0 前言
CSV文件(Comma-Separated Values,字符分隔值)是一种普遍采用的数据存储格式,有不少企业和机构都用它来进行数据的管理和存储。身为开发者,您可能经常遇到这样的需求:需要将CSV的数据导入OceanBase数据库,或者需要验证OceanBase数据库与您先前使用的数据库之间的兼容性。针对这类需求,OB Cloud云数据库提供了Load Data功能,这是一个高效且可靠的方案,能够帮助您迅速将CSV格式的数据导入到数据库中。
Load Data 功能具有如下特点:
- 快速导入:通过 Load Data 功能可以轻松地将最多 10 GB 数据导入到数据库中,无需手动设定参数或执行脚本,节省时间和人力成本;
- 灵活配置:允许导入时根据数据文件的结构自动创建对应的表定义;
- 精准匹配:提供多种 CSV 配置选项,以满足不同格式的导入需求;能在无需强制要求数据文件与表中列顺序完全相同的前提下,自动匹配数据列;
- 数据安全:我们的导入功能可以根据需要设置出错中断,且可以保证导入的数据符合规范并且不会损害数据库的完整性。
本文介绍了通过该功能,将数据从普通 CSV 文件或从其他类型数据库的数据表中迁移至 OceanBase 数据表中的方法和步骤。
1 功能入口
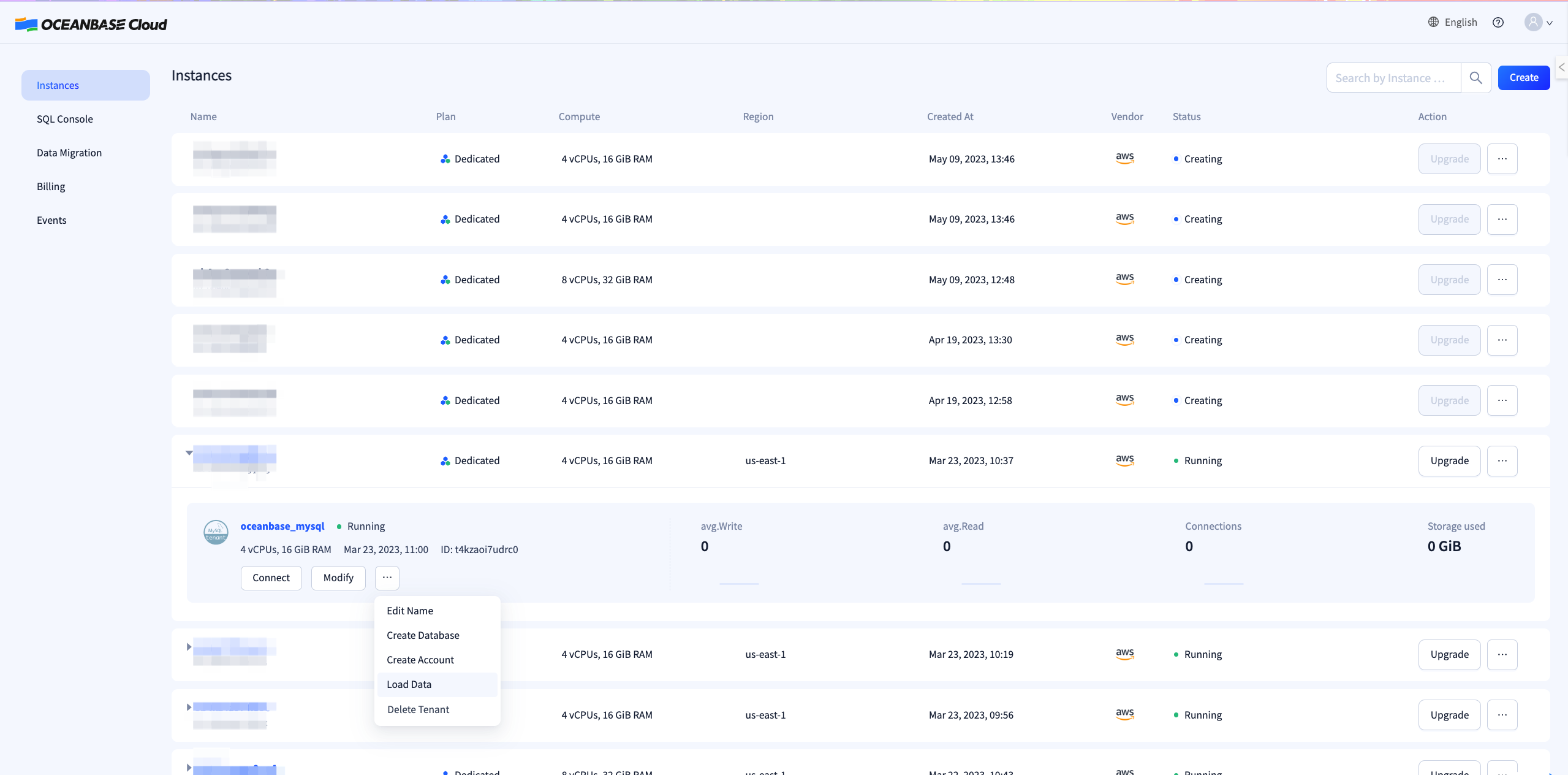
您可以从OB Cloud的控制台首页的租户卡片发起数据导入,或从租户工作台进入 Load Data 界面,以发起导入任务或查看当前租户的历史任务。

2 数据文件准备
CSV 文件使用逗号或其他指定的字符分隔的形式储存信息,通常情况下,所有记录都有完全相同的序列形式。OceanBase Cloud 的 Load Data 功能目前支持将单个 CSV 文件中的数据导入至单个数据表中,我们建议您使用的 CSV 文件符合 RFC 4180 规范。
在导入数据之前,请确保CSV文件中的数据完整且没有错误。如果您是从其他来源获得CSV文件,则需要进行数据清洗,以确保数据格式正确和数据的完整性。
若您的数据来源是 OceanBase 数据库或 OceanBase 以外的数据库如 MySQL 或 Oracle ,可以参考 从数据库中导出CSV文件小节。
