请求对象
请求对象参数
scrapy.Request(url[],callback,method="GET",headers,body,cookies,meta,dont_filter=False)
callback表示当前的url响应交给那个函数去处理method指定请求方式headers接受一个字典,其中不包括cookiesbody接收json字符串,为POST请求的数据,发送payload_post请求时使用cookies接收一个字典,专门放置cookiesmeta实现数据在不同的解析函数中传递,meta默认带有部分数据,比如下载延迟,请求深度dont_filter默认为False,会过来请求的url地址,即请求过的url地址不会继续被请求。对需要重复请求的url地址可以把他设置为True,比如贴吧的翻页请求,页面的数据总是在变化。start_urls中的地址会被反复请求,否则程序不会启动。
meta参数的使用
meta可以实现数据在不同的解析函数中的传递。具体作用包括:
- 数据传递:可以在一个解析函数中抓取到的部分数据,通过meta传递给下一个回调函数继续处理,尤其适用于需要多步流程才能完全获取到所需数据的情况。
- 状态标志:可以传递一些布尔值或标记,告诉后续的回调函数如何处理响应数据,比如是否已登录、是否需要特殊处理等。
- 请求关联:可以用来关联多个请求,比如将同一个项目的不同部分关联在一起,便于最后聚合组装完整数据项。
- 指定回调函数:有时候还可以通过meta中的callback键来动态指定响应应该由哪个函数来处理。
示例
def parse(self, response):item = Item()# ... 抓取部分数据填充到item中 ...next_url = response.css('a.next::attr(href)').get()yield Request(next_url, callback=self.parse_next_page, meta={'item': item})def parse_next_page(self, response):item = response.meta['item'] # 从上一步传递过来的item# ... 在这里继续抓取并更新item ...yield item # 最终输出完整的item
模拟登录
这里主要是利用 cookie,scrapy中cookie不能放在headers中,需要在构造请求的时候有专门的cookies参数。并且需要在setting文件中设置ROBOTS协议、USER_AGENT
创建项目
scrapy startproject github
创建爬虫
scrapy genspider git1 github.com
在浏览器控制台里选择一个地址做登录请求,比如:https://github.com/exile-morganna
并从浏览器里拿到对应的cookie
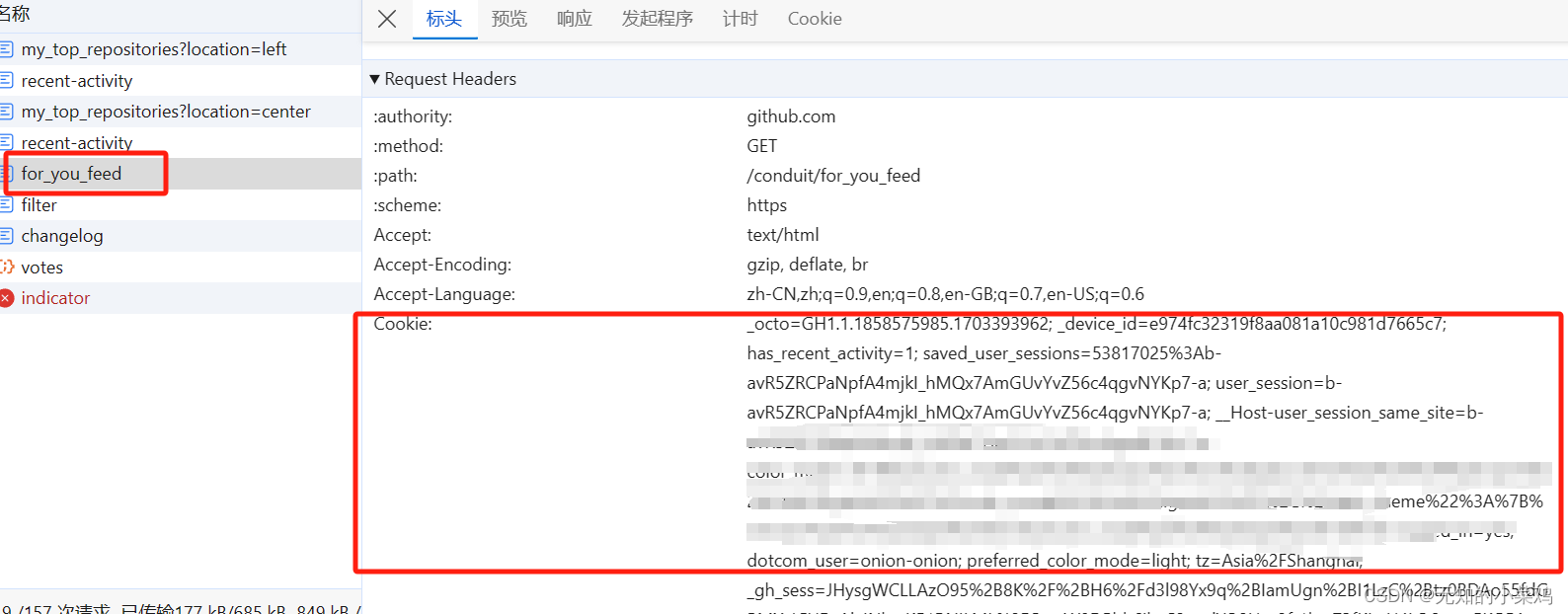
