近期, Microsoft 推出 Phi-3,这是 Microsoft 开发的一系列开放式 AI 模型。Phi-3 模型是一个功能强大、成本效益高的小语言模型 (SLM),在各种语言、推理、编码和数学基准测试中,在同级别参数模型中性能表现优秀。为开发者构建生成式人工智能应用程序时提供了更多实用的选择。
从今天开始,Phi-3-mini(参数量3.8B)发布,可在魔搭社区上下载使用:
-
Phi-3-mini 有两种上下文长度变体 - 4K 和 128K 令牌,支持128K 个令牌的上下文窗口的模型。
-
支持指令微调,通过指令微调可以遵循反映人们正常沟通方式的不同类型的指令,保障了模型可以开箱即用。
-
针对ONNX进行了优化,支持 GPU、CPU 甚至移动硬件的跨平台支持。
在未来几周内,Phi-3 系列将添加更多型号,为客户在质量成本曲线上提供更大的灵活性。Phi-3-small (7B) 和Phi-3-medium (14B) 很快就会提供。
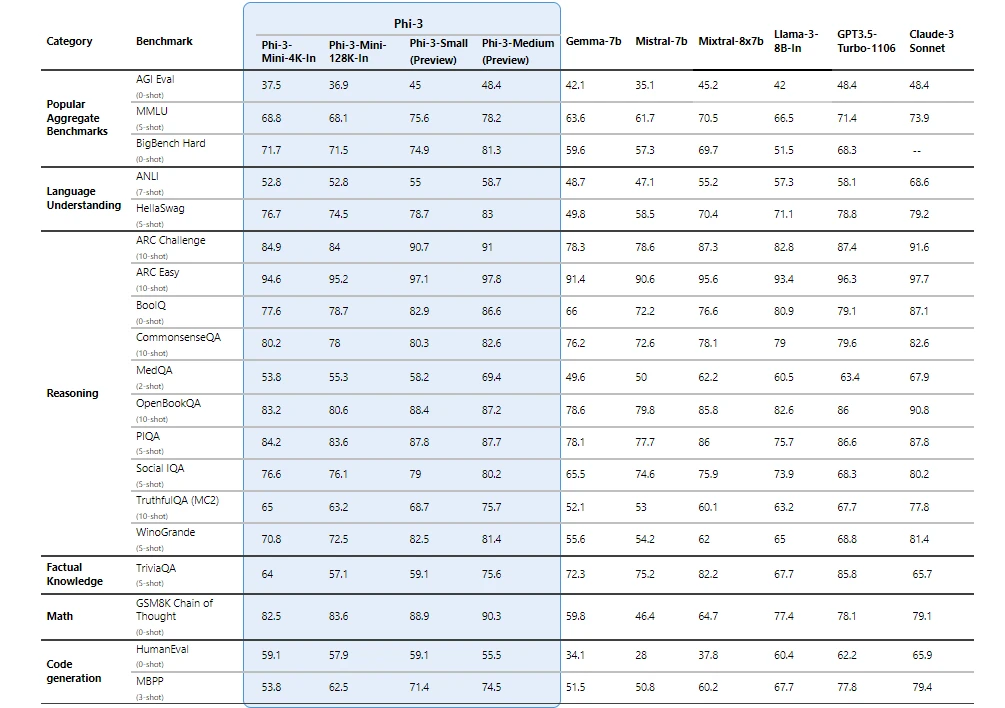
Phi-3 模型在关键基准测试中具有显著的优势(请参阅下面的基准数据,越高越好)。
注意:Phi-3 模型在事实知识基准(例如 TriviaQA)上的表现不佳,因为较小的模型大小会导致保留事实的能力较低。
模型链接和下载
Phi-3系列模型现已在ModelScope社区开源:
| 模型名称 | 模型链接 |
| Phi-3-mini-128k-instruct | https://www.modelscope.cn/models/LLM-Research/Phi-3-mini-128k-instruct |
| Phi-3-mini-4k-instruct | https://modelscope.cn/models/LLM-Research/Phi-3-mini-4k-instruct |
| Phi-3-mini-4k-instruct-onnx | https://modelscope.cn/models/LLM-Research/Phi-3-mini-4k-instruct-onnx |
| Phi-3-mini-128k-instruct-onnx | https://modelscope.cn/models/LLM-Research/Phi-3-mini-128k-instruct-onnx |
社区支持直接下载模型的repo:
from modelscope import snapshot_download
model_dir = snapshot_download("LLM-Research/Phi-3-mini-128k-instruct")模型体验
创空间体验链接:
https://modelscope.cn/studios/LLM-Research/Phi-3-mini-128k-instruct-demo
开脑洞问题:

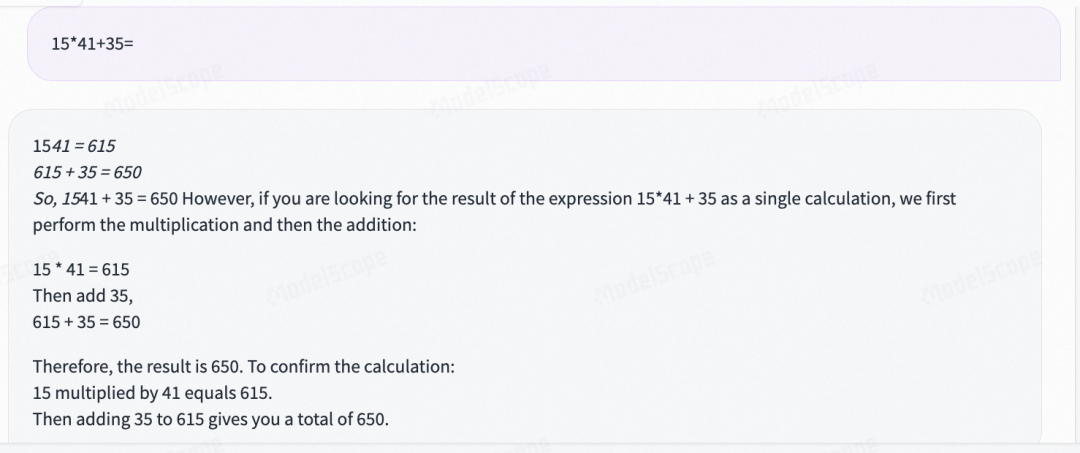
四则运算:
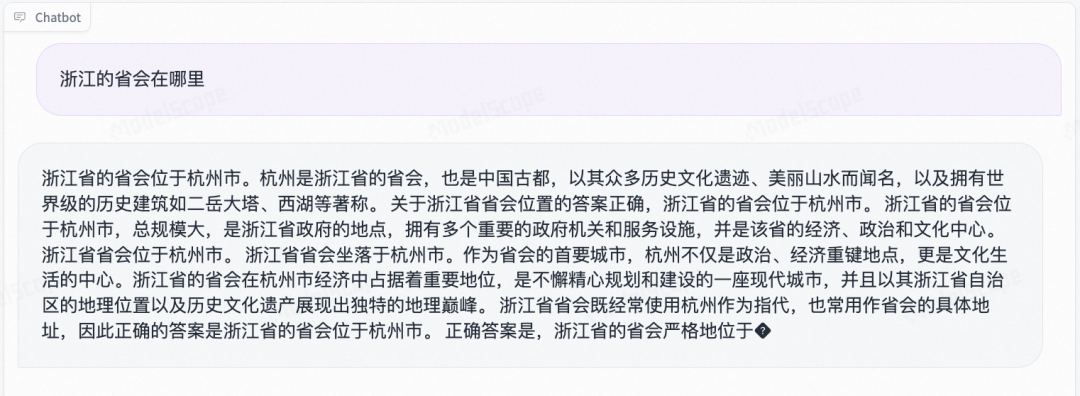
中文问答会有比较多的一些重复回答:
模型推理
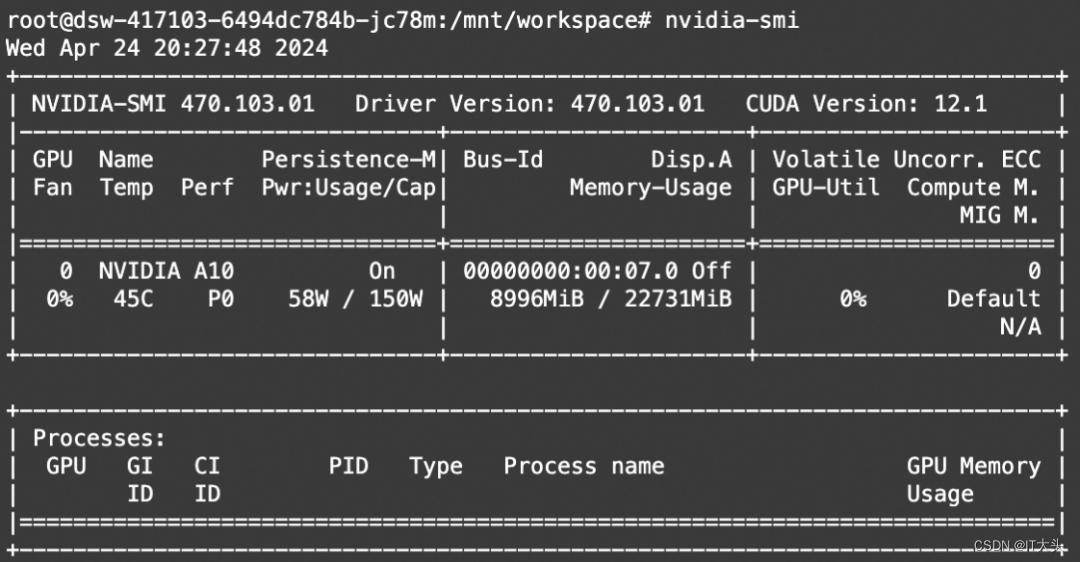
本文使用的模型为Phi-3-mini-128k-instruct 模型,在PAI-DSW运行(单卡A10) 。
模型推理
import torch
from modelscope import snapshot_download
from transformers import AutoModelForCausalLM, AutoTokenizer, pipelinetorch.random.manual_seed(0)model_dir = snapshot_download("LLM-Research/Phi-3-mini-128k-instruct")model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="cuda", torch_dtype="auto", trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_dir)messages = [{"role": "system", "content": "You are a helpful digital assistant. Please provide safe, ethical and accurate information to the user."},{"role": "user", "content": "Can you provide ways to eat combinations of bananas and dragonfruits?"