论文地址:https://arxiv.org/abs/2211.12905
代码地址:https://github.com/huawei-noah/Efficient-AI-Backbones/tree/master/ghostnetv2_pytorch
解决了什么问题?
在计算机视觉领域,深度神经网络在诸多任务上扮演着重要角色。为了将神经网络部署在边缘设备如手机和可穿戴设备,我们不只要考虑模型的表现,也要考虑其效率,尤其是实际的推理速度。矩阵乘法占据了算力消耗和参数量的主要部分。设计轻量级模型能显著降低推理延迟。
基于卷积的轻量级模型不擅长建模远距离的依赖关系,只能获取窗口区域内的局部信息,使性能无法进一步提升。在卷积中引入自注意力可以获得全局信息,但会制约实际的速度。常用的自注意力模块需要很高的复杂度,对低算力不友好。此外,需要对特征做大量的 split 和 reshape 操作,从而计算注意力图。尽管理论复杂度可忽略不计,但这些操作会增加内存占用和延迟。因此,在轻量级模型中使用原版的子注意力不适合移动设备。
提出了什么方法?
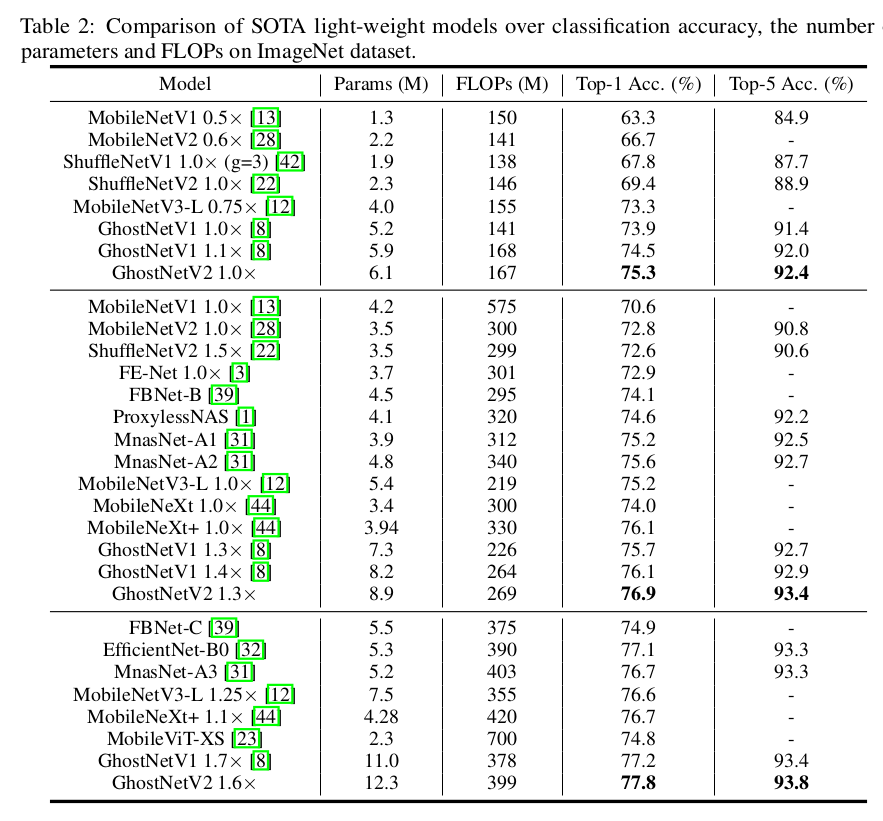
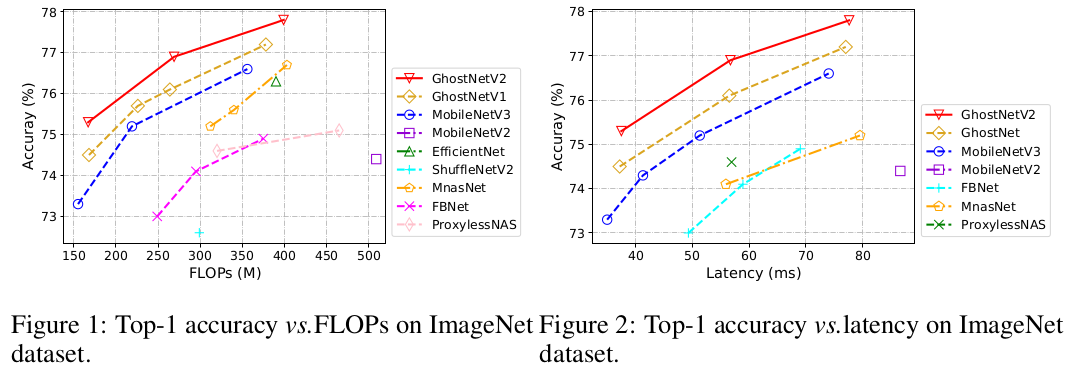
本文提出了一个硬件友好的注意力机制(叫 DFC 注意力),然后针对移动设备提出了一个新的 GhostNetV2 架构。DFC 注意力由全连接层组成,在常用的硬件上不只计算速度快,而且也可以获取远距离像素之间的关系。作者进一步分析了之前的 GhostNet,用带 DFC 注意力的低成本操作输出扩展特征,这样 GhostNetV2 能同时聚合局部和远距离的信息。在 ImageNet-1K 上,它取得了 75.3 % 75.3\% 75.3% 的准确率,FLOPs 为 167 M 167M 167M。
为了简洁,只有全连接层参与注意力图的生成。一个全连接层被拆分成水平方向的全连接和垂直方向的全连接,聚合 2D 特征图的像素。这两个 FC 层会将各自方向上距离较远的像素都涵盖进来,把它们堆叠到一起,从而产生全局感受野。此外,作者回顾了 GhostNet 的表征瓶颈,通过 DFC 层来加强中间特征。然后作者构建了一个轻量级的视觉主干 GhostNetV2。
GhostNet 回顾
GhostNet 是针对移动设备设计的轻量级模型,能进行高效的推理。它主要的模块是 Ghost 模块,利用低成本操作生成出更多的特征图,从而替换原始的卷积。给定输入特征 X ∈ R H × W × C X\in \mathbb{R}^{H\times W\times C} X∈RH×W×C,Ghost 模块通过两步替换标准卷积。首先,用一个 1 × 1 1\times 1 1×1卷积来生成 intrinsic 特征,
Y ′ = X ∗ F 1 × 1 Y'=X \ast F_{1\times 1} Y′=X∗F1×1