2.1 上传文件以导入
您可以从本地上传文件至服务器,以进行导入任务。由于客户端的网络波动可能会影响上传速度等原因,此种方式将文件大小限制为 1 GB。
若希望导入超过 1G 的数据,可先将文件至云存储服务,选择 Load From Cloud storage file,除文件大小限制不同外,其余导入操作并无差异。
2.2 导入云存储中的文件
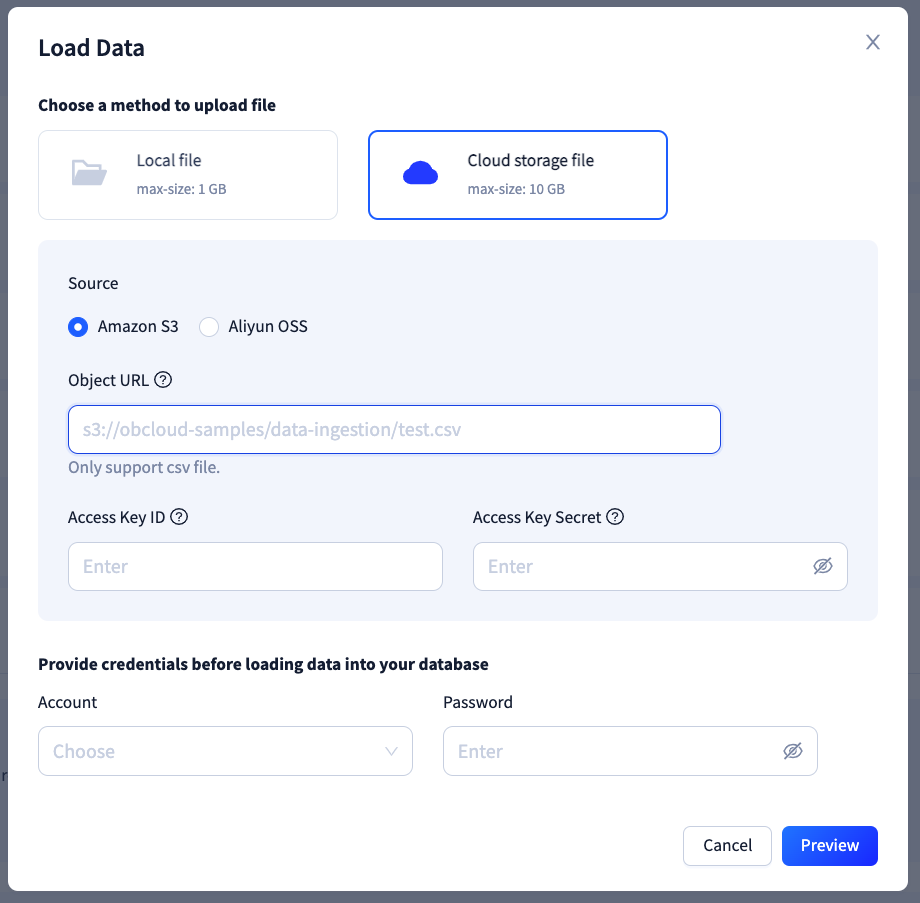
OceanBase Load Data 目前支持从 s3 和 oss 两种云存储导入文件。使用云存储作为导入任务的数据源时,能够支持 10 GB 以下的文件,若超过该限制,则无法发起导入任务。
Credentials
从云存储导入时,需要填写:
- Object URL:包括了对象存储的 bucket 和 path 信息,格式为
[oss/s3]://bucket/path,需要能够具体定位到文件,而非某个目录; - Access Key ID/Secret:用于访问对象存储的凭证,需在云存储控制台创建,只有在最初创建时才能访问密钥,若丢失则必须创建新的密钥对;
注:
- 当云存储提供商为 AWS s3 时,无需填写 Region 字段,因为 bucket 是全局唯一的,我们会根据 URL 中解析得到的 bucket 查找对应的区域;
- 您填写的 AK/SK 仅用于当前导入任务的文件获取,OceanBase 并不会存储该凭证,且网络通信过程会将其进行加密传输,因此无需担心凭证泄漏的安全问题。
3 选择导入目标
您可以选择已有数据库和表,也可以新建数据库后导入到该库中,前提是使用的用户具有建库权限。
在数据预览界面,点击数据库列表中的 Create Database 以创建新的数据库。
3.1 数据预览
选择已有的数据表时,我们会解析您提供的文件的部分数据,并与目标表的结构进行对比,生成数据预览视图,以确保导入的文件内容和 CSV 配置与您的预期相同。
- 若指定了跳过首行,则会根据数据文件中的列名与表列名匹配,此时二者顺序无需完全相同,我们会寻找二者的交集,仅在文件中和表中共同存在的列才会被导入;
- 您可以通过编辑 CSV 格式配置修改匹配的文件格式,且修改可实时生效,无需返回前一个界面。
