前言:在上一篇文章中,我们已经会使用getpid/getppid函数来查看pid和ppid,本篇文章会介绍第二种查看进程的方法,以及如何创建子进程!

本篇主要内容:
- 查看进程的第二种方法
- 创建子进程
- 系统调用函数fork

在开始前,我先来回顾一下如何获取pid,ppid
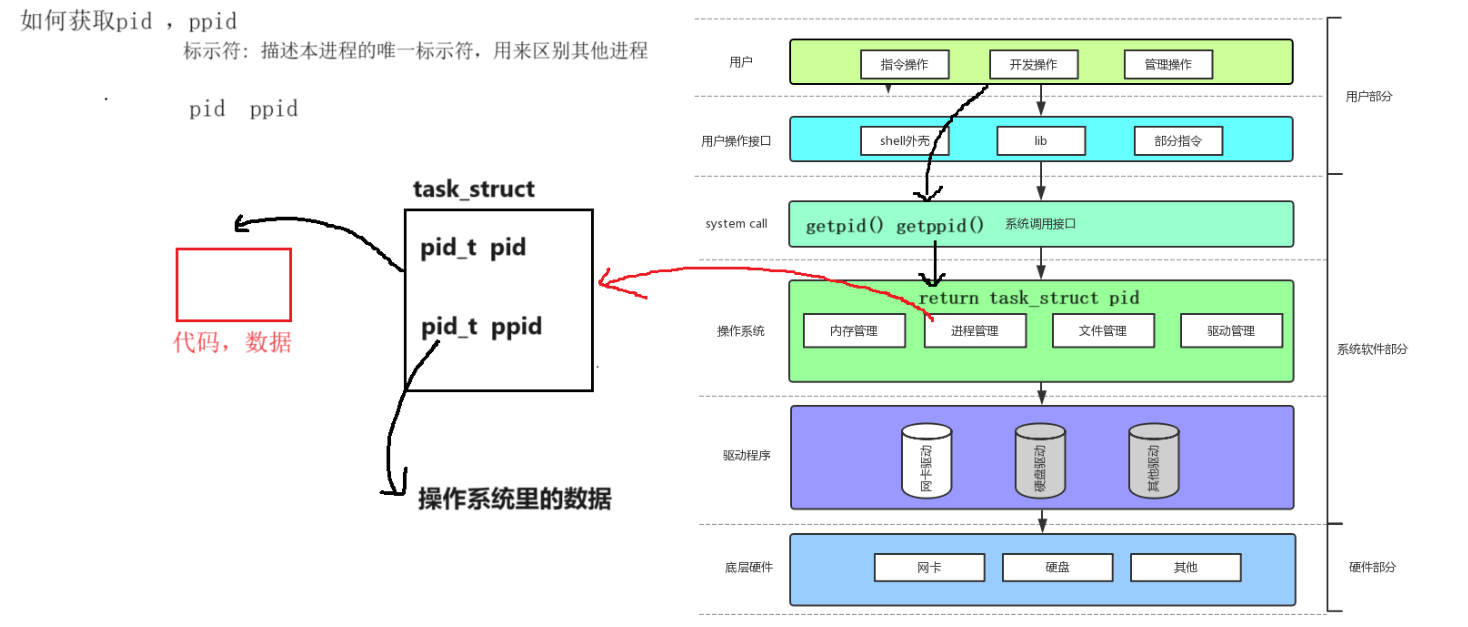
进程要想区分就一定会有唯一的标示符,而pid,ppid初始化后就变为内核中的数据,也就是操作系统里的数据,在我们自己开发时,操作系统不会将内部数据暴露出来,不能直接访问,所以通过系统调用接口直接获取pid,ppid。
目录
- 1. 查看进程的第二种方法
- 2. 创建子进程
- 2.1 系统调用函数fork
- 2.2 fork的一般写法
- 2.3 fork的原理
- 3. 总结
1. 查看进程的第二种方法
在Linux系统中,不只有ps能够查看进程,还存在着一个动态目录proc,该目录存放了所有存在的进程,目录的名称。它会随着进程的改变而随时更新它的内容!
