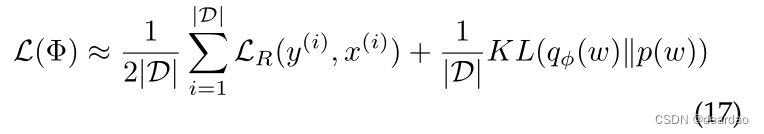1. 到底什么是数据结构?
数据结构是指在计算机中组织和存储数据的方式,它涉及到数据元素之间的关系以及对这些关系进行操作的方法。数据结构可以看作是一种将数据组织起来以便有效使用的方式,它关注数据的组织、存储和操作,以及如何优化这些操作以提高计算机程序的性能和效率。常见的数据结构包括:数组、链表、栈、队列、树、图等。每种数据结构都有其特定的优缺点和适用场景,程序员在设计和实现算法时需要根据实际情况选择合适的数据结构。
2. 抽象数据类型
抽象数据类型(Abstract Data Type,ADT)是一种数学模型或者说是一种数据模型,用来描述数据对象的逻辑结构以及对这些对象进行操作的方法。它主要关注数据的逻辑特性而不涉及具体的实现细节,是一种对数据结构的抽象描述。
ADT 的定义包括两个部分:
①. 数据对象集(Data Objects):即数据的逻辑结构,描述了数据对象的属性和关系。
②. 操作集(Operations):定义了对数据对象进行的操作,包括:对数据的创建、销毁、添加、删除、修改、查询等操作。
举个例子,以栈(Stack)为例,栈是一种具有先进后出(LIFO)特性的数据结构。其数据对象集可以描述为一组元素,这些元素按照入栈顺序排列;而操作集包括入栈(Push)、出栈(Pop)、判空(isEmpty)、获取栈顶元素(Top)等操作。
在实际编程中,ADT 提供了一种规范的描述方式,可以让程序员在实现数据结构时更加专注于数据结构的逻辑特性而不必过多关注具体的实现细节。常见的 ADT 包括:栈、队列、链表、树等,它们在计算机科学领域中被广泛应用于解决各种问题。
3. 什么是算法
算法是指解决特定问题或执行特定任务的一组有限步骤的规则或者指令。它是一种对问题进行抽象和描述的方式,能够在计算机或者其他设备上被实现和执行。算法通常包括输入(Input)、处理(Processing)和输出(Output)三个基本部分,它们描述了算法如何接受输入数据、对数据进行处理,并生成输出结果。
算法的特点包括:
①. 有限性:算法必须由有限个步骤组成,且在有限时间内执行完成。
②. 确定性:算法的每一步骤必须精确地定义,没有歧义,不会出现二义性。
③. 有效性:算法必须能够解决特定问题,即能够产生正确的输出结果。
④. 输入输出:算法必须接受输入数据,并根据输入产生输出结果。
⑤. 可行性:算法必须是可以实现和执行的,能够利用计算机或其他工具来进行实际操作。
算法在计算机科学和信息技术领域中扮演着非常重要的角色,它们被广泛用于解决各种问题,例如:排序、搜索、优化、数据处理等。
算法的设计和分析涉及到:时间复杂度、空间复杂度、正确性、可读性等方面,对于提高程序性能、优化资源利用、提升用户体验等方面具有重要意义。
3.1 什么是好的算法
时间复杂度[S(n)]和空间复杂度[T(n)]是衡量算法性能的两个重要指标。
时间复杂度(Time Complexity):时间复杂度是对算法运行时间的估计,通常用大O符号(O)来表示。它描述了算法的运行时间随着输入规模增大而增长的趋势。时间复杂度可以分为:最坏情况时间复杂度、平均情况时间复杂度和最好情况时间复杂度,其中最坏情况时间复杂度是最常用的衡量指标。
空间复杂度(Space Complexity):空间复杂度是对算法所需存储空间的估计,通常也用大O符号表示。它描述了算法在运行过程中所需的额外空间随着输入规模增大而增长的趋势。