class Git1Spider(scrapy.Spider):name = "git1"allowed_domains = ["github.com"]start_urls = ["https://github.com/exile-morganna"]# 默认的请求不会携带cookie,需要重写请求def start_requests(self):# 处理cookie字符串为字典temp = "你的cookie"# 分割字符串cookies = {data.split("=")[0]: data.split("=")[-1] for data in temp.split("; ")}for url in self.start_urls:yield scrapy.Request(url=url, cookies=cookies)def parse(self, response):# 获取标题title = response.xpath("/html/head/title/text()").extract_first()print(title)
如果运行时提示下面的内容说明,网站不允许爬取。需要修改settings.py里的内容
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0"# Obey robots.txt rules
#ROBOTSTXT_OBEY = True

请求成功

POST请求
在scrapy中一般使用scrapy.FormRequest()来发送post请求
获取到请求地址,可以点击登录按钮,获取到请求地址https://github.com/session
创建爬虫
scrapy genspider git2 github.com
获取的post请求的参数
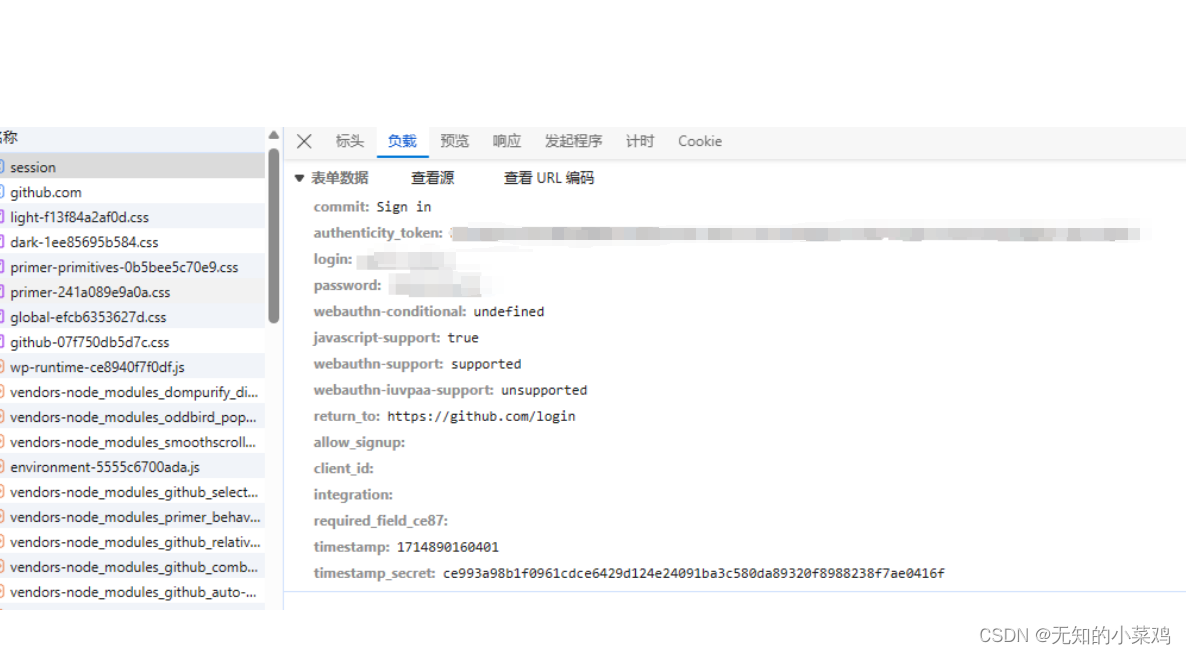
从请求页中获取到token
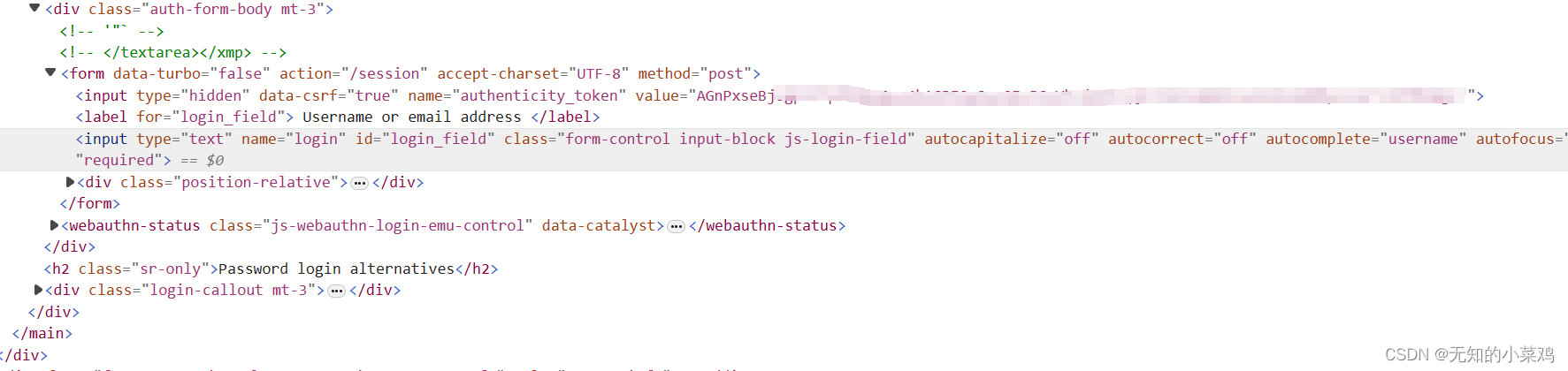
class Git2Spider(scrapy.Spider):name = "git2"allowed_domains = ["github.com"]start_urls = ["https://github.com/login"]def parse(self, response):# 从登录页面响应中解析出post数据# 从登录页获取到tookentoken = response.xpath("//input[@name='authenticity_token']/@value").extract_first()# 你的账号和密码post_data = {"commit": "Sign in","authenticity_token": token,"login": "1111","password": "1111","webauthn-support": "supported",}# print(post_data)# 针对登录URL发送post请求yield