查看所有进程:
指令:ls /proc/
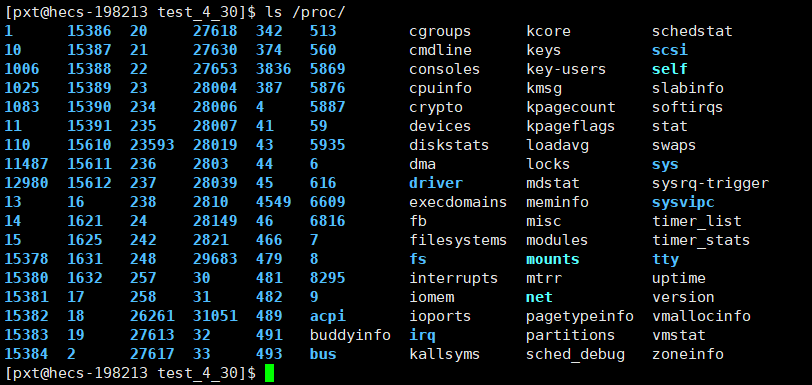
查看指定pid的进程文件:
指令:ls /proc/进程pid
如果想只查看这个目录我们可以:
指令:ls /proc/进程pid -dl
proc查看进程
当我们结束这个进程时,文件也会从proc中被删除
误删可执行程序时
在看完这个视频后,我们发现当我们在程序运行时,误删了可执行程序,进程不会被终止,但是在proc目录中的exe被标红并注明delete
在自行创建的进程中,我们只需要掌握好两个文件
cwd和exe
- cwd代表当前工作目录
- exe指向可执行程序的位置
默认情况下,进程启动所处的路径,就是当前路径,pwd指令其实就是从cwd中找到当前路径的!
当前工作目录是可以通过系统调用进行修改的:
指令:chdir ( " 路径 " )
我们只需要在代码编写时,加入这条指令我们就能更改当前工作目录
2. 创建子进程
2.1 系统调用函数fork
在Linux中,进程的创建方式有两种:
- 命令行中直接启动进程
- 通过代码创建
而在用代码创建进程时,实则是进行了系统调用,这里我们就得在学习一个系统调用函数fork!
函数:
fork
让我们来简单用man指令了解fork函数信息
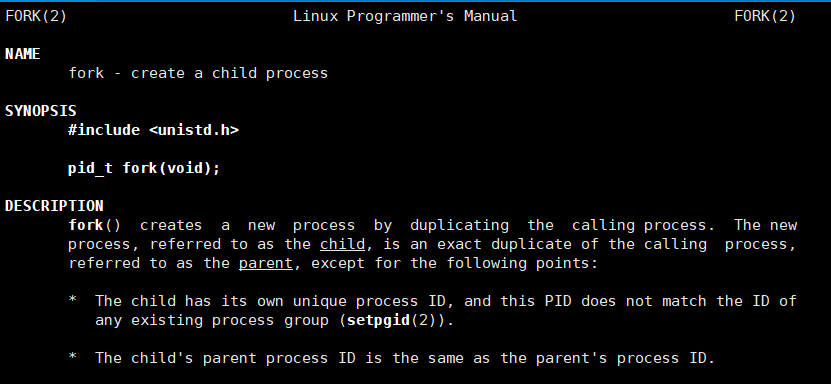
fork的功能是创建一个子进程
让我们来简单实现以下fork
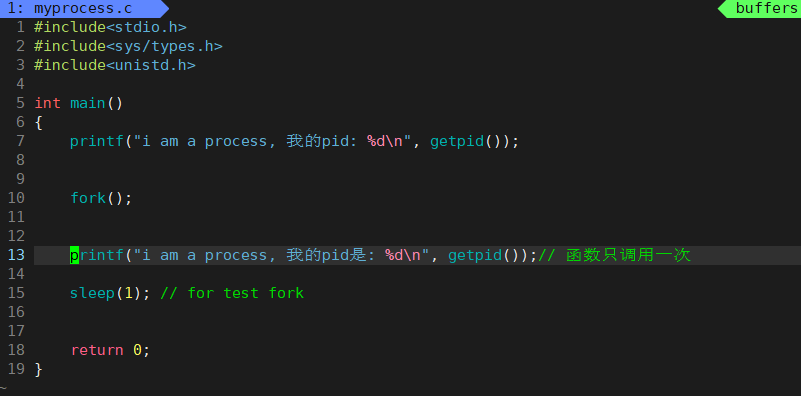

我们发现在fork之后函数printf调用了两次!!!