在分析算法性能时,常常关注算法的时间复杂度和空间复杂度,因为它们能够帮助我们评估算法在大规模数据处理时的效率和资源消耗情况,从而选择合适的算法来解决问题。
3.2 时间复杂度的渐进表示法
时间复杂度的渐进表示法是用来描述算法运行时间或空间需求与输入数据量之间关系的数学模型。主要有以下几种符号:
-
大O表示法 (O-notation):用于描述算法的上界,表示算法在最坏情况下的运行时间。形式为 𝑂(𝑓(𝑛)),意味着存在常数 𝐶 和
,使得对所有 𝑛≥
-
大Ω表示法 (Ω-notation):用于描述算法的下界,表示算法在最好情况下的运行时间。形式为 Ω(𝑔(𝑛)),意味着存在常数 𝐶和
-
大Θ表示法 (Θ-notation):用于精确描述算法的界限,当算法的上界和下界相同时使用。形式为 Θ(ℎ(𝑛)),意味着同时满足大O和大Ω的条件,即存在常数 𝐶1,𝐶2 和
-
小o表示法 (o-notation):用于描述算法的非紧致上界,即 𝑇(𝑛) 在 𝑓(𝑛)增长速度之下但没有达到 𝑓(𝑛)的速度。形式为 𝑜(𝑓(𝑛)),意味着对于任何常数 𝐶>0,存在
-
小ω表示法 (ω-notation):用于描述算法的非紧致下界,即 𝑇(𝑛)在 𝑔(𝑛)增长速度之上但不是其严格的下界。形式为 𝜔(𝑔(𝑛)),意味着对于任何常数 𝐶>0,存在
3.3 常见的时间复杂度
①. 常数时间复杂度 O(1): 不管数据量多大,算法所需的时间总是固定的。例如,访问数组的某个具体位置。
②. 对数时间复杂度 O(log n): 随着输入数据量的增加,算法执行时间的增长速度逐渐减慢。典型的例子是二分查找。
③. 线性时间复杂度 O(n): 算法执行时间与输入数据的大小成正比。例如,遍历一个数组。
④. 线性对数时间复杂度 O(nlog n): 比线性时间复杂度慢,常见于某些高效的排序算法,如快速排序和归并排序。
⑤. 二次时间复杂度 O(): 算法执行时间与输入数据量的平方成正比。典型的例子包括:简单排序算法,如冒泡排序和插入排序。
⑥. 立方时间复杂度 O(): 算法执行时间与输入数据量的立方成正比,例如,三重循环的简单算法。
⑦. 指数时间复杂度 O(): 算法的执行时间随数据量指数级增长,这在某些递归算法中常见。
⑧. 阶乘时间复杂度 O(n!): 算法的执行时间随输入数据的阶乘增长,典型的例子是求解旅行推销员问题的穷举搜索。
作为程序员,通常应该朝着具有较低时间复杂度的算法努力。这意味着尽可能选择和设计时间复杂度较低的算法,以提高程序的效率和性能。以下是一些具体的建议:
①. 避免指数级和阶乘级复杂度:应尽量避免设计指数级(O())和阶乘级(O(n!))时间复杂度的算法,因为它们在处理大规模数据时会非常低效。
②. 优先选择线性对数级及以下复杂度:优先选择具有线性对数级(O(n log n))及以下时间复杂度的算法,例如快速排序、归并排序等。这些算法在大部分情况下都能提供良好的性能。
3.4 分析时间复杂度小窍门
①. 若两段算法 分别有复杂度和
,则
②. 若是关于n的k阶多项式,那么
③. 一个for循环的时间复杂度等于:循环次数乘以循环体代码的复杂度;
④. if-else结构的复杂度取决于if的条件判断复杂两个分枝部分的复杂度,总体复杂度取三者中最大;


![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-13-按键实验](https://img-blog.csdnimg.cn/direct/bcad413e52ca4f1e9869c1882c8541c1.png)