合集 ChatGPT 通过图形化的方式来理解 Transformer 架构
- 翻译: 什么是ChatGPT 通过图形化的方式来理解 Transformer 架构 深度学习一
- 翻译: 什么是ChatGPT 通过图形化的方式来理解 Transformer 架构 深度学习二
- 翻译: 什么是ChatGPT 通过图形化的方式来理解 Transformer 架构 深度学习三
- 翻译: 什么是ChatGPT 通过图形化的方式来理解 Transformer 架构 深度学习四
- 翻译: 什么是ChatGPT 通过图形化的方式来理解 Transformer 架构 深度学习五
- 翻译: 什么是ChatGPT 通过图形化的方式来理解 Transformer 架构 深度学习六

在本章的最后一课,我想更详细地讨论softmax函数,因为当我们探索注意力机制时,它会重新成为焦点。

如果你想要一串数字成为概率分布,
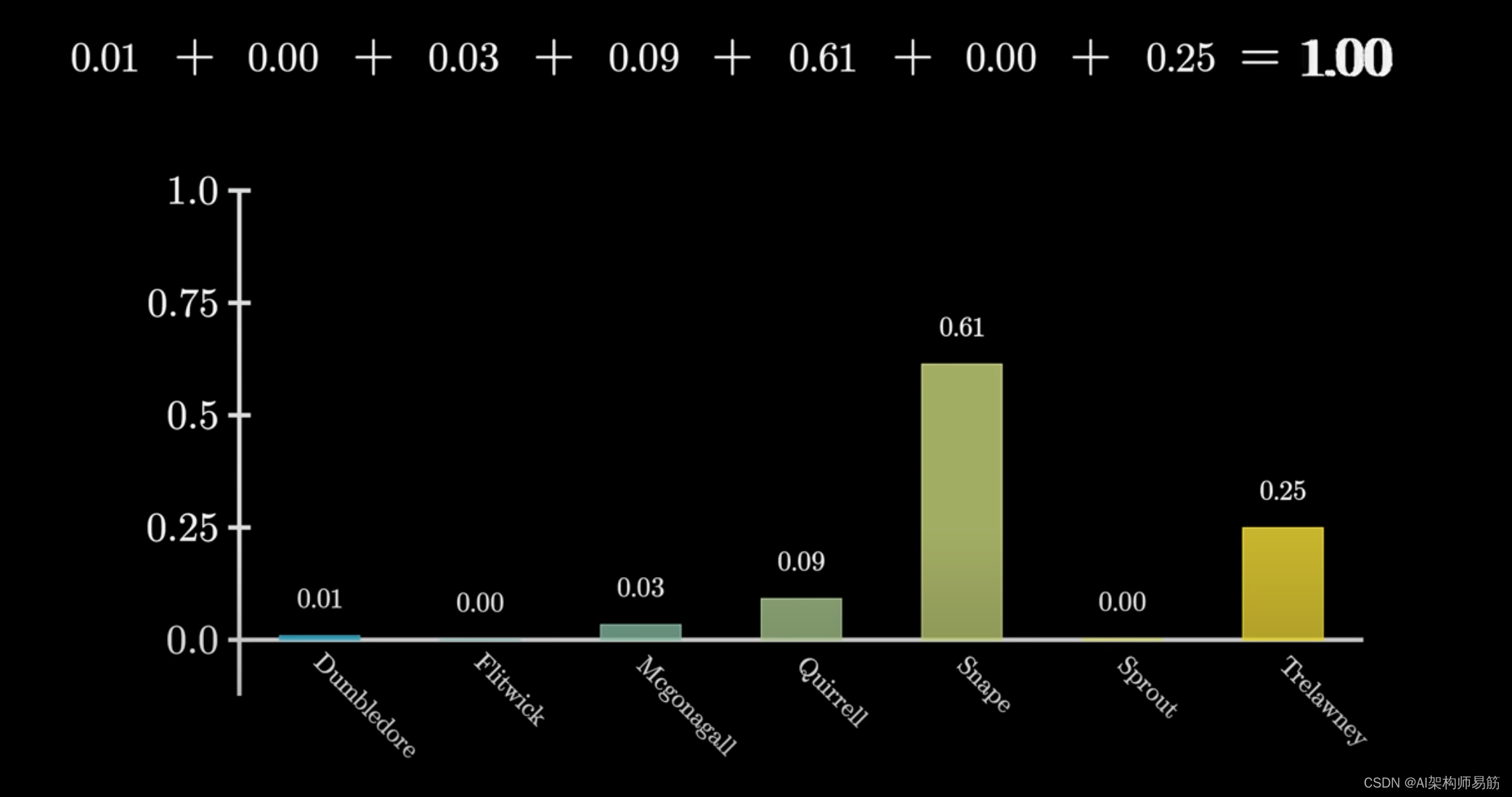
例如预测可能出现的下一个词的概率,那么这些数字中的每一个都必须在0和1之间,并且加起来等于1。
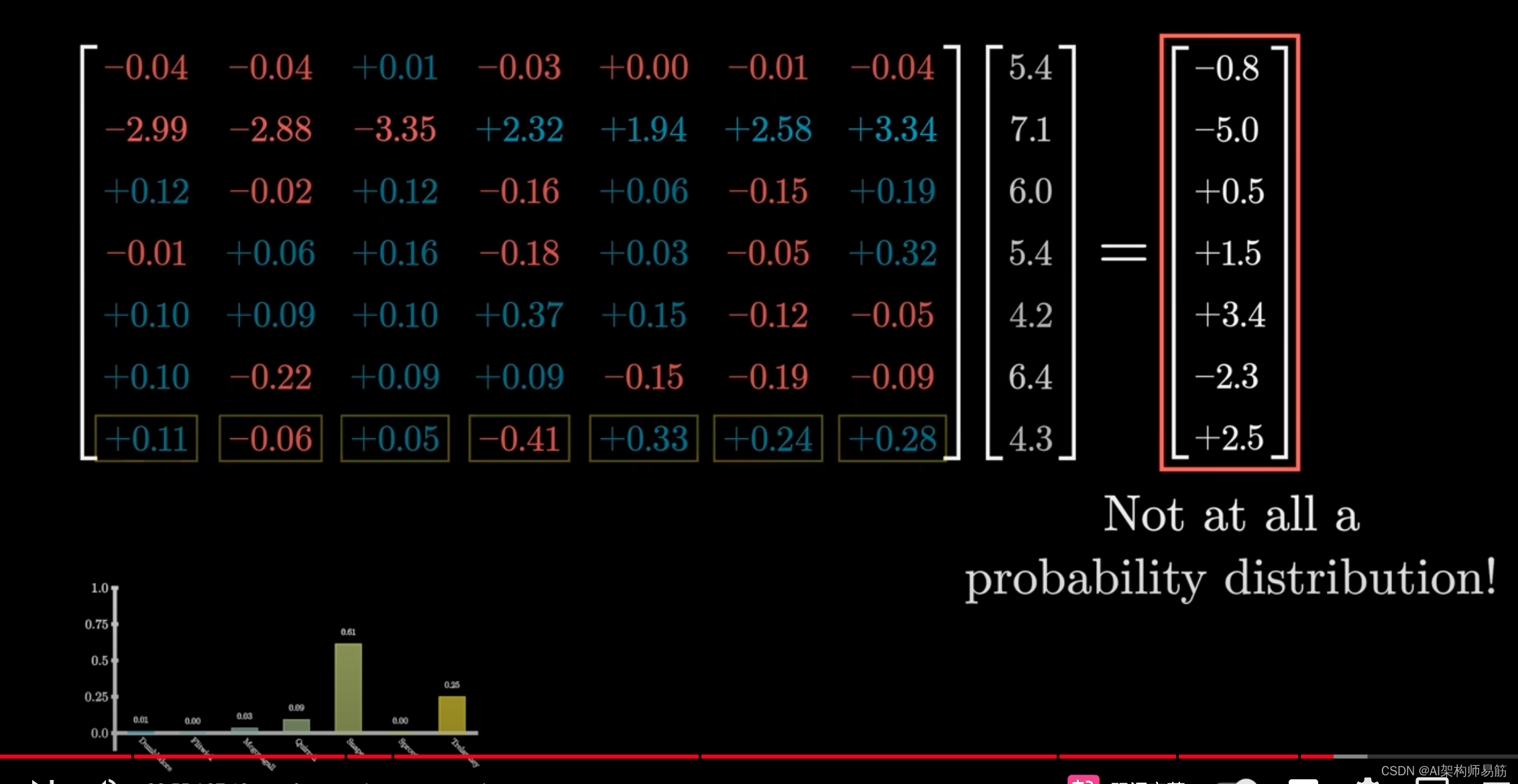
然而,如果你正在练习深度学习,而且你做的每一步可能看起来都像是矩阵和向量的乘法,那么你得到的结果可能不满足这个条件。

