这是一篇mac m2本地纯python环境安装 qanything的文章。安装并不顺利,官方提供的模型无法在本地跑。
这篇文章记录了,使用xinference来部署本地模型,并利用openAi的通用接口的方式,可以正常使用。
记录了遇到的所有的问题,以及解决方法,包括源码的修改。这是一个成功的案例。
一、关于QAnything的简介
开源的RAG本地知识库检索的有不少。最近比较火热的就是 QAnything 和 RAGflow 。其中Qanything 是相对比较早的。并且它是网易开源的,各种都相对更正规一些。安装部署文档也都比较齐全。
dify 是开源做工作流的,其中也有RAG的部分。但是做的很粗糙。
如果想做自己的本地知识库开发,可以在Qanything上做。我看过QAnything 和 RAGflow dify的源码,也对比了他们的效果,最终评估使用Qanything 打底。做一个全新的RAG搜索。
二、使用官方的文档来本地部署模型,启动
2.1 这里是官方文档
QAnything/README.md at qanything-python · netease-youdao/QAnything · GitHub
2.2 以下是安装过程
2.3 问题:启动过过程中遇到了问题(3B模型在mac上无法使用)
我的是mac m2 ,如果是m1,应该不会有问题。
llama_new_context_with_model: n_ctx = 4096
llama_new_context_with_model: n_batch = 512
llama_new_context_with_model: n_ubatch = 512
llama_new_context_with_model: freq_base = 10000.0
llama_new_context_with_model: freq_scale = 1
ggml_metal_init: allocating
ggml_metal_init: found device: Apple M2 Max
ggml_metal_init: picking default device: Apple M2 Max
ggml_metal_init: using embedded metal library
ggml_metal_init: error: Error Domain=MTLLibraryErrorDomain Code=3 "program_source:155:11: error: unions are not supported in Metalunion {^
program_source:176:11: error: unions are not supported in Metalunion {^
program_source:197:11: error: unions are not supported in Metalunion {^
program_source:219:11: error: unions are not supported in Metalunion {^
program_source:264:11: error: unions are not supported in Metalunion {^
program_source:291:11: error: unions are not supported in Metalunion {^
2.4 试试使用另外openAI的api的方式来启动
也就是说不用使用本地的模型(embedding模型还是用本地的,ocr模型也是用本地的)。
这里还是跟着官方文档来操作。
QAnything/README.md at qanything-python · netease-youdao/QAnything · GitHub
使用这个命令启动

这个就报错,因为还没有配置apikey,这里官方文档也没有说
这里需要修改这里,替换成自己的apikey就可以了(我这个是一个失效的key,没有调用量了)
该模型在本地跑不起来,有错误。官方的教程是针对M1的。所以需要探索本地部署模型的方法。
这里不附错误的图了。我原本的截图在csdn上发布的时候丢失了。
三、Macbook M2本地部署模型的方案
在经过大量调研和使用后,准备使用Xinference来部署模型。
下载部署Xinference的教程(教程是我自己写的,都验证通过的)
Mac M2 本地下载 Xinference-CSDN博客
使用Xinference部署模型的教程
使用Xinference 在mac m2 上部署模型 Qwen 7B-CSDN博客
到这里为止,本地已经可以运行模型来。
四、继续脱坑
4.1 这里使用本地7B的模型来配合使用qanything
在Qanything中切换使用本地模型,这里需要在调用openai的基础上改!
Xinference是可以发布成和openai兼容的接口的,利用这一点。
这里先做一个测试方法,来调用本地模型(调试好了,可以直接使用的,我这里本地部署的是qwen7b,注意要替换model_uid)
这个id在这个界面上可以看到。
 代码
代码
import openai# Assume that the model is already launched.
