ 表示卷积操作。Ghost 模块通过两个步骤降低传统卷积的参数量和计算量。首先,输出 intrinsic 特征 Y ′ Y' Y′,通道数低于原有特征 Y Y Y。然后对 Y ′ Y' Y′ 使用低成本操作(如深度卷积),输出 ghost 特征 Y ′ ′ Y'' Y′′。最后,沿着通道维度 concat Y ′ Y' Y′ 和 ghost 特征得到最终的输出。表述如下:
Y ′ = X ∗ W p Y'=X \ast W_p Y′=X∗Wp
Y = C a t ( Y ′ , X ∗ W c ) Y=Cat(Y', X \ast W_c) Y=Cat(Y′,X∗Wc)
其中 W p W_p Wp 和 W c W_c Wc 表示原卷积和低成本卷积的参数。堆叠多个 Ghost 模块就得到了 GhostNet 模型。
GhostNetV2 通过一个高效的注意力模块(DFC 注意力)增强了精简模型。GhostNet 通常使用的小卷积核,如 1 × 1 1\times 1 1×1 和 3 × 3 3\times 3 3×3,从输入特征提取全局信息的能力比较弱。GhostNetV2 使用了一个全连接层来捕捉远距离空间信息,产生注意力图。为了计算效率,它将全局信息解耦为水平和垂直方向,沿着这两个方向融合像素。如下图所示,Ghost 模块和 DFC 注意力能高效地提取出全局和局部信息,很好地平衡了准确率和计算复杂度。
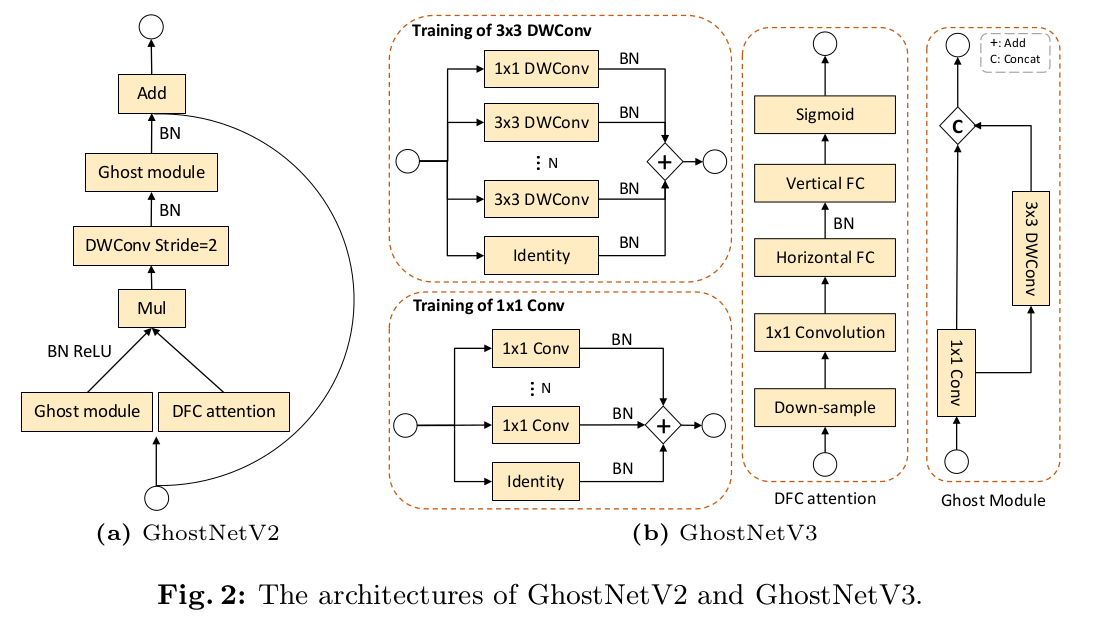
训练策略
目的在不改变推理时网络结构的前提下,研究如何保持模型的大小和速度的训练策略。作者研究了学习策略、数据增强、重参数化和知识蒸馏。
重参数化
重参数化在传统卷积上已经证明了其作用。作者在精简模型上增加重复的分支(带 BN 层),对精简模型做重参数化。GhostNetV3 重参数化设计请参考上图 b。作者在重参数 3 × 3 3\times 3 3×3 深度卷积中引入了一个 1 × 1 1\times 1 1×1 深度卷积分支。推理时,通过一个逆重参数化的过程,该重复分支可以被去掉。由于在推理时卷积和 BN 操作都是线性操作,它们可以组合成一个卷积层,权重矩阵记做 W ^ ∈ R c o u t × c i n × k × k \widehat{\bm{W}}\in \mathbb{R}^{c_{out}\times c_{in}\times k\times k} W ∈Rcout×cin×k×k,bias 记做 b ^ ∈ R c o u t \widehat{\bm{b}}\in \mathbb{R}^{c_{out}} b ∈Rcout。然后合在一起的权重和 biases 可以重参数化成 W ^ r e p = ∑ i W ^ i \widehat{\bm{W}}_{rep}=\sum_i \widehat{\bm{W}}_i W rep=∑iW i 和 bias b r e p = ∑ i b ^ i \bm{b}_{rep}=\sum_i \widehat{b}_i brep=∑ib i,其中 i i i表示第几个重复分支。
知识蒸馏
