本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
- 引言
- 业务案例
- Presto
- Spark
- XStream
- Distributed messaging system
- Data Ingestion
- Data Preprocessing
- Feature Engineering
- 组件
- Type System
- Vectors
- Expression Eval
- Functions
- Operators
- Memory Management
- 性能
- 结束语
引言
在《从一到无穷大 #25 DataFusion:可嵌入,可扩展的模块化工业级计算引擎实现》 [12]中我基于sigmod2024的一篇Industry paper介绍了DataFusion的大体架构。
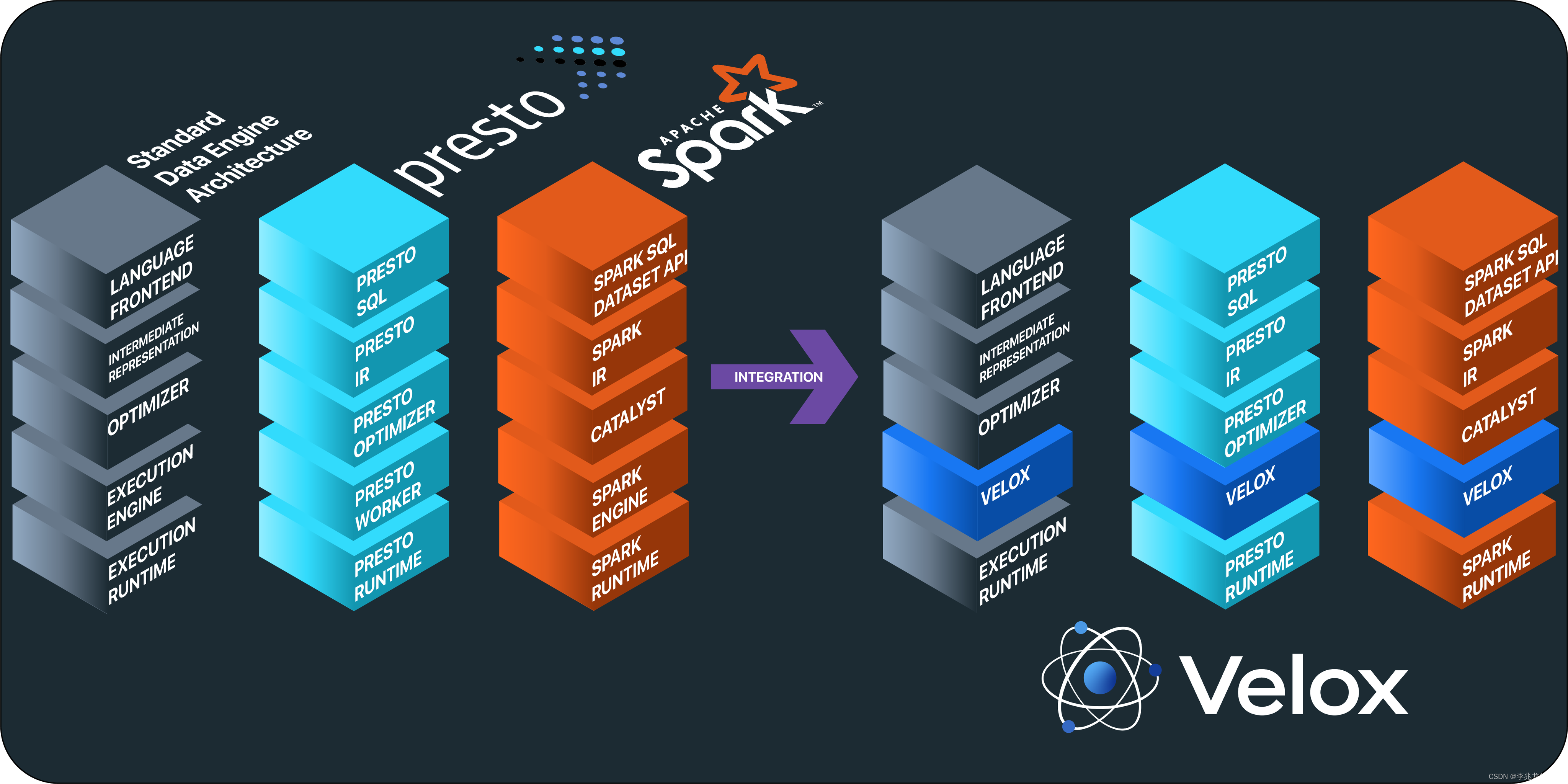
DataFusion和Velox的初衷一致,均为用单一模块化的执行引擎来减少重新实现计算模块的额外人力开销(专业的事情交给专业的人来做)。但是定位却存在不同,DataFusion是一个不折不扣的计算引擎,Front End,逻辑计划优化,执行计划优化,执行引擎一把抓;而Velox则聚焦于高效的实现执行引擎,输入为优化后的逻辑计划。
上篇文章中我提到我们内部系统计算层实现事实上是完全自研的,重新实现一套这个领域这么多年的优化经验以及随着业界理论发展逐步迭代计算引擎是不现实的。于我们团队的需求来说,我们希望可以在cpp代码中使用一个开源成熟的计算引擎/执行引擎(而不是像Presto/Spark使用Velox那样再经过一次转换),在计算层面用最少的投入达到与一流OLAP系统相近的分析能力,虽然从DuckDB,Clickhouse抠出计算模块也不是不行,但是考虑到不兼容部分修改难度和软件健康的迭代方式,Velox这种语言相同的模块化执行引擎就成了最优秀的选择。
两篇论文的侧重点有所不同;DataFusion从扩展性入手,详细介绍全部七个模块的核心功能;Velox则从Meta内部业务使用入手,介绍了Velox执行引擎的详细实现与细致入微的优化点;
业务案例
Presto
Presto 为 Meta 的大部分交互式(低延迟)SQL 分析工作负载和部分批处理工作负载提供服务,不过大部分繁重的 ETL 处理工作都是在 Spark 中完成的。
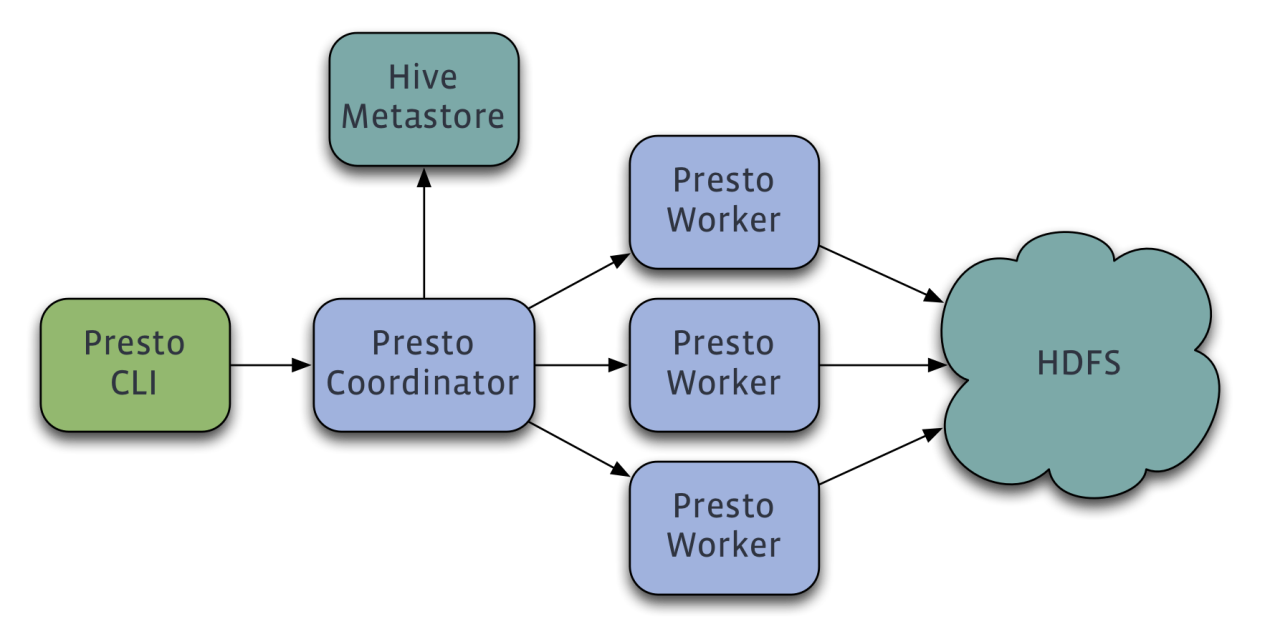
Presto 采用双层架构,由 coordinator node / worker node 组成:
- coordinator node负责接收用户查询、SQL 解析、元数据解析、全局查询优化和资源管理;
- 工作节点负责实际执行给定查询计划片段的查询。
coordinator / worker 进程共享相同的 Java 代码库,并通过 HTTP REST 接口进行通信。考虑到所有 data processing 以及 shuffling 都发生在工作节点内部或工作节点之间,工作节点和协调器的数量比例通常为 100-1000 比 1,因此绝大部分 CPU 时间都花在了工作节点上。
