概要:
使用Llama3 Langchain和ChromaDB创建一个检索增强生成(RAG)系统。这将允许我们询问有关我们的文档(未包含在训练数据中)的问题,而无需对大型语言模型(LLM)进行微调。在使用RAG时,首先要做一个检索步骤,从一个特殊的数据库中提取任何相关的文档,本文使用的是《欧盟人工智能法案》文本。
LLAMA3
Meta Llama 3是Meta股份有限公司开发的一系列模型,是最先进的新型模型,有8B和70B参数大小(预先训练或指导调整)。Llama3模型是用15T+(超过15万亿)tokens和800亿至700亿参数进行预训练和微调的,这使其成为强大的开源模型之一。这是对Llama2模型的高度改进。
结构
Meta Llama 3使用的token结构
- <|begin_of_text|>:这相当于BOS令牌
- <|eot_id|>:这表示消息依次结束。
- <|start_header_id|>{role}<|end_header_id |>:这些标记包含特定消息的角色。可能的角色可以是:系统、用户、助理。
- <|end_of_text|>:这相当于EOS令牌。生成此代币后,Llama 3将停止生成更多代币。
提示应包含单个系统消息,可以包含多个交替的用户和助手消息,并且始终以最后一条用户消息结尾,后跟助手标头。
结构样式
<|begin_of_text|>{{ user_message }}
Llama 3 的对话格式

- List item指定提示的开始
- 指定消息的角色,即“用户”
- 输入消息(来自“用户”)
- 指定输入消息的结尾
- 指定消息的角色,即“助理”
LLaMA模型的特点包括:
规模和效率:LLaMA模型设计为在保持较小模型尺寸的同时,实现与更大模型相似的性能。
多任务学习:这些模型通常在多种语言和任务上进行训练,以提高它们的通用性和跨领域的表现。
自注意力机制:LLaMA模型使用自注意力(self-attention)机制来处理长距离的依赖关系,这是现代大型语言模型的一个关键技术。
预训练和微调:它们通常首先在大量文本数据上进行预训练,然后针对特定任务进行微调。
可扩展性:设计时考虑到了模型的可扩展性,使其能够通过增加参数数量来提升性能。
研究和开源:Meta可能会将这些模型用于研究目的,并且可能会开源部分或全部模型,以便学术界和工业界可以使用和进一步研究。
RAG
大型语言模型(LLM)已经证明了它们理解上下文并在提示时为各种NLP任务提供准确答案的能力,包括摘要、问答。虽然他们能够很好地回答有关他们所接受训练的信息的问题,但当话题是关于他们“不知道”的信息时,即没有包括在他们的训练数据中时,他们往往会产生幻觉。检索增强生成将外部资源与LLM相结合。因此,RAG的主要两个组成部分是检索器和生成器。
代码实现
加载依赖
import sys #sys模块提供了与Python解释器和操作系统底层进行交互的功能。
from torch import cuda, bfloat16
import torch
import transformers
from transformers import AutoTokenizer
from time import time
#import chromadb
#from chromadb.config import Settings
from langchain.llms import HuggingFacePipeline #huggingface 管道
from langchain.document_loaders import PyPDFLoader #python 加载
from langchain.text_splitter import RecursiveCharacterTextSplitter #分词
from langchain.embeddings import HuggingFaceEmbeddings #矢量化
from langchain.chains import RetrievalQA #构建对话系统
from langchain.vectorstores import Chroma #Chroma 向量数据库
加载模型
#加载本地模型
model_id = 'D:\临时模型\Meta-Llama-3-8B-Instruct'
#设定使用cpu 还是gpu
device = f'cuda:{cuda.current_device()}' if cuda.is_available() else 'cpu'# 设置量化配置以加载GPU内存较少的大型模型
# 这需要“bitsandbytes”库
# 模型量化
bnb_config = transformers.BitsAndBytesConfig(load_in_4bit=True, # 指定以 4 位精度加载模型bnb_4bit_quant_type='nf4', # 选择使用 NF4(Normal Float 4)数据类型bnb_4bit_use_double_quant=True,# 启用嵌套量化bnb_4bit_compute_dtype=bfloat16 #更改计算期间将使用的数据类型 16位浮点数据类型
)print(device)
模型实例化
time_start = time()#AutoConfig.from_pretrained 根据预训练模型的名称或路径创建配置对象 模型配置文件
model_config = transformers.AutoConfig.from_pretrained(model_id,#模型路径trust_remote_code=True,#默认情况下,trust_remote_code 设置为 True。这意味着使用 from_pretrained() 方法加载模型配置文件时,它将下载来自 Hugging Face 模型中心或其他在线资源的配置文件。max_new_tokens=1024 #新生成令牌的数量
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 设置 pad_token_id 为 eos_token_id 的值
#pad_token_id = tokenizer.eos_token_id #指定填充标记(pad_token)使用结束标记(eos_token)# AutoModelForCausalLM 加载自动模型因果语言模型
model = transformers.AutoModelForCausalLM.from_pretrained(model_id,#模型的名称或地址trust_remote_code=True,#信任的存储库设置为Trueconfig=model_config, #加载配置文件quantization_config=bnb_config,#加载模型量化device_map='auto',#使用cpu 或GPU
)time_end = time()
print(f"Prepare model, tokenizer: {round(time_end-time_start, 3)} sec.")
