21. Hierarchical Text-Conditional Image Generation with CLIP Latents
该文提出一种基于层级式扩散模型的由文本生成图像的方法,也就是大名鼎鼎的DALLE·2。在DALLE·2之前呢,OpenAI团队已经推出了DALLE和GLIDE两个文生图模型了,其中DALLE是基于VQVAE方法的与现在流行的扩散模型不同,所以我就不详细展开了。而DALLE·2其实与同样基于扩散模型的GLIDE关系更为密切,关于GLIDE的介绍,可以参见笔者之前的博客。DALLE·2所做的工作其实在题目里面就说的很清楚了,作者首先用一个训练好的CLIP模型,将输入的文本描述转换成潜在的文本特征,然后利用一个先验模型(Prior)将这个文本特征映射成对应的图像特征,最后有一个解码器(Decoder)生成对应的图像。层级式是因为原始输出只有64 * 64的分辨率,作者通过两个级联的上采样器将其分辨率逐步提升至256 * 256和1024 * 1024。整体过程如下图所示
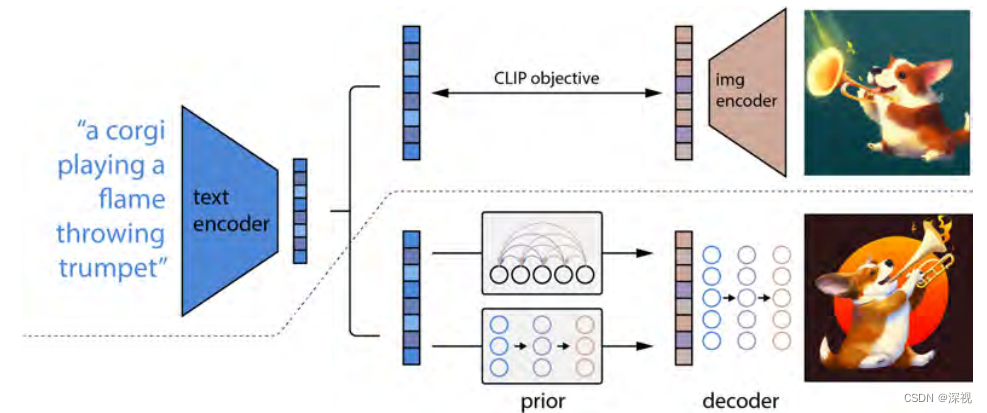
首先,作者需要按照CLIP的模式训练一个文本编码器,简单来说就是收集一些文本-图像对,用一个文本编码器将文本转换成文本特征(Text embedding),用一个图像编码器将图像转换成图像特征(Image embedding),然后利用对比学习的方法对模型进行训练,最终得到一个文本编码器和图像编码器,这个过程如图中虚线以上的部分所示。CLIP的效果非常强大,应用也是非常广泛,具体可以参考其他的讲解文章和论文。
然后,作者将训练好的文本编码器权重锁定,给定一个文本会输出一个确定的文本特征 z t z_t zt,将文本特征输入到一个先验模型(Prior)中,将其转化成一个图像特征 z i z_i zi。这个先验模型有两种实现形式:基于自回归机制(Autoregressive, AR)和基于扩散模型。AR其实是作者先前的工作DALLE中采用的技术,实验表明,二者的效果接近,但扩散模型的计算效率更高,因此作者最终采用了基于扩散模型的方案,下文中我们也主要介绍基于扩散模型的方案。得到图像特征 z i z_i zi后,作者再次利用一个基于扩散模型的图像解码器生成对应的图像。这整个过程就像是将CLIP反过来,从由图到特征,变为由特征到图,因此作者其实是称自己的模型为unCLIP。下面我们详细介绍下基于扩散模型的先验模型和图像解码器的实现方法
先验模型 Prior
在训练阶段,我们将文本的编码(这里是指采用BPE编码的编码结果,而不是CLIP输出的文本特征),CLIP输出的文本特征,扩散时间步数嵌入特征和加入随机噪声的CLIP输出的图像特征一起输入到一个带有causal attention 掩码的Transformer的解码器中。