Prestissimo 是该项目的代号,旨在用基于 Velox 的 C++ 进程取代 Java Worker,从而提高效率。Prestissimo 提供了 Presto’s HTTP REST interface的实现,包括 Worker 到 Worker 的 exchange wire protocol、coordinator-to-worker orchestration,status reporting endpoints,从而提供了 Presto Worker 的直接替代品,替换后 Worker 上就不需要 Java 进程、JVM ,垃圾回收。主要的查询工作流程包括:
- Java 协调器接收 Presto 计划片段
- 转换为 Velox 查询计划
- 然后交给 Velox 执行
Prestissimo 充分利用了 Velox 库的如下特性:
- types
- Vectors
- expression eval
- functions
- operators
- serializers
- I/O
- resource management primitives
Spark
Spark 应用程序由driver process 和一组 executor process 构成:
- driver process:负责任务规划、调度以及与外部资源管理器通信
- executor process:负责执行实际计算以及与远程存储系统通信
在 Meta,Spark 通常用于执行批处理和 ETL SQL 查询,使用 SparkSQL 或 Dataframe API 进行表达,这是因为 Spark 对于长期运行的查询/应用程序具有卓越的容错特性(主要是因为RDD(Resilient Distributed Dataset)特性,由于RDD不可变,一旦创建,它的数据就不会改变,这意味着如果在计算过程中某个节点失败,Spark可以使用原始的数据源重新计算丢失的RDD分区,而不是从头开始重新运行整个查询[14])。
Spruce 是 Spark Velox 实现的代号。Spruce 利用一个允许用户在 Spark 中执行任意二进制文件的现有接口(称为 Spark 脚本转换),将执行工作卸载到执行 Velox 的外部 C++ 进程中,基本流程如下:
- 查询时,Spark 执行器接收查询计划
- 将其序列化后使用转换接口将其转发给外部 C++ 进程(SparkCpp)
- SparkCpp 对计划进行反序列化,将其转换为 Velox 计划
- 并使用 Velox 执行该计划
SparkCpp 利用了 Velox 库的如下特性:
- 使用 Velox’s extensibility APIs 添加 operators, scalar, and aggregate functions 使新的 C++ 代码与现有的 Spark Scala execution engine 完全兼容
- SparkCpp 也添加了 UnsafeRow serializer , 用于 data shuffling in Spark 以及向客户端返回数据
XStream
XStream 是 Meta 的流处理平台,允许用户创建流处理应用程序。
XStream 使用了 Velox 库的如下特性:
- XStream 应用程序通常从 Meta 的消息传输服务中连续读取数据,并在应用业务逻辑后将结果写回 Scribe 或其他数据汇,如用于在线服务的日志分析平台(Scuba)或键值存储系统。虽然流处理提供的抽象是一次对单行进行操作,但在实践中,读取和写入是分批进行的,以优化 IO,这可以受益于Velox的 vectorized execution model
- XStream 中的大多数数据处理操作都可以直接映射到 Velox 操作符,因此可以直接重复使用,例如 projections, filters 以及 as ongoing work, lookup joins。