KD 是模型压缩的常用方法,大教师模型预测的结果作为小型学生模型的学习目标。给定一个样本 x x x和标签 y y y,用 Γ s ( x ) \Gamma_s(x) Γs(x)和 Γ t ( x ) \Gamma_t(x) Γt(x)分别表示学生和教师模型预测的 logits,KD 的整体损失表示如下:
L t o t a l = ( 1 − α ) L c e ( Γ s ( x ) , y ) + α L k d ( Γ s ( x ) , Γ t ( x ) ) \mathcal{L}_{total}=(1-\alpha)\mathcal{L}_{ce}(\Gamma_s(x),y) + \alpha \mathcal{L}_{kd}(\Gamma_s(x),\Gamma_t(x)) Ltotal=(1−α)Lce(Γs(x),y)+αLkd(Γs(x),Γt(x))
其中 L c e \mathcal{L}_{ce} Lce和 L k d \mathcal{L}_{kd} Lkd分别是交叉熵损失和 KD 损失。 α \alpha α是平衡参数。
通常 KD 损失使用 KL 散度函数表示,
L k d = τ 2 ⋅ KL ( softmax ( Γ s ( x ) ) / τ , softmax ( Γ t ( x ) ) / τ ) \mathcal{L}_{kd}=\tau^2 \cdot \text{KL}(\text{softmax}(\Gamma_s(x))/\tau, \text{softmax}(\Gamma_t(x))/\tau) Lkd=τ2⋅KL(softmax(Γs(x))/τ,softmax(Γt(x))/τ)
其中 τ \tau τ是 label smoothing 调节参数。
学习策略
学习率是模型优化的重要参数。通常有两种策略: s t e p step step 和 c o s i n e cosine cosine。 s t e p step step 策略线性地降低学习率,而 c o s i n e cosine cosine 则在开始时缓慢地降低学习率,在中期则几乎是线性地降低,在后期又变得缓慢。
EMA 是一个有效的提升测试准确率的方法,提升模型的鲁棒性。训练时,它逐渐地取模型参数的平均。假设 t t t步时模型的参数为 W t \bm{W}_t Wt,EMA 计算如下:
W ‾ t = β ⋅ W ‾ t − 1 + ( 1 − β ) ⋅ W ‾ t \overline{\bm{W}}_t=\beta \cdot \overline{\bm{W}}_{t-1} + (1-\beta)\cdot \overline{\bm{W}}_t Wt=β⋅Wt−1+(1−β)⋅Wt
W ‾ t \overline{\bm{W}}_t Wt表示第 t t t 步时 EMA 模型的参数, β \beta β 是个超参数。
数据增强
数据增强能够提升传统模型的表现。AutoAug 收入了 25 种增强子策略组合,每个都包含2个变换。对于每个输入图像,随机选择一个子策略组合。图像混叠方法如 Mixup 和 CutMix 融合两张图像,生成一个新图像。Mixup 将两张图像和标签组合,训练网络。CutMix 随机去除图像上的一块区域,然后替换为另一张图像的一个区域。RandomErasing 随机选择图像上的一个矩形区域,替换成随机像素值。