构建管道
time_start = time()
#构建管道
query_pipeline = transformers.pipeline("text-generation",#文本生成管道model=model,#模型加载tokenizer=tokenizer,#tokan加载torch_dtype=torch.float16,max_length=1024,#最大长度1024device_map="auto",)
time_end = time()
print(f"Prepare pipeline: {round(time_end-time_start, 3)} sec.")
测试没有RAG的回答
#在没有RAG的情况下进行测试
def test_model(tokenizer, pipeline, message):time_start = time()sequences = pipeline(message,#输入的提示do_sample=True,#模型将生成确定性的输出,即在给定输入的情况下,每次运行都会产生相同的结果top_k=10,#模型将只考虑概率最高的10个词汇 top_k通常与另一个参数top_p一起使用,top_p也用于控制生成过程中的随机性。top_p是累积概率阈值,它考虑了概率最高的词汇,直到累积概率达到或超过这个阈值。num_return_sequences=1,#对于给定的输入,生成模型将只产生一个输出序列。eos_token_id=tokenizer.eos_token_id,pad_token_id = tokenizer.eos_token_id,max_length=1000,)#这里输出需要足够大time_end = time()total_time = f"{round(time_end-time_start, 3)} sec."question = sequences[0]['generated_text'][:len(message)]answer = sequences[0]['generated_text'][len(message):]return f"Question: {question}\nAnswer: {answer}\nTotal time: {total_time}"
信息美化
#`Markdown` 类是 IPython 提供的一个工具,用于将字符串格式化为 Markdown 格式的文本。
#`display` 函数用于在 Notebook 中显示对象。它能够自动选择最合适的显示方式,
from IPython.display import display, Markdown#数据回复样式
def colorize_text(text):for word, color in zip(["Reasoning", "Question", "Answer", "Total time"], ["blue", "red", "green", "magenta"]):text = text.replace(f"{word}:", f"\n\n**<font color='{color}'>{word}:</font>**")return text
演示
#演示
response = test_model(tokenizer,query_pipeline,"Please explain what is EU AI Act.")
display(Markdown(colorize_text(response)))
这里只是部分回复的内容

#测试
response = test_model(tokenizer,query_pipeline,"In the context of EU AI Act, how is performed the testing of high-risk AI systems in real world conditions?")
display(Markdown(colorize_text(response)))

hugging face 管道构建
query_pipeline = transformers.pipeline("text-generation",#文本生成管道model=model,#模型加载tokenizer=tokenizer,#tokan加载torch_dtype=torch.float16,max_length=1024,#最大长度1024device_map="auto",eos_token_id=tokenizer.eos_token_id,pad_token_id = tokenizer.eos_token_id,
)#转换成 huggingface 的管道
llm = HuggingFacePipeline(pipeline=query_pipeline,# 再次检查是否一切正常
time_start = time()
question = "Please explain what EU AI Act is."
response = llm(prompt=question)
time_end = time()
total_time = f"{round(time_end-time_start, 3)} sec."