# The api_key can't be empty, any string is OK.
model_uid = "qwen-chat"
client = openai.Client(api_key="not empty", base_url="http://localhost:9997/v1")
# client.chat.completions.create(
# model=model_uid,
# messages=[
# {
# "content": "What is the largest animal?",
# "role": "user",
# }
# ],
# max_tokens=1024
# )
#
# 定义一个调用方法
def chat_with_model(prompt):try:response = client.chat.completions.create(model=model_uid,messages=[{"content": prompt,"role": "user",}],stream=False,max_tokens=1024)# Extracting the model's reply from the responseif response.choices and len(response.choices) > 0:model_reply = response.choices[0].message.contentprint(f"Model's Reply: {model_reply}")return response.choices[0].message.contentelse:print("No response received from the model.")except Exception as e:print(f"An error occurred: {e}")# 测试 chat_whith_model 函数
chat_with_model("什么是房颤")4.2 修改qanything的代码
在llm_for_openai_api.py下,87行处添加我们的自己部署的模型(模型名称在xinference上看,和上边一样)。否则会报错。

4.3 使用不支持流式接口

看到X inference后台模型的日志

这个问题暂时是无法解决的,模型的问题
但是我找到了一个解决方案,我修改了这里,指定为非流式输出处。这个问题就可以暂时解决了。
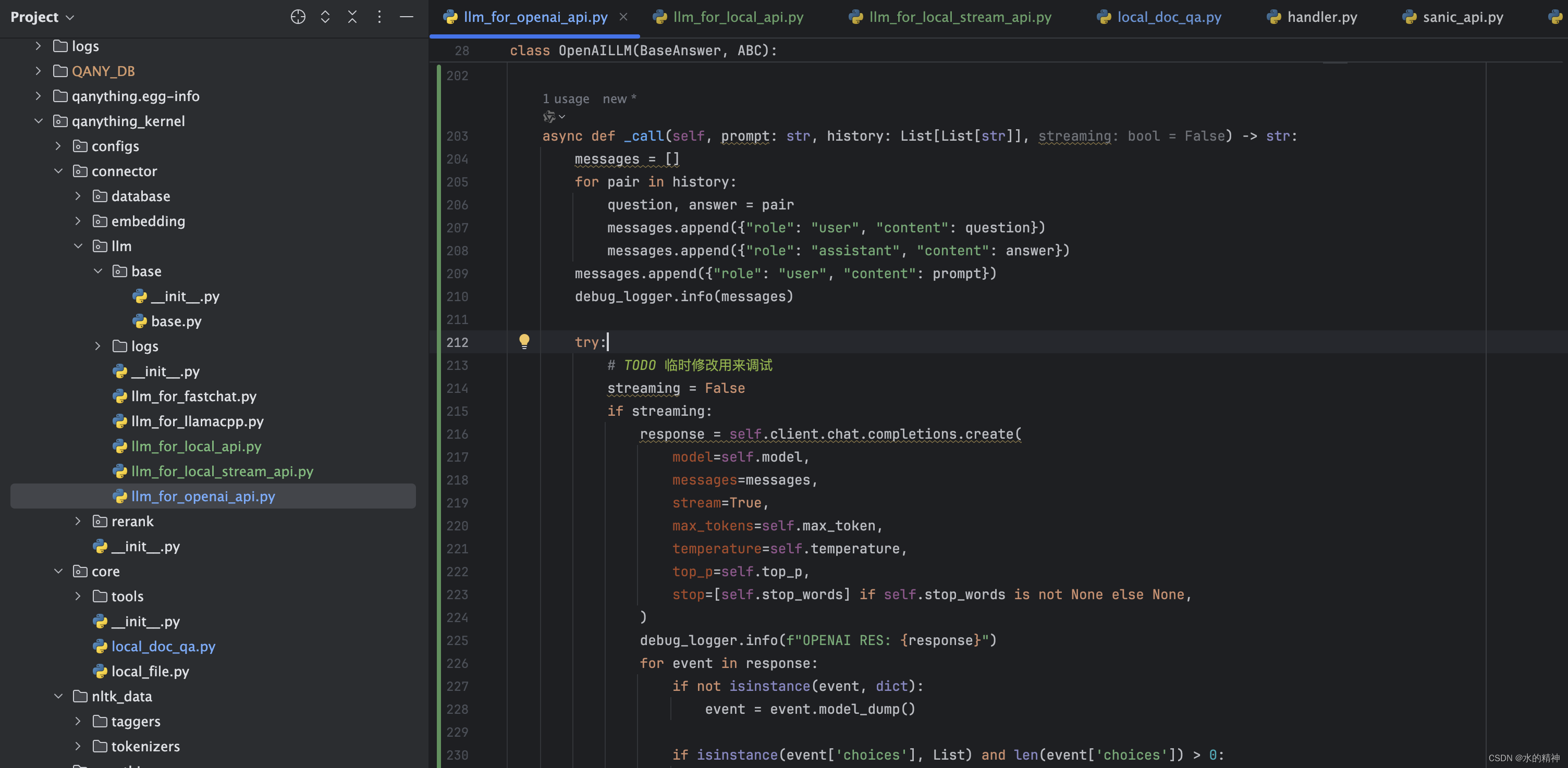
这是我修改后的_call方法
async def _call(self, prompt: str, history: List[List[str]], streaming: bool = False) -> str:messages = []for pair in history:question, answer = pairmessages.append({"role": "user", "content": question})messages.append({"role": "assistant", "content": answer})messages.append({"role": "user", "content": prompt})debug_logger.info(messages)try:# TODO 临时修改用来调试streaming = Falseif streaming:response = self.client.chat.completions.create(model=self.model,messages=messages,stream=True,max_tokens=self.max_token,temperature=self.temperature,top_p=self.top_p,stop=[self.stop_words] if self.stop_words is not None else None,)debug_logger.info(f"OPENAI RES: {response}")for event in response:if not