这些值可能是负数

或者远大于1,

加起来几乎肯定不等于1。
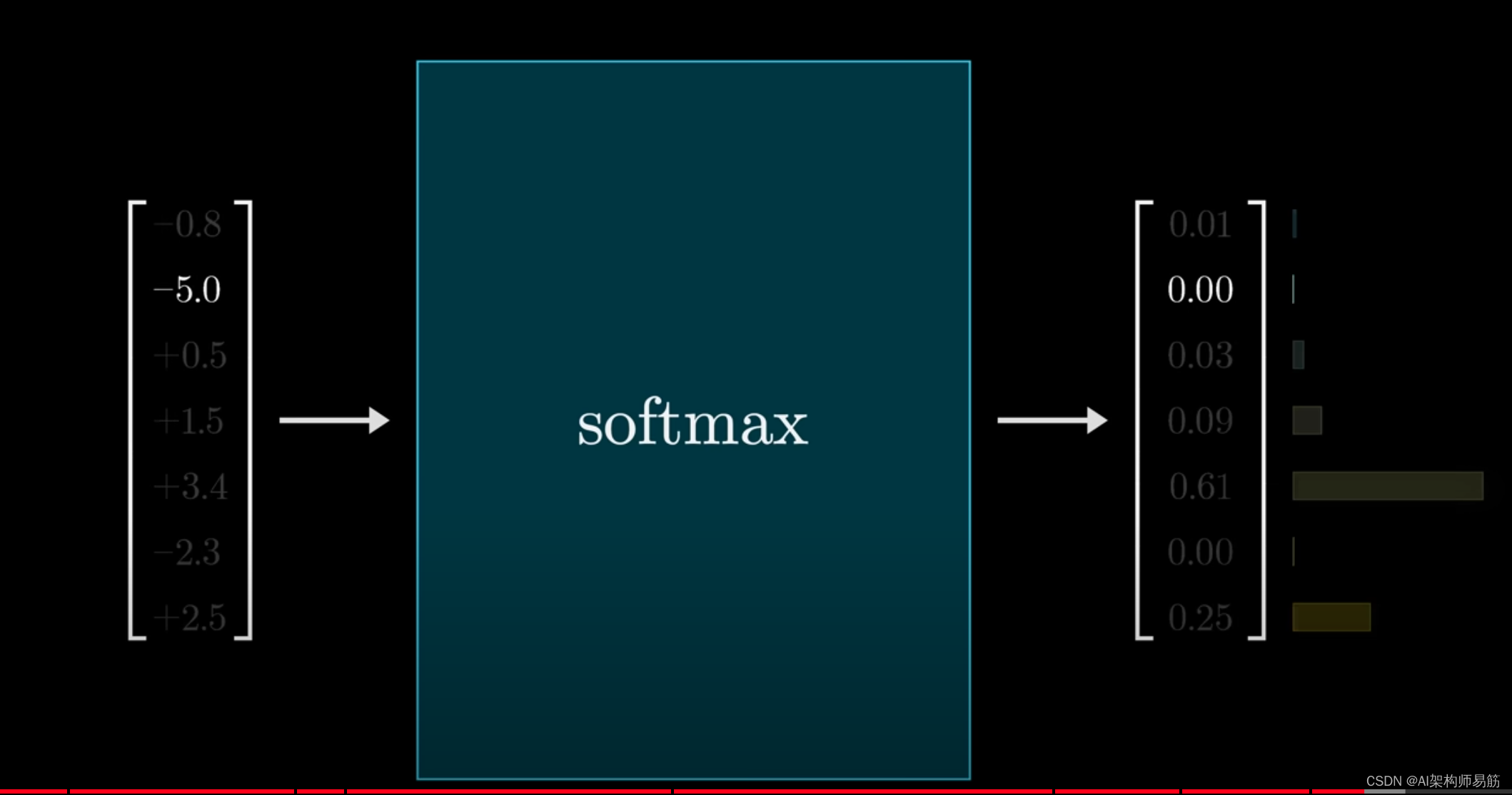
Softmax是一种标准方法,可以将任何一组数字转换为有效的分布,使得最大值非常接近1,较小的值非常接近0。
理解这一点就足够了。
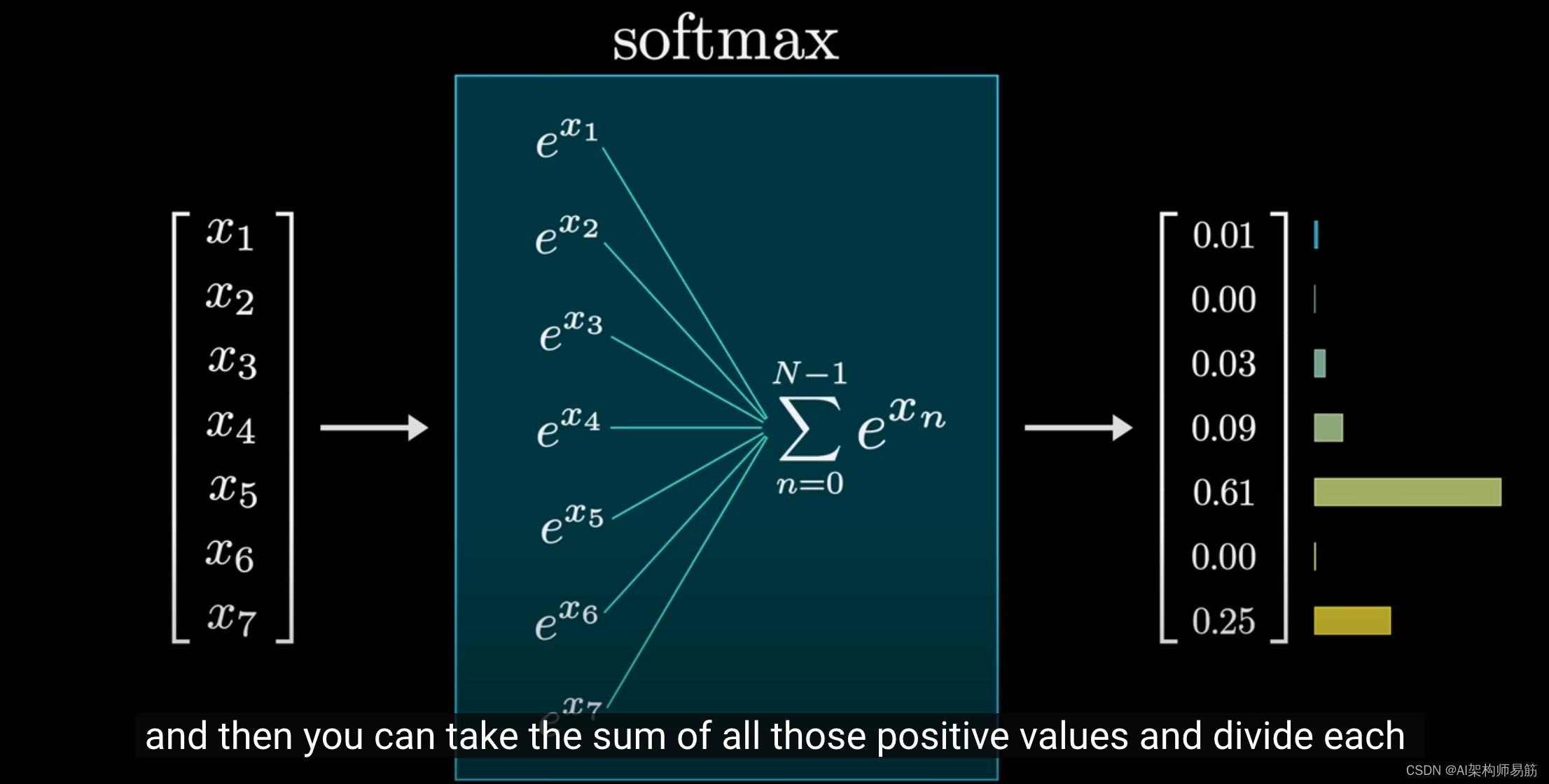
但如果你很好奇,这里是它的工作原理:首先对每个值做指数e运算,这样你就得到一组正数,然后你对所有正数求和,