full_response = f"Question: {question}\nAnswer: {response}\nTotal time: {total_time}"
display(Markdown(colorize_text(full_response))) )
返回

开始构建RAG
数据加载与切分
#数据加载
loader = PyPDFLoader("./aiact_final_draft.pdf")
documents = loader.load()#数据切分实例化
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
#切分加载的数据
all_splits = text_splitter.split_documents(documents)model_name = "G:\hugging_fase_model2\all-mpnet-base-v2"#加载向量模型
model_kwargs = {"device": "cuda"}# 加载embedings 向量模型
try:embeddings = HuggingFaceEmbeddings(model_name=model_name, model_kwargs=model_kwargs)
except Exception as ex:print("Exception: ", ex)# 加载本地模型#local_model_path = r"G:\hugging_fase_model\all-MiniLM-L6-v2"#local_model_path =r'E:\hugging_face_embeding\bert-base-uncased'local_model_path ='all-MiniLM-L6-v2'print(f"Use alternative (local) model: {local_model_path}\n")embeddings = HuggingFaceEmbeddings(model_name=local_model_path, model_kwargs=model_kwargs)
all-mpnet-base-v2
all-mpnet-base-v2 是一个基于sentence-transformers库的预训练模型,它专门设计用于处理句子和段落级别的文本,并将其映射到一个768维的密集向量空间。这个模型可以用于多种自然语言处理任务,包括但不限于聚类(clustering)和语义搜索(semantic search)。
以下是关于all-mpnet-base-v2模型的一些关键点:
-
向量空间映射:该模型将输入的文本(句子或段落)转换成一个768维的向量,这个向量能够捕捉文本的语义信息。
-
使用简便:如果已经安装了sentence-transformers库,使用这个模型将变得非常简单。用户可以通过几行代码加载模型并生成文本的嵌入表示。
-
预训练和微调:all-mpnet-base-v2模型基于microsoft/mpnet-base进行预训练,然后在超过10亿句子对的数据集上进行微调。
-
自监督学习:在微调阶段,该模型使用对比学习目标,通过计算批次中可能的句子对之间的余弦相似度,并应用交叉熵损失来优化模型。
-
训练细节:模型在TPU v3-8上训练了100,000步,使用1024的批量大小,序列长度限制为128个标记,采用AdamW优化器,学习率为2e-5,并应用了学习率预热。
-
多任务应用:生成的向量可以用于信息检索、文本聚类或句子相似性任务,适用于商业应用、学术研究、语言理解和生成等多个领域。
-
模型性能:all-mpnet-base-v2模型在多个自然语言处理任务中表现出色,包括语义相似度计算、实体关系抽取和文本分类等。
-
资源消耗:相比于更高维度的模型,all-mpnet-base-v2生成的768维向量占用的存储空间更少,这使得它在资源有限的环境中更为实用。
all-MiniLM-L6-v2
all-MiniLM-L6-v2 是一个由sentence-transformers库提供的预训练模型,专门设计用于生成句子和段落的嵌入表示(embeddings)。这个模型能够将文本映射到一个384维的密集向量空间,这些向量可以用于多种下游任务,如聚类(clustering)、语义搜索(semantic search)等。
以下是关于all-MiniLM-L6-v2模型的一些关键特点:
-
文本嵌入:模型接收句子或段落作为输入,并输出一个固定大小的向量,该向量捕捉了输入文本的语义信息。
-
使用简便:如果已经安装了sentence-transformers库,使用这个模型将变得非常容易。用户可以通过简单的代码调用模型并生成文本的嵌入表示。
-
预训练和微调:all-MiniLM-L6-v2模型基于MiniLM架构,并在超过10亿句子对的数据集上进行了微调。
-
自监督学习:在微调阶段,该模型使用对比学习目标,通过计算批次中句子对的余弦相似度,并应用交叉熵损失来优化模型。
-
向量空间映射:模型将句子映射到向量空间中,使得语义相似的句子在该空间中距离较近,这有助于执行语义搜索和相似性计算。
-
多任务应用:生成的向量可以用于多种NLP任务,如信息检索、文本聚类或句子相似性评估等。
-
环境要求:使用all-MiniLM-L6-v2模型需要有适当的Python环境和必要的库,如PyTorch和Transformers。
-
资源消耗:相比于更高维度的模型,all-MiniLM-L6-v2生成的384维向量占用的存储空间更少,这使得它在资源有限的环境中更为实用。
-
开源和社区支持:all-MiniLM-L6-v2模型是开源的,并且得到了活跃的社区支持,用户可以从Hugging Face模型库中轻松下载和使用。
向量搜索
#灌库
vectordb = Chroma.from_documents(documents=all_splits, embedding=embeddings, persist_directory="chroma_db")#矢量化搜索
#将一个查询向量检索器(retriever)集成到向量数据库中。
#将查询向量与数据库中的向量进行比较,以找到最相似的数据条目
retriever = vectordb.as_retriever()#构建对提问对话系统
qa = RetrievalQA.from_chain_type(llm=llm, #加载实例化模型#使用“stuff”链的优势在于能够综合利用多个文档中的信息,从而提高系统对问题的理解和回答的准确性。然而,它也可能导致信息的冗余和噪音,需要在实际应用中进行权衡和调整。chain_type="stuff", #`chain_type`参数指定用于组合检索到的文档的链的类型。使用stuff”链将检索到的文档连接在一起并将它们作为单个输入传递给LLMretriever=retriever, #加载检索的信息verbose=True,#`verbose是一个布尔标志,当设置为True时,它将导致RetrievalQA实例打印出有关其操作的其他信息。
)
测试
# 测试
def test_rag(qa, query):time_start = time()#用run 方法执行response = qa.run(query)time_end = time()#查看耗时total_time = f"{round(time_end-time_start, 3)} sec."full_response = f"Question: {query}\nAnswer: {response}\nTotal time: {total_time}"#美化输出display(Markdown(colorize_text(full_response)))query = "How is performed the testing of high-risk AI systems in real world conditions?"