isinstance(event, dict):event = event.model_dump()if isinstance(event['choices'], List) and len(event['choices']) > 0:event_text = event["choices"][0]['delta']['content']if isinstance(event_text, str) and event_text != "":# debug_logger.info(f"[debug] event_text = [{event_text}]")delta = {'answer': event_text}yield "data: " + json.dumps(delta, ensure_ascii=False)else:# response = self.client.chat.completions.create(# model=self.model,# messages=messages,# stream=False,# max_tokens=self.max_token,# temperature=self.temperature,# top_p=self.top_p,# stop=[self.stop_words] if self.stop_words is not None else None,# )model_uid = "qwen1.5-chat"client = openai.Client(api_key="not empty", base_url="http://localhost:9997/v1", timeout=6000)print(">>>>>gpt调用")print(messages)response = client.chat.completions.create(model=model_uid,messages=messages,max_tokens=1024)debug_logger.info(f"[debug] response.choices = [{response.choices}]")event_text = response.choices[0].message.content if response.choices else ""delta = {'answer': event_text}yield "data: " + json.dumps(delta, ensure_ascii=False)except Exception as e:debug_logger.info(f"Error calling OpenAI API: {e}")delta = {'answer': f"{e}"}yield "data: " + json.dumps(delta, ensure_ascii=False)finally:# debug_logger.info("[debug] try-finally")yield f"data: [DONE]\n\n"4.3 一个问题很长时间不回答
我这里上传了一个文档,来测试问题。半天没有反应
这里折腾了半天,看了半天,调试了半天,还以为是程序不行呢。因为界面上没有反应。这里看了下mac的cpu监控,发现推理任务还在跑着。也就是程序是没有问题的。
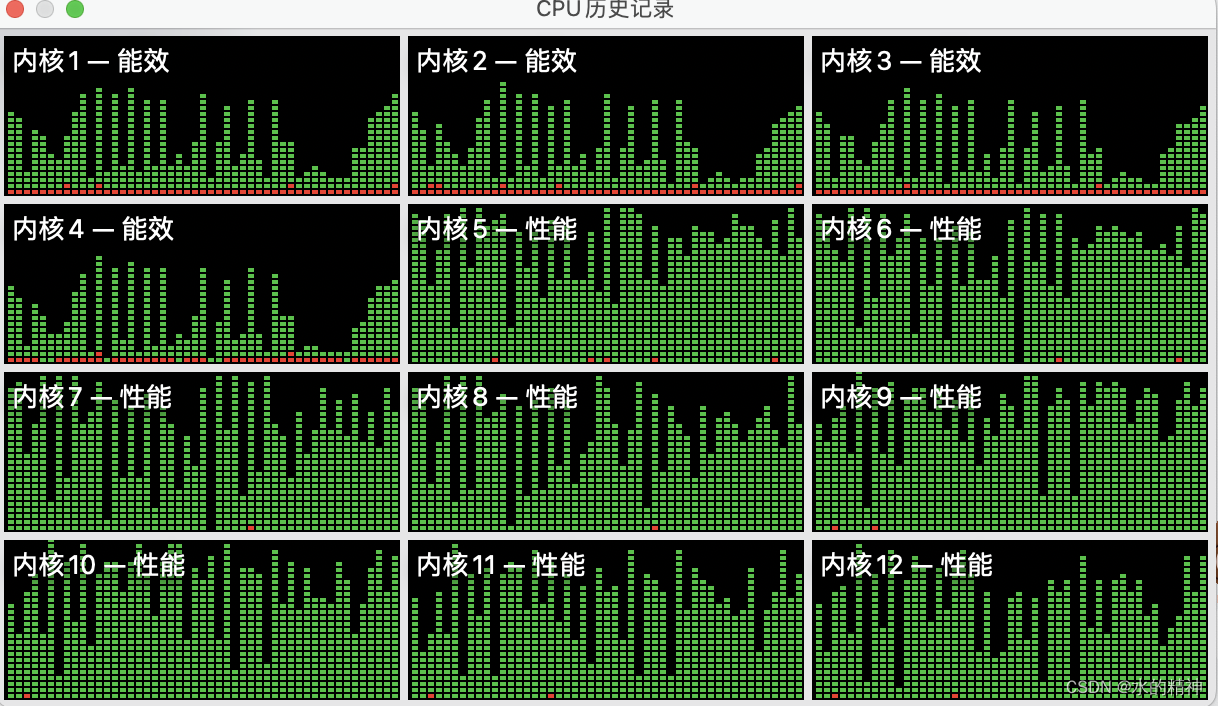
这里在重复的跑这个任务,一直没有结束。且一直在重复的调用。跟了一遍源码,源码中没有这样的循环逻辑。
然后看模型的任务,每个任务都很长时间,

先测试修改超时时间,看是否可以
修改调用模型的超时时间,并不可以。这里没有用。一开始觉得是模型的问题,模型推理的太慢了,所以试试再部署一个小模型测试一下。
这里我部署了一个qwen1.5 ,占用内存不到10个g,推理速度使用cpu也很快。
这里有教程细节
使用X inference下载部署小模型(qwen1.5)测试效果-CSDN博客
最后看到了能够成功调用,但是这里还是一个问题,发现有在一直重新调用后台接口,这里不知道是不是流式请求的问题。到这里我也找到的后台日志显示一直重新调用的罪魁祸手,就是在前端这里调用的,本来我还以为是后台代码有地方是写的循环,看了一圈以后,也没有循环的地方。