我们再来看看进程的ppid
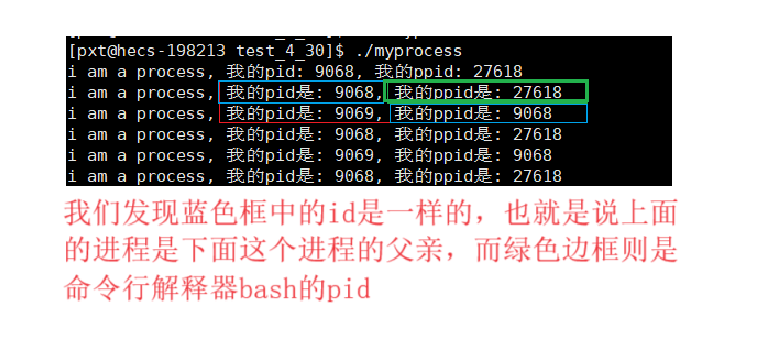
- 说明了一个情况:fork之后,会创建子进程,并且子进程会和父进程一起进入后面的函数并且分别执行一次
2.2 fork的一般写法
结合目前: 只有父进程执行fork之前的代码(一定),fork之后,父子进程都要执行后续的代码!
- 因此我们推断
fork函数不仅会帮我们创建子进程而且它还有两个返回值,fork成功的时候,会有两个不同的返回值,给子进程返回0,给父进程返回子进程的pid。
首先我们来思考以下问题:
那么我们为什么要创建子进程?子进程的作用是啥?
- 我们想让子进程协作父进程完成一些工作,这些工作是单进程解决不了的,因此子进程的创建是为了协助父进程,因此父子进程做的是不一样的事情
我们怎么保证父子进程做的是不一样的事情呢?
- 我们可以通过判断
fork的返回值,判断谁是父,谁是子,然后让他们执行不同的代码片段
让我们来看一下fork的一般写法
1 #include<stdio.h>2 #include<sys/types.h>3 #include<unistd.h>4 5 int main()6 {7 printf("i am a process, 我的pid: %d\n", getpid());8 9 10 pid_t id = fork();11 12 if(id < 0) return 1;13 14 else if(id == 0)15 {16 // child17 while(1)18 {19 printf("我是子进程: pid: %d, ppid: %d, ret: %d, 我正在执行下载任务 \n",getpid(),getppid(),id);20 sleep(1);21 }22 }23 24 else25 {26 // parent27 while(1)28 {29 printf("我是父进程: pid: %d, ppid: %d, ret: %d, 我正在执行播放任务 \n",getpid(),getppid(),id);30 sleep(1);31 }32 }33 }
我们可以看到明明我们的fork只使用了一个变量接收但是出现了两个返回值
2.3 fork的原理
关于fork这个函数的原理,我们依然抛出几个问题
- fork干了什么事情?
- 为什么fork会有两个返回值?
- 为什么fork的两个返回值,会给父进程返回子进程pid,给子进程返回0?
- fork之后父子进程谁先运行?
- 如何理解同一个变量会有不同的值?
fork干了什么事情?