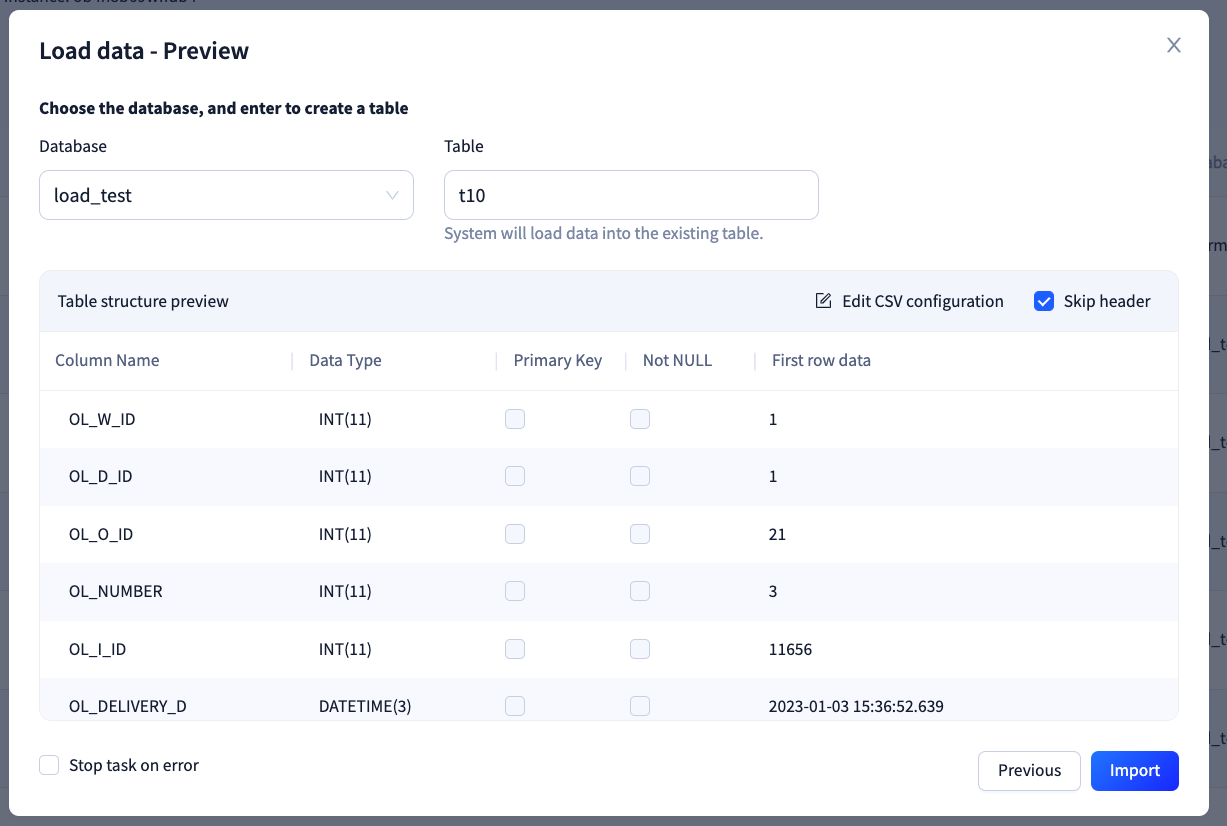
3.2 选择新建表
OceanBase 提供了解析文件以新建表的能力,您可以尝试在 Table 栏输入一个当前库中不存在的表名,我们会尝试生成文件对应表的结构预览。此处的功能包括:
- 与 选择已有表 时的数据预览不同,此时您可以编辑列名、主键、是否为空等元信息,若您根据当前预览发起导入任务,那么在导入数据之前会创建出对应的表定义;
- 若选择了“跳过首行”的选项,则使用首行数据作为列名,否则会自动生成类似 columnN 的列名;
- 当匹配到某个列名为“ID”或“UUID”时,默认会指定其为主键,您可以手动取消该主键。

数据类型
数据类型选择是一项十分重要的功能,您可以根据以下操作生成您需要的表定义:
- 默认的,我们会扫描文件数据,解析每个列可能的数据类型(目前仅支持常用的几种类型,我们后续会持续优化,完善数据类型);
- 在数据类型选择时,为了取得在可用性(完全手动输入)和易用性(完全下拉选择)的平衡,我们选取了一个折中的方式,即同时允许下拉选择和手动输入,在选择列表中提供了一部分常用类型,如下所示:

- 若在使用过程中遇到了手动输入的合法数据类型被拒绝的场景,请及时向我们反馈。
4 导入
当所有准备都完成后,此时便可以发起导入任务了。此时还有一个可选的配置项,那就是出错时是否立刻中断任务(Stop when error),若选择该项,则顾名思义,出错时导入任务会立刻停止,否则会跳过当前失败的数据,继续尝试导入。
值得注意的是,使用 Load Data 功能导入数据时,即便指定了出错立刻终止任务,但对于“重复主键”的错误,我们并不会立刻停止,而是忽略该条记录,继续尝试导入后续的数据。
如果导入数据中有大量的 Bad Record(无法被插入的数据),而又选择了失败时跳过,那么可能会导致任务变得特别缓慢,我们强烈建议此刻终止任务以释放占用的资源。
发起导入任务后,您可以在任务列表查看历史任务的详情。导入任务是跨租户隔离的,因此该页面仅展示当前租户的任务列表。
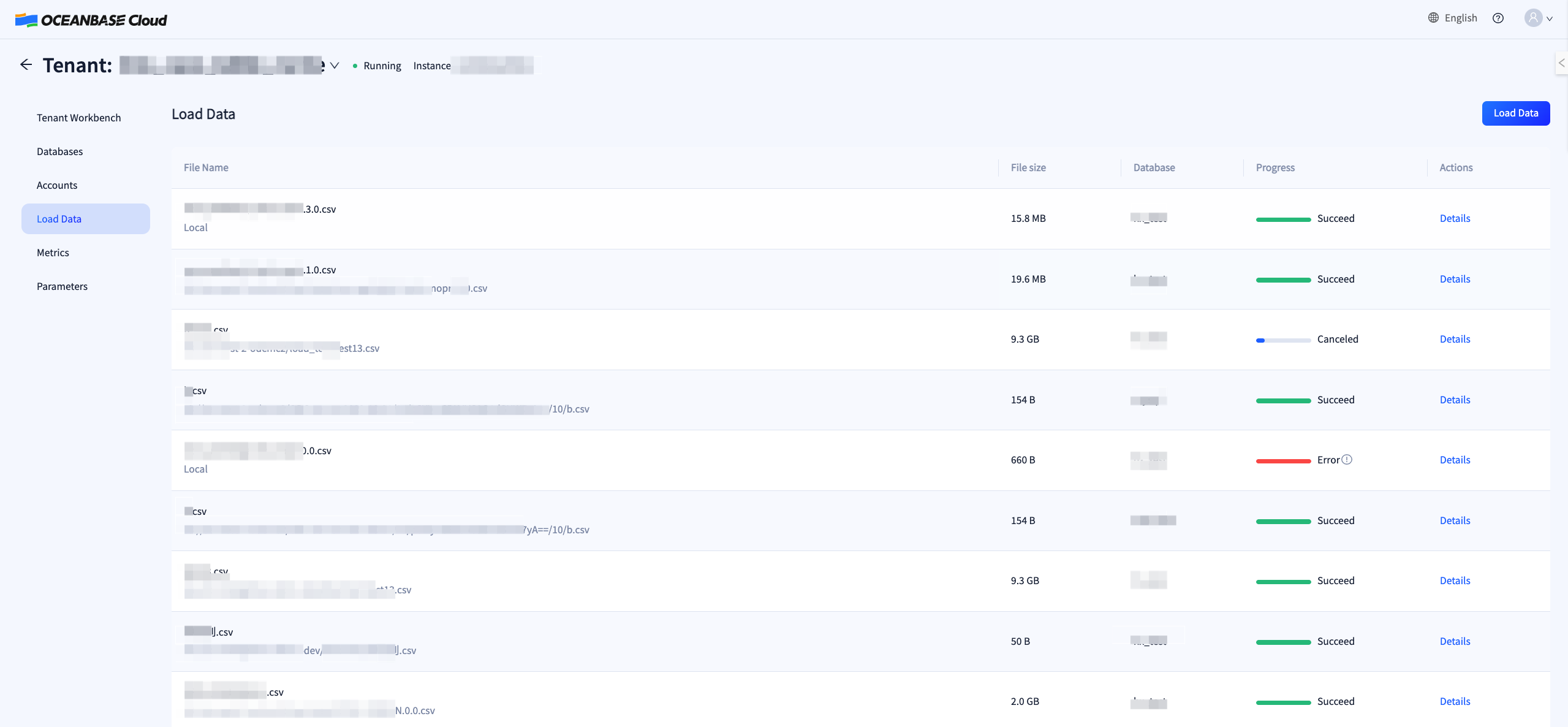
失败原因排查
对于一个失败的导入任务,可能存在多种失败原因,您可以通过如下方式进行排查:
- 点击任务详情,在详情界面我们展示了一条可能的失败原因;
- 若当前错误信息并不能解释任务失败原因,您也可以点击 Download Log 以下载任务日志,日志中记录了任务执行的详细信息,包括导入速率、失败记录、总导入数据量等;
- 若从日志中仍然难以定位任务失败原因,您可以点击反馈联系我们,会有专门值班人员跟进。
5 从数据库中导出 CSV 文件
5.1 From Oracle
如果导入的数据类型非源自于 OceanBase 数据库,例如 Oracle,则使用 Load Data 的功能导入单张表的数据前,需要将 Oracle Schema 中的表数据导出到 CSV 格式数据文件中。
您可以使用 Navicat 或 SQL Developer 等数据库开发工具进行导出,或仅使用 SQLPlus 命令工具将数据导入到文件中。使用 Navicat 导出的示例可参考后文 From MySQL 小节中的内容。
SQLPlus
以 SQLPlus 为例,可通过下面步骤,使用 SPOOL 命令将表 STUDENT 中的数据导出为 CSV 文件:
- 执行
sqlplus连接到默认数据库,或执行sqlplus schema@//machine.domain:port/database(替换为实际值)指定用户或数据库来连接; - 使用 SQLPlus 官方提供的
SET MARKUP命令用于指定结果输出至 CSV 格式:
SET MARKUP CSV ON DELIMITER , QUOTE ON;其中 DELIMITER , 选项指定输出数据以逗号(COMMA)为分隔符;QUOTE ON 选项指定打开文本引用,使用双引号(")引用文本数据。
说明:SET MARKUP CSV 仅支持上述两项格式配置,若您希望指定更加详细的 CSV 文件配置,请关闭 CSV 格式输出,并参考 文档 指定列分隔符等其他格式。
- 使用
SPOOL命令将查询结果输出至文件,完整的操作流程如下:
SQL> SET MARKUP CSV ON DELIMITER , QUOTE ON;
SQL> SPOOL STUDENT.csv;
SQL> SELECT * FROM STUDENT;"ID","NAME","SEX"