- Velox 允许 XStream 使用公开在 Presto 中的相同函数包,从而提高了用户使用多个服务时的一致性。
- 由于流处理聚合需要与时间窗口(tumbling, hopping andsession windows)相关的特定引擎逻辑,因此 aggregations是作为 XStream 中 Velox 的扩展来实现的。
时序数据库中也会支持流计算,允许降维度或者不降低维度,基本的逻辑是消费WAL的更新流,然后在计算节点实时计算,最后写入数据库本身,这个流程原则上也可以使用Velox这样的执行引擎作为执行模块,当然我们现在时序数据库的流计算模块工作节点具体逻辑仍旧是自己从零实现的。
Distributed messaging system
Scribe 是一个Distributed messaging system,用于收集、聚合和以低延迟交付大量数据,是 Meta data ingestion pipelines 的主要入口。
Scribe 使用了 Velox 库的如下特性:
- 在常见的使用场景中,数据在网络层生成并写入 Scribe,随后由流处理应用程序读取,数据是逐行写入 Scribe,正常也是以同样的方式读取。如今,Scribe 读取服务能够充分利用 Velox 中的 wire serialization formats ,这些格式由于采用了面向列的编码而更加高效,而且数据消费者可以轻松地将其反序列化为 Velox Vectors。
- 在 Scribe 读取服务中使用 Velox 可以让数据消费者将 projections / filtering 等操作下推到更接近存储的位置,例如用于流处理应用,从而减少从 Scribe 读取的数据量,并在许多情况下减少跨数据中心的流量。
- Scribe 的 projections / filtering提供了与其他计算引擎相同的语义,从而促进了更加一致的数据用户体验。
Data Ingestion
FBETL 是 Meta 的 data ingestion engine,主要负责两个用例:data warehouse ingestion 和 database ingestion。
FBETL 使用了 Velox 库的如下特性:
- data warehouse ingestion 是将从 Scribe 管道读取的数据转换为仓库文件(通常使用 ORC 格式或称为 DWRF 的内部变体进行编码),以便长期保留和进一步处理的过程。FBETL使用 Velox中的 ORC 文件编码器代码库,
- 在FBETL 中使用 Velox 的 projections,expressions, UDFs, 以及在导入时应用于数据的filtering,这样做用户就不必创建一个完整的流处理应用程序来实现相同的结果,因为这样做会产生向新的 Scribe 管道写入数据并再次读取以进行摄取的开销。
- 提供了一致的用户体验,例如,终端用户可以重复使用 Presto 中可用的任何函数,以指定在摄取时应用于数据的转换,此外还减少了代码的重复。
Data Preprocessing
TorchArrow 是 PyTorch 的一个新项目,旨在为 ML 用户统一并提供一流的结构化数据预处理能力。它提供了一个类似于 Pandas 的 Python Dataframe层,并深度集成到 PyTorch 生态系统中。TorchArrow 在内部将 Dataframe 转换为 Velox 计划,并将其委托给 Velox 执行;