解码器直接输出无噪声的图像特征,并与真实的无噪声图像特征 z i z_i zi计算均方差损失来训练模型,如下式所示 L prior = E t ∼ [ 1 , T ] , z i ( t ) ∼ q t [ ∥ f θ ( z i ( t ) , t , y ) − z i ∥ 2 ] L_{\text {prior }}=\mathbb{E}_{t \sim[1, T], z_{i}^{(t)} \sim q_{t}}\left[\left\|f_{\theta}\left(z_{i}^{(t)}, t, y\right)-z_{i}\right\|^{2}\right] Lprior =Et∼[1,T],zi(t)∼qt[ fθ(zi(t),t,y)−zi 2]这里的先验模型与常见的扩散模型有很多不同,首先,其输入是文本特征 z t z_t zt,输出是图像特征 z i z_i zi,其更接近StableDiffusion中的方法,在特征层面上进行扩散和采样。其次,先验模型采用的是Casual Transformer模型而不是常见的UNet模型。最后,模型直接预测的是采样结果,即无噪声的图像特征,而不是常见的噪声均值。
在推理阶段,我们还是可以根据输入的文本描述得到对应的文本编码和文本特征,然后从随机高斯分布中采样得到 t t t时刻的图像特征 z i ( t ) z_i^{(t)} zi(t)并与时间步数 t t t编码一起输入到训练好的先验模型中,得到去噪后的图像特征 z i z_i zi。
这里其实有一点疑问,就是如果按照典型的扩散模型采样流程,应该是先预测得到 t − 1 t-1 t−1时刻的图像特征 z i ( t − 1 ) z_i^{(t-1)} zi(t−1),然后再逐步的去噪得到最终的图像特征 z i z_i zi。但是按照训练过程来看,他是直接预测去噪后的图像特征 z i z_i zi的,因此这一点可能还需要阅读代码来确认。
解码器 Decoder
这里的解码器也与很多AE中的解码器概念不太一样,它并不是直接把前面得到的图像特征解码重建得到图像,而是依旧采用一个扩散模型,将前文得到的图像特征与输入的文本特征一起作为一个条件引导信息,来引导扩散模型完成图像的采样。那么图像特征和文本特征如何构成条件来引导扩散模型呢?一方面,图像特征经过映射后直接加到时间步数嵌入上作为一个条件输入,另一方面,图像特征映射为四个额外的Token并与文本特征序列级联起来也作为一个条件输入。扩散模型采用IDDPM,随机采样 t t t时刻噪声图像,与上述两个条件一起输入到模型中输出噪声分布的均值,然后从中采样得到一个噪声,经过去噪后得到 t − 1 t-1 t−1时刻的图像,迭代上述过程直至得到无噪声图像 x 0 x_0 x0。下图引用自知乎用户“莫叶何竹”的博文
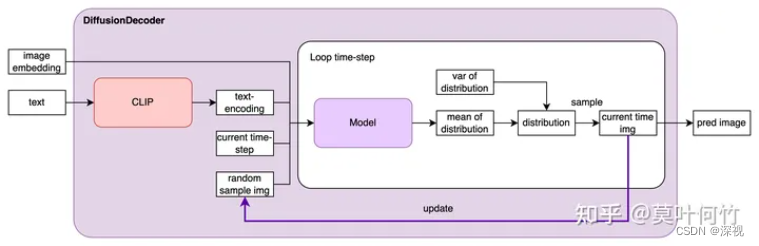
在训练过程中,作者也采用了无分类器引导扩散模型(CDM)中的训练技巧,随机抛弃掉10%的图像特征输入和50%的文本特征。最后,为了提升生成图像的分辨率,作者训练了两个级联的基于卷积模型的上采样器,逐步将图像分辨率提升至256 * 256 和 1024 * 1024。
作者在MS-COCO数据集上测试了文本-图像的生成效果,并与其他方法做了对比,效果如下