test_rag(qa, query)

query = "What are the operational obligations of notified bodies?"
test_rag(qa, query)

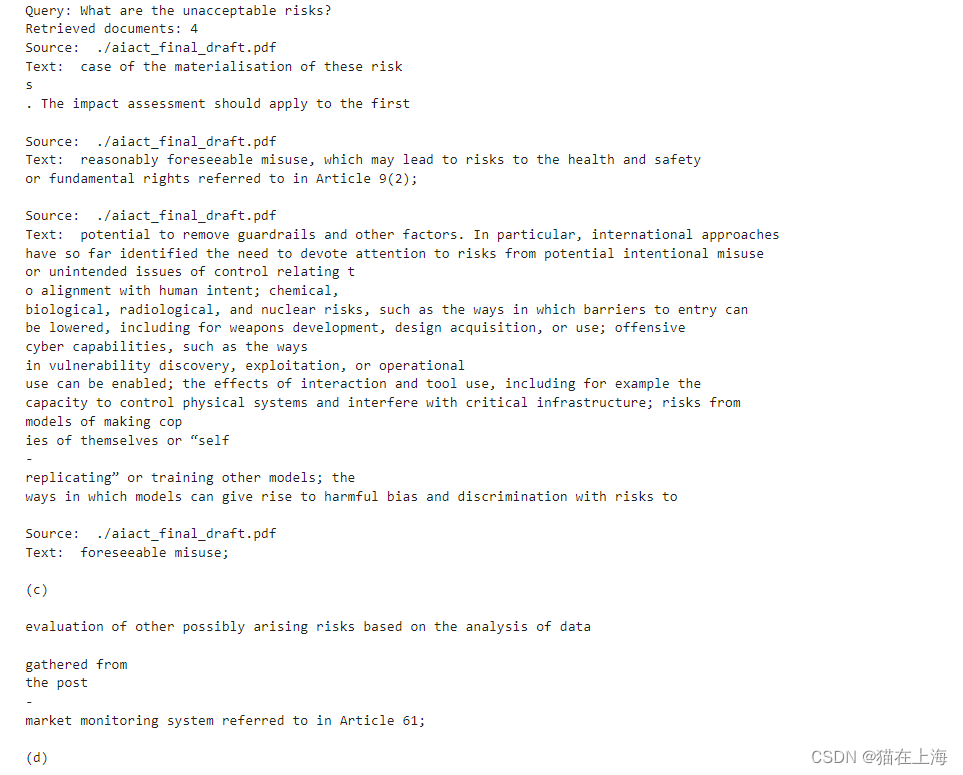
用相似性搜索方法来查找文档
#用相似性搜索方法来查找文档
docs = vectordb.similarity_search(query)
"""
# K=3用于指定返回的文档数量
docs = vectordb.similarity_search(question,k=3)
"""
print(f"Query: {query}")
print(f"Retrieved documents: {len(docs)}")
for doc in docs:doc_details = doc.to_json()['kwargs']print("Source: ", doc_details['metadata']['source'])print("Text: ", doc_details['page_content'], "\n")
以上是文本的全部内容,感谢阅读。