可以看出TorchArrow就是把Velox 像 Presto/Spark当作一个完整的执行引擎来用的。
Feature Engineering
feature engineering workflows也可以收益于Velox,即使用领域知识以特征形式提取有用信息的过程,这些特征可被 ML 算法使用。Meta 的特征工程框架是一个名为 F3(Facebook Feature Framework)的系统,用户可以通过定义 F3 DSL 文件,指定生成特定特征所需的转换(例如,将生日转换为数字年龄值),从而以编程方式创建特征。
当前的实现方式时:
- 根据 DSL 定义,F3 将特征生成转换集成到 Spark(用于批处理)和 XStream(用于实时数据集)中,从而管理离线和实时数据生成。
- 在线服务期间也使用相同的 DSL 定义来生成推理过程中输入模型的特征值,从而提供训练和服务/推理之间的一致性。
事实上我们看到 F3 完全可以将其执行引擎与 Velox 统一起来,不需要再使用 Spark 和 XStream,当然论文中提到现在已经在这样做了。
这里论文提出特征工程中的操作多为从用户服务路径中的应用程序调用,具有如下特性:
- 具有非常高的 QPS 和低延迟要求
- 并针对小批量数据(通常是单条记录)执行
这样看 Velox 的矢量化执行引擎因 interpretation overhead(我对这个词的理解是矢量化中的解包打包,额外的控制逻辑等,并不指代某个问题) 而不是最佳选择。对于这种用例,考虑到 DAG 本身大多是静态的,Meta 团队正在投资为 Velox 添加 codegen based execution,大体思路为:
- 整个表达式树会被重写为 C++ 函数的源代码
- 写入源文件
- 并使用 gcc 或 clang 等常规编译器编译为共享库
- 动态链接到主进程
组件
Type System
类型系统是执行引擎必不可少的一个子组件,因为所有的数据流转都需要机遇行,而行的元素就是类型系统的实体化,这通常也是执行引擎内存消耗最大的地方。
基础类型:int、float/double、string、dates、timestamp、functions
复杂类型:array、定长array、map、rows/struct
所有这些类型都可以任意嵌套,并提供序列化/反序列化方法。
最后,Velox 提供了一种不透明数据类型,开发人员可以用它来轻松封装任意的 C++ 数据结构。该类型系统具有可扩展性,允许开发人员添加特定于引擎的类型,而无需修改主库。比如 Presto 的 HyperLogLog 类型(用于估计cardinality)和其他 Presto 日期/时间特定数据类型(如带时区的时间戳)。
Vectors
Velox 的 Vectors 提供了不少优化,论文中提到这些点:
- Velox 向量允许开发人员利用各种编码格式在内存中表示列式数据集,并用作大多数其他组件的输入和输出
- Vector允许以任意方式嵌套,但是需要选择适当的编码,且所有的 vector 数据都使用 Velox 缓冲区存储,缓冲区是从内存池中分配的连续内存块,而且支持不同的所有权格式,我理解类似string和string_view
- 所有 Vector 和缓冲区都有引用计数,单个缓冲区可被多个 Vector 引用;只有单个引用的数据才是可变的,但任何 Vector 和缓冲区都可以通过写时拷贝实现可写。