此外,作者还做了许多有趣的实验。首先,给定一幅照片经过编码处理后可得到图像特征 z i z_i zi,然后将其作为条件信息与随机采样的噪声图像一起输入到解码器中就可以得到重建后的图像,如下图所示。可以看到重建后的图像与原图保持了风格和基本布局上的一致,但在细节上呈现了更多的多样性。

然后,作者实现了两个图像的融合,分别从两幅图像得到对应的特征 z i 1 z_{i_1} zi1和 z i 2 z_{i_2} zi2,然后采用球形插值得到插值后的图像特征 z i θ = slerp ( z i 1 , z i 2 , θ ) z_{i_{\theta}}=\operatorname{slerp}\left(z_{i_{1}}, z_{i_{2}}, \theta\right) ziθ=slerp(zi1,zi2,θ), θ \theta θ的取值范围是[0,1]。将插值后的特征输入到编码器中,就能得到两幅图像逐渐融合的过程,如下图所示

最后,作者还尝试了文本差异引导图像生成,假设原始图像的文本描述特征为 z t 0 z_{t_0} zt0,目标文本描述特征为 z t z_{t} zt,则可以计算文本特征差异 z d = norm ( z t − z t 0 ) z_d=\text{norm}(z_{t}-z_{t_0}) zd=norm(zt−zt0),将 z d z_d zd与图像特征 z i z_i zi进行球形插值 z θ = slerp ( z i , z d , θ ) z_{{\theta}}=\operatorname{slerp}\left(z_{i}, z_{d}, \theta\right) zθ=slerp(zi,zd,θ),再进行图像生成,就能得到从原始图像过渡到目标图像之间的过程,如下图所示

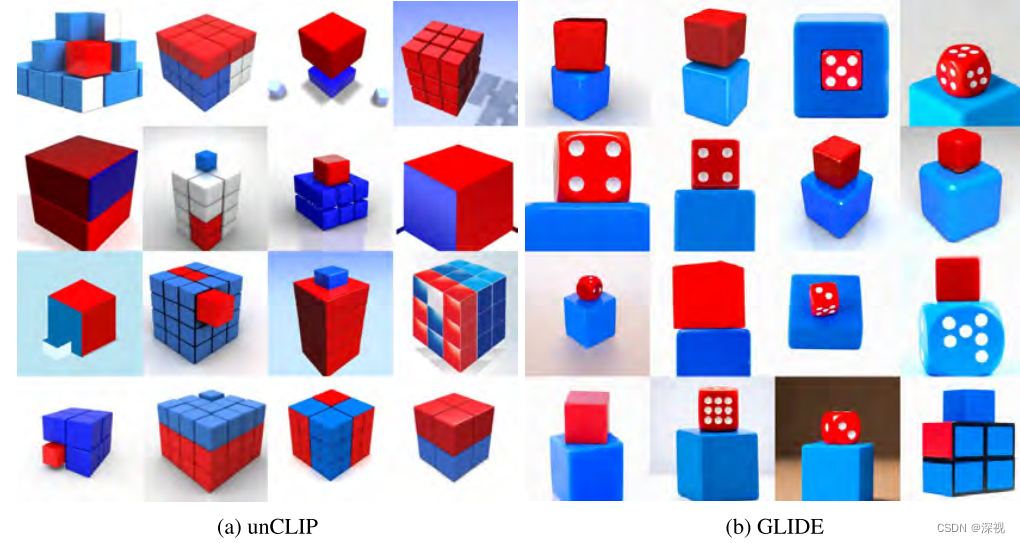
即使DALLE·2已经取得了非常惊艳的生成效果,但在许多任务中仍存在一定的缺陷和局限性。例如,无法将图像的内容和属性对齐,如下图它无法理解“把红色方块放到蓝色方块”上的操作,只是生成了包含红色方块和蓝色方块的图片,这一点上GLIDE表现得要更好
此外,在生成一个带有文本的图像时,DALLE·2的生成效果也是一塌糊涂,字母的顺序都是凌乱的。

由于图像是从低分辨率图像逐渐上采样得到高分辨率图像的,因此在生成高质量图像时,经常出现许多细节上的缺失和错乱,如下图所示