并用这个和去除以每个数,这样你就把它们归一化为一个加起来等于1的列表。

你会注意到,如果输入中的一个值明显大于其他值,那么在输出中,与该值对应的项将主导分布,在采样时几乎肯定会选择最大的输入值。

但这种方法比直接选择最大值更加微妙,因为当其他值也接近最大值时,它们在整体分布中也会获得重要的权重,而且随着你改变输入,一切都在连续变化。
在某些情况下,例如当ChatGPT使用这个分布来生成下一个词时,
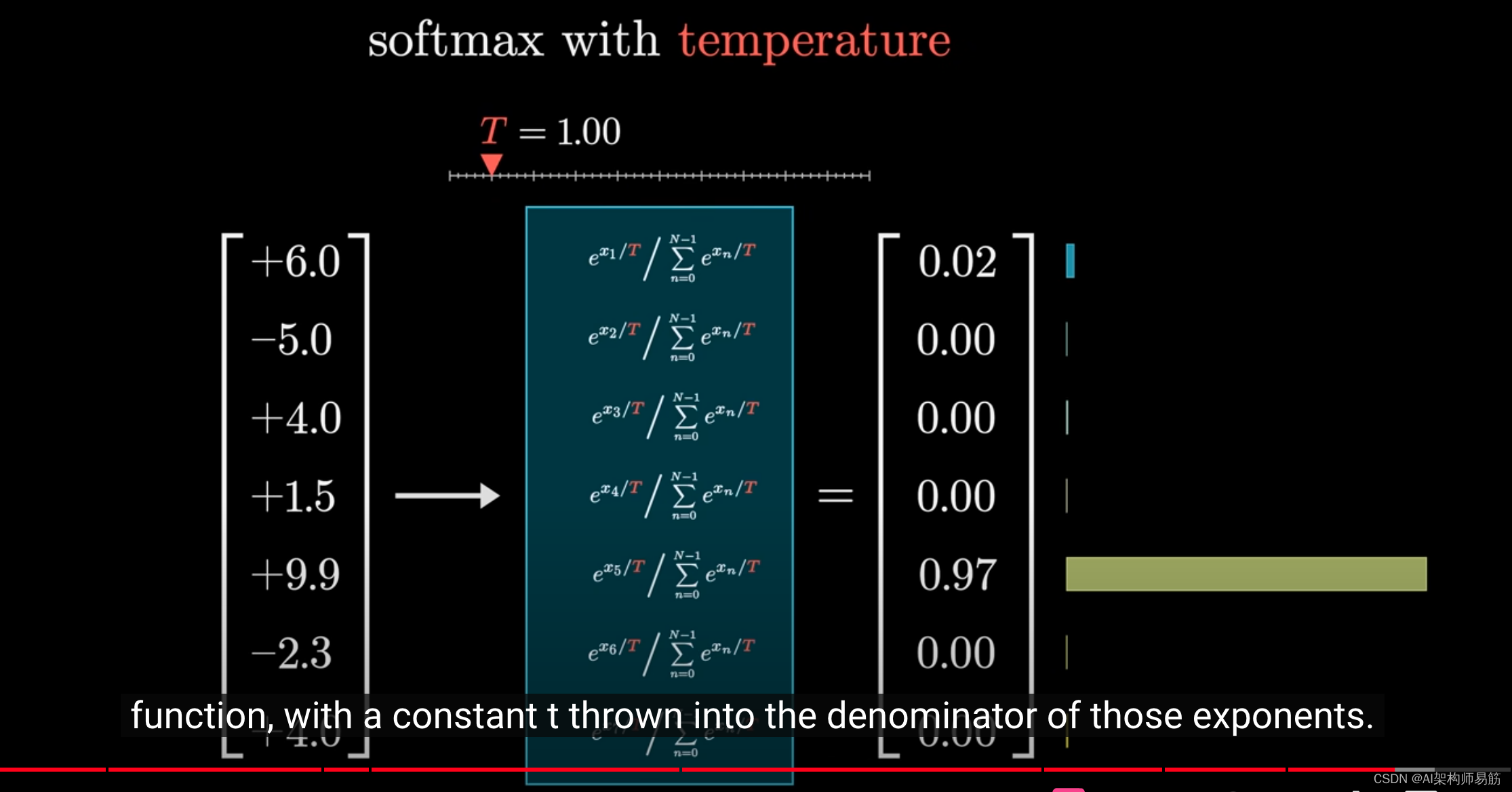