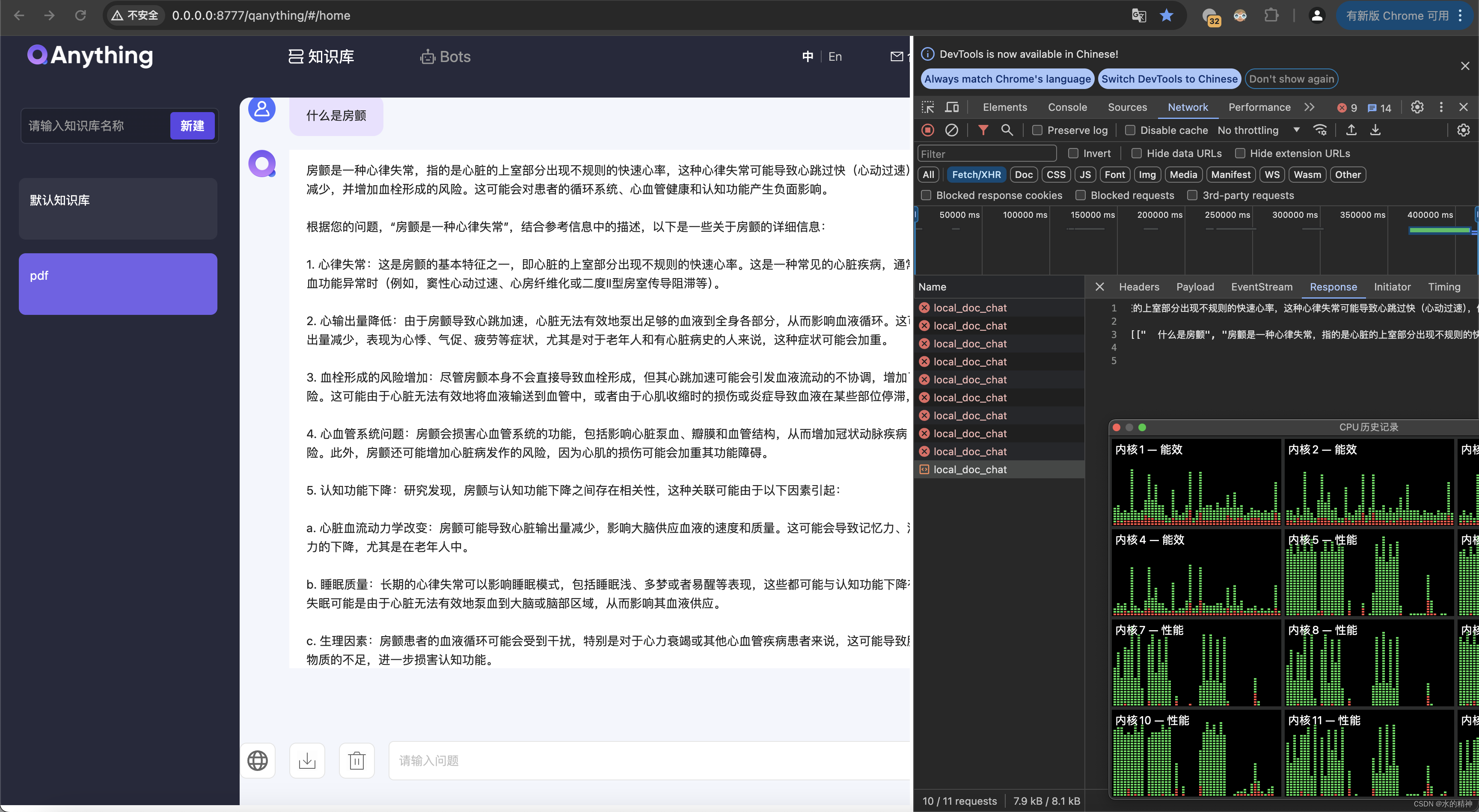
这里要找到源码中,前端部分,发送请求的时候发送,不指定流式输出。
这里先验证一下测试接口的输出
测试问答的接口
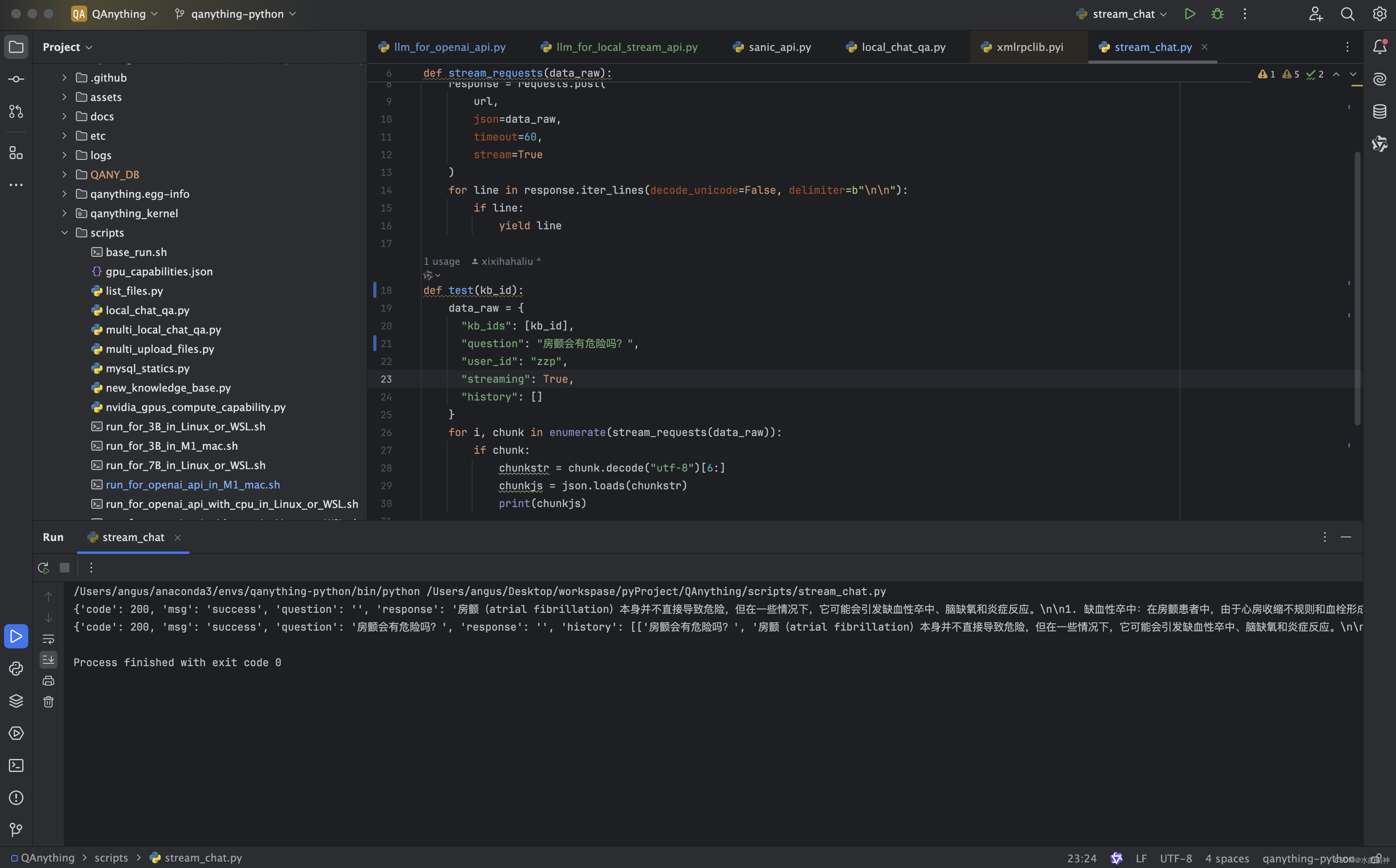
stream_chat.py
import json
import requests
import sys#kb_id = sys.argv[1]
def stream_requests(data_raw):url = 'http://0.0.0.0:8777/api/local_doc_qa/local_doc_chat'response = requests.post(url,json=data_raw,timeout=60,stream=True)for line in response.iter_lines(decode_unicode=False, delimiter=b"\n\n"):if line:yield linedef test(kb_id):data_raw = {"kb_ids": [kb_id],"question": "房颤会有危险吗?","user_id": "zzp","streaming": True,"history": []}for i, chunk in enumerate(stream_requests(data_raw)):if chunk:chunkstr = chunk.decode("utf-8")[6:]chunkjs = json.loads(chunkstr)print(chunkjs)if __name__ == '__main__':
# 在文件上传的时候,日志后台会打印知识库的id,这里需要替换自己的test("KBa2f41b8753fd48df8b408bca28e17830")
可以看到测试结果
五、源码结构解析
这里有时间再整理。之所以本地跑通,是因为我想在源码的基础上做开发和优化。
后续这块,我需要改成访问es的方式。会整理更多的内容出来。