一、介绍
1.1 文本摘要简介
文本摘要(Text Summarization),作为自然语言处理(NLP)领域的一个分支,其核心目标是从长篇文档中提取关键信息,并生成简短的摘要,以提供对原始内容的高度概括。这一过程不仅有助于用户迅速把握信息的核心,而且对于有效组织和归纳大量的文本数据至关重要。
文本摘要的任务可以根据不同的输入和输出进行分类。首先,根据输入文档的数量,可以将摘要任务分为单文档摘要和多文档摘要。单文档摘要专注于处理单个文档,而多文档摘要则需要整合多个相关文档的信息。其次,根据输入和输出的语言,摘要任务可以分为单语言摘要、跨语言摘要和多语言摘要。在本课程中,我们将重点关注单文档单语言摘要,即处理单个文档并以同一种语言生成摘要。
在单文档单语言摘要中,系统需要理解文档的语义和结构,并从中提取最重要的信息,然后以简洁明了的方式呈现给用户。这个过程涉及对文本的理解、分析和重构,要求模型能够准确捕捉文档的主要观点,同时保持信息的完整性。
1.2 T5简介
T5(Text-to-Text Transfer Transformer)是一种基于Transformer架构的文本到文本的预训练语言模型领域的通用模型,由Google Research开发。T5模型的主要特点是将文本生成任务视为一种文本到文本的转换,这使得它可以被广泛应用于多种文本生成任务,如文本摘要、机器翻译、问答系统、文本生成等。
T5模型通过预训练来学习文本的通用表示,这使得它在下游任务中能够快速适应并表现出色。预训练的过程包括在大规模文本数据上进行自监督学习,模型通过预测文本中的缺失部分来学习文本的表示。
T5模型的一个重要特点是它采用了统一的编码器-解码器架构,这意味着它可以在多种文本生成任务中使用相同的模型,只需调整模型的输入和输出即可。这种统一的架构使得T5模型在各种文本生成任务中表现出了强大的通用性和灵活性。
T5模型的另一个特点是它采用了简单的任务提示(Task Prompt)技术,通过在输入文本中添加一些简单的提示词,如“摘要:”、“翻译:”等,来指导模型生成相应的文本。这种方法可以有效地提高模型的生成质量,并且可以很容易地应用于不同的文本生成任务。
总的来说,T5模型是一种强大的文本到文本的预训练模型,它在多种文本生成任务中都表现出了出色的性能。随着研究的不断深入,T5模型有望在未来的文本生成任务中发挥更大的作用。
1.3 Seq2Seq
序列到序列(Seq2Seq)模型是一种用于处理序列数据的神经网络模型,它由两个主要部分组成:编码器(Encoder)和解码器(Decoder)。这种模型通常用于机器翻译、语音识别、文本摘要等任务
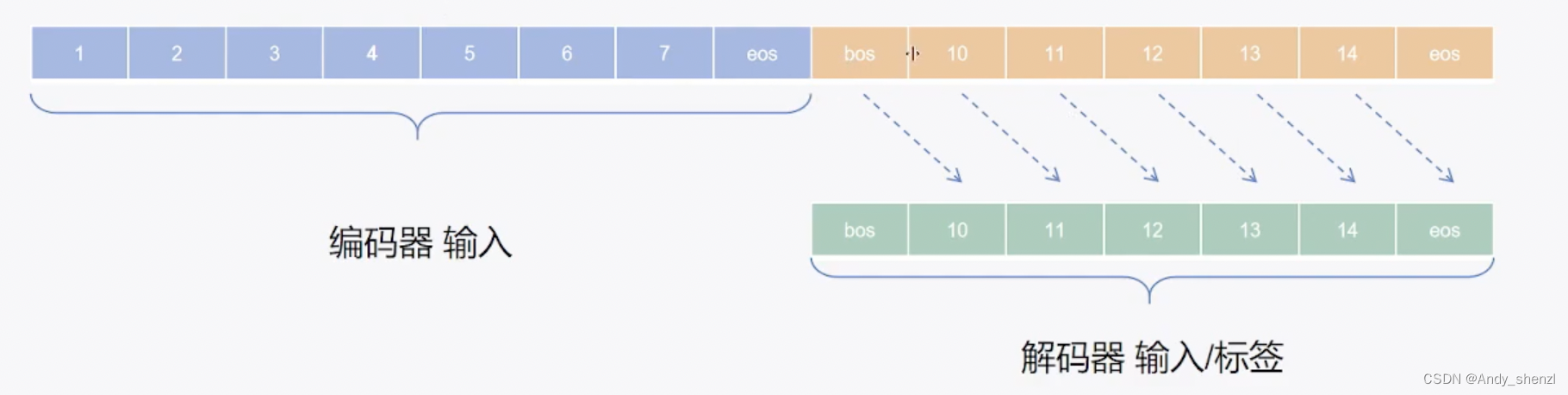
- 数据处理:在序列到序列模型的数据预处理阶段,我们需要将输入数据(input)和标签数据(labels)分开处理。例如,我们可以有一个文本数据集,其中每一行代表一个样本,第一列是输入数据,后续列是该样本的标签。
