- 前言
- 1. 概述
- 2. 大小端字节序和字节序判断
- 2.1 大端字节序(Big-Endian)
- 2.2 小端字节序(Little-Endian)
- 2.3 判断字节序的示例
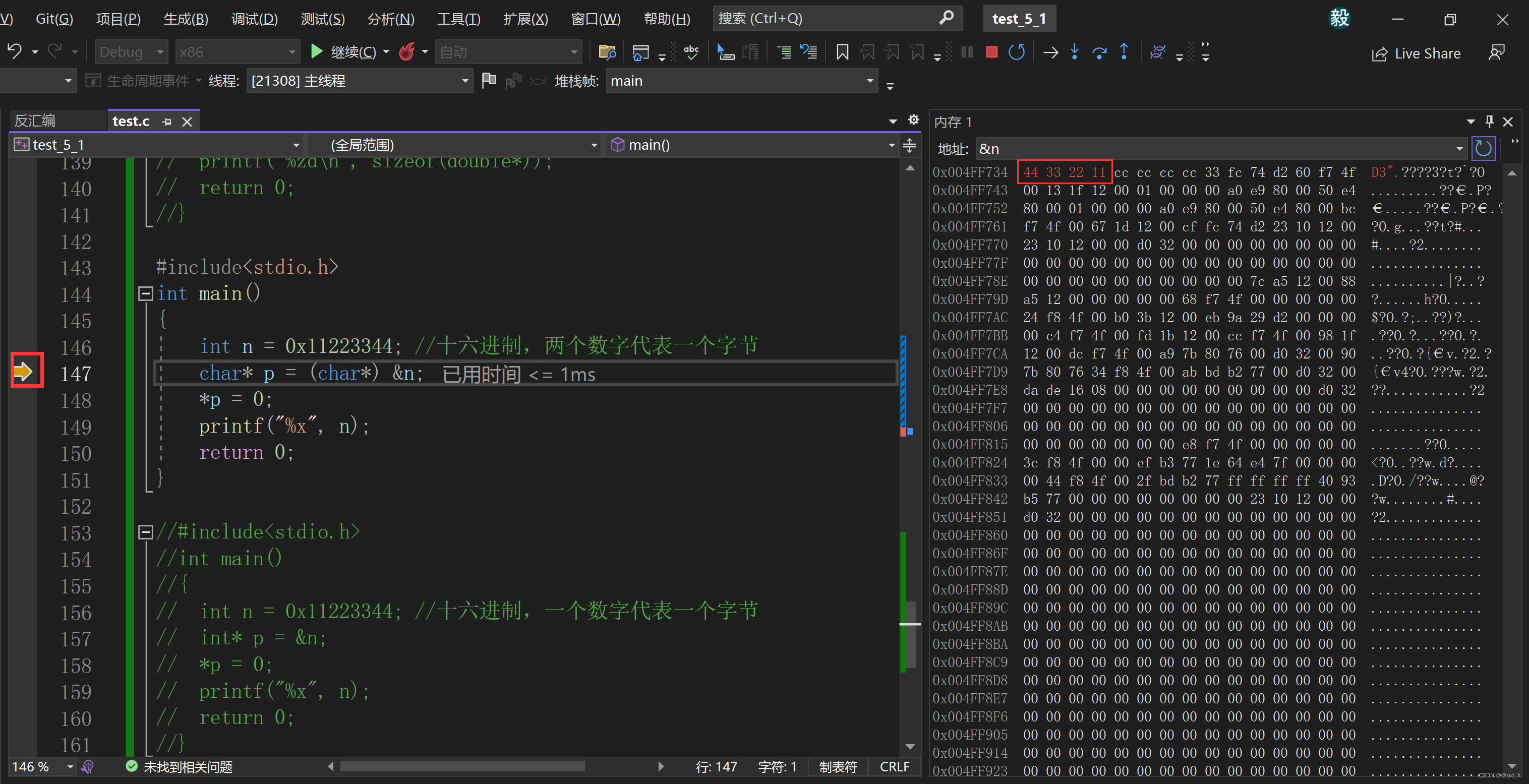
- 3. 数据在内存中的存储
- 3.1 整数在内存中的存储
- 3.2 浮点数在内存中的存储
- 结语


↓
上期回顾: 【C语言回顾】字符函数、字符串函数,内存函数
个人主页:C_GUIQU
专栏:【C语言学习】
↑

前言
各位小伙伴大家好!上期小编给大家讲解了C语言中的字符函数、字符串函数,内存函数,接下来我们讲解一下数据在内存中的存储!