- Velox 还提供了 Lazy Vectors 的概念,如果一个查询只需要数据集中的一小部分数据,使用 Lazy Vectors 可以避免加载和处理整个数据集。只有当查询的某个部分真正需要访问特定数据时,这些数据才会被加载和计算。这种方法特别适用于大数据场景,可以显著减少I/O操作、内存使用和CPU时间。
- Velox扩展了Arrow标准,以加速数据处理操作,,在2024年,这些特性已经与Arrow社区达成一致了[4]
Expression Eval
表达式的评估分为编译和执行两个步骤,下文将详细介绍这两个步骤。
编译:
- Common Subexpression Elimination:表达式编译过程负责识别常见的子表达式,这些子表达式在评估过程中只优化和计算一次。例如,考虑以下表达式:strpos(upper(a), ‘FOO’) > 0 OR strpos(upper(a), ‘BAR’) > 0。在这个例子中,𝑢𝑝𝑒𝑟(𝑎) 是一个常见的子表达式,因此只计算一次。
- FilterProject :运算符也受益于这一功能,它为所有 Filter 和 Project 表达式创建了一个单一的编译表达式对象,从而允许在 Filter 和 Projection 表达式之间共享子表达式,减少数据流转步骤。在我们的实现中子查询可以参考这种优化。
- Constant Folding:对不依赖于任何输入列的确定性子表达式进行评估,并用常量/字面表达式节点进行替换。例如,表达式𝑢𝑝𝑒𝑟(𝑎) = 𝑢𝑝𝑒𝑟(‘𝐹𝑜’)在编译过程中将被转换为𝑢𝑝𝑒𝑟(𝑎) = ‘𝐹𝑂𝑂’。
- Adaptive Conjunct Reordering:最后,在评估 AND 或 OR 表达式时,引擎会动态跟踪单个连接词的性能,并选择先评估最有效的连接词,即在最少时间内丢弃最多值的连接词。为了在执行过程中最大限度地发挥Adaptive Conjunct Reordering的效果,表达式编译还会对相邻的 AND/OR 表达式进行扁平化处理。这是个很有效的方式,但是在时序数据库中作用不大,因为每一个where条件都需要去索引中查找条件对应的tsid,不能够基于上一次的筛选结果做筛选,当然如果条件中为多个等于号和一个不等于号,我们就可以把不等于号放在最后,只去筛选前面得到的tsid,防止 != 的全表扫描。
执行:
- Peeling :我理解就是字典化,这确实可以显著减少内存的使用量,在我们的时序数据库实现中流计算的执行引擎以及时序存储引擎的索引组件都大规模使用了字典化,但是在查询过程中构造字典我不确定是否是一个好办法,因为在执行前无法评估构造字典需要开销和带来的节省是否值得,总而言之这个优化并不通用。
- Memoization:理想场景很优秀的做法,但是我认为记忆化最大的问题是淘汰,你无法确定字典中的值是否后续还会使用,这就导致记忆化需要一种清理不再使用字典key的能力。
Functions
Velox 提供的应用程序接口允许开发人员创建 scalar and aggregate functions。
scalar function 是将单行的值作为参数并产生单行输出的函数,但是Velox是一个矢量化执行引擎,考虑到额外接口的实现简单性,Velox提供了简单接口,开发人员不需要再遍历每一行输入数据、正确处理无效性缓冲区、不同的输入(和输出)编码格式、复杂的嵌套类型以及分配或重复使用输出缓冲区。
简单函数存在如下优化:
- DecodedVectors 抽象向开发人员隐藏了输入数据编码格式,并利用 C++ 模板元编程对成批的行(Vectors)高效地应用所提供的方法,而不会对每一行产生调度成本。