- 标签处理:在实际应用中,标签不仅仅是分类的结果,它们还可以包含更多的信息,如情感分析中的正面、负面和中性
- 情绪,或者是机器翻译中的源语言和目标语言等。这些额外的信息对于模型的学习和泛化非常重要。
- 编码和解码器结构:在序列到序列模型的架构设计中,编码器和解码器通常采用相同的结构,但它们的用途不同。编码器负责将输入数据转换为一个表示,而解码器则使用这个表示来生成相应的输出。这种对称的结构有助于提高模型的效率和可扩展性。
- 注意力机制:在某些序列到序列模型中,如Transformer模型,注意力机制被用来关注输入数据的不同部分,从而捕捉长距离依赖关系。这有助于模型更好地理解上下文,尤其是在处理自然语言时。
- 优化算法:为了训练序列到序列模型,我们通常会使用梯度下降或其他优化算法来更新模型参数。在这个过程中,我们需要考虑如何有效地计算梯度和选择合适的 learning rate 等超参数。
- 评估指标:在评估序列到序列模型的性能时,常用的指标包括 BLEU(Bilingual Evaluation Understudy)、ROUGE(Recall-Oriented Understudy for Gisting Evaluation)和 CIDEr(Cascade Intersection over Union)。这些指标可以帮助我们了解模型生成文本的质量。
1.4 评价指标
评价指标包括Rouge,具体又分为Rouge-1、Rouge-2、Rouge-L,它们分别基于1-gram、2-gram、LCS。
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)是一种用于自动评估文本摘要质量的指标,它主要关注召回率(Recall)和F1分数。ROUGE-1、ROUGE-2和ROUGE-L是ROUGE的不同变体,它们分别计算不同长度的匹配项。
以下是计算ROUGE-1、ROUGE-2和ROUGE-L的基本步骤:
- ROUGE-1:计算1-gram(单字词)的匹配项。
- ROUGE-2:计算2-gram(双字词)的匹配项。
- ROUGE-L:计算最长公共子序列(Longest Common Subsequence, LCS)的匹配项。
计算公式如下:
ROUGE-1
- Precision §: 匹配到的1-gram数量 / 生成的1-gram总数
- Recall ®: 匹配到的1-gram数量 / 参考的1-gram总数
- F1 Score: 2 * P * R / (P + R)
ROUGE-2
- Precision §: 匹配到的2-gram数量 / 生成的2-gram总数
- Recall ®: 匹配到的2-gram数量 / 参考的2-gram总数
