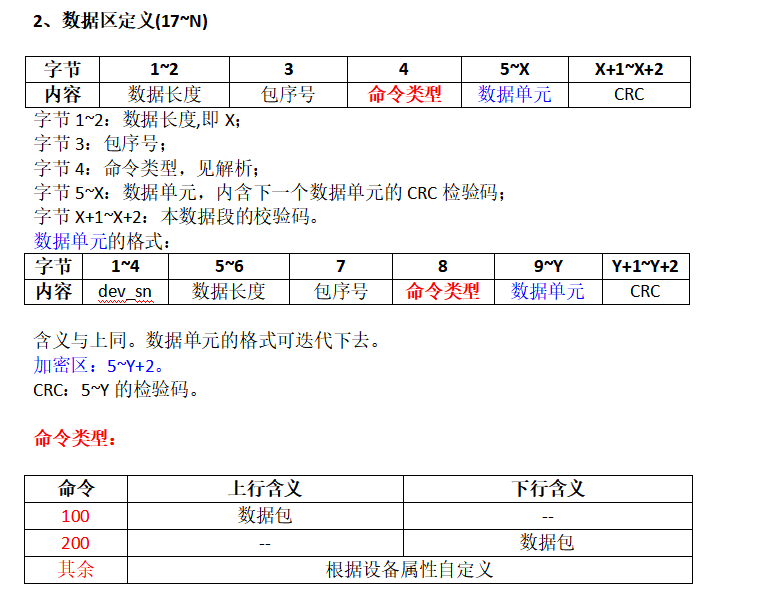
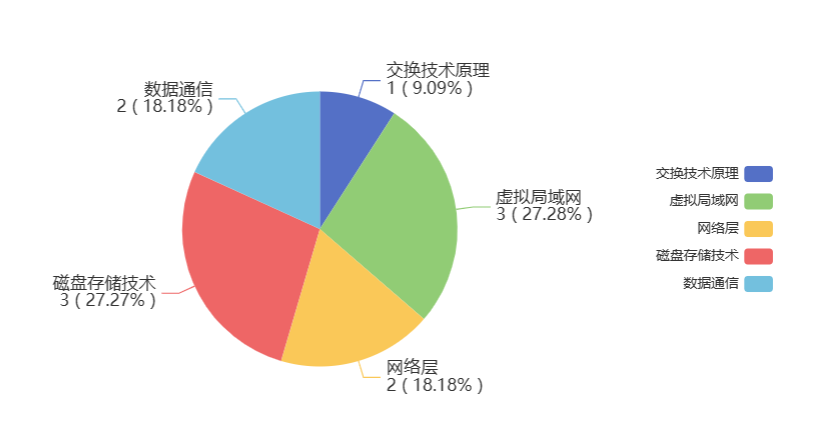
概念
检索增强生成(Retrieval Augmented Generation, RAG)是一种结合语言模型和信息检索的技术,用于生成更准确且与上下文相关的输出。
通用模型遇到的问题,也是RAG所擅长的:
知识的局限性: RAG 通过从知识库、数据库、企业内部数据等外部数据源中检索相关信息,将其注入到模型提示词中,使模型能够利用这些信息进行推理和生成。这弥补了模型仅基于公开训练数据的不足,让其在面对实时性、非公开或离线数据时也能提供相关内容。
幻觉问题: 由于语言模型的底层运作基于数学概率,其输出本质上是一系列数值运算结果,因此在模型知识匮乏或不擅长的领域,可能会出现幻觉问题,即生成与现实脱节或错误的内容。RAG通过将检索到的准确且相关的信息作为输入的一部分,降低了幻觉问题的发生几率,使模型生成的内容与现实更为一致。
数据安全性: 对于企业来说,数据安全至关重要,将私有数据上传到第三方平台进行训练存在风险。RAG 可以在企业内部构建知识库或数据库,并从中检索信息,将其注入模型提示词。这一过程可以在本地进行,无需将数据上传到外部,从而确保数据安全。
基本工作流程包括三个主要步骤:
1. 检索(Retrieve):
