点击免费下载原文及代码
摘要
我们处在一个大数据的时代,伴随着网络信息资源的庞大,人们越来越多地注重怎样才能快速有效地从海量的网络信息中,检索出自己需要的、潜在的、有价值的信息,从而可以有效地在日常工作和生活中发挥作用。因为搜索引擎这一技术很好的解决了用户搜索网上大量信息的难题,所以在当今的社会,无论是发展迅猛的计算机行业,还是作为后起之秀的信息产业界,都把Web搜索引擎的技术作为了争相探讨与专研的方向。
搜索引擎的定义就是指按照既定的策略与方法,采取相关的计算机程序,通过在互联网中进行寻找信息,并显示信息,最后把找到的信息进行整理和筛选,为搜索引擎的使用者提供检索信息的服务,终极目标是为了提供给使用者,他所搜索信息相关的资料的计算机系统。搜索引擎的种类繁多,既可以进行全文的索引,还可以进行目录的索引,不仅有集合式的搜索引擎,还有垂直搜索的引擎以及元搜索引擎。除此之外,还有门户搜索引擎和免费链接列表等等。
本文首先介绍了搜索引擎出现的必要性,以及什么是搜索引擎、搜索引擎的分类、处理流程、核心技术,同时也对如何才能提高搜索引擎的精准度以及关联度进行了更加深入的研究。
关键词: Web搜索引擎、信息检索、人机交互、Lucene全文检索引擎
Abstract
We are in an era of big data, with the network information resources is huge, more and more people pay attention to how to quickly and efficiently from the massive network information, searching for their own needs, potential, valuable information, which can effectively play a role in the daily work and life. Because the search the engine of this technology is a good solution to the problem of Internet users to search a large amount of information, so in today's society, whether it is the rapid development of computer industry, information industry as the bright younger generation, the Web search engine technology as the direction to explore and research.The search engine (Search Engine) refers to the strategy and methods established, take computer related procedures, through the Internet search and display information, then the information sorting and filtering, provide information retrieval services for users of search engines, the ultimate goal is to provide to the user, the computer system of his search data information related to the type of search engine. There can be the index, can also be a directory index, not only has the integrated search engine, and the vertical search engine and meta search engine. In addition, there is the portal search engine and free chain Access list and so on