- 框架为 C++ 编译器提供了提示,以确保在大多数情况下,执行循环中的所有逻辑都被内联(从而防止热循环中的函数调用和缓存缺失)
- 允许编译器应用自动矢量化。例如,在编译 Velox 引擎时,clang 和 gcc 等主要编译器能够完全根据上述函数定义自动生成算术函数的 SIMD 代码
- 简单函数框架可将所有原始类型直接映射为相应的 C++ 类型。非原始类型,如字符串、数组、映射和行/结构体,则通过使用代理对象来实现,以避免将数据具体化并复制到临时对象(如 std::string 或 std::vector)中所产生的开销。代理对象的应用程序接口与 std 对应对象类似,但可直接对使用 Velox 向量表示的底层数据进行操作,不会产生额外的分配或复制。

可以看到部分函数的简单函数实现有更高的性能。


文中提到了字符串是否是ASCII-only对应性能处理有较大影响,因为处理UTF-8需要额外的逻辑。这个结论对于我们的实践有部分启发,因为字符串处理在部分路径上是瓶颈,但是部分业务的数据中确实没有UTF-8,但是这里肯定不能假设,需要有一种判断逻辑,不确定这个逻辑是否会抵消带来的好处。
Operators
只讨论优化。
- Simple filters 使用 SIMD。字典编码数据(Expression Eval中提到的字典化)的过滤结果会被缓存,SIMD 会再次使用 gather + compare + mask lookup + permute 来检查缓存的命中率
- efficient implementation for large IN filters,没看明白在干什么。。
- FilterProject 运算符对所有 Filter / Projection 使用单独的Operator,没有Filter成功,就不执行Projection
- 哈希键使用 VectorHasher 以列式方式进行处理,VectorHasher 可识别 key ranges and cardinality,并在适当的情况下将键转换为较小的整数域。如果所有键都映射到少数几个整数,则直接映射到平面数组,增加查找速度。
- 后面的哈希表优化也没看明白,没有样例确实比较抽象。
Memory Management
- 内存管理,任务暂停逻辑可拔插:query plans, expression trees, and other control structures从堆中分配,data cache entries, hash tables for aggregates and hash joins, and other assorted buffers 使用自定义分配器,为大对象提供 zero fragmentation 服务。内存被分层追踪,内存失败时可以选择失败,释放内存为其他任务腾出空间;也可以异步暂停,将数据溢出至磁盘。这里的逻辑和DataFusion行为很像,决定任务请求和取消的逻辑是可拔插的。
- operators还可以选择监控整体内存使用情况,并根据不同的内存压力情况做出反应;例如,如果内存变得稀缺(或某些分配失败),Exchange operators 可以决定缩小缓冲区大小。
- Cache管理,合并查询与预读:对于利用 disaggregated storage architecture 的的数据计算系统,Velox 提供对内存和固态硬盘缓存的支持,以减轻远程 IO 停顿对查询延迟的影响。缓存列首先从 S3 或 HDFS 等系统中读取,在首次使用时存储在 RAM 中,并最终持久化到本地 SSD 中。此外,如果相邻列之间的差距足够小(目前固态硬盘约为 20K,分解存储约为 500K),则通常会对相邻列的 IO 读取进行聚合(合并),目的是以尽可能少的 IO 读取次数为相邻读取提供服务。当然,这也利用了时间局部性的效果,使相关列一起缓存在固态硬盘上。