它可以通过在指数的分母中添加一个常数t来为函数增加一些趣味性。
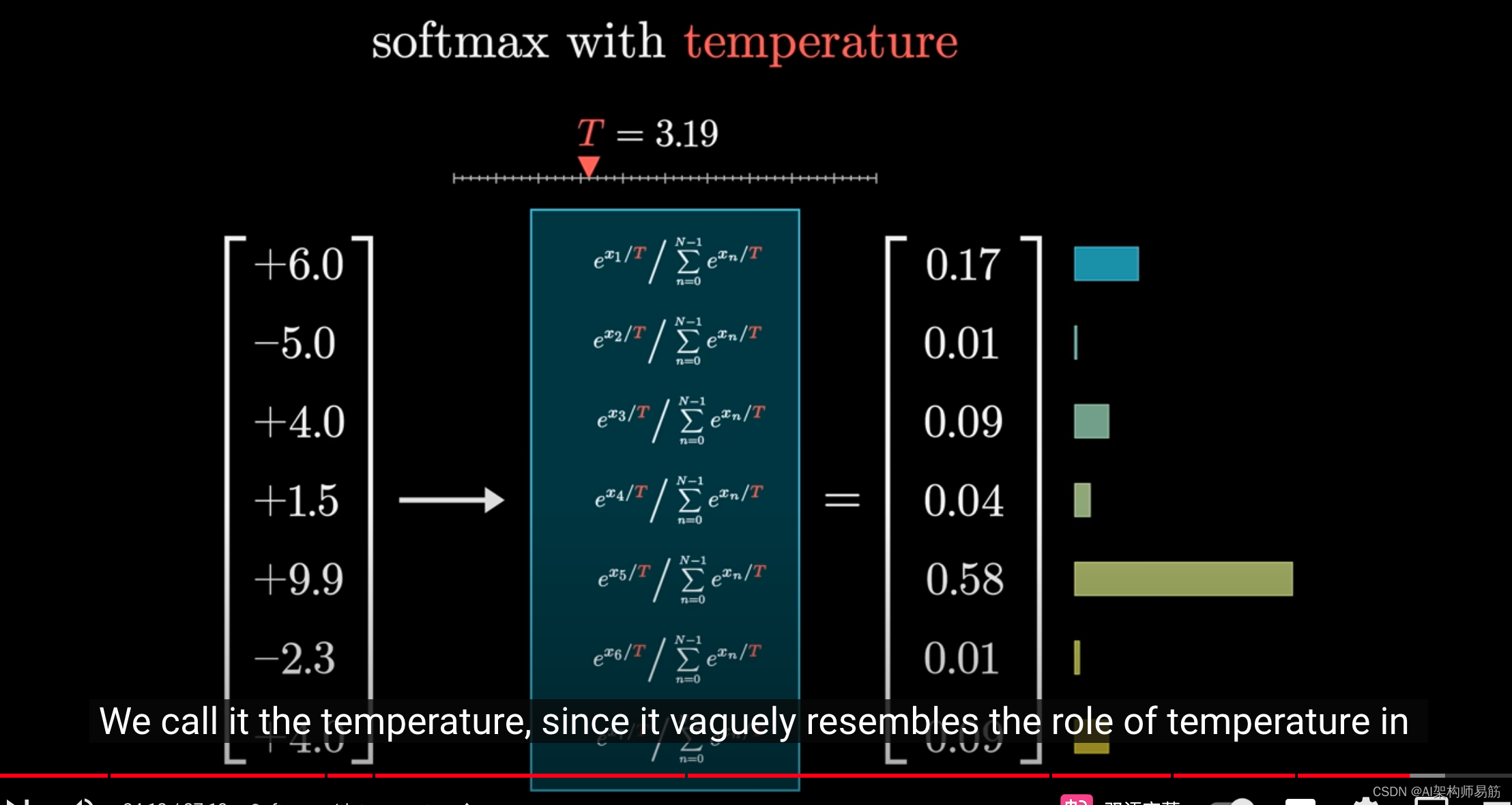
我们称之为"温度",因为它在某种程度上类似于热力学方程中温度的作用。
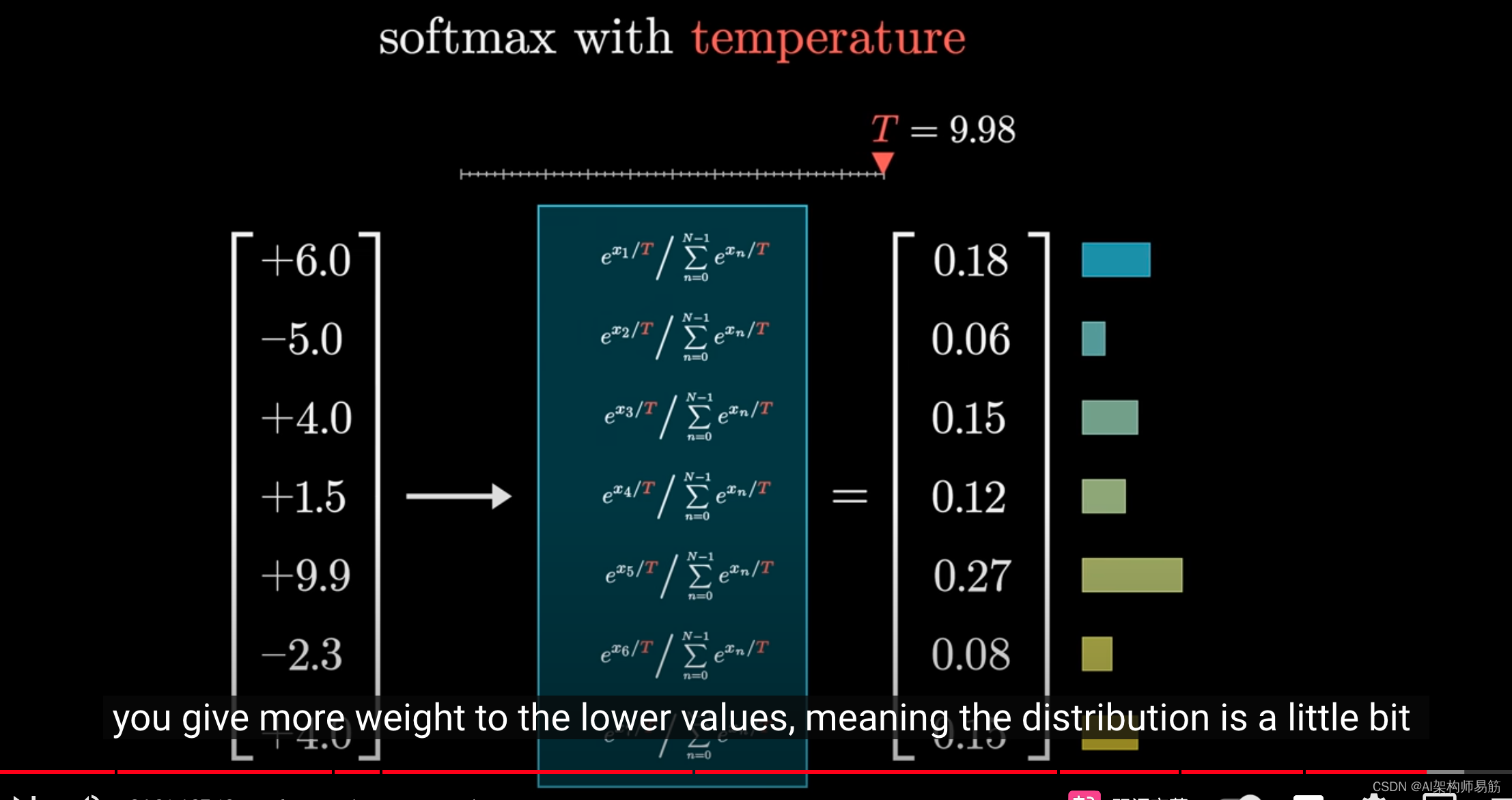
效果是,当t值较大时,较小的值会获得更多的权重,使分布略微更加均匀。
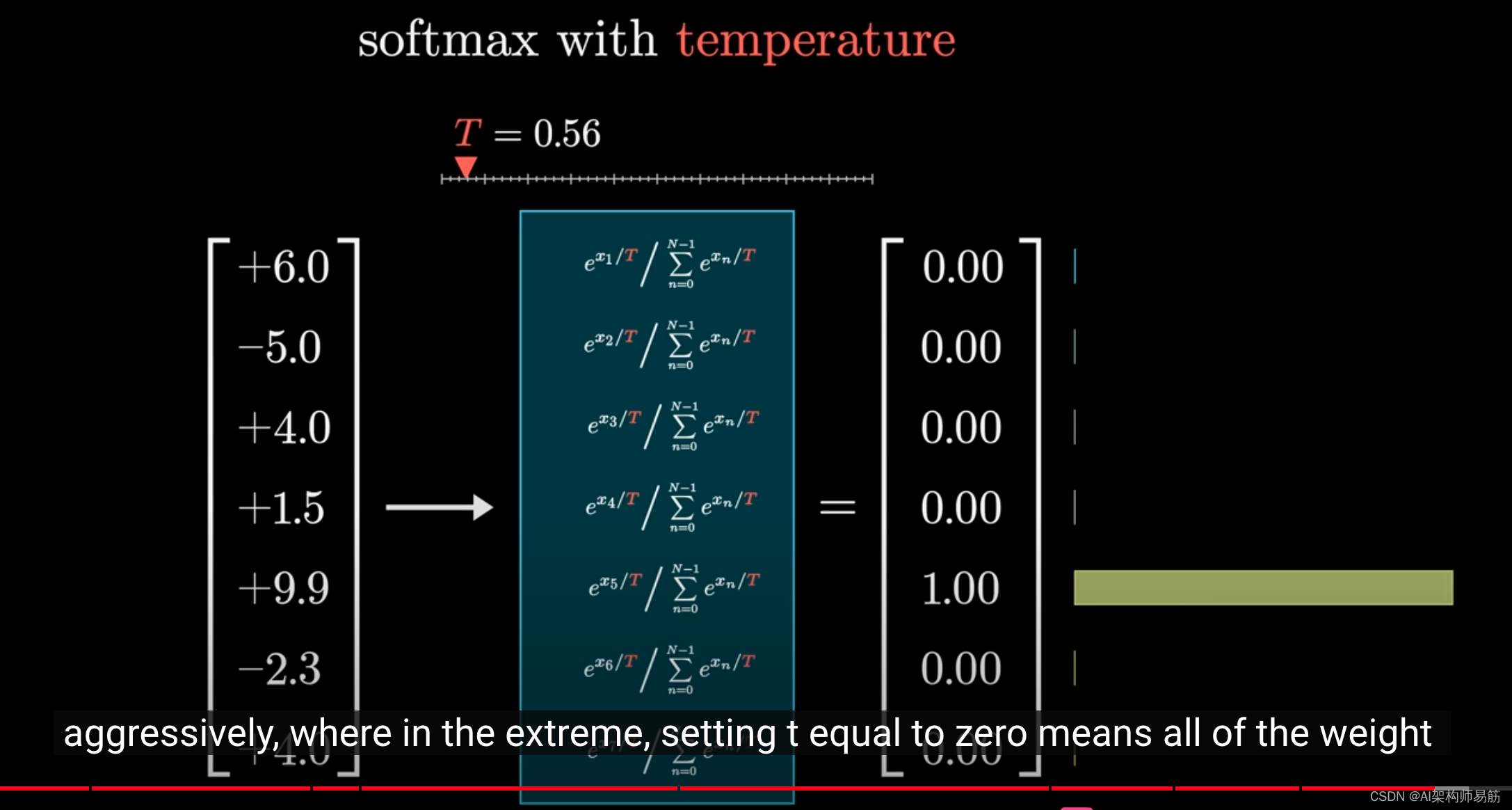
如果t值较小,较大的值会更加明显,在极端情况下,如果t设置为0,那么所有的权重都会集中在最大值上。