其中, ∗ \ast ∗ 表示卷积操作, F 1 × 1 F_{1\times 1} F1×1 表示 pointwise conv, Y ′ ∈ R H × W × C o u t ′ Y'\in\mathbb{R}^{H\times W\times C'_{out}} Y′∈RH×W×Cout′ 是 intrinsic 特征,该特征的尺寸要小于原始输出的特征 C o u t ′ < C o u t C'_{out}<C_{out} Cout′<Cout。然后,使用低成本操作(如深度卷积)来计算 intrinsic 特征,从而生成更多的特征。然后沿着通道维度,将这两部分特征 concat 一起:
Y = Concat ( [ Y ′ , Y ′ ∗ F d p ] ) Y=\text{Concat}([Y', Y' \ast F_{dp}]) Y=Concat([Y′,Y′∗Fdp])
其中 F d p F_{dp} Fdp 是深度卷积滤波器, Y ∈ R H × W × C o u t Y\in\mathbb{R}^{H\times W\times C_{out}} Y∈RH×W×Cout 是输出特征。尽管 Ghost 模块能够大幅度降低计算成本,但表征能力还是被弱化了。要想准确的识别,像素之间的关系至关重要。在 GhostNet 中,只用到了廉价的操作( 3 × 3 3\times 3 3×3 深度卷积)来获取空间信息,只占特征的一半。其余的特征是通过 1 × 1 1\times 1 1×1 pointwise 卷积产生的,没有和其他像素有任何交流。获取的空间信息不足会阻碍模型的表现进一步提升。
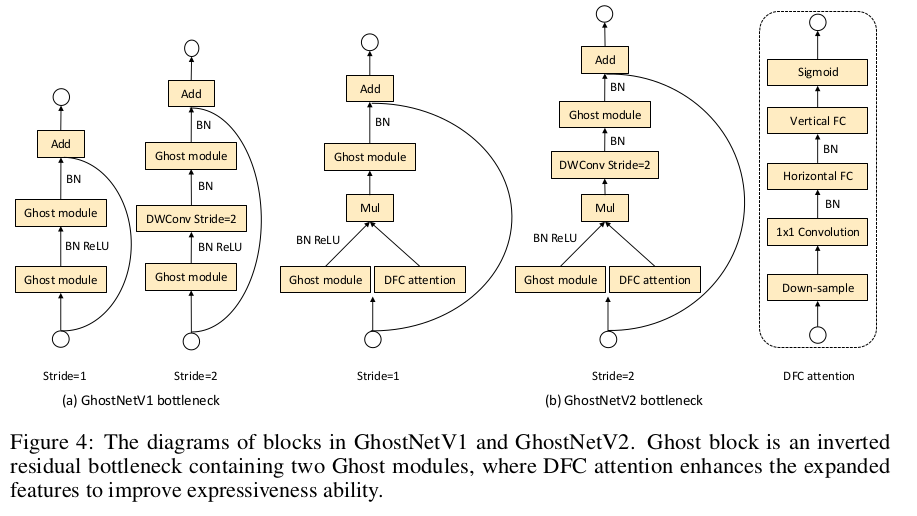
GhostNet block 是用两个堆叠的 Ghost module 构成的,如下图 a 所示。与 MobileNetV2 类似,它也是一个 inverted bottleneck,第一个模块是扩展层,增加输出通道数,第二个模块降低通道数来匹配短路连接的输出。
回顾移动架构的注意力机制
注意力模型最近也引入到了计算机视觉任务。ViT 使用标准的 transformer 模型,它由自注意力模块和 MLP 模块组成。Wang 等人将自注意力操作插入到了卷积网络中,获取全局信息。注意力模块的复杂度通常是关于特征尺寸的二次方程,对于高分辨率图像(目标检测和语义分割任务)就比较困难了。
主流的降低注意力复杂度的策略是将图像切分成多个窗口,在每个窗口内和跨窗口进行注意力操作。例如,Swin-Transformer 将原始特征图切分为多个非重叠窗口,在局部窗口内计算自注意力。MobileViT 将特征展开为多个非重叠的区域,计算这些区域之间的注意力。对于 CNN 的 2D 特征图,做特征切分和注意力会增加一些 tensor reshape 和转置操作,其理论复杂度可忽略,但事实上并非如此。对于高复杂度的大模型中(Swin-B 的 FLOPS 有几十亿次),在每次推理时这些操作只占一小部分。对于轻量级模型,这些部署延迟可忽略不计。
本文中,作者将 MobileViT 中的自注意力加入到了 GhostNet 中,在 Huawei P30 上用 TFLite 工具评测其延迟性。作者使用了标准的 ImageNet 输入分辨率 224 × 224 224\times 224 224×224。理论上注意力机制只增加了 20 % 20\% 20% 的 FLOPs,但是在移动设备上增加了一倍的推理时间。理论和实际复杂度之间的巨大差异说明,针对移动设备设计一个硬件友好的注意力机制是非常必要的。