- F1 Score: 2 * P * R / (P + R)
ROUGE-L
- Precision §: LCS匹配到的1-gram数量 / 生成的1-gram总数
- Recall ®: LCS匹配到的1-gram数量 / 参考的1-gram总数
- F1 Score: 2 * P * R / (P + R)
其中,LCS匹配是指在生成文本和参考文本之间找到的最长公共子序列。
示例
假设我们有一个生成的摘要和一个参考摘要,我们想要计算ROUGE-1、ROUGE-2和ROUGE-L。
生成摘要:今天不错
参考摘要:今天天气不错
- ROUGE-1
- 生成的1-gram:今天, 不, 错
- 参考的1-gram:今天, 天气, 不, 错
- P: 4/4
- R: 4/6
- F1: 2 * 4/4 * 4/6 / (4/4 + 4/6)
- ROUGE-2
- 生成的2-gram:今天不错, 不错今天
- 参考的2-gram:今天天气, 天气不错, 不错天气
- P: 2/3
- R: 2/5
- F1: 2 * 2/3 * 2/5 / (2/3 + 2/5)
- ROUGE-L
- 生成的1-gram:今天, 不, 错
- 参考的1-gram:今天, 天气, 不, 错
- P: 4/4
- R: 4/6
- F1: 2 * 4/4 * 4/6 / (4/4 + 4/6)
请注意,这些计算是基于示例文本进行的,实际应用中可能需要更复杂的数据处理和计算。在实际使用ROUGE时,通常会使用专门的ROUGE工具来进行计算,而不是手动计算。
二、实战
2.1 下载数据集
常见的数据集
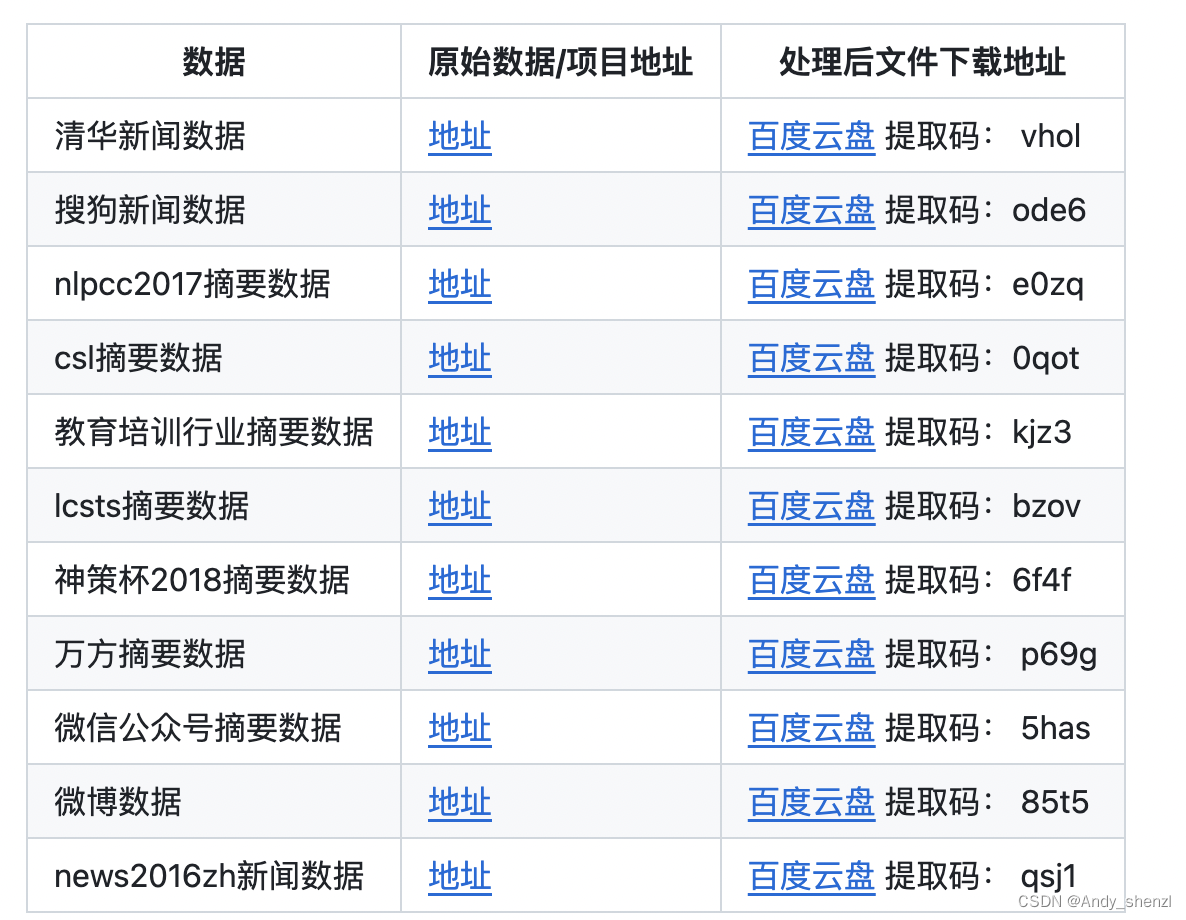
我们使用的是lcsts摘要数据:
lcsts摘要数据是哈尔滨工业大学整理,基于新闻媒体在微博上发布的新闻摘要创建了该数据集,每篇短文约100个字符,每篇摘要约20个字符。
整理后数据信息如下:
总数量:2108915个样本;
摘要:平均字数 18,字数标准差 5,最大字数 30,最小数字 4;
正文:平均字数 104,字数标准差 10,最大字数 152,最小数字 69;
sum_datasets = load_dataset("hugcyp/LCSTS")
sum_datasets
DatasetDict({train: Dataset({features: ['summary', 'text'],num_rows: 2400591})validation: Dataset({features: ['summary', 'text'],num_rows: 8685})test: Dataset({features: ['summary', 'text'],num_rows: 725})
})
数据集太大了,所以我们做一个简单的