- 输入查询: 用户通过输入查询或问题来开始这个流程。
- 相似性搜索: 系统将用户查询通过嵌入模型转换为向量,并在外部知识源中的向量数据库中进行相似性搜索。
- 返回相关信息: 搜索会返回与查询最接近的前 k 个数据对象(上下文信息),这些对象来自于知识库、数据库或其他数据源。
2. 增强(Augment):
- 填入模板: 用户查询与检索到的上下文信息被填入到一个提示模板中。
- 构建完整提示: 这个模板整合了查询和相关信息,构建出一个完整的提示词,用于指导模型生成。
3. 生成(Generate):
- 输入到 LLM: 构建好的提示被输入到大型语言模型(LLM),比如 GPT 或 Qwen。
- 生成内容: 模型根据提示词中的信息生成相关内容,包括回答、文本或其他输出。
RAG 的优势:
- 即时性: 通过检索外部信息源,RAG 能够即时更新模型的知识,让其对实时性、非公开或离线的数据也能提供有效回应。
- 准确性: 注入的相关信息提升了模型输出的准确性,减少了幻觉问题。
- 数据安全: 可以在内部构建知识库,从而确保敏感数据不会外泄。
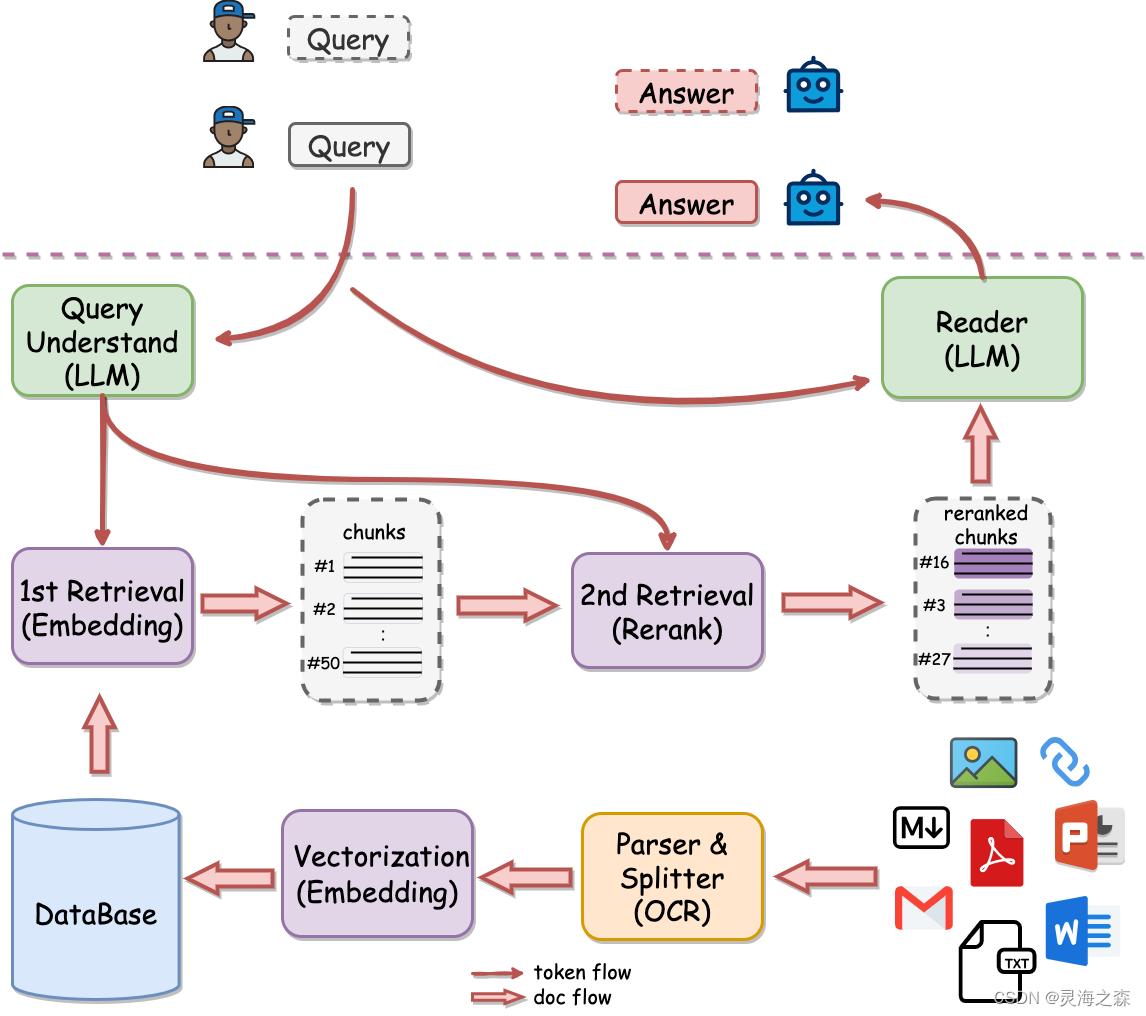 这是有道开源的QAnything,可以拿来直接用,使用MILVUS数据库和langchain。画的这个图很好。
这是有道开源的QAnything,可以拿来直接用,使用MILVUS数据库和langchain。画的这个图很好。