This paper first introduces the necessity of the search engine, and what is the search engine, search engine classification, treatment process, the core technology, but also on how to improve the search accuracy and relevance of a more in-depth study.
Keywords: Web search engine、information retrieval、human-computer interaction,、Lucene full text search engine
1 绪论
1.1 项目背景
环球信息网(World Wide Web),即3W,一般在计算机与信息行业用Web这个词汇来来表示,万维网是它进入中国时所赋予的称呼,其实,这就是一个资料的汇集与存储的空间。
在这个空间中,以事物为单位,一个事物也可以称为一样“资源”,利用URL来标识,统一资源标识符”(URL。这些资源通过超文本传输协议(Hypertext Transfer Protocol,HTP)传送给终端用户,其中给到用户手上的是一个个链接,然后用户通过逐层点击链接,就可以查看到资源,也可以获得到资源。
万维网也常常被人们误以为是因特网的近义词,在这里必须要表明的概念是:万维网与因特网存在着本质的区别。因特网(Internet)是指,把全世界所有的各类型电脑,利用网络连接,所形成的硬件框架,这是一个实实在在的“网”。万维网,其本质是一种功能,即让使用者光看网络页面,而页面之间又交相辉映,从而让使用者觉得这也是一种“网”,但这种网是虚拟的,是不存在的。
可以说1994年在信息时代是一个重大突破的一年,因为万维网(World Wide Web)出现了。在这一改变之前,人们的信息获取方式还是通过各种传统文化传媒,相对于万维网来说是很传统、笨拙的,它在开放性和广泛的可访问性极大的激励了人们创作的积极性。所以万维网的出现极大的缩短了人们信息获取的时间,同时信息的时效性也得到了保障。万维网一出现就收到了全世界各国人的追捧,人们在它出现的十几年的一个时间段中,就在万维网这一平台上发布了几十亿条的网页信息,他的一个数据量是那么的庞大,粗略计算一下,万维网上的网页信息每天都会不断增长几十万。因为网络化、数字化的信息资源,所以网络信息也是有利有弊:利的一面是提高了我们的信息量;不利的一面是庞大的信息一并向我们开来,犹如破堤的江水,汹涌澎湃,造成了我们无所适从。
关于搜索引擎的由来,北美加拿大(Canada)的麦吉尔大学就必须要介绍一下了,早在上世纪,90年代之初,由于网络资源众多,分散性特别大,人们在找资料的时候特别费力。麦吉尔大学的团队也意识到了这个问题,所以他们就研发出了Archie,这是一个可以自动运行的系统,可以完成在FTP上搜集有用资源的作用。该系统定期会自动搜索FTP系统上保存的文档名以及相关的资源,而且还可以自行分析,如果有客户端发出搜索请求,该系统会根据搜索请求的内容,自动提供保存在主机中文件。在以Web网页为对象的搜索引擎系统的大背景下,搜索引擎被人们当做了在网上查找信息的重要手段,通过搜索引擎系统人们可以在浩瀚的网络海洋中第一时间找到自己真正想要的信息,并且搜索引擎的智能以及现在网页的特性使得人们只要输入相关的词语(即关键词)就可以找到相关的信息。