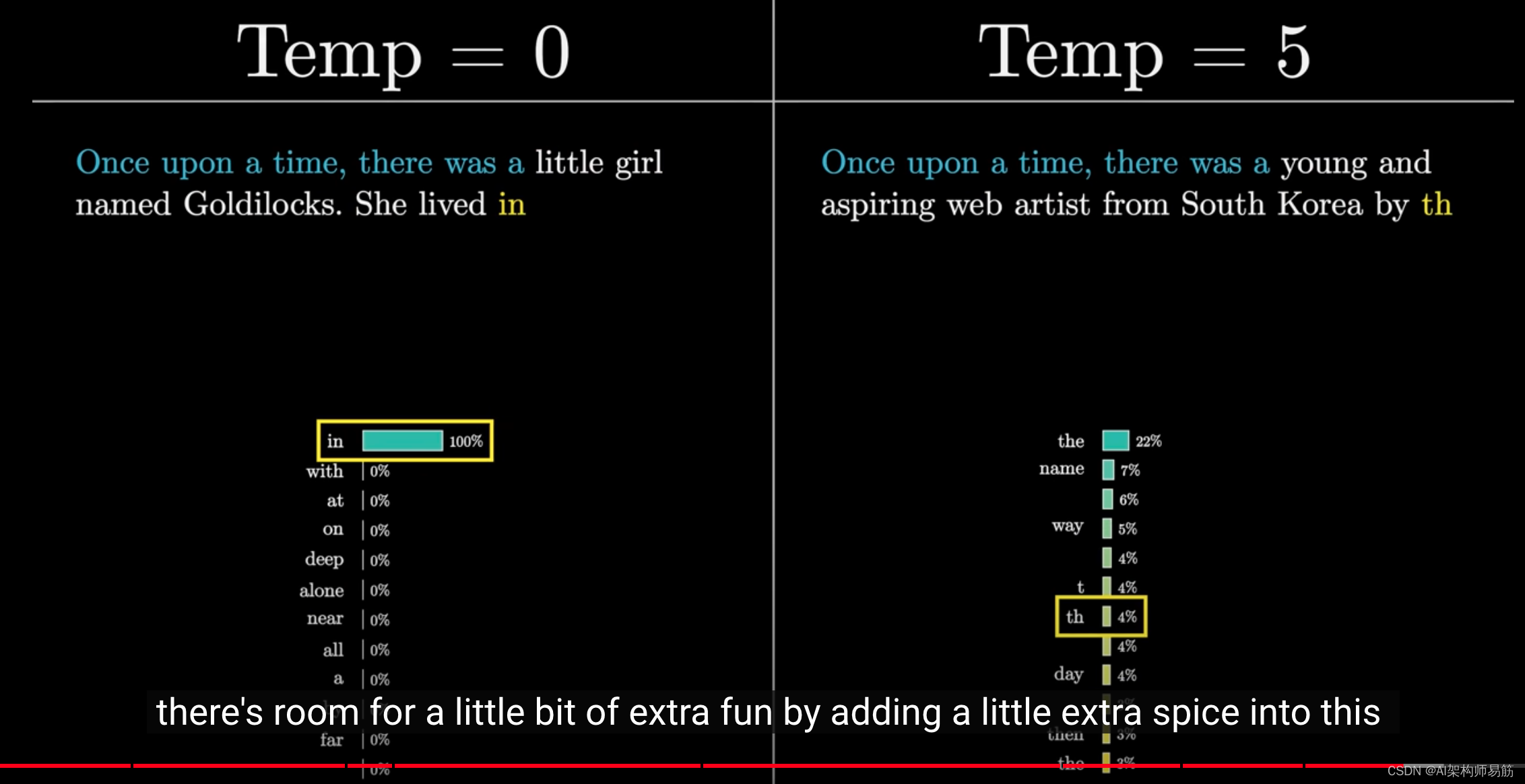
例如,我将使用GPT-3生成一个故事,种子文本是"从前有一个A",但我将为每个测试使用不同的温度。
温度为0意味着它总是选择最可预测的词,你得到的结果变成了一个老套的金发女孩的故事。
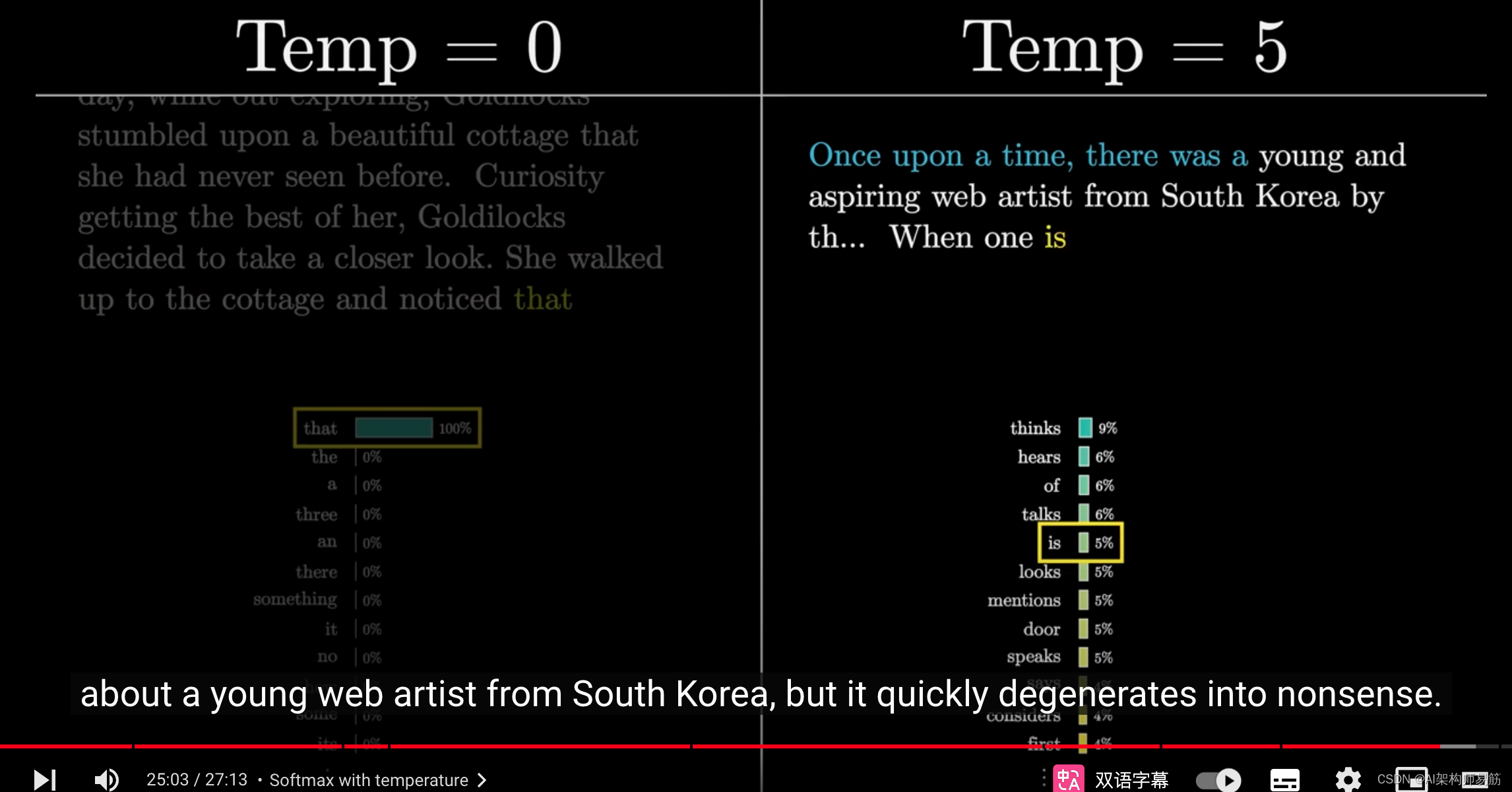
较高的温度给了它选择不太可能出现的词的机会,但这也伴随着风险。
在这种情况下,故事以一个关于韩国年轻网络艺术家的原创故事开始,但很快就变得毫无意义。
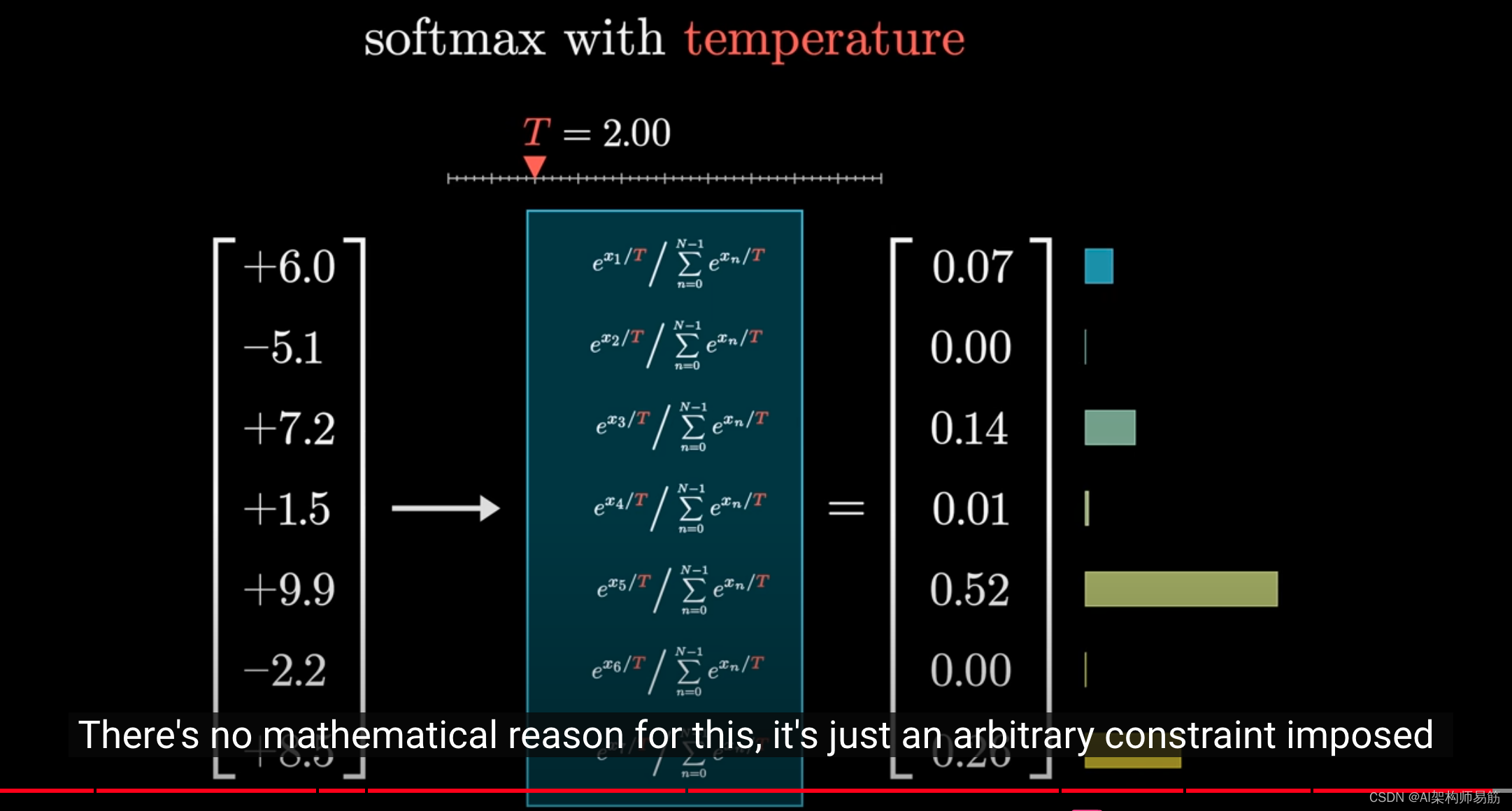
严格来说,API实际上并不允许你选择大于2的温度。
这个限制没有数学基础,我猜这只是一个人为的限制,以防止他们的工具产生过于荒谬的结果。