1. 概述
在C语言中,数据在内存中的存储方式受到数据类型、对齐规则和编译器实现的影响。
以下是C语言中数据在内存中存储的一些关键点:
- 数据类型大小:C语言中的基本数据类型(如
int、char、float、double等)在内存中占用的字节数是由编译器和目标系统架构决定的。例如,在32位系统中,int通常占用4个字节,float占用4个字节,而double占用8个字节。 - 内存对齐:为了提高内存访问效率,C语言在存储数据时通常会遵循特定的对齐规则。这些规则规定了数据应该从特定的地址开始存储。例如,一个4字节的整数可能会被要求从4的倍数地址开始存储。结构体中的成员也会根据这些规则进行对齐,这可能导致结构体实际占用的内存大小比各成员大小之和要大。
- 字节顺序:C语言中的数据在内存中的存储顺序可能因系统架构而异。在大端(Big-Endian)系统中,数据的最高有效字节存储在最低的内存地址,而在小端(Little-Endian)系统中,数据的最低有效字节存储在最低的内存地址。例如,整数
0x12345678在大端系统中存储为12 34 56 78,而在小端系统中存储为78 56 34 12。 - 堆和栈:在C语言中,动态分配的内存(使用
malloc、calloc、realloc等函数)通常在堆(heap)上分配,而局部变量和函数调用的上下文信息通常在栈(stack)上分配。堆上的内存需要在不再需要时由程序员显式释放,而栈上的内存则会在函数调用结束后自动释放。 - 数组和指针:在C语言中,数组是一块连续的内存区域,其元素按照顺序存储。指针是一个变量,它存储了一个内存地址,可以通过指针来访问和修改内存中的数据。指针的大小通常与系统的地址总线宽度相等,在32位系统中为4字节,在64位系统中为8字节。
- 结构体和联合:结构体(
struct)和联合(union)是C语言中用于创建复杂数据结构的关键字。结构体中的成员按照它们在结构体定义中的顺序存储在内存中,每个成员按照其对齐规则进行对齐。联合中的所有成员共享同一块内存区域,因此联合的大小是其最大成员的大小,并且对齐到最大成员的对齐要求。
了解C语言中数据在内存中的存储方式对于编写高效和正确的程序至关重要,尤其是在进行指针操作、内存管理、数据结构和网络编程时。
2. 大小端字节序和字节序判断
大小端字节序(Endianess)是指多字节数据在内存中的存储顺序。在不同的计算机体系结构中,多字节数据的存储顺序可能不同。以下是大小端字节序的定义和如何判断字节序的示例:
2.1 大端字节序(Big-Endian)
在大端字节序中,数据的最高有效字节(Most Significant Byte, MSB)存储在最小的内存地址中,而最低有效字节(Least Significant Byte, LSB)存储在最大的内存地址中。这类似于阅读和写入数字时的顺序,从最高位到最低位。
例如,一个16位的整数0x1234在大端字节序中的存储顺序如下:
地址增长方向 -->
[0x12] [0x34]
MSB LSB
2.2 小端字节序(Little-Endian)
在小端字节序中,数据的最低有效字节(LSB)存储在最小的内存地址中,而最高有效字节(MSB)存储在最大的内存地址中。这与我们通常阅读数字的顺序相反。
例如,同样的16位整数0x1234在小端字节序中的存储顺序如下:
地址增长方向 -->
[0x34] [0x12]
LSB MSB
2.3 判断字节序的示例
在C语言中,可以通过编写一个简单的程序来判断当前系统的字节序。以下是一个示例程序:
#include <stdio.h>
int main() {unsigned int num = 1;char *ptr = (char *)#if (*ptr == 1) {printf("小端字节序\n");} else {printf("大端字节序\n");}return 0;
}
这个程序创建了一个无符号整数num并将其初始化为1。然后,它将一个char类型的指针ptr指向这个整数。由于char类型通常是一个字节,所以ptr指向的是num的第一个字节。如果第一个字节是1,那么系统是小端字节序;如果第一个字节是0,那么系统是大端字节序。
运行这个程序,你将能够看到你的系统是使用大端还是小端字节序。
3. 数据在内存中的存储
3.1 整数在内存中的存储