现如今,人们看到的百度、Google取得的显著成效,可以说是成为了行业的领头羊,所以整个世界也都把视觉一部分放置在了搜索引擎这一领域当中,各种各样的搜索服务犹如雨后春笋一般争相冒出。搜索引擎不仅种类愈来愈多,而且其服务的质量也越来越全面,从最初期的国外的Google引擎、Yahoo引擎,到如今的中国的Baidu引擎、360引擎等等。随着web技术的不断完善,网络信息资源也是翻倍增长的(变化关系是成正比的)。所以为了满足用户的需要,既可以快速的找到到资源,而且还可以提高资源的质量,各类型的引擎中,必须引入检索这一概念。此外,在企业级应用的市场上,由于搜索的资源需求量大,要求的精度更加高,全文检索的功能也就被人们重视起来了,例如在各种文件档案的处理过程中、企业管理的软件中。
在这样的环境下,搜索引擎的技术也在迅猛发展。各种讨论搜索引擎的文章、博客、杂志等席卷网络的相关信息。在这个信息化全面进入人们生活各层各面的时代,搜索引擎这项技术无疑会在最热门的技术中占有一席之地。
1.2 国内外发展现状及分类
当今的时代,网络信息呈现指数型上升,其复杂性不言而喻,而网络检索技术的发展却不尽如人意,有很多方面的不足,具体阐述如下:
(1) 随着网页数量的迅猛增加,尽管是专业人员,他对所有的认知也存在不足,同时专业人员的工作量也很大,单凭人工操作,是没有办法对如此庞大的信息量进行有效的分类,更不用说是再加以检索和利用了。网络用户接触的是庞大对的、未经组织的信息,只是使用简单的关键词搜索,它对应的反馈给用户的结果冗余度较大且涵盖有限,这是让用户无法接受的。
(2) 信息实用性评价低迷。有些网站在网页中高频的出现某些关键字,从而轻易的被一些显著的搜索引擎收录,以此来提高该网站的知名度,但实际上它对用户是没有提供任何有价值的信息。
(3) 网络信息变更过快。如今的社会就是一个快节奏的社会,人们更多的喜欢是速食文化,即尽可能快的获取信息,可是分布式的信息布局,就算网络传输速度再快,要想实现实时的搜索难度堪比登天啊,即使是上一秒刷新过的网页,在下一秒就会有无尽的可能,时效性一直是人们追求网络信息的方向,但却很难做到真正的实时。
速度和效率往往是会体现这个搜索引擎是否良好的标准,故此,对于网络信息检索工具而言,其发展的主要方向就是,在信息检索的速度和效率是一步一步不断改进和突破,以提高检索的技术,提供更高的检索服务的质量,改善甚至消除局部网络信息检索的用户不满意之处。
万维网:它是世界上最大的域名注册以及虚拟主机提供商,现在的域名多种多样,不过以www开头的最多,相应的费用也是最贵的,但是,现在还有一批域名不是以www开头,直接二级域名开头,我们在做网站的时候,首先需要购买域名,然后大约根据程序的大小订购服务器,服务器按系统分为linux、window的,按开发语言也可以选择服务器,按代码的上传方式也可以选择服务器,服务器有一定的界面,当然你也可以在linux系统中敲指令来实现,window服务器使用起来比较麻烦,因为你的电脑是window的,然后你要进入另外一台主机中,就会出现只能选择其一的现象,不能同时看到,接着建立站点,设置 ftp,建立数据库,然后上传代码。
1.3 本论文组织结构介绍
本次设计是在Lucene技术之上进行的开发,最终成功的设计出搜索引擎的全过程。从开始本次设计到最终的实现,都会在下述做详细的介绍:
第1章 绪论,本章主要从如下几个方面做了阐述:
1、本次设计的系统所会面临的问题;
2、怎么处理所面临的难题;
3、攻克难题的详细内容;
4、本次课题是基于什么样的研究背景、意义而进行;
5、本次设计的可行性分析以及论文中各章节内容描述。
第2章 相关技术介绍,对涉及到的理论知识和用到的开发工具做相关阐述。