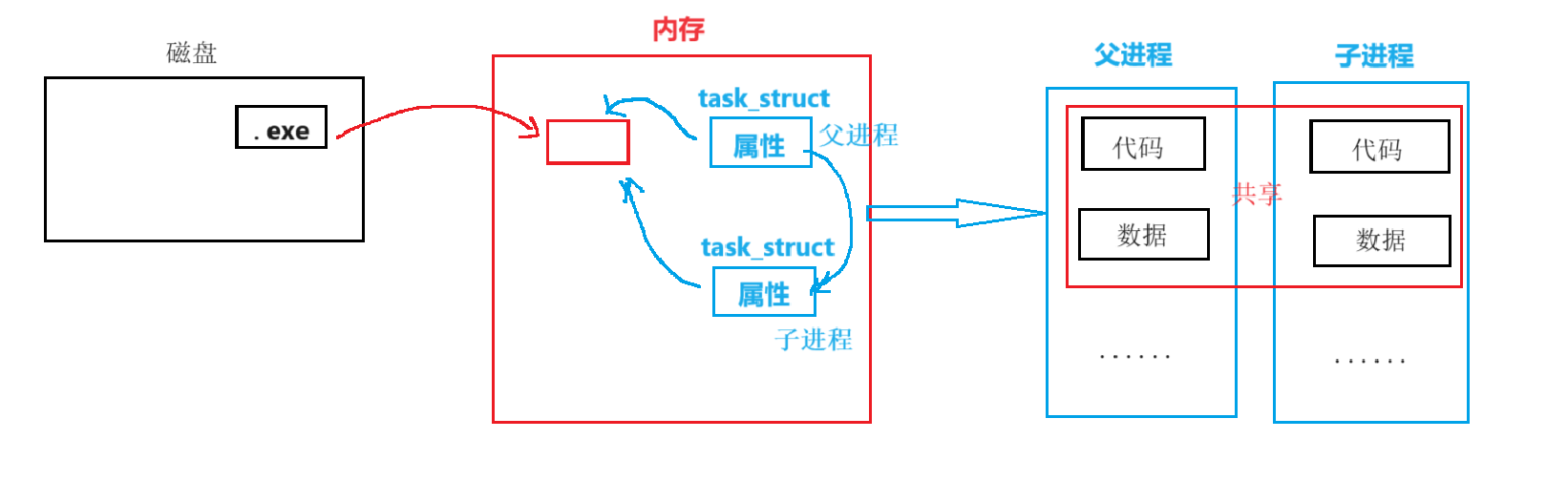
fork创建子进程,系统中会多一个子进程
- 以父进程为模板,为子进程创建PCB
- 但是你今天创建的子进程,是没有代码和数据的!!!目前和父进程共享代码和数据!!
- 所以,
fork之后,父子进程会执行一样的代码
为什么fork的两个返回值,会给父进程返回子进程pid,给子进程返回0?
在用进程中,一个父进程可能会有多个子进程,但是子进程永远都只有一个父进程,所以
父 :子 只会是 1 :n,为了能够更好的管理这些子进程,就必须返回具有唯一性的pid。但是子进程会很容易找到父进程,所以返回0表示成功即可!!
fork之后父子进程到底谁先运行?
创建完成子进程,只是一个开始,创建完成子进程之后,系统的其他进程,父进程和子进程,接下来要被调度执行的,当父子进程的PCB都被创建并在运行队列中排队的时候,哪一个进程的PCB先被选择调度,那个进程就先运行!!
- 但是PCB的选择调度是由操作系统自主决定(由各自PCB中的调度信息(时间片,优先级等)+调度器算法共同决定)
- 所以我们不确定父子进程到底谁先运行
最后为什么fork会有两个返回值?
如果一个函数到达了return,那么他的核心工作是否完成?
- 答案很显然是的,所以。。。

最后在fork之后代码共享,所以return也会被共享进入父子进程,并在父子进程中分别执行,所以在fork函数return之前,父子进程就已经分流,因此就会产生两个返回值!
如何理解同一个变量会有不同的值?
同一个函数有两个返回值是因为fork后两个进程都被调度了,但是同一个变量会有不同的值?该如何理解?
首先我们思考一下,如果我们杀掉子进程,父进程还会存在嘛?杀掉父进程呢?
分析父子进程是否独立
由此,我们可以得出结论:进程之间运行的时候,是具有独立性的,杀掉父进程不会影响子进程!反之也是!
- 进程的独立性,首先是表现在有各自的PCB进行之间不会互相影响,代码本身是只读的,不会影响,数据父子是会修改的!代码共享,数据各个进程都会写时拷贝私有一份!
- 变量id是父进程定义的变量,保存数据,返回的时候发生写时拷贝,不同
的进程执行的代码中的变量id获取的值不同,所以id在父进程和子进程中值不同
3. 总结
fork函数的内容远不只有这么一点,但是理解这五个问题能快速帮助我们,简单理解这个函数,了解fork的原理!关于如何创建子进程我们就讲到这里!
谢谢大家支持本篇到这里就结束了