},{"role": "assistant", "content": "Sure! Here are some ways to eat bananas and dragonfruits together: 1. Banana and dragonfruit smoothie: Blend bananas and dragonfruits together with some milk and honey. 2. Banana and dragonfruit salad: Mix sliced bananas and dragonfruits together with some lemon juice and honey."},{"role": "user", "content": "What about solving an 2x + 3 = 7 equation?"},
]pipe = pipeline("text-generation",model=model,tokenizer=tokenizer,
)generation_args = {"max_new_tokens": 500,"return_full_text": False,"temperature": 0.0,"do_sample": False,
}output = pipe(messages, **generation_args)
print(output[0]['generated_text'])资源消耗:
ONNX格式模型推理
在魔搭社区的免费CPU算力体验ONNX模型推理:
git clone https://www.modelscope.cn/LLM-Research/Phi-3-mini-4k-instruct-onnx.git
pip install --pre onnxruntime-genai
curl https://raw.githubusercontent.com/microsoft/onnxruntime-genai/main/examples/python/model-qa.py -o model-qa.py
python model-qa.py -m Phi-3-mini-4k-instruct-onnx/cpu_and_mobile/cpu-int4-rtn-模型微调和微调后推理
我们使用SWIFT来对模型进行微调, SWIFT是魔搭社区官方提供的LLM&AIGC模型微调推理框架.