第3章搜索引擎的基本原理,详细介绍了搜索引擎的基本组成结构和工作原理。
第4章 搜索引擎系统的分析与设计,根据所需要实现的功能入手,一步步的完成设计目标。
第5章 搜索引擎系统的具体设计步骤,分步骤详细地表述了该设计的实现过程以及设计中会遇到的注意事项。
第6章 系统测试,对系统做了相关测试和评价说明。
最后:总结、致谢、参考文献。
2 相关技术介绍
2.1 什么是搜索引擎
随着Web信息的爆炸型增长,Web型搜索引擎的设计就被提上了日程,大约是从上世纪90年代开始,逐渐的逐渐发展起来。实际上,本次设计的就是一种在互联网上,专门给用户提供各种查询信息服务的网站,它以自己特定的方式在互联网中寻找信息,并且把信息提取出来,然后再进行理解信息,把信息重新组织以及信息的加工处理,并反馈给用户的服务,从而达到信息资源导航的目的。用户可以通过自由词、关键字、等方式进行查询,也可以利用全文进行检索,或者根据类别进行搜索,甚至还可以加入一些特有的信息进行限制,例如名字、性别、出版社、序列号等等。
如今搜索引擎提供的信息资源导航服务已发展成互联网上非常重要的网络服务之一,搜索引擎网站也被称之为 “网络门户”。
根据搜集资源与提供给用户的方式进行区别,如今的搜索引擎可以划分为两类:
(1)目录式搜索引擎:按照人为地方案或者是半自动的工作模式去搜索信息,然后指定职业的工作人员查看信息,采取人工的方式对信息进行筛选,最终会把检索到的信息分类存放在指定的框架当中。这一类信息大多数是直接与网站进行交互的,只可以提供文档目录的查看以及直接检索的服务。由于这一类型的搜索引擎引入了人的智能的功能,所以提供的信息质量非常高,精确地匹配所检索的信息;但由于需要指定人员进行查看和分类,这无疑会使得信息的更新不够及时,而且信息量如此之大,会使得维护任务异常繁重。雅虎(yahoo!)就是这一类型的典型代表。
(2)机器人搜索引擎:利用蜘蛛 (spider)程序在互联网中进行自主的检索资源,通过索引器搜索的信息绘制索引表,索引器就是依照使用者的输入请求,查看索引库中的内容,最终将匹配到的结果显示出来,供用户查看。这一类型的服务方式是面向web的全文检索。该类搜索引擎相比于目录式的搜索引擎,省去了人工操作的环节,使得更新更加及时,而且由于是计算机自动进行查询,会使得查询得到的信息量大幅提升;但正是由于这样,会使得返回的信息匹配率相比于目录式检索会有所下降,用户所看到的信息过于庞大,还需自身进行筛选。由于其优点突出,目前,比较流行的搜索引擎大多数采取了这一种方式,这其中代表性最强的引擎有: google(谷歌)、Baidu(百度)、360、等等。
现在网络的搜索引擎也已经有不少,国际上比较著名的有Google(谷歌)等等。国内目前也建立了很多的搜索引擎,比如:百度、360、搜狐、新浪等。其中,在信息检索的准确率和全面性这两个指标上,做得较好有Google、百度。 同时搜索引擎的准确度及相关性还是有待科技人员进一步提高和完善的。
以Google为例再具体的阐述一下,它可以在检索信息时做到了快、准、狠。它最厉害的优势在于:1、超大容量的web存储空间。据保守估计,Google目前收录的Web网页总量己经高达80亿。2、响应速度及时。据数据显示,Google(谷歌)通常搜寻所用时间大致上小于0.3 s,这么卓越的性能是基于数百台高性能的硬件服务器以及谷歌公司所使用的的分布式并行查询的系统。3、反馈信息全面。据了解,Google查询反馈的信息不仅仅集中于各个大型热门网站,同时针对的是更多的特定的Web页面(即便是存放这些页面的网站很冷门),但正是由于这样,才会使得谷歌可以获取的信息,能够和使用者查找的请求具有较高的相关度、匹配性、准确度,Google(谷歌)不断发展改善的页面优先度程序和查询到的信息最优化的排序机制,使得谷歌能够在搜索引擎中处于佼佼者的地位。
2.2 sqlserver数据库