所以,如果你很好奇,这个动画是这样工作的:我选择了GPT-3生成概率最高的前20个tokens,这看起来是他们能给我的最多的了。

然后,我根据1/5的指数来调整这些概率。
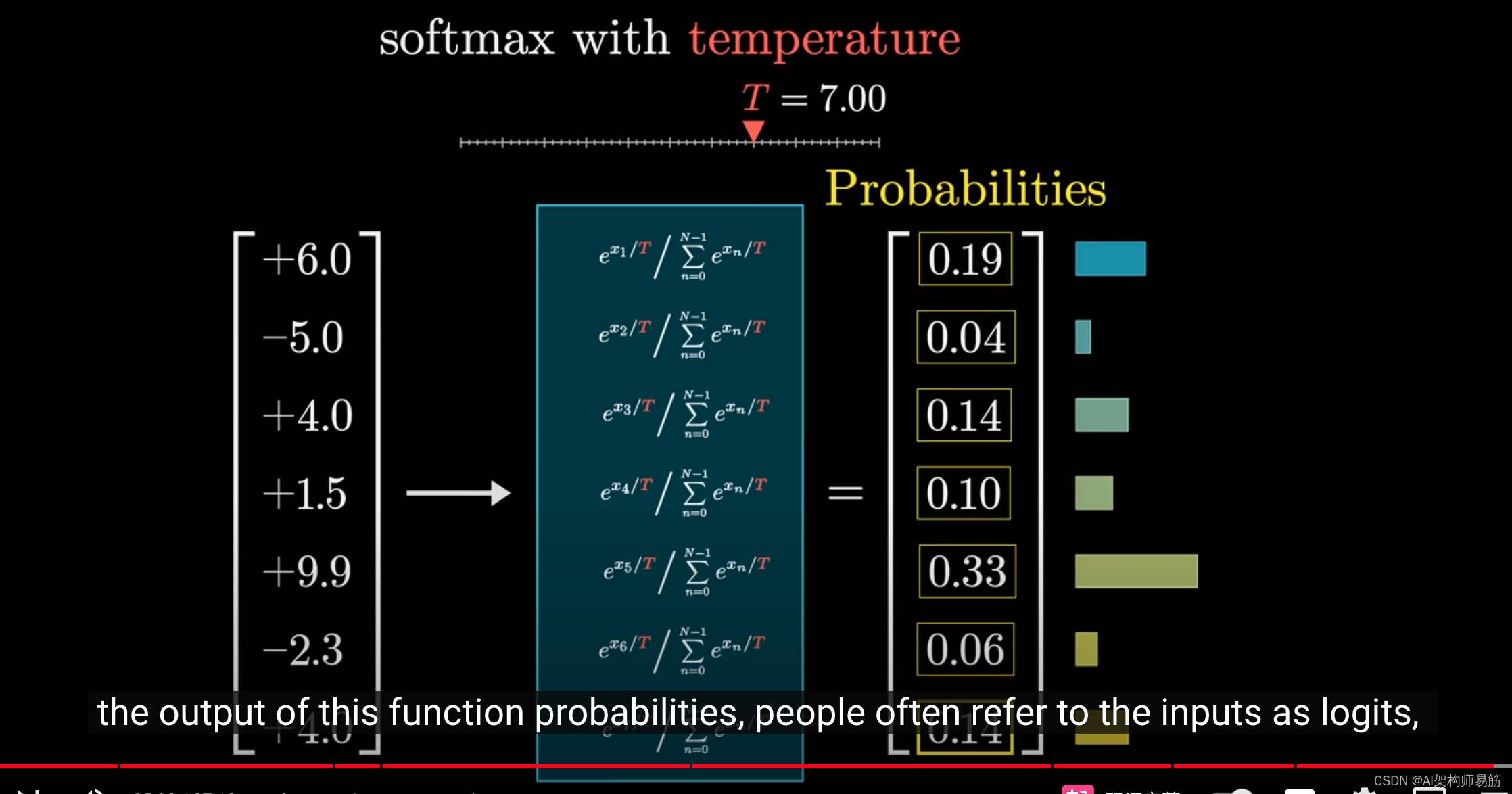
我要向你介绍另一个技术术语,在这个上下文中,我们通常称这个函数的输出分量为概率,
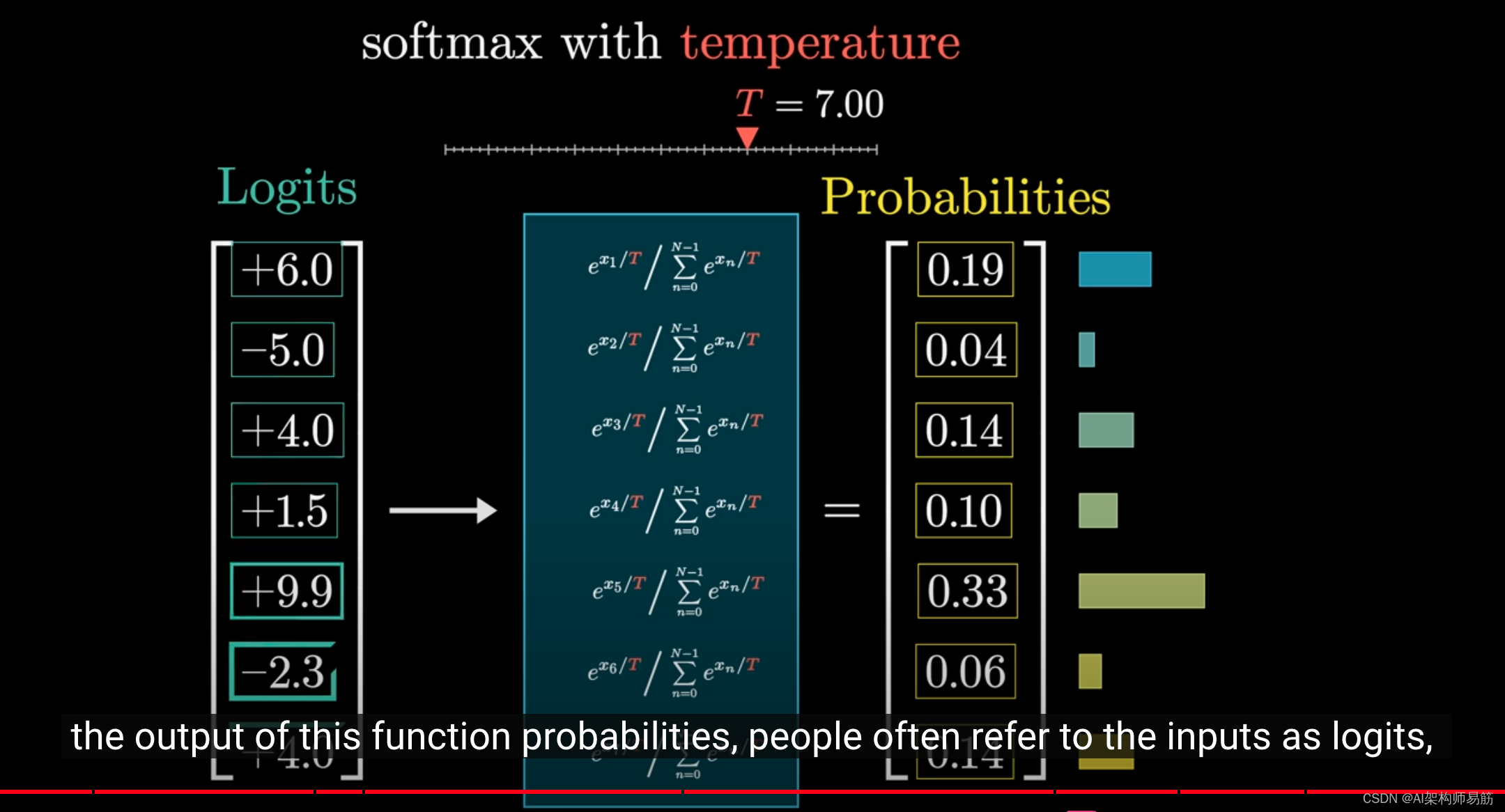
而人们通常称输入为logits,有些人说logits,有些人说logits,我选择说logits。