sum_datasets = load_dataset("hugcyp/LCSTS",split="train[:10000]")
sum_datasets = sum_datasets.train_test_split(test_size=0.2)
sum_datasets
DatasetDict({train: Dataset({features: ['summary', 'text'],num_rows: 8000})test: Dataset({features: ['summary', 'text'],num_rows: 2000})
})
查看数据
sum_datasets["train"][0]
{'summary': '美国学生如何吐槽第一夫人的营养餐?','text': '在米歇尔强力推动下,美国国会通过了法案,要求学生午餐必须包括一份水果或蔬菜,并设定了卡路里的上限。从此美国学校饭堂出现了各种奇葩的“达标”午餐(如下图),譬如用番茄酱来代替水果,引发学生吐槽。'}2.2 数据预处理
在hugging face中找一个T5Chinese的模型试一下
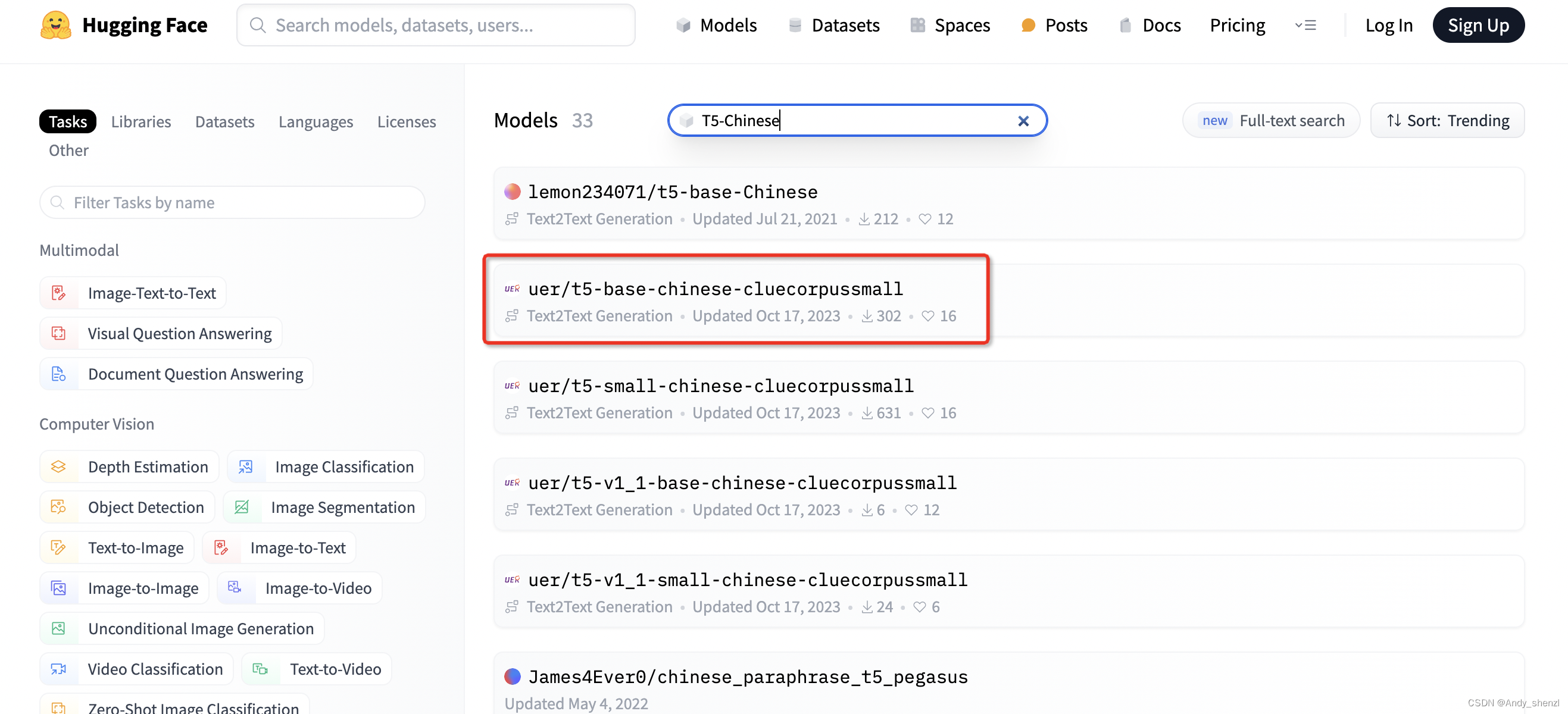
tokenizer = AutoTokenizer.from_pretrained("uer/t5-base-chinese-cluecorpussmall")def process_func(exmaples):contents = ["摘要生成: \n" + e for e in exmaples["text"]]inputs = tokenizer(contents, max_length=384, truncation=True)labels = tokenizer(text_target=exmaples["summary"], max_length=64, truncation=True)inputs["labels"] = labels["input_ids"]return inputs
这段代码是一个函数,名为process_func,它的目的是处理输入的数据,以便用于训练一个序列到序列(Seq2Seq)模型。在这个函数中,它接受一个字典exmaples作为输入,该字典包含原始文本"text"和对应的摘要"summary"。
函数的步骤如下:
- 生成摘要生成提示:使用列表推导式,遍历
exmaples["text"]列表,为每个文本生成一个摘要生成提示。提示的格式为"摘要生成: \n"加上文本内容。 - 分词:使用分词器
tokenizer对生成的内容列表进行分词。这里设置了max_length=384和truncation=True,这意味着分词器将尝试将每个内容分词后的序列长度限制在384个token以内,如果超过这个长度,则进行截断。 - 生成输入:将分词后的内容列表转换为模型可以理解的格式,即整数序列。这个整数序列将作为模型的输入。
