文章目录
前言
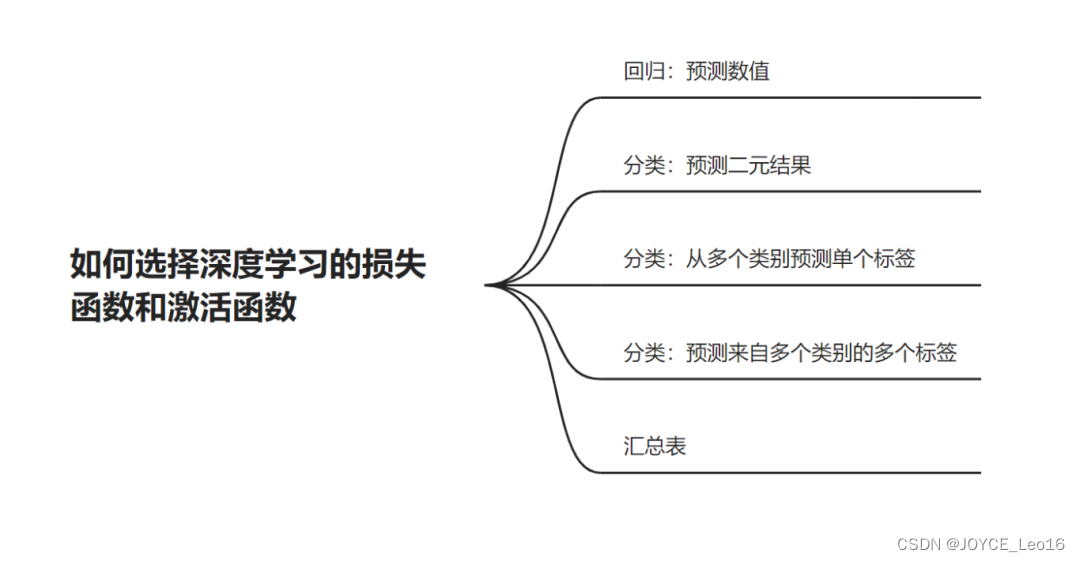
你需要解决什么问题?
你想预测数值吗?
你想预测分类结果吗?
回归:预测数值
分类:预测二元结果
分类:从多个类别中预测单个标签
分类:从多个类别中预测多个标签
总结表
前言
本篇博客的目的是根据业务目标,为大家提供关于在构建神经网络时,如何根据需求选择合适的最终层激活函数和损失函数的指导和建议。
如果大家还没了解激活函数,可以参考:神经元和激活函数介绍
你需要解决什么问题?
和所有机器学习一样,业务目标决定了你应该如何评估是否成功。

你想预测数值吗?
例如:预测产品的合适价格,或预测每天的销售数量。
如果是这样,你需要用到“回归:预测数值”部分的知识。
你想预测分类结果吗?
比如,你想知道图片中有什么物体,或者对话是关于什么主题的。
如果是的话,接下来你需要考虑你的数据中有多少种不同的类别,以及你想为每个项目找到多少个标签。
如果你的数据是二元的,也就是说,每个项目要么属于某个类别,要么不属于(比如判断是否为欺诈行为、诊断结果、是否可能购买),那么你需要用到“分类:预测二元结果”这部分的知识。
如果你的数据有多个类别(比如,图片中可能有多个物体,电子邮件涉及多个主题,或者多种产品适合进行宣传),而且每个项目只能属于一个类别,那么你需要用到“分类:从多个类别中预测单个标签”这部分的知识。
最后,如果你的数据中的每个项目可能属于多个类别,也就是说,每个项目可以有多个标签,那么你需要用到“分类:从多类别中预测多个标签”这部分的知识。
回归:预测数值
例如:预测产品的价格。
神经网络的最终层将有一个神经元,它返回的值是一个连续的数值。
为了了解预测的准确性,它会与真实值进行比较,真实值也是一个连续的数字。