例如,当你输入一段文本时,所有这些词向量都会流经网络,
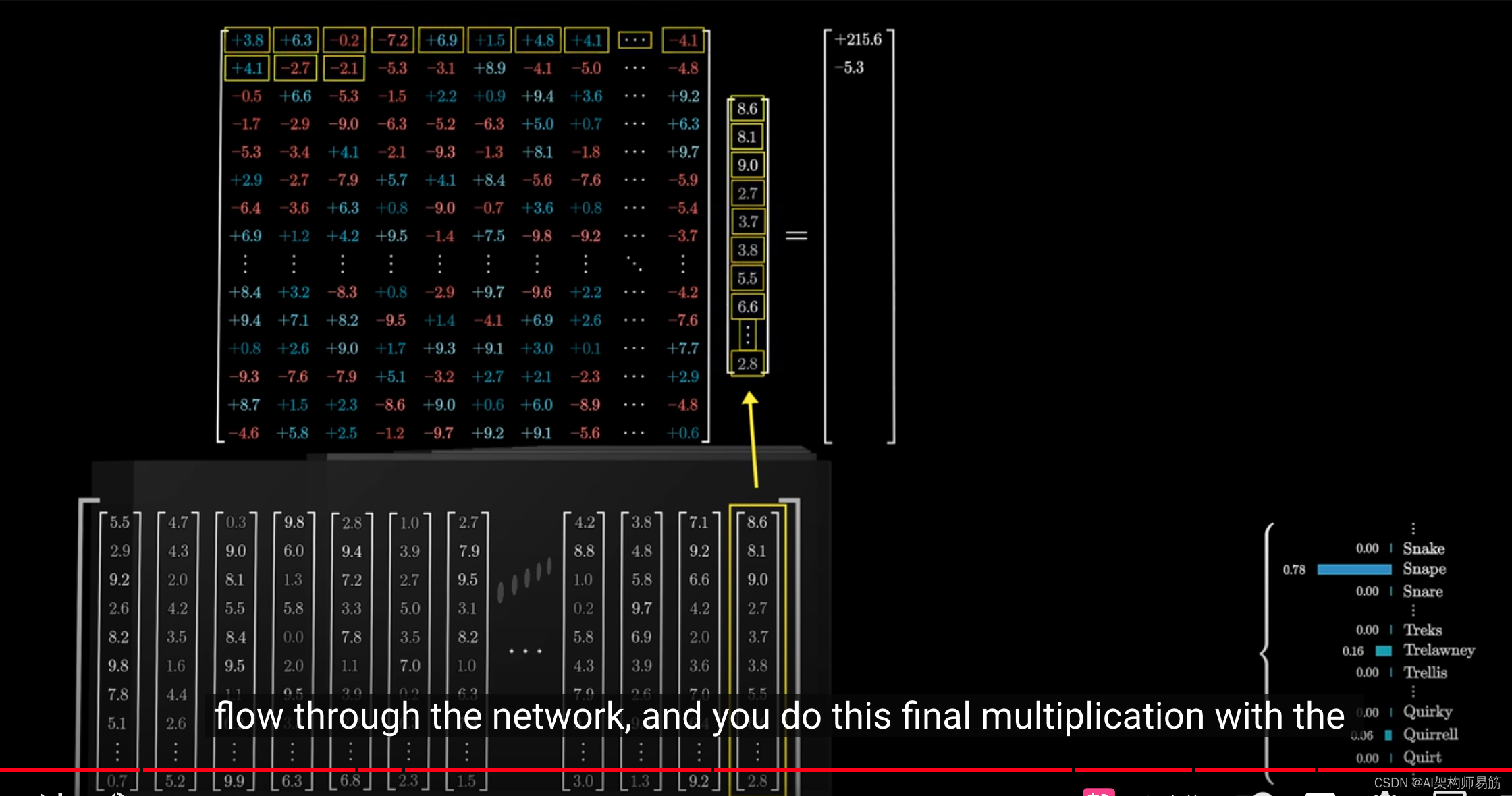
并与unembedding matrix相乘。
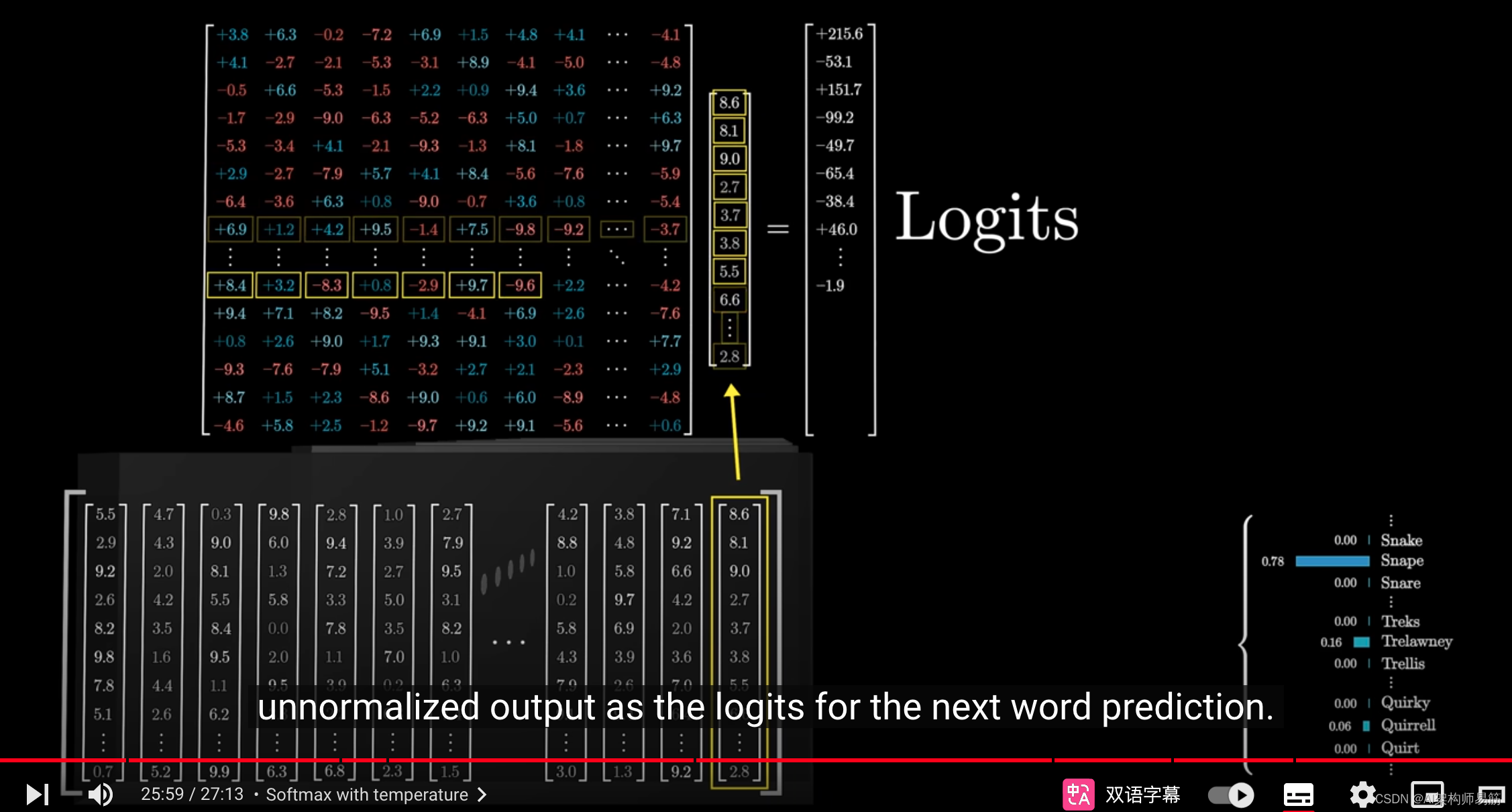
机器学习专家会将这个原始的、未经归一化的输出分量称为下一个词预测的logits。


