作者:来自 Elastic Aditya Tripathi
红帽和 Elastic 今天宣布开展合作,以便在 Red Hat OpenShift AI 上集成 Elasticsearch 向量数据库。 Red Hat OpenShift 用户现在可以通过红帽生态系统目录实施 Elasticsearch 以进行向量搜索和检索增强生成 (RAG) 应用程序。
此公告是红帽与 Elastic 之间多年合作的自然演变。 Elastic Cloud on Kubernetes (ECK) 是经过 Red Hat OpenShift 认证的产品。 Elastic 是 IBM 合作伙伴,IBM Watsonx Assistant 和 Watsonx Discovery 使用 Elastic 向量搜索来进行问答和检索增强用例。
随着今天的发布,Elasticsearch 用户将受益于红帽 OpenShift AI,这是一个灵活、可扩展的 MLOps 平台,用于为支持 AI 的应用程序构建、训练、测试和服务模型。
用于生成 AI 和 RAG 应用程序的 Elasticsearch 向量数据库
Elasticsearch Relevance Engine (ESRE) 是一套全面的开发人员工具,用于构建生成式 AI 和 RAG 应用程序。 ESRE 包含一个向量数据库,用于存储文本、图像和视频数据的嵌入。 ESRE 的本机混合搜索可以有效地将包含文本、向量和地理空间数据的结果与过滤、聚合和文档级安全性结合起来。
借助 ESRE,开发人员可以实现向量搜索和语义搜索,包括 k 最近邻 (kNN) 和近似最近邻 (ANN) 搜索,以及对内置和第三方自然语言处理 (NLP) 模型的支持。 ESRE 还与 Cohere、LangChain 和 LlamaIndex 等提供商的关键第三方生态系统产品无缝集成。 Elasticsearch 可以自我管理,也可以通过 Elastic Cloud 进行部署。
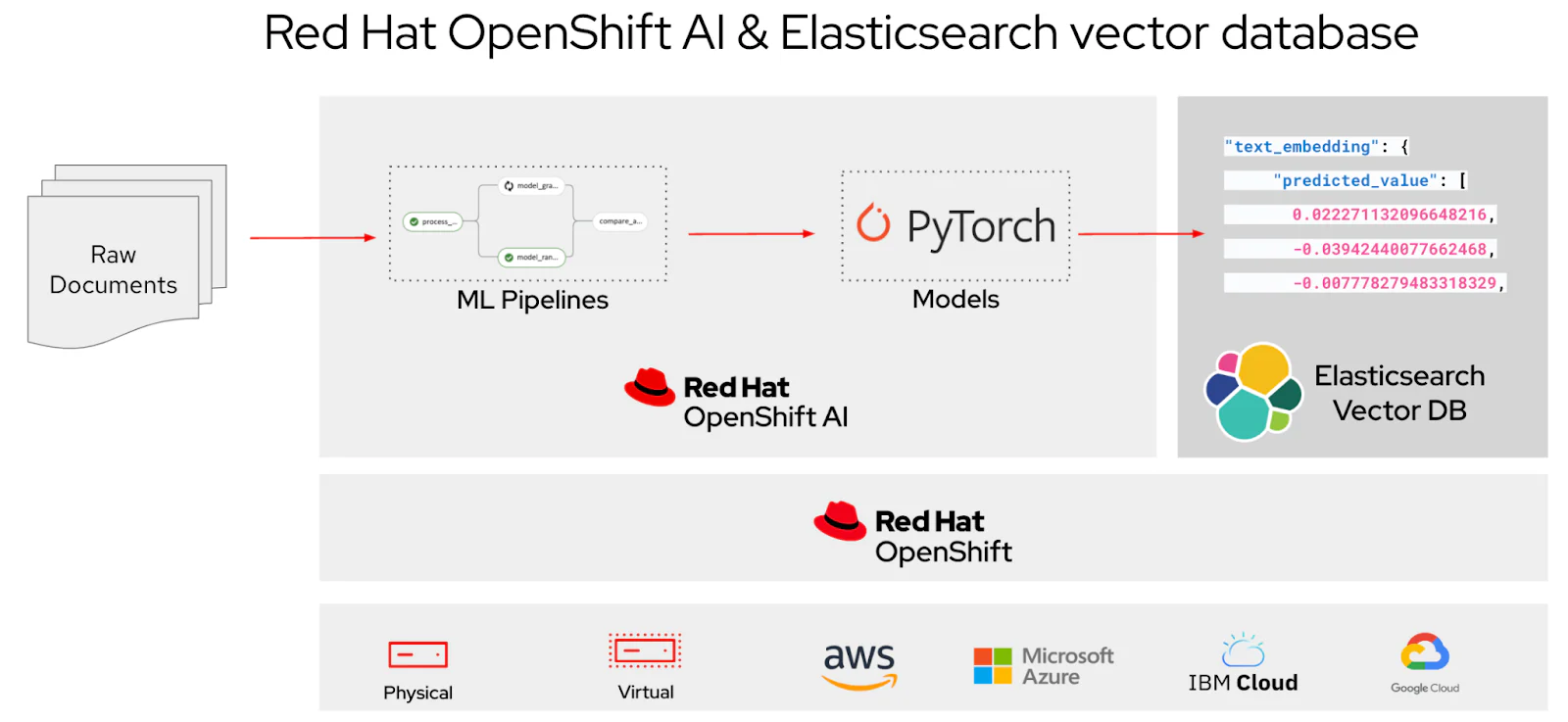
作为今天公告的一部分,用户将能够通过直接从红帽生态系统目录下载 Elasticsearch 来利用 ESRE 功能。
什么是面向生成式 AI 应用的红帽 OpenShift AI
红帽 OpenShift AI 是一个混合 MLOps 平台,它将 IT、数据科学和应用程序开发团队聚集在一起。 它旨在简化生成式人工智能应用程序的开发和部署,提供针对分布式工作负载量身定制的全面基础设施堆栈。 这包括训练、优化、微调和部署基础和预测人工智能模型。 与模型构建者合作有助于提供对各种预构建模型的访问。 开发人员和数据科学家可以在同一平台上协同工作,从而极大地增强协作。 该平台促进端到端人工智能生命周期管理 —— 从模型开发和培训到部署、服务和持续监控。
- 模型开发:使用我们的笔记本图像或你自己的笔记本图像,在 JupyterLab 中进行探索性数据科学,并访问核心 AI / ML 库和框架,包括 TensorFlow 和 PyTorch。
- 模型服务和监控:在完全托管或自我管理的红帽 OpenShift 环境中跨本地或任何云部署模型,并集中监控其性能。
- 生命周期管理:创建可重复的数据科学管道以进行模型训练和验证,并将其与 DevOps 管道集成,以便在整个企业内交付模型。
- 增强的功能和协作:创建项目并在团队之间共享。 结合红帽组件、开源软件和 ISV 认证的软件。
首先,只需按照红帽生态系统目录(Red Hat Ecosystem Catalog)中提供的安装说明进行操作,然后开始使用 RAG 构建你的下一个生成式 AI 应用程序!
访问 Elasticsearch Labs,获取有关向量搜索、RAG 等的文章和示例笔记本。
准备好将 RAG 构建到您的应用程序中了吗? 想要尝试使用向量数据库的不同 LLMs?
在 Github 上查看我们的 LangChain、Cohere 等示例笔记本,并参加即将开始的 Elasticsearch 工程师培训!
原文:Red Hat extends collaboration with Elasticsearch vector database for Red Hat OpenShift AI — Elastic Search Labs