- 生成标签:使用分词器
tokenizer对exmaples["summary"]进行分词。这里同样设置了max_length=64和truncation=True,确保摘要分词后的序列长度不超过64个token。 - 设置标签:将摘要分词后的整数序列作为模型的标签,并将其添加到输入字典
inputs中。 - 返回处理后的数据:函数返回包含分词后的输入和标签的
inputs字典,这些数据可以被模型用于训练。
总的来说,这个函数将原始文本和摘要转换为模型可以处理的整数序列格式,并为模型提供了输入和标签,以便于训练。
tokenized_ds = sum_datasets.map(process_func, batched=True)
tokenized_ds
DatasetDict({train: Dataset({features: ['summary', 'text', 'input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 8000})test: Dataset({features: ['summary', 'text', 'input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 2000})
})
print(tokenized_ds["train"][0]){'summary': '新民评论:罚丁书苗25亿意义深远', 'text': '加大对行贿者的惩治力度,应当以人身处罚和财产处罚并重,让行贿者把非法获利“吐”出来,防止“一人坐牢,全家享福”的不正常现象。对丁书苗案的判决,能否在刑法修订、行贿成本有望提高的背景之下,成为一个具有典型意义的判例,令人期待。', 'input_ids': [101, 3036, 6206, 4495, 2768, 131, 1217, 1920, 2190, 6121, 6594, 5442, 4638, 2674, 3780, 1213, 2428, 8024, 2418, 2496, 809, 782, 6716, 1905, 5385, 1469, 6568, 772, 1905, 5385, 2400, 7028, 8024, 6375, 6121, 6594, 5442, 2828, 7478, 3791, 5815, 1164, 100, 1402, 100, 1139, 3341, 8024, 7344, 3632, 100, 671, 782, 1777, 4286, 8024, 1059, 2157, 775, 4886, 100, 4638, 679, 3633, 2382, 4385, 6496, 511, 2190, 672, 741, 