1,"leo","m"
2,"tracy","f"
3,"mike","m"SQL> SPOOL OFF;- 最终得到的文件格式如下,需要将首尾删除,仅保留中间的有效数据,才能够通过 Load Data 功能导入 OceanBase。

说明:通过这种方式导出的数据默认转义符为双引号,导入时需要修改对应 CSV 格式配置,否则将会识别为错误的数据。
5.2 From MySQL
与 Oracle 相同,首先需要将数据导出至 csv 文件中,再进行导入操作。您可以使用 Navicat 、DBeaver 等白屏数据库开发工具进行导出,也可以使用 mysqldump 导出工具。
mysqldump
当使用 mysqldump 工具时,可以参考如下命令导出数据到 "/output" 目录:
mysqldump -h 127.0.0.1 -P 3306 -u xxx -p xxx --databases test --compact --fields-optionally-enclosed-by '\"' --fields-escaped-by '\\' --fields-terminated-by ',' --lines-terminated-by '\r\n' --tab='/output/'
说明:该示例将数据库中定义的Schema和表数据分开导出,Schema是按照SQL-format格式输出,数据是按照标准的 CSV 格式输出,CSV规范可参考 RFC-4180
mysqldump 工具提供了很多灵活的配置,允许将数据库定义以及其中数据导出为多种格式的文件,具体使用方式可参考官方文档,但对于简单的数据迁移任务,使用上述命令即可满足导入 OceanBase 需求的格式。
Navicat
与 mysqldump 不同,白屏开发工具支持的配置有限,您可以按照如下流程将 STUDENT 表中的数据导出到 CSV 文件:
- 打开 Navicat 中的连接,选中
STUDENT表,打开Export Wizard导出向导,选中 csv 格式; - 在自定义格式配置的界面,按照如下格式进行配置:
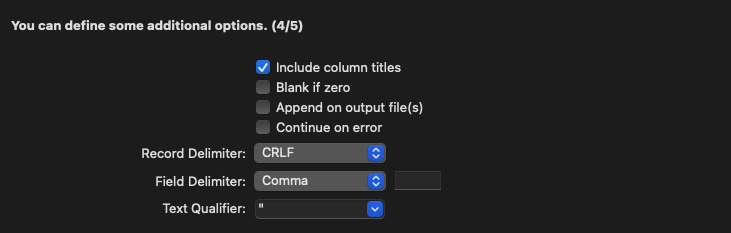
- 点击导出,可将文件导出为如下格式:
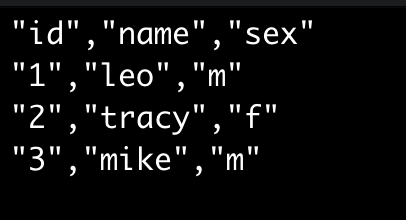
说明:当前格式是我们推荐的,可按照默认 CSV 配置导入 OceanBase 的 CSV 格式,您也可以按需修改,在导入预览时通过 Edit CSV Configuration 功能修改为对应格式即可。
5.3 From OceanBase
一般情况下,我们推荐使用 ob-dumper 从 OceanBase 导出数据,例如,下面的命令可将 Schema "test" 中所有表中的数据按照 CSV 格式导出到 "/output" 目录中
./obdumper -h 127.0.0.1 -P 2883 -u xxx -t tenant_A -c cluster_A -p xxx --sys-password xxx -D test --table '*' --column-delimiter '\"' --csv -f '/output/'
说明:
- 命令行参数指定的对象名、数据文件名、控制规则文件名要求大小写一致。Oracle 默认大写,MySQL 默认小写。如果需要区分大小写,请将表名放入中括号内([ ])。例如:--table '[test]' 表示 test 表,文件名格式为 test.group.sequence.suffix; --table '[TEST]' 表示 TEST 表,文件名格式为 TEST.group.sequence.suffix;
- 导出的数据文件的命名规范是 table.group.sequence.suffix
6 结语
感谢您的阅读,并了解我们的 Load Data 功能。我们相信,OceanBase 的快速导入功能可以帮助您快速、准确地将数据导入到数据库中,并提高数据管理和处理的效率和质量。
如果您对我们的导入功能感兴趣,欢迎访问 OceanBase Cloud 了解更多信息或试用我们的产品。我们随时准备为您提供专业的技术支持和服务,并与您共同探讨如何更好地应用数据管理于您的业务中。
目前 Load Data 功能仅支持单 CSV 文件 -> 单表的数据导入,后续会继续支持 SQL 数据文件、SQL DDL 文件、多表和整库的多种导入方式,如果您有其他功能场景的需求或创意,也欢迎向我们反馈~