- 考虑到所有远程列格式都有类似的访问模式,包括首先读取文件元数据以识别缓冲区边界,然后读取这些缓冲区的部分内容,因此可以提前安排 IO 读取,以交错 IO 停顿和 CPU 处理。Velox 可根据每次查询跟踪列的访问频率,并自适应地为 hot columns 安排预取,这可以使 IO 停顿被从关键路径中移除,不会造成查询延迟。
关于预读可以参考[15]。
性能
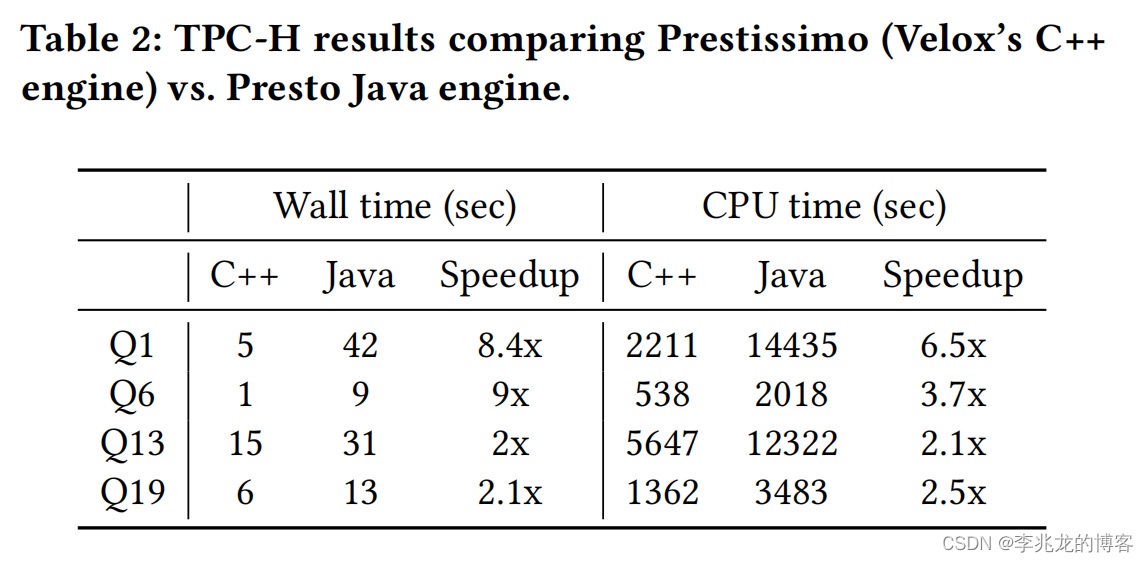
与DataFusion持相同的看法,知道这是一个工业级可用的执行引擎就够了。
结束语
[1][11] 不提Meta对于开源的态度,不提公司政治,不提个人发展。
在希望提供更强工程能力的计算引擎这点来看,项目开发之初接入Velox是正确的,此时最大的风险在于接入Velox最大的问题在于将自己的身家性命与快速迭代的可能交给了Velox和它的扩展API,当Velox无法支持时必要特性时就麻烦了,因为比起公司内部流程开源社区一个特性的的反馈周期过于长。但是GrepTime,influxdb 3.0这种强开源的公司确实可以选择这样的路,因为完全没有重新开发一个的理由。
如果项目开发已经有段时间,此时愿意放弃自己团队已经投入很久的实现,而完全去使用Velox的c++实现作为单机runtime需要团队有一定的魄力,其次需要技术视野清晰,明确替换后的优势,一定需要ROI确定后再动手。
于我而言想这样做,但是可见的ROI过低,因为时序数据库多为聚合操作,绝大多数聚合操作已经通过协处理器执行,执行引擎本身要做的事情很少,但是确实存在少部分业务的大查询突出了目前我们执行引擎的性能低下,全面替换我觉得至少是一人力半年以上的排期。
所以这两篇论文对我最大的帮助是:
- 确定了Velox是一条可行的道路
- 不讨论实现,明确了优秀执行引擎应该做到的功能
参考:
- Facebook的新开源项目Velox,有点命运多舛啊
- Introducing Velox: An open source unified execution engine
- Velox 介绍:一个开源的统一执行引擎
- Aligning Velox and Apache Arrow: Towards composable data management
- https://velox-lib.io/blog
- Prestissimo: A Year In, The Path to Veloxification
- Presto 向量化引擎(Prestissimo/Velox)在 Meta 的一年总结
- Facebook Velox源码浅读
- Facebook Velox 运行机制全面剖析
- Facebook开源的Velox,到底长什么样,浅读VLDB 2022 velox paper
- Facebook的开源Native大数据引擎Velox能成为我说的又好又快的Native引擎吗?
- 从一到无穷大 #25 DataFusion:可嵌入,可扩展的模块化工业级计算引擎实现
- Presto实现原理和美团的使用实践
- Spark RDD 论文分析
- 从一到无穷大 #22 基于对象存储执行OLAP分析的学术or工程经验,我们可以从中学习到什么?