方法
DFC 注意力

作者介绍了如何为移动端 CNN 设计一个注意力模块,它应该具备以下特性:
- 长距离:要想增强表征能力,获取长距离空间信息对注意力机制来说是非常关键的,小型 CNN 为了节省成本,通常只使用了小型的卷积核( 1 × 1 1\times 1 1×1卷积)。
- 部署高效:注意力模块应该极其高效,以免降低推理速度。我们不希望出现高 FLOPs 的操作或硬件不友好的操作。
- 概念简洁:为了保持模型的泛化能力,该注意力应该非常简洁。
尽管自注意力能够很好地建模长距离像素关系,但部署起来并不高效。权重固定的全连接层非常简单,且部署简单,可以用全局感受野产生注意力图。计算过程如下:
给定特征 Z ∈ R H × W × C Z\in\mathbb{R}^{H\times W\times C} Z∈RH×W×C,可以看作为 H W HW HW 个 tokens z i ∈ R C \mathcal{z}_i \in\mathbb{R}^C zi∈RC,即 Z = { z 11 , z 12 , . . . , z H W } Z=\{\mathcal{z}_{11}, \mathcal{z}_{12}, ..., \mathcal{z}_{HW}\} Z={z11,z12,...,zHW}。产生注意力图的 FC 层的具体实现如下:
a h w = ∑ h ′ , w ′ F h w , h ′ w ′ ⊙ z h ′ w ′ \mathcal{a}_{hw}=\sum_{h',w'}{F_{hw, h'w'}\odot \mathcal{z}_{h'w'}} ahw=h′,w′∑Fhw,h′w′⊙zh′w′
其中 ⊙ \odot ⊙是逐元素相乘。 F F F是全连接层的权重, A = { a 11 , a 12 , . . . , a H W } A=\{\mathcal{a}_{11}, \mathcal{a}_{12},...,\mathcal{a}_{HW}\} A={a11,a12,...,aHW} 是生成的注意力图。上式能捕捉到全局信息,通过权重 F F F 聚合所有的 tokens,这要比自注意力简单多了。但是,该计算过程的复杂度关于特征大小仍然是二次方程,即 O ( H 2 W 2 ) \mathcal{O}(H^2W^2) O(H2W2),这在高分辨率输入图像场景中难以接受。比如,GhostNet 的第四层的特征图有 3156 ( 56 × 56 ) 3156(56\times 56) 3156(56×56)个 tokens,计算注意力图就复杂度太高了。实际上,CNN 的特征图通常是 low-rank 的,并不需要将不同空间位置的所有的输入和输出 tokens 都密集地连接起来。特征图的 2D 形状自然地提供了一个方法来降低 FC 层的复杂度,将上式拆分成两个 FC 层,然后沿着水平和垂直方向聚合特征。表示如下:
a ′ h w = ∑ h ′ = 1 H F h , h ′ w H ⊙ z h ′ w , h = 1 , 2 , . . . , H , w = 1 , 2 , . . . , W \mathcal{a'}_{hw}=\sum_{h'=1}^H{F^H_{h,h'w} \odot \mathcal{z}_{h'w}}, h=1,2,...,H, w=1,2,...,W a′hw=h′=1∑HFh,h′wH⊙zh′w,h=1,2,...,H,w=1,2,...,W
a h w = ∑ w ′ = 1 W F w , w ′ w W ⊙ a ′ h w ′ , h = 1 , 2 , . . . , H , w = 1 , 2 , . . . , W \mathcal{a}_{hw}=\sum_{w'=1}^W{F^W_{w,w'w} \odot \mathcal{a'}_{hw'}}, h=1,2,...,H, w=1,2,...,W ahw=w′=1∑WFw,w′wW⊙a′hw′,h=1,2,...,H,w=1,2,...,W
其中 F H F^H FH 和 F W F^W FW 是权重。以原始特征 Z Z Z 作为输入,依次地输入上面式子,分别沿着高度和宽度两个方向计算得到长距离依赖关系。作者将这个操作命名为 decoupled fully connected(DFC) 注意力,如上图所示。将水平和垂直变换拆分后,注意力模块的计算复杂度降低到了 O ( H 2 W + H W 2 ) \mathcal{O}(H^2W+HW^2) O(H2W+HW2)。在全注意力中,方块中的所有区域都直接参与到了受关注区域的计算。在 DFC 注意力中,一个区域只和它水平和垂直方向的区域做直接的融合,而其它区域只参与受关注 token 的水平和垂直方向的区域的生成,它们与受关注 token 只有间接的关联。因此,方块中所有的区域都参与到了各区域的计算。
上面两个式子表示了 DFC 注意力,分别沿着水平和垂直方向聚合像素。通过共享部分的权重,它能很方便地用卷积实现,省去了推理耗时的 tensor reshape 和转置操作。为了处理不同分辨率的输入图像,滤波器大小可以解耦成特征图大小,即对输入特征图应用两个大小分别是 1 × K H 1\times K_H 1×KH 和 K W × 1 K_W\times 1 KW×1 的深度卷积。用卷积实现时,DFC 注意力的理论复杂度就是 O ( K H H W + K W H W ) \mathcal{O}(K_HHW + K_WHW) O(KHHW+KWHW)。TFLite 和 ONNX 可以很好地支持这个策略,方便移动端部署。
GhostNet V2
本文,作者使用 DFC 注意力来提升轻量级模型的表征能力,然后提出了新的主干网络 GhostNetV2。
增强 Ghost 模块
如上所述,Ghost 模块只有一半的特征会和其它像素交互,这破坏了空间信息获取的能力。因此,作者使用 DFC 注意力来增强 Ghost 模块的输出特征 Y Y Y,获取不同的空间像素的长距离依赖关系。