最终激活函数
线性——这将产生一个我们需要的数值。

或 ReLU——这将产生一个大于0的数值。

损失函数
均方误差(MSE)——这计算了预测值与真实值之间的平均平方差。
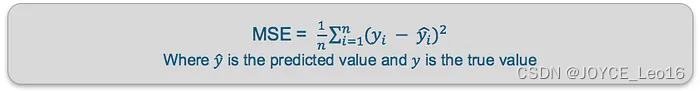
分类:预测二元结果
例如:预测一笔交易是否为欺诈。
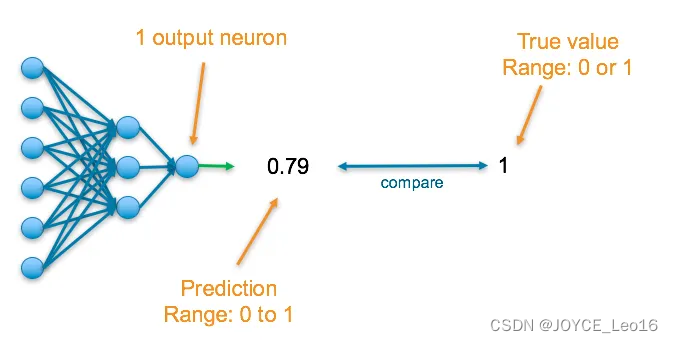
神经网络的最终层将有一个神经元,并返回一个介于0到1之间的值,这个值可以被推断为概率。
为了了解预测的准确性,它会与真实值进行比较。如果数据属于该类,真实值为1,否则为0。
最终激活函数
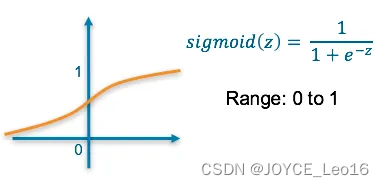
Sigmoid——这将产生一个介于0和1之间的值,我们可以推断出模型对示例属于该类别的信心程度。

损失函数
二元交叉熵——交叉熵量化了两个概率分布之间的差异。
我们的模型预测了一个模型分布 {p,1-p},因为我们有一个二元分布。
我们使用二元交叉熵来将其与真实分布 {y,1-y} 进行比较。

分类:从多个类别中预测单个标签
神经网络的最终层将为每个类别有一个神经元,并返回一个介于0和1之间的值,这个值可以被推断为概率。
输出结果随后形成一个概率分布,因为其总和为1。
为了了解预测的准确性,每个输出都会与其对应的真实值进行比较。
真实值已经过独热编码,这意味着在对应正确类别的列中会出现1,否则会出现0。

最终激活函数
Softmax——这将为每个输出产生介于0和1之间的值,这些值的总和为1。
所以这可以被推断为概率分布。

损失函数
交叉熵——交叉熵量化了两个概率分布之间的差异。我们的模型预测了一个模型分布 {p1,p2,p3}(其中p1+p2+p3=1)。
我们使用交叉熵来将其与真实分布 {y1,y2,y3}进行比较。

分类:从多个类别中预测多个标签
例如:预测图像中动物的存在。
神经网络的最终层将为每个类别有一个神经元,并返回一个介于0和1之间的值,这个值可以被推断为概率。
为了了解预测的准确性,每个输出都会与其对应的真实值进行比较。如果真实值列中出现1,则表示数据中存在它所对应的类别;否则会为0。

最终激活函数
Sigmoid——这将产生一个介于0和1之间的值,我们可以推断出模型对于某个实例属于该类别的信心程度。
损失函数
二元交叉熵——交叉熵量化了两个概率分布之间的差异。对于每个类别,我们的模型都会预测一个模型分布 {p,1-p}(二元分布)。
我们使用二元交叉熵来将这些与每个类别的真实分布 {y,1-y}进行比较,并汇总它们的结果。

总结
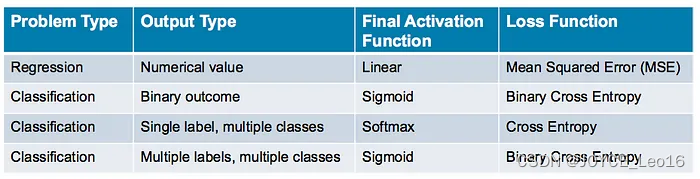
以下表格总结了上述信息,以便您能够快速找到适用于您用例的最终层激活函数和损失函数。
参考: 人工智能学习指南