scrapy.FormRequest(url="https://github.com/session",formdata=post_data,callback=self.after_login,)# 登录后续操作def after_login(self, response):# 请求案例1中的yield scrapy.Request("https://github.com/exile-morganna", callback=self.check_login)# 校验是否登录成功def check_login(self, response):# 获取标题title = response.xpath("/html/head/title/text()").extract_first()print("标题是:", title)
管道的使用
pipeline中常用的方法
-
process_item(self,item,spider)- 管道类中必须有的函数
- 实现对
item数据的处理 - 必须
return item
-
open_spider(self,spider)在爬虫开启的时候仅执行一次 -
close_spider(selef,spider)在爬虫关闭的时候仅执行一次
在study1项目里我们使用了__init__ 和 __del__ 方法来进行文件操作。在这里可以使用open_spider 、close_spider 来替换
def open_spider(self, spider):if spider.name == "itcast":print("itcast爬虫开启")self.file = open("itcast.json", "w", encoding="utf-8")
我们可以通过爬虫名,来对某一个爬虫执行一些独有的操作。
crawlspider爬虫类
简介
CrawlSpider 是 Scrapy 网络爬虫框架中的一个高级爬虫类,它是 Spider 类的子类,专为大规模和半结构化网站的爬取而设计。相较于基础的 Spider 类,CrawlSpider 引入了自动化链接跟踪的能力,使得它非常适合进行整个站点或部分站点的深度爬取。
主要特点和功能:
-
Link Extractors(链接提取器):
CrawlSpider强调使用Link Extractors来自动发现并跟随网页中的链接。这些链接可以基于 CSS 选择器、正则表达式等规则来提取。这意味着你可以定义规则来自动抓取与初始请求相关的页面,实现对网站的深度爬取。
-
Rules(规则):
- 规则是
CrawlSpider的核心特性,它定义了如何处理从网页中提取的链接。每个规则包含一个Link Extractor用于提取链接,以及一个可选的回调函数(callback)用于处理匹配链接抓取回来的响应。此外,规则还可以指定是否应跟进提取的链接(follow=True 或 follow=False),以及对链接进行预处理的函数(如process_links和process_request)。
- 规则是
-