5728, 3428, 4638, 1161, 1104, 8024, 5543, 1415, 1762, 1152, 3791, 934, 6370, 510, 6121, 6594, 2768, 3315, 3300, 3307, 2990, 7770, 4638, 5520, 3250, 722, 678, 8024, 2768, 711, 671, 702, 1072, 3300, 1073, 1798, 2692, 721, 4638, 1161, 891, 8024, 808, 782, 3309, 2521, 511, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], 'labels': [101, 3173, 3696, 6397, 6389, 8038, 5385, 672, 741, 5728, 8132, 783, 2692, 721, 3918, 6823, 102]}
2.3 创建模型
model = AutoModelForSeq2SeqLM.from_pretrained("uer/t5-base-chinese-cluecorpussmall")
2.4 创建评估函数
!pip install rouge_chineseimport numpy as np
from rouge_chinese import Rougerouge = Rouge()def compute_metric(evalPred):predictions, labels = evalPreddecode_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)labels = np.where(labels != -100, labels, tokenizer.pad_token_id)decode_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)decode_preds = [" ".join(p) for p in decode_preds]decode_labels = [" ".join(l) for l in decode_labels]scores = rouge.get_scores(decode_preds, decode_labels, avg=True)return {"rouge-1": scores["rouge-1"]["f"],"rouge-2": scores["rouge-2"]["f"],"rouge-l": scores["rouge-l"]["f"],}
这段代码的目的是计算ROUGE(Recall-Oriented Understudy for Gisting Evaluation)分数,这是一种用于评估文本摘要质量的指标。
