pandas入门
- 一、pandas简介
- 1.1 pandas介绍
- 1.2 pandas的基本功能
- 二、pandas快速入门
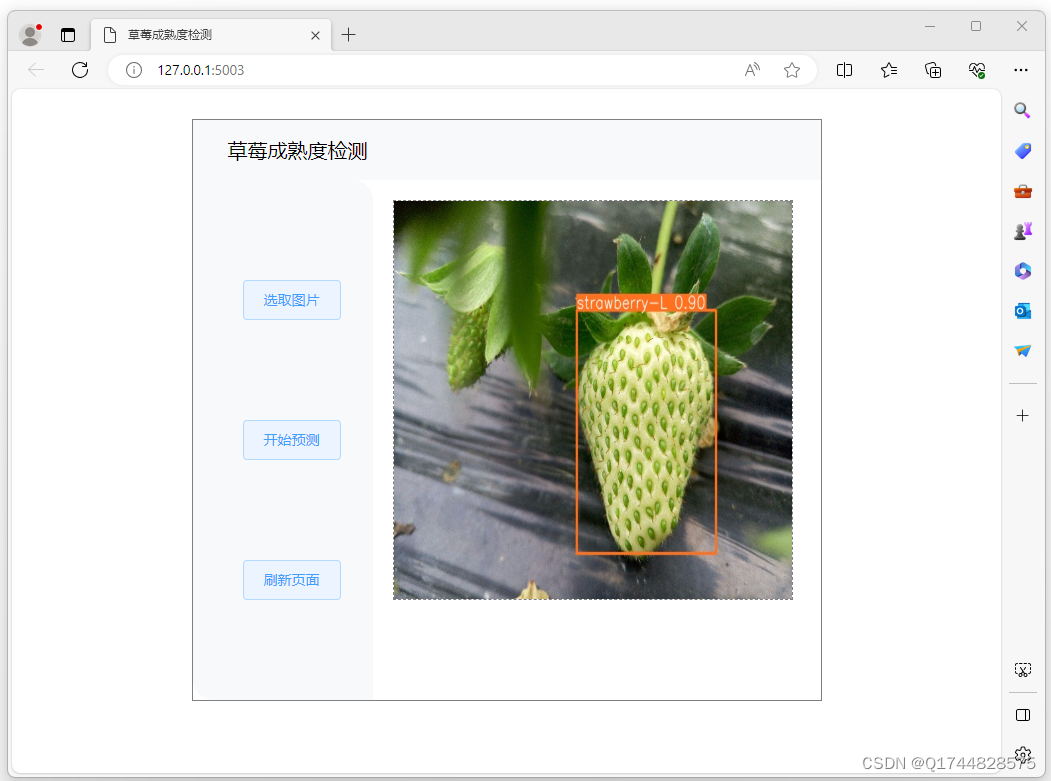
- 2.1 读取数据
- 2.2 验证数据
- 2.3 建立索引
- 2.4 数据抽取
- 2.4.1 选择列
- 2.4.2 选择行
- 2.4.3 指定行和列
- 2.5 排序
- 2.6 分组聚合
- 2.7 数据转置
- 2.8 增加列
- 2.9 统计分析
一、pandas简介
1.1 pandas介绍
pandas是使用Python语言开发的用于数据处理和数据分析的第三方库。它擅长处理数字型数据和时间序列数据,文本型的数据也能轻松处理。
1.2 pandas的基本功能
1、从Excel、csv、网页、SQL等文件或工具中读取数据;
2、合并多个文件或者电子表格中的数据,将数据拆分为独立文件;
3、数据清洗,如去重、处理缺失值、填充默认值、补全格式、处理极端值等;
4、建立高效的索引;
5、按一定的业务逻辑插入计算后的列、删除列;
6、灵活方便的数据查询、筛选;
7、分组聚合数据,可独立指定分组后的各字段计算方式;
8、数据的转置,如行转列、列转行变更处理;
9、对时序数据进行分组采样,如按季、按月、按工作小时,也可以自定义周期,如工作日;
10、等等。
二、pandas快速入门
2.1 读取数据
本次演示采用的数据集是学生成绩数据集。首先,将数据读取到pandas里,变量名用df。
import pandas as pd # 导入pandas库,起别名dfdf = pd.read_excel('team.xlsx') # team.xlsx文件与notebook文件或py文件在同一目录下
看一下数据集的情况:

2.2 验证数据
下面是一些常用的验证数据的代码,可以执行看看效果(一次执行一行):
df.shape # (100,6)查看行数和列数
df.info() # 查看索引、数据类型和内存信息
df.describe() # 查看数值型列的汇总统计
df.dtypes # 查看各字段类型
df.axes # 查看数据行和列名
df.index # 行名
df.columns # 列名
2.3 建立索引
以下代码将name列设置为索引:
df.set_index('name', inplace=True)
其中可选参数inplace=True会将指定好索引的数据再赋值给df使索引生效,否则索引不会生效。注意,这里并没有修改原Excel,从我们读取数据后就已经和它没有关系了,我们处理的内存中的df变量。
再来查看一下索引列更改之后的数据,使用代码df.head()查看:

2.4 数据抽取
2.4.1 选择列
选择列的方法有如下几种:
df['Q1'] # 查看指定列
df.Q1 # 同上,如果列名符合Python变量名要求,可使用
df[['Q1', 'Q2']] # 选择两列
df.loc[:, ['team', 'Q1']] # 和上一行效果一样
2.4.2 选择行
# 用指定索引选取
df[df.index=='Arry']# 用自然索引选取,类似列表的切片
df[0:3] # 选择前三行
df[0:20:2] # 添加了步长
df.iloc[:10, :] # 选取前10行
2.4.3 指定行和列
同时选取行和列的范围:
df.loc['Ben', 'Q1':'Q4'] # 查看Ben的四个季度成绩
df.loc['Eorge':'Alexander', 'team':'Q4'] # 同时指定行和列区间
2.5 排序
示例如下:
df.sort_values(by='Q1') # 按Q1列升序排序
df.sort_values(by='Q2', ascending=False) # 按Q2列降序排序,ascending是上升的意思
df.sort_values(by=['team', 'Q1'], ascending=[True, False]) # team升序,Q1降序
2.6 分组聚合
我们可以实现类似SQL的groupby那样的数据透视功能:
df.groupby('team').sum() # 按团队分组对应列求和
# 不同列不同的计算方法
df.groupby('team').agg({'Q1':'sum', # 求和'Q2':'count', # 总数'Q3':'mean', # 平均值'Q4':'max'}) # 最大值
2.7 数据转置
数据的转置非常简单,在DataFrame后面加T即可,示例如下:
df.head().T
对比一下转置前和转置后的数据:


2.8 增加列
用pandas增加一列非常方便,就与新定义一个字典的键值对一样。
df['one'] = 1 # 增加一个固定值的列
df['total'] = df.Q1 + df.Q2 + df.Q3 + df.Q4 # 增加总成绩列
# 将计算得来的结果赋值给新列
df['total'] = df.loc[:, 'Q1':'Q4'].apply(lambda x:sum(x), axis=1)
df['total'] = df.sum(axis=1) # 可以把所有为数字的列相加
df['avg'] = df.total / 4 # 增加平均成绩列
2.9 统计分析
df.loc[:, 'Q1':'Q4'].mean() # 返回所有列的均值
df.loc[:, 'Q1':'Q4'].mean(1) # 返回所有行的均值
df.loc[:, 'Q1':'Q4'].corr # 返回列与列之间的相关系数
df.count() # 返回每一列的非空值的个数
df.max() # 返回每一列的最大值
df.min() # 最小值
df.median() # 中位数
df.std() # 标准差
df.var() # 方差