将输入特征 X ∈ R H × W × C X\in \mathbb{R}^{H\times W\times C} X∈RH×W×C 输入两个分支,一个 Ghost 模块产生输出特征 Y Y Y,另一个输入 DFC 模块产生注意力图 A A A。在自注意力中,线性变换层用于将输入特征变换成 query 和 key 来计算注意力图。类似地,作者使用了 1 × 1 1\times 1 1×1 卷积将模块的输入 X X X 变换成 DFC 的输入 Z Z Z。最终的输出 O ∈ R H × W × C O\in \mathbb{R}^{H\times W\times C} O∈RH×W×C 是两个分支输出的乘积:
O = Sigmoid ( A ) ⊙ V ( X ) O = \text{Sigmoid}(A)\odot \mathcal{V}(X) O=Sigmoid(A)⊙V(X)
其中 ⊙ \odot ⊙ 是逐元素相乘, Sigmoid \text{Sigmoid} Sigmoid是缩放函数,将注意力图 A \mathcal{A} A归一化到 ( 0 , 1 ) (0,1) (0,1)之间。
该信息聚合的过程如下图所示。对于相同的输入,Ghost 模块和 DFC 注意力是两个平行的分支,从不同的角度提取信息。二者的乘积就是输出结果,包含了 Ghost 模块的特征和 DFC 注意力的信息。每个注意力值的计算都涉及了距离远的区域,输出特征就包含了这些区域的信息。

特征下采样
Ghost 模块直接和 DFC 注意力并行计算会增加一些计算量。因此,作者通过水平和垂直方向的下采样来降低特征图尺寸,这样 DFC 注意力的所有操作都可以在更小的特征上进行。宽度和高度都默认缩放为原来的一半,这降低了 DFC 注意力 75 % 75\% 75% 的 FLOPs。然后将输出特征图上采样到原来的尺寸,从而匹配上 Ghost 分支的特征尺寸。对于下采样作者使用了 average pool,对于上采样使用了双线性插值。直接使用 sigmoid 函数会增加延迟,作者因此也在下采样后的特征图上使用了 sigmoid 函数,从而降低推理时间。尽管注意力图的值可能不在 ( 0 , 1 ) (0,1) (0,1) 区间,作者发现其对模型的最终表现影响微乎其微。
GhostV2 bottleneck
GhostNet 采用了包括了两个 Ghost 模块的倒转残差 bottleneck,第一个模块产生更多通道的扩展特征,第二个降低通道数来获取输出特征。这个倒转 bottleneck 天然地拆分了模型的 expressiveness 和 capacity。前者体现在扩展特征上,后者体现在模块的输入和输出上。原始的 Ghost 模块通过廉价操作生成部分特征,但损害了 expressiveness 和 capacity。通过比较将 DFC 注意力加在扩展特征还是输出特征上的表现,作者发现增强 expressiveness 更有效。因此,作者只将扩展特征和 DFC 注意力相乘。
图4b 展示了 GhostNetV2 的 bottleneck。DFC 注意力分支与第一个 Ghost 模块平行,增强扩展特征。然后该特征输入第二个 Ghost 模块来产生输出特征。它获取了不同空间位置的像素之间远距离依赖关系,增强模型的 expressiveness。