可以根据这个图来分析RAG系统的构建流程:
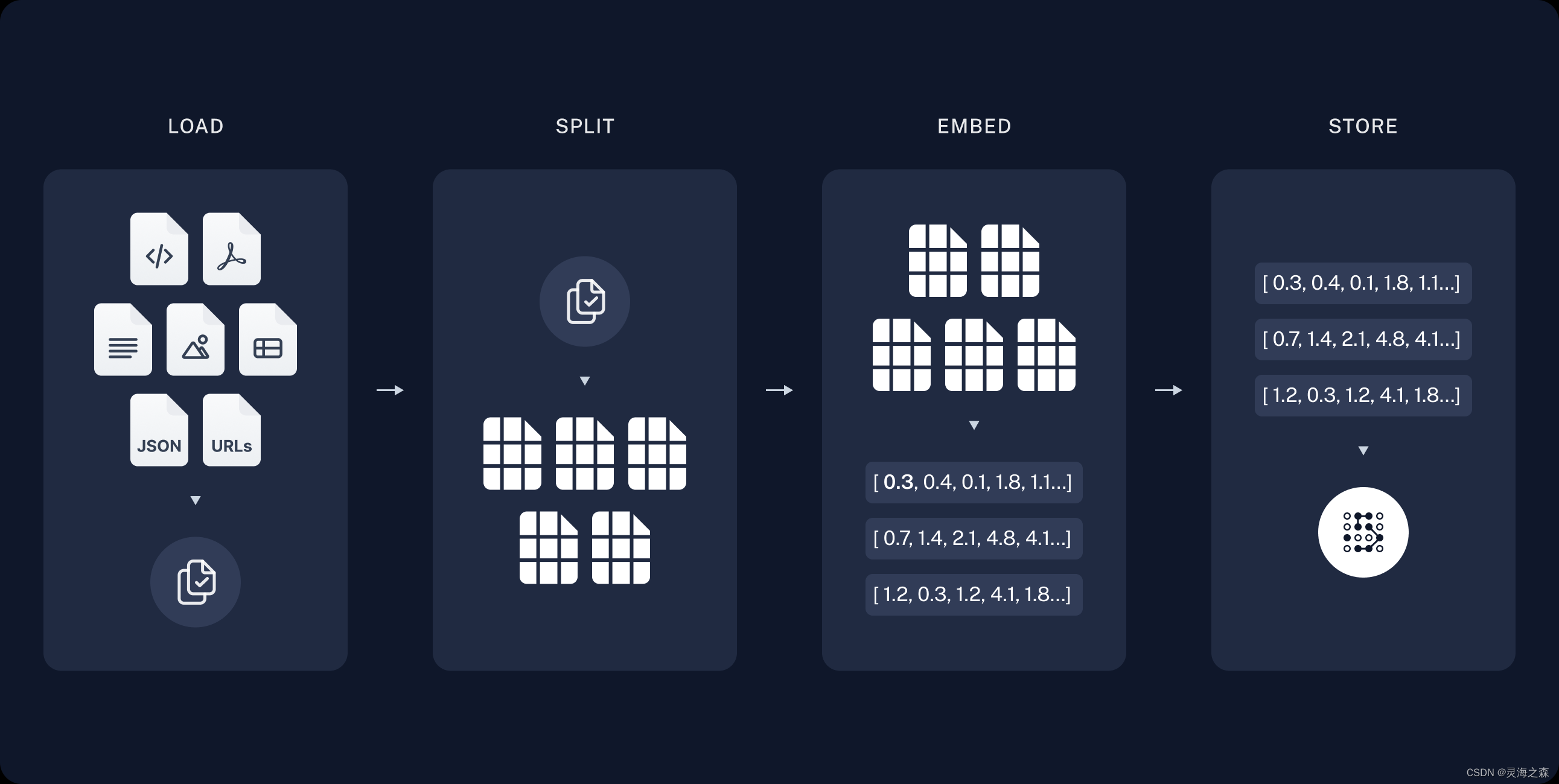
part1:indexing
1.数据读取:各种类型的数据都可以读取。
2.文档切分:因为一篇文档可能很大,模型的上下文窗口有限;用户query的答案一般只会在文档的某部分。
3.向量嵌入:文本向量化。
4.向量入库:将稠密向量存入向量数据库,如mivlus, Chroma,Faiss。个人觉得第一个最好,但是个人配置太麻烦,选择第二个。
part2:Retrieval and generation
1.检索:根据query从向量数据库中检索相关文档。
2.prompt增强:将召回的文档填入prompt作为外部知识。
3.生成:LLM基于增强的prompt生成回复。
part1:indexing
索引阶段,包含数据读取,切片,向量化,入库。
langchain提供了开发文档:https://python.langchain.com/docs/modules/data_connection/document_transformers/
数据读取
使用langchain_community.document_loaders,读取PDF,CSV文件。
from langchain_community.document_loaders.csv_loader