值得介绍的是,数据库是由一个个基本的表组成的,这些表包括约束、规则、索引、触发器、函数、默认值等其他数据库对象,同时这些数据库对象都是依附于表对象而存在的。用自己的概括数据库跟表的关系:数据库是分母(无限大),表是分子(一个表对应一个单位)。
本次设计,我采用的是sqlserver数据库,主要使用的是sqlserver 2008这款软件,它的最大的优势在于:
1)可以很快捷的添加删除修改数据;
2)它的图形化界面可以很快的建立表与表之间的联系图,一个表的外键关系可以很快地建立出来;
3)有很强大的安全机制,有自己的导入导出格式,很安全;具有强大的功能,事务操作等等。
它也存在的缺点:在环境配置上要相较其他中小型的服务器要复杂一些,同时我们还知道sqlserver的语法跟mysql,orcale之间有一些像素也有一些不同,包括在转化为mysql或者orcale时都是有些差异的。
2.3 Tomcat服务器
Tomcat是一个轻量级的应用型服务器,它具有如下的优点:系统的扩展性能优越、服务器的性能非常稳定、服务器的源码开放,便于发烧友的研究与学习以及本身就带有的免费获取的机制,这都是导致Java技术研究人员里有一大批忠于Tomcat的人员。这款服务器还是目前相当流行的Web应用服务器。
我们都知道,Tomcat既是Servlet容器,还是独立的服务器,如果想要有动态泰德效果,需要把动态数据放在服务器上,基于java语言,Tomcat是一个容器,存放并且运行基于servlet的java程序,像我们熟悉的三大框架都是你可以在Tomcat跑起来的,我们通常会把写好的jsp的网站打包成一个压缩文件,然后放到服务器上,在浏览器中输入域名/网址就可以运行起来了,就可以实现跟数据库的连接,获取到动态数据。
3 搜索引擎的基本原理
3.1 搜索引擎的基本组成及其功能
由下图可知,搜索引擎程序可以化分为搜索器子程序、索引器子程序、检索器子程序以及用户接口子程序等模块;存储器以及存储桶是用来存储所检索到的各种资源的。

搜索引擎程序的组成结构具体如下:
l.搜索器 (Crawler)
搜索器,顾名思义,就是用于在互联网中探索、寻找信息,最终的目的是为了把信息存储在存储单元中的。这种计算机程序,需要日夜不停地处于运行的状态,为的是可以尽可能的更快地搜集更多的新信息,这些信息的种类是多种多样的,包括有HTML格式、XML格式、字处理文档格式以及多媒体信息等等,此外搜索引擎还需要定期更新存储器里的信息。
| 搜索器 | 即蜘蛛((Spider)程序,它无时无刻不在运行,主要任务是从因特网上搜集各种的信息资源,然后通过压缩处理等手段,使其占用空间变小,最终存到存储库里,为日候的用户检索做准备。 |
| 索引器 | 把存储库里的信息提取出来,进行识别与分析,根据结果进行分类,然后再建立索引,并进行简单的排队,把结果放在恰当的硬件存储单元里,也就是上文提到的存储桶。 |
| 检索器 | 当用户进行查询的时候,检索器会通过判断用户输入的请求,在存储桶中进行查找,将查到的结果,根据匹配度、优先度等指标进行最终的排序,呈现给用户最好的结果。 |
| 用户接口 | 是用户与搜索引擎进行人机交互的界面,既可以用于输入用户的请求,也可以用来返回查找的结果,供用户选择。 |
如今,互联网已经进入了寻常百姓的家中,人们可以自由的发布信息,导致信息更新的很快,只有定时的更新网络上的信息,才能避免使用者搜索信息时的死连接或者是无效连接。现在我们考虑的搜集信息的策略有两种:

为了提高信息的发现以及信息的更新速度, 搜索器的实现方法通常会采用分布式、并行计算技术,这样就可以满足商业搜索引擎每天几百万网页的的信息发现了。
2.索引器(Indexer)
索引器,通过阅读所搜集的信息,并进行整理,将信息中的索引项生成索引表,同时还可以用索引项表示文档。索引项有客观索引项以及内容索引项之分:

为了对文档的内容进行区分,通常会给单索引项赋权值,这样就可以用单索引项进行区分了,而且还可以用来得出查询结果与查询目标的相关度。一般使用的方法有:统计学方法、概率学方法以及信息论法。短语索引项的提取,一般会采用统计学的方法或者是概率学的方法甚至是语言学的方法。
索引表,一般会采用由索引项去查找相对应文档的内容,这就是所谓的倒排表 (InversionList)。当然,索引表还会把索引项在文档中出现的位置也记录在表,目的是为了计算索引项之间的关系,究竟是相邻还是接近。
索引器的算法有两种:集中式、分布式,每一种算法都有优点,但也都有其缺点。当搜索的数据量巨大的时候,为了解决跟上信息量上升迅速的难题,必须采取即时索引 (InstantIndexing)的方式,一个漂亮的索引算法,随着索引器的搜索的数据的提升,其性能的优越性就会展露无遗。索引的质量的高低,有时就会完全决定搜索引擎的有效性。
3.检索器(Searcher)
依照用户的查询请求,搜索索引库并快速的检索出所需的文档,然后比较所查到的文档和查询请求之间的相关度评价。最终,根据相关度的高低,将输出的查询结果进行由高到低的排序,还可以实现用户相关性与搜索引擎之间的反馈机制。
检索器的设计,目前已有四种成熟的模型:
混合的模型、代数的模型、以及概率模型、集合理论模型。
4.用户接口(UserInterface)
搜索引擎,目的是为了让用户进行检索信息,所以必须有用户接口,这样才能实现人机交互,从而才能真正的体现搜索引擎的价值。用户接口就是用来进行,将用户的查询请求输入搜索引擎、显示用户的查询结果、更高级的可以提供用户相关性反馈机制,从而更好地实现搜索引擎,其所提供的信息的准确性、合理性等等。 有了用户接口,不仅方便了用户使用搜索引擎,而且使得用户可以更加的高效率、多方式地得到及时的信息。
用户输入接口我们可以分为两类,一种是简单接口,另外一种就是与之对应的复杂接口。
简单接口,就是最为平常的一种交互界面,使用者只能够输入查询信息,不能进行更加精确地查询,而且也没有反馈的功能;
复杂接口,不仅可以提供输入查询信息的文本框,而且使用者还可以对查询得信息进行限制,减小搜索空间,例如,使用逻辑运算符、使用相近、相邻的关系、域名的范围(如.cn、.com)、出现的位置 (如题目、关键字、作者、时间)、搜索文档的字数等等。中国知网、万方数据库等等,都可以提供上述限制,由于不同的公司所用的限制方式不同,会给用户的使用带来一些不便,当前就有一些公司与机构,正在着手制定查询选项的一系列标准。
3.2 搜索引擎的详细工作流程
搜索引擎的详细软件内部构成和具体工作流程说明如下:
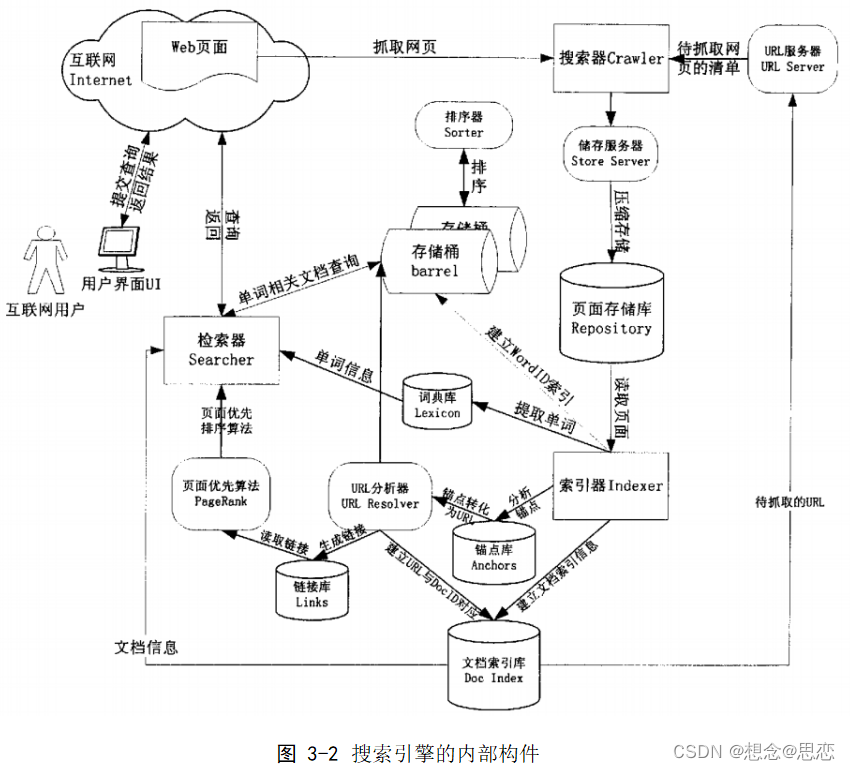
搜索引擎的工作原理:当我们在一个表单中输入要搜索的内容时,搜索引擎就会根据我们输入的内容在数据库中进行搜索,首先他会匹配各个网页中的头部信息中的关键字,如果这个网站中有这个关键字的话,就会匹配出来;如果没有的话,搜索引擎就会自动过滤掉。简单直白的说,搜索引擎的工作原理就是对已存在的一个大型数据库内的信息资源进行智能化的筛选过程,并将有效的结果反馈给用户。
在这一个过程中无论是谁家的搜索引擎,无论是百度还是谷歌还是雅虎都会采用自己的算法根据一些指标来进行判断,然后暗战关联度。高低从高到低排序。在这一过程中,需要我们在做网站的时候头部关键字部分还有超链接部分
还有在做完网站之后会引入一个文件以便收录,结合一些SEO技术,一个成功的网站是会在排名前五,而且通过一些合理的页面布局,利用不同的工具,还有超链接的设置要合理,避免垃圾链接无用链接。通过让搜索引擎爬你的网站,从而增加网站的流量,为各大站长带来收益。
我们通常会用好多指令查看某一个网站的浏览人数,但是对于每一个搜索引擎又各有各的算法,在百度适用的不一定在谷歌适用。典型的我们会通过查看看site://www.xxx.com 类型的网站,来了解某一个网站的浏览人数。