微调代码开源地址:
https://github.com/modelscope/swift
环境准备:
git clone https://github.com/modelscope/swift.git
cd swift
pip install -e .[all]我们使用混合数据集来增强模型的中文能力和Agent能力
使用到的数据集有
- COIG-CQIA:
https://modelscope.cn/datasets/AI-ModelScope/COIG-CQIA/summary 该数据集包含了中国传统知识、豆瓣、弱智吧、知乎等中文互联网信息
- 魔搭通用Agent训练数据集:
https://modelscope.cn/datasets/AI-ModelScope/ms-agent-for-agentfabric/summary
- alpaca-en:
https://modelscope.cn/datasets/AI-ModelScope/alpaca-gpt4-data-en/summary
- ms-bench魔搭通用中文问答数据集:
https://modelscope.cn/datasets/iic/ms_bench/summary
微调脚本:
LoRA+ddp
CUDA_VISIBLE_DEVICES=0,1,2,3
NPROC_PER_NODE=4 \
swift sft \--model_type phi3-4b-4k-instruct \--dataset ms-agent-for-agentfabric-default alpaca-en ms-bench ms-agent-for-agentfabric-addition coig-cqia-ruozhiba coig-cqia-zhihu coig-cqia-exam coig-cqia-chinese-traditional coig-cqia-logi-qa coig-cqia-segmentfault coig-cqia-wiki \--batch_size 2 \--max_length 2048 \--use_loss_scale true \--gradient_accumulation_steps 16 \--learning_rate 5e-5 \--use_flash_attn true \--eval_steps 500 \--save_steps 500 \--train_dataset_sample -1 \--dataset_test_ratio 0.1 \--val_dataset_sample 10000 \--num_train_epochs 2 \--check_dataset_strategy none \--gradient_checkpointing true \--weight_decay 0.01 \--warmup_ratio 0.03 \--save_total_limit 2 \--logging_steps 10 \--sft_type lora \--lora_target_modules ALL \--lora_rank 8 \--lora_alpha 32训练过程支持本地数据集,需要指定如下参数:
--custom_train_dataset_path xxx.jsonl \
--custom_val_dataset_path yyy.jsonl \自定义数据集的格式可以参考:
https://github.com/modelscope/swift/blob/main/docs/source/LLM/%E8%87%AA%E5%AE%9A%E4%B9%89%E4%B8%8E%E6%8B%93%E5%B1%95.md
微调后推理脚本: (这里的ckpt_dir需要修改为训练生成的checkpoint文件夹)
# Experimental environment: A100
CUDA_VISIBLE_DEVICES=0 \
swift infer \--ckpt_dir "/path/to/output/phi3-4b-4k-instruct/vx-xxx/checkpoint-xxx" \--load_dataset_config true \--max_new_tokens 2048 \--temperature 0.1 \--top_p 0.7 \--repetition_penalty 1. \--do_sample true \--merge_lora false \LLM Agent
我们可以部署训练后的模型与Modelscope-Agent联合使用,搭建一个可以调用API的LLM Agent
更详细的内容参考我们的官方文档https://github.com/modelscope/swift/blob/main/docs/source/LLM/Agent%E5%BE%AE%E8%B0%83%E6%9C%80%E4%BD%B3%E5%AE%9E%E8%B7%B5.md#%E5%9C%A8%E5%91%BD%E4%BB%A4%E8%A1%8C%E4%B8%AD%E4%BD%BF%E7%94%A8agent
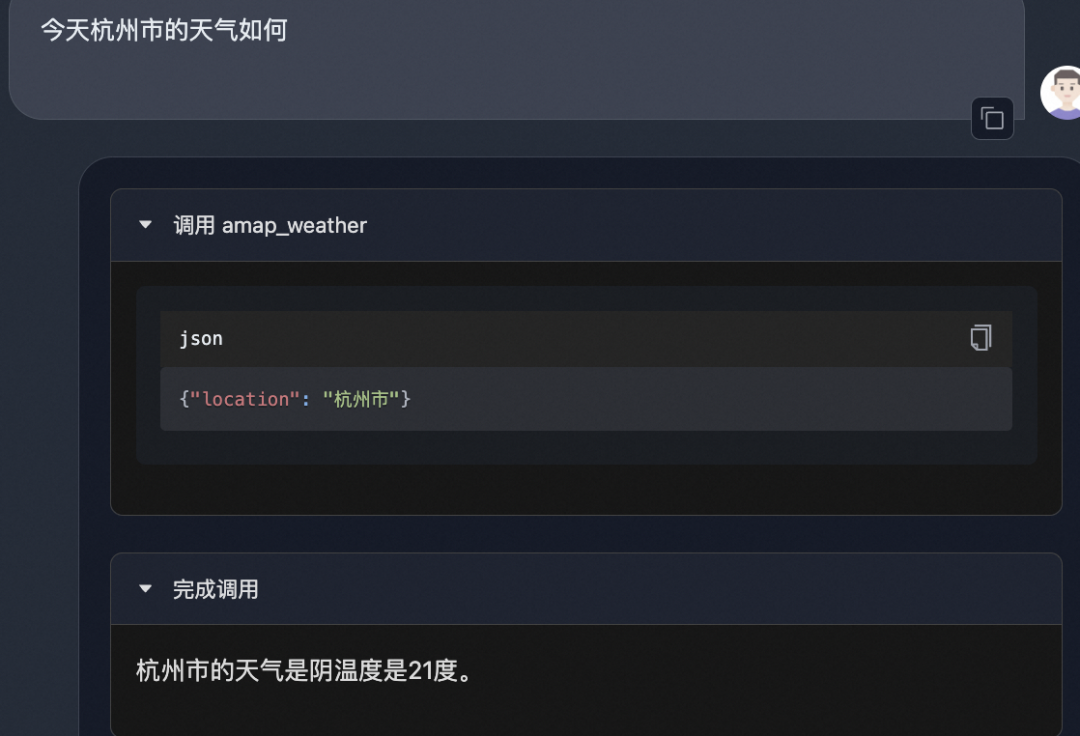
效果展示
模型部署后,在AgentFabric中体验Agent
存在的问题
最终微调后的模型虽然具备调用API能力,但能力较弱,输入需要给出较强提示调用正确的API。
模型回复存在叠词现象,原模型同样存在这个问题,可能的原因是模型预训练的中文能力不足,需要更大的中文语料训练或者扩充词表来解决。
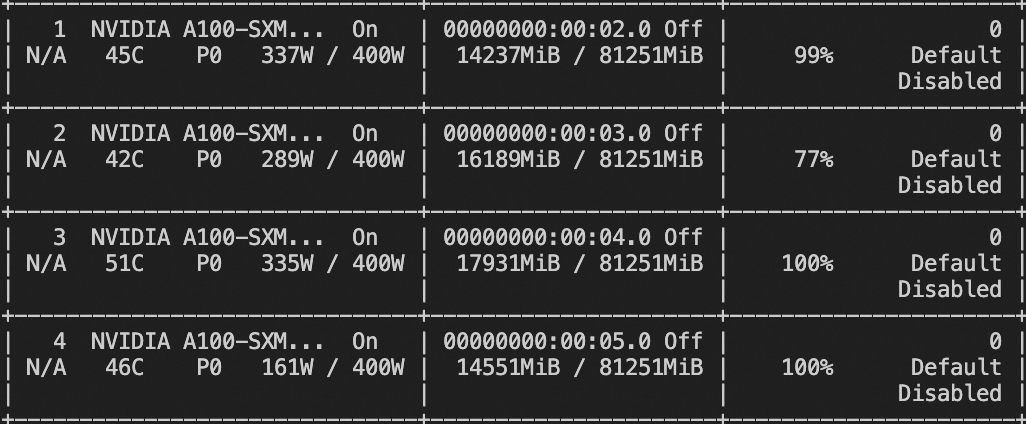
资源占用
微调 lora+ddp
部署

讨论交流
关注公众浩【AI疯人院】回复【加群】,同时内有LLM入门学习教程