自动化Request生成:
- 一旦定义了规则,
CrawlSpider会自动处理从响应中提取链接、生成新的请求、并调度这些请求的过程,大大简化了对多页数据爬取的编程工作。
- 一旦定义了规则,
-
广泛适用性:
CrawlSpider特别适合那些有明确模式可循的网站爬取,比如新闻网站、论坛或者产品目录等,尤其是当你想要遍历多个页面并提取相似结构的信息时。
使用方法:
- 创建
CrawlSpider实例时,通常需要覆盖或添加规则(rules属性)来指导爬虫如何抓取。 - 使用
scrapy genspider -t crawl <爬虫名> <域名>命令可以快速生成基于CrawlSpider的爬虫模板。 - 在爬虫类中定义
start_requests()方法来指定起始URL,以及规则(rules)来定义链接的提取逻辑和处理方式。
总之,CrawlSpider 通过集成链接提取和自动请求生成的机制,为开发者提供了一种高效且灵活的方式来实施复杂的爬取任务,特别是在处理大型网站数据抓取时表现出色。
基本使用
创建爬虫
scrapy genspider -t crawl 爬虫名 域名
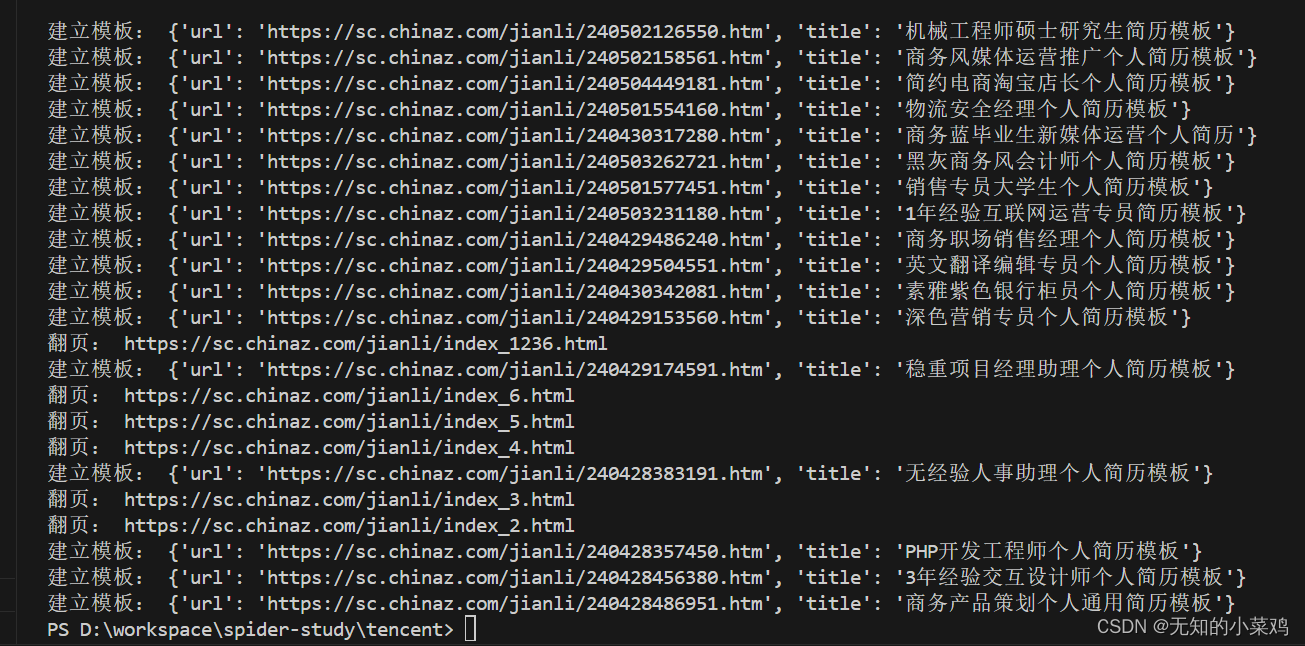
class TencentCrawlSpider(CrawlSpider):name = "tencent_crawl"allowed_domains = ["chinaz.com"]start_urls = ["https://sc.chinaz.com/jianli/"]rules = (# 使用Rule类生成链接提取规则,生成LinkExtractor对象# LinkExtractor 用于设置链接提取规则# allow参数,接收正则表达式# callback参数,回调函数,值是函数名的字符串# follow参数,决定是否在链接提取器提取的链接对应的响应中继续应用链接提取器提取链接,类似于递归# 在正则里.要用\.进行转移Rule(LinkExtractor(allow=r"https://sc.chinaz.com/jianli/\d+\.html?"),callback="parse_item",follow=False,),# 翻页规则Rule(LinkExtractor(allow=r"https://sc.chinaz.com/jianli/index_\d+\.html"),callback="parse_page",follow=False, # 设置为true时会一致递归下去,数据太多了),)def parse_item(self, response):item = {}item["url"] = response.urlitem["title"] = response.xpath("//h1/text()").get()print("建立模板:", item)return itemdef parse_page(self, response):print("翻页:", response.url)