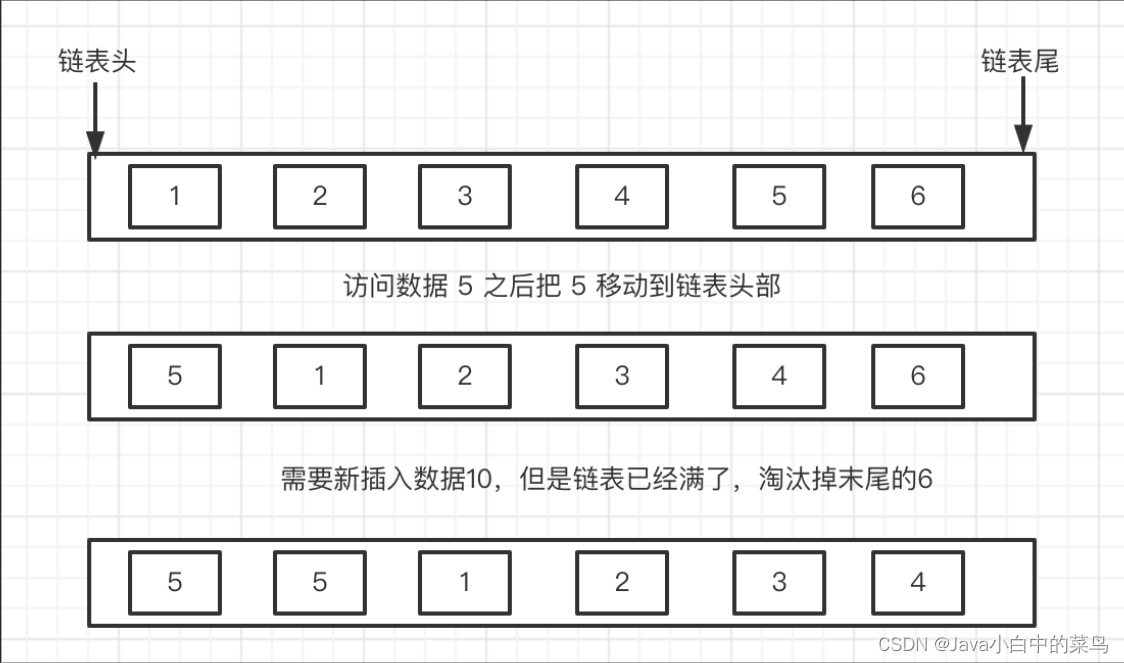
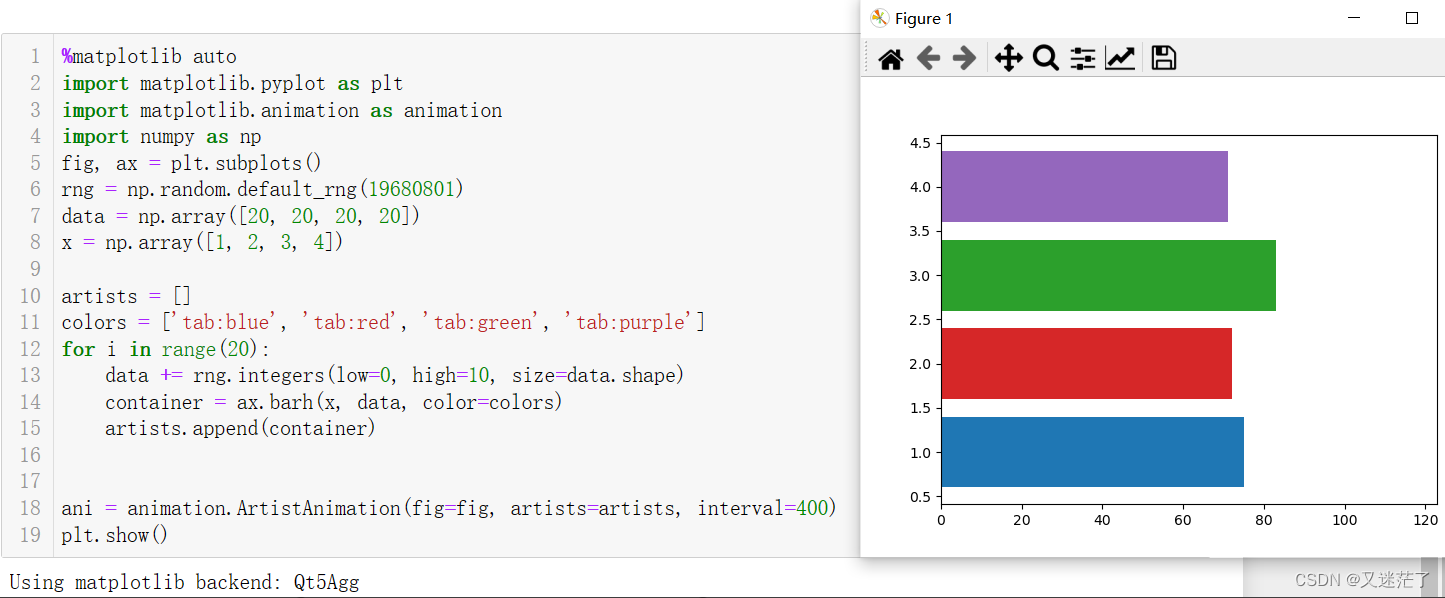
缓存淘汰算法中,LRU(Least Recently Used)算法是一种常见的算法。它的基本思想是根据最近的访问情况来决定哪些数据被保留在缓存中,哪些数据被淘汰出去。
具体来说,当需要从缓存中淘汰数据时,LRU算法会选择最近最少被访问的数据进行淘汰。这通常可以通过使用一个队列或双向链表来实现:新访问的数据被移到队列或链表的头部,而最久未被访问的数据则位于尾部。当缓存达到容量限制时,淘汰尾部的数据即可。
LRU算法的优点是简单且易于实现,而缺点是在实际应用中可能会对性能造成一下几方面影响。
-
缓存命中率问题:
- 冷启动效应:系统刚启动或缓存被清空后,LRU算法会导致所有数据都需要从底层存储重新加载到缓存中,这时缓存命中率低,可能会暂时降低系统响应速度。
- 突发性访问模式:如果遇到大量不常访问的数据一次性集中请求,这些数据可能会短时间内占据缓存,迫使经常访问的数据被移除,降低了后续的缓存命中率。
-
维护成本:
- LRU算法需要维护一个有序的数据结构(如链表)来追踪数据的访问顺序,这会增加一定的内存开销和CPU计算成本,尤其是在频繁的插入和删除操作下。
-
实现复杂度:
- 实现精确的LRU算法可能较为复杂,特别是在需要高效操作(如O(1)复杂度的get和put操作)时,可能需要额外的数据结构支持,如哈希表加双向链表,这增加了实现难度和潜在的错误引入风险。
-
过度淘汰热门数据:
- 在某些特定访问模式下,如果大量数据访问具有周期性或者短时间内访问非常集中,LRU可能过早淘汰即将再次访问的热门数据,影响性能。
-
空间利用率:
- 当缓存容量设置不合理或数据访问分布极不均匀时,LRU可能无法充分利用缓存空间,导致缓存效率降低。
-
响应时间不稳定性:
- 在缓存替换关键时刻,如果需要进行复杂的淘汰决策,可能会引起系统响应时间的暂时增加,尤其是当淘汰策略涉及到复杂的比较或外部系统查询时。
下图是LRU算法的实现,将最近使用的留下来,不常使用的淘汰掉就是LRU算法