函数的步骤如下:
- 导入库:首先,导入了
numpy和rouge_chinese库。numpy是一个用于科学计算的库,而rouge_chinese是一个用于计算中文文本ROUGE分数的库。 - 创建ROUGE实例:使用
Rouge()创建了一个Rouge对象,这通常是一个计算ROUGE分数的函数或类。 - 定义函数:函数
compute_metric接受一个评估预测(evalPred)作为输入。 - 解码预测和标签:使用分词器
tokenizer批量解码预测(predictions)和标签(labels)。skip_special_tokens=True参数确保了在解码过程中特殊标记(如<sos>和<eos>)被忽略。 - 处理标签:将标签中的
-100替换为分词器的pad_token_id,以确保标签长度与预测长度一致。 - 批量解码标签:使用分词器批量解码标签,以便与预测进行比较。
- 拼接解码后的预测和标签:将解码后的预测和标签拼接成字符串,以便进行ROUGE计算。
- 计算ROUGE分数:使用
rouge.get_scores()函数计算ROUGE-1、ROUGE-2和ROUGE-L的分数。avg=True参数表示计算平均分数。 - 返回ROUGE分数:函数返回一个字典,其中包含ROUGE-1、ROUGE-2和ROUGE-L的F1分数。
2.5 创建训练器
args = Seq2SeqTrainingArguments(output_dir="./summary",per_device_train_batch_size=4,per_device_eval_batch_size=8,gradient_accumulation_steps=8,logging_steps=8,evaluation_strategy="steps",eval_steps=200,save_strategy="epoch",metric_for_best_model="rouge-l",predict_with_generate=True,report_to=['tensorboard']
)
因为训练速度比较慢,我们根据step打印一次预测结果
2.6 训练模型
trainer = Seq2SeqTrainer(args=args,model=model,train_dataset=tokenized_ds["train"],eval_dataset=tokenized_ds["test"],compute_metrics=compute_metric,tokenizer=tokenizer,data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer)
)trainer.train()
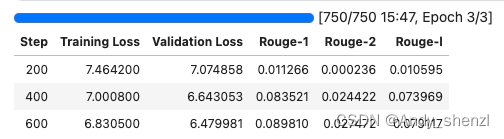