本章的主要目标是为理解注意力机制奠定基础,就像电影《The Kid》中的基本技能一样。
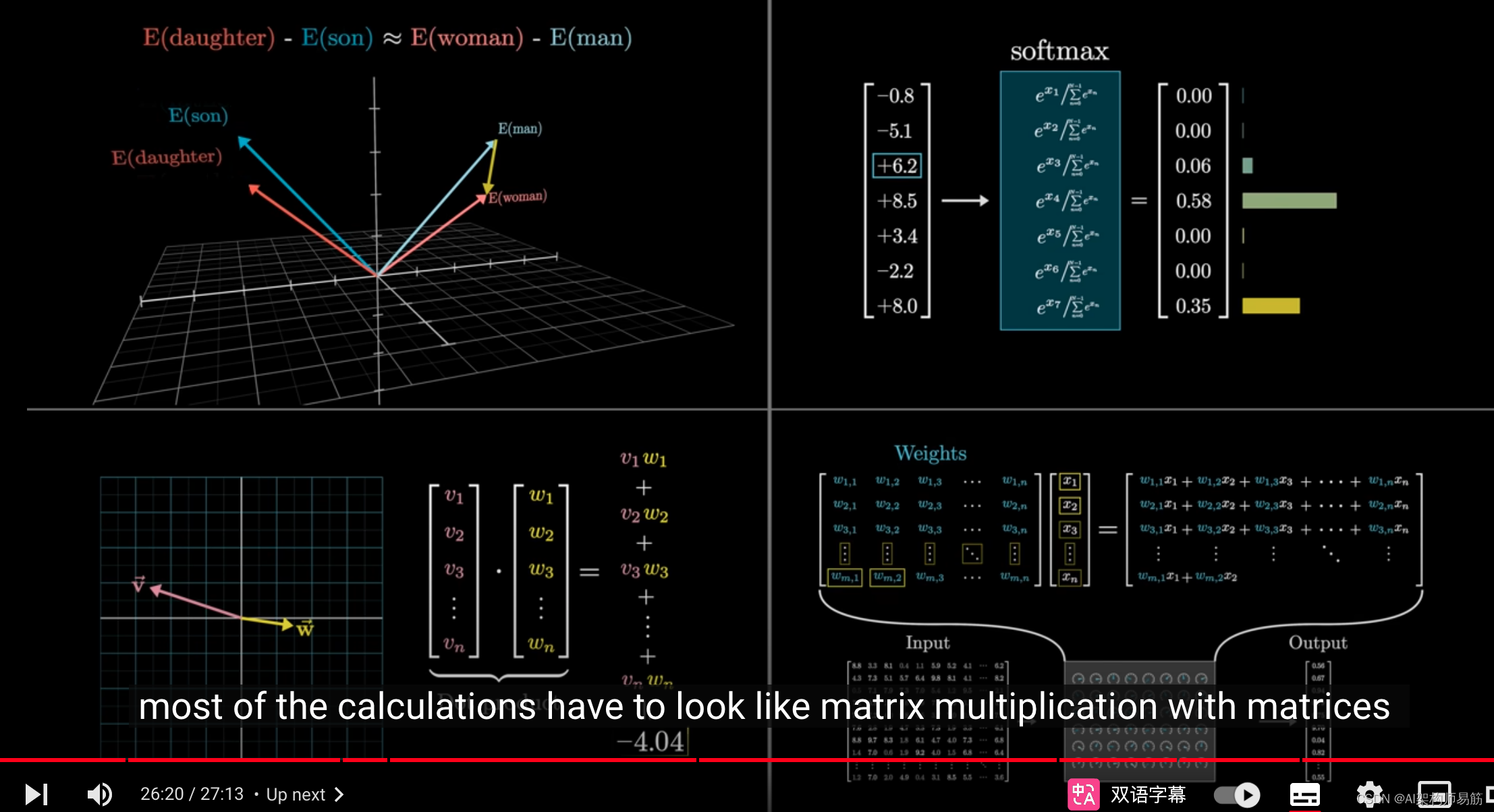
你看,如果你对词嵌入、softmax、点积如何衡量相似性
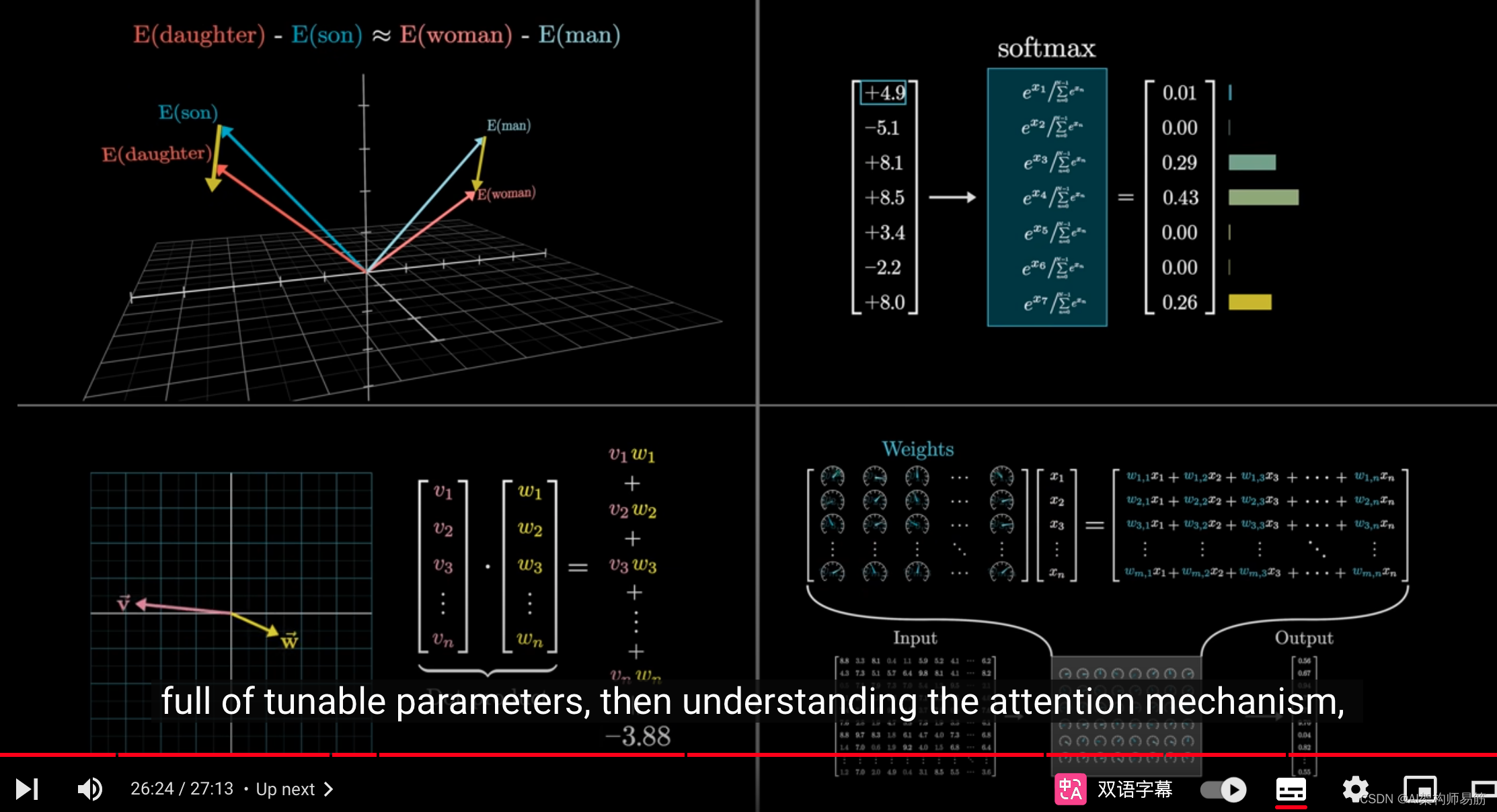

以及大多数计算看起来像是填充可调参数的矩阵乘法有深入的理解,

那么你应该更容易掌握注意力机制,这是现代AI浪潮中的一项关键技术。

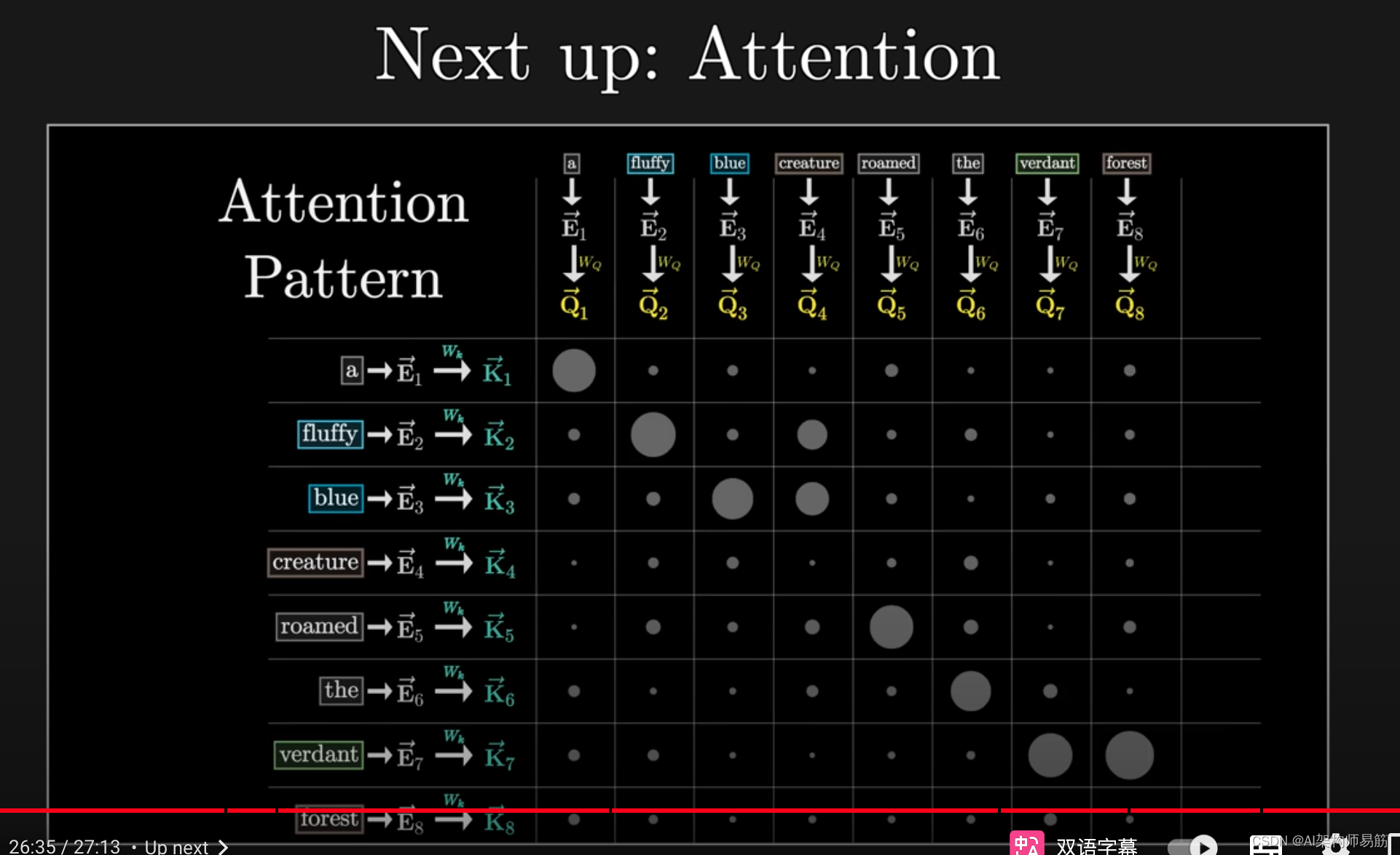
参考
https://youtu.be/wjZofJX0v4M?si=DujTHghH5dYM3KpZ