整数在内存中的存储方式取决于整数的类型、大小以及计算机的体系结构(特别是字节序)。以下是一些关于整数在内存中存储的基本信息:
- 有符号与无符号整数:
- 有符号整数(例如
int、short、long)可以表示正数、负数和零。 - 无符号整数(例如
unsigned int、unsigned short、unsigned long)只能表示非负数(正数和零)。
- 有符号整数(例如
- 原码、反码和补码:
- 有符号整数通常使用补码(two’s complement)形式存储在内存中。
- 原码(sign-magnitude)直接将最高位用作符号位(0表示正,1表示负),其余位表示数值。
- 反码(ones’ complement)在原码的基础上,将负数的所有位取反(符号位不变)。
- 补码在反码的基础上加1。
- 字节序:
- 如前所述,整数在内存中的字节顺序取决于计算机的大小端字节序。
- 在大端字节序中,整数的最高有效字节存储在最小的内存地址。
- 在小端字节序中,整数的最低有效字节存储在最小的内存地址。
- 整数大小:
int类型的大小通常是平台相关的,通常为4字节(32位)或8字节(64位)。short通常为2字节(16位),而long和long long分别为4字节和8字节,或者更大。
- 示例:
- 假设我们有一个32位的有符号整数
int num = 12345,在小端字节序的系统中,它可能会按照以下方式存储:地址增长方向 --> [0x39] [0x30] [0x00] [0x00] LSB ... - 如果
num是一个负数,比如-12345,在补码表示法下,它首先会被转换为补码,然后按照相同的字节顺序存储。
- 假设我们有一个32位的有符号整数
- 对齐要求:
- 整数在内存中的存储还可能受到对齐要求的限制,这意味着整数可能需要从特定地址开始存储,例如,一个4字节的整数可能需要从4的倍数地址开始存储。
理解整数在内存中的存储方式对于编写高效和正确的程序至关重要,尤其是在进行位操作、网络编程、跨平台开发以及与硬件接口交互时。
- 整数在内存中的存储还可能受到对齐要求的限制,这意味着整数可能需要从特定地址开始存储,例如,一个4字节的整数可能需要从4的倍数地址开始存储。
3.2 浮点数在内存中的存储
浮点数在内存中的存储遵循特定的标准,最常见的是IEEE 754标准。这个标准定义了浮点数的存储格式,并且被大多数现代计算机系统所采用。以下是关于浮点数在内存中存储的一些关键点:
- IEEE 754标准:
- IEEE 754标准定义了单精度(32位)和双精度(64位)浮点数的格式。
- 单精度浮点数(float)通常占用4个字节。
- 双精度浮点数(double)通常占用8个字节。
- 浮点数的组成部分:
- 符号位(Sign bit):决定浮点数是正数(0)还是负数(1)。
- 指数(Exponent):表示浮点数的数量级。
- 尾数(Mantissa)或有效数字(Significand):表示浮点数的精确值。
- 单精度(float)存储格式:
- 符号位:1位
- 指数:8位(偏移量编码)
- 尾数:23位(隐藏的最高位通常不存储)
- 双精度(double)存储格式:
- 符号位:1位
- 指数:11位(偏移量编码)
- 尾数:52位(隐藏的最高位通常不存储)
- 特殊值:
- 零(0):所有位都是0。
- 无穷大(Infinity):指数全为1,尾数全为0。
- 非数(NaN,Not a Number):指数全为1,尾数不全为0。
- 字节顺序:
- 和整数一样,浮点数的字节顺序也取决于系统的大小端字节序。
- 示例:
- 假设我们有一个单精度浮点数
float f = 123.45,在小端字节序的系统中,它可能会按照以下方式存储:地址增长方向 --> [0x00] [0x00] [0x7A] [0x44] LSB MSB
- 假设我们有一个单精度浮点数
其中,0x44 是尾数的部分,0x7A 是指数和符号位的组合。
理解浮点数在内存中的存储方式对于编写科学计算、图形处理和需要高精度计算的程序非常重要。需要注意的是,浮点数的表示可能会有精度损失,特别是在进行大量计算时。因此,在设计算法和处理数据时,需要特别注意浮点数的特性和限制。
结语
以上就是小编对数据在内存中的存储的详细讲解。
如果觉得小编讲的还可以,还请一键三连。互三必回!
持续更新中~!