TrainOutput(global_step=750, training_loss=7.258201690673828, metrics={'train_runtime': 948.8402, 'train_samples_per_second': 25.294, 'train_steps_per_second': 0.79, 'total_flos': 3313311337635840.0, 'train_loss': 7.258201690673828, 'epoch': 3.0})效果很差,虽然我们训练的次数比较少,但是这个效果还是不能接受的,原因很有可能是我们的模型选的有问题,我们重新选一个模型在测试一下
。
重新选择一个模型,选择搜索出来的第一个试一下
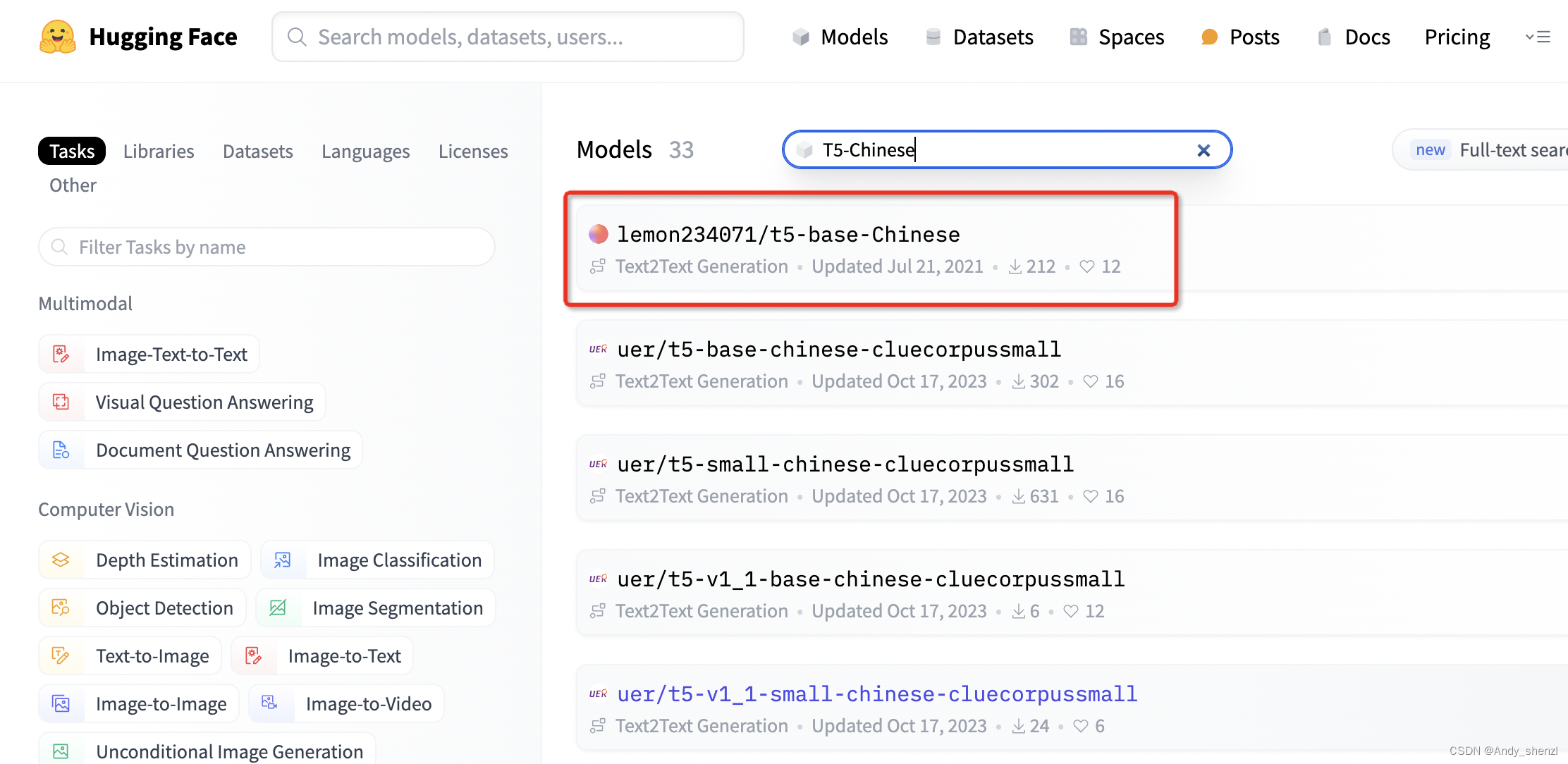
tokenizer = AutoTokenizer.from_pretrained("lemon234071/t5-base-Chinese")
model = AutoModelForSeq2SeqLM.from_pretrained("lemon234071/t5-base-Chinese")
trainer.train()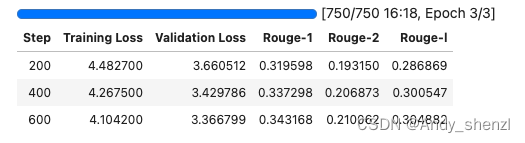
TrainOutput(global_step=750, training_loss=4.802234703063965, metrics={‘train_runtime’: 979.7099, ‘train_samples_per_second’: 24.497, ‘train_steps_per_second’: 0.766, ‘total_flos’: 2839954114953216.0, ‘train_loss’: 4.802234703063965, ‘epoch’: 3.0})
这个明显好了很多
2.7 预测
from transformers import pipeline
pipe = pipeline("text2text-generation", model=model, tokenizer=tokenizer, device=0)pipe("摘要生成:\n" + sum_datasets["test"][10]["text"], max_length=64, do_sample=True)
[{'generated_text': '<extra_id_0>海口首条水上巴士航线试运行'}]
sum_datasets["test"][10]["summary"]'海口首条水上巴士将启航航线从万绿园至西秀海滩'其实生成的效果不是很好,还需要多训练几轮,因为现在的loss还是比较大,而且Rouge-1才0.3
完整代码