目录
一、slice函数的常见应用场景
二、slice函数使用注意事项
三、如何用好slice函数?
1、slice函数:
1-1、Python:
1-2、VBA:
2、推荐阅读:
个人主页: https://blog.csdn.net/ygb_1024?spm=1010.2135.3001.5421



一、slice函数的常见应用场景
Python中的slice函数在某些特定场景下非常有用,尽管在日常编程中,我们更多地使用切片语法(如my_list[start:stop:step]),不过,了解slice()函数仍然有助于更深入地理解Python的切片机制。以下是slice()函数的一些常见应用场景:
1、动态切片:当你需要在运行时根据某些条件动态地确定切片的起始、结束和步长时,slice()函数会非常有用,你可以根据这些条件创建切片对象,并将它们传递给需要切片的函数或方法。
2、作为函数参数:当你编写一个函数,并希望该函数能够接受一个切片作为参数时,你可以使用slice()函数来创建这个切片,这样,调用者可以传递一个切片对象,或者传递起始、结束和步长的参数,函数内部可以统一处理。
3、构建自定义的序列类型:当你需要构建自定义的序列类型(如列表、元组或字符串的自定义版本)时,你可能会希望支持切片操作,通过使用slice()函数,你可以在你的类内部处理切片请求,并提供自定义的切片行为。
4、处理多维数据结构:当处理如NumPy数组、Pandas DataFrame或多维列表等多维数据结构时,slice()函数可以帮助你构建复杂的切片表达式,通过组合多个slice()对象,你可以指定多个维度上的切片参数,并轻松地提取或修改多维数据结构中的子集。
5、创建可重用的切片对象:在某些情况下,你可能需要多次对同一数据集应用相同的切片操作,通过创建一个slice()对象并将其存储起来,你可以避免重复编写相同的切片参数,并在需要时重复使用该切片对象。
6、与第三方库集成:在某些第三方库中,可能需要使用slice()函数来与Python的切片机制进行集成。例如,某些数据处理或可视化库可能允许你使用slice()函数来指定要处理或可视化的数据子集。
7、切片操作的可视化和调试:在开发过程中,有时需要可视化或调试切片操作以确保其按预期工作,通过使用slice()函数并打印或记录切片对象的状态,你可以更清晰地了解切片操作的内部逻辑,并更容易地诊断潜在问题。
8、结合内置函数或方法使用:有些内置函数或方法(如sorted()、enumerate()等)可以接受一个可选的key参数,该参数可以是一个函数,用于在排序或枚举时确定元素的顺序,你可以使用slice()函数创建一个切片对象,并将其作为key参数传递给这些函数,以实现基于切片的排序或枚举,但请注意,这种用法可能不太常见,因为通常需要更复杂的逻辑来确定排序或枚举的顺序。
9、自定义数据处理的流水线:在处理大型数据集或执行复杂的数据处理任务时,你可能希望将数据划分为多个部分或子集,并在不同的处理阶段之间传递这些子集,通过使用slice()函数,你可以构建灵活的切片逻辑,并在数据处理流水线中动态地选择和处理数据子集。
总之,虽然slice()函数在日常编程中可能不是必需的,但在处理复杂数据或需要更灵活、更动态的切片操作时,它可以是一个有用的工具。

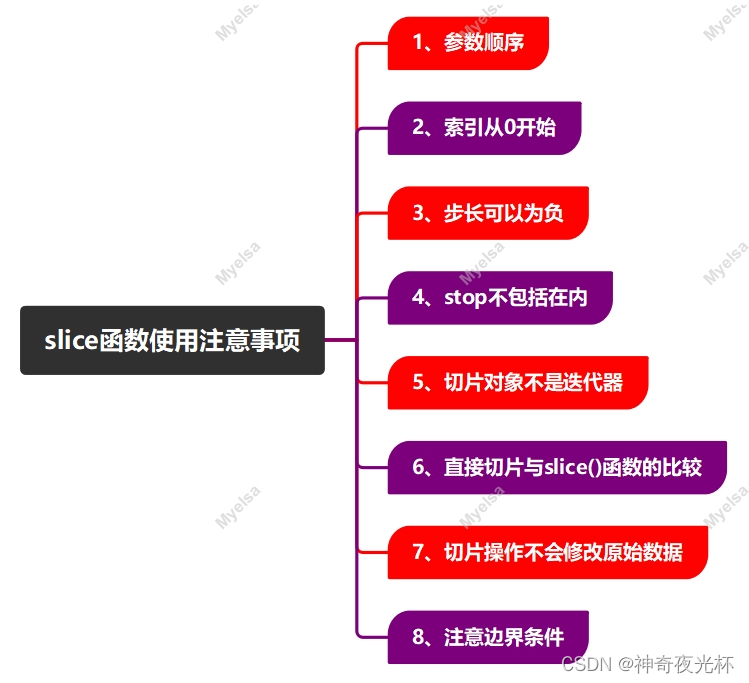
二、slice函数使用注意事项
在 Python 中,slice()函数并不直接用于数据切片,但它返回一个表示切片操作的 `slice` 对象,这个 `slice` 对象通常被传递给需要切片的函数或方法,比如列表(list)、元组(tuple)、字符串(str)的 `__getitem__` 方法等,使用slice()函数时,需要注意以下几点:
1、参数顺序:slice()函数接受三个参数,分别是 `start`(切片开始位置,默认为 0),`stop`(切片结束位置,但不包括该位置,默认为 `None`)和 `step`(切片的步长,默认为 1),这些参数都是可选的,但在使用时必须按照 `start, stop, step` 的顺序提供。
2、索引从0开始:Python中的索引是从0开始的,所以在使用slice()函数时要注意这一点。例如,如果你想从列表的第二个元素开始切片,`start` 应该设置为 1,而不是 2。
3、步长可以为负:如果 `step` 参数为负,则切片将从右到左进行。例如,`slice(None, None, -1)` 会创建一个表示从末尾到开头的切片。
4、stop不包括在内:`stop` 参数指定的位置是不包括在切片结果中的,这意味着如果你想要一个包含列表最后一个元素的切片,你需要将 `stop` 设置为 `None` 或列表的长度。
5、切片对象不是迭代器:slice()函数返回的 `slice` 对象本身并不是迭代器,它只是一个表示切片操作的对象,你可以将其传递给需要切片的函数或方法。
6、直接切片与slice()函数的比较:在大多数情况下,直接使用切片语法(如 lst[start:stop:step])比使用slice()函数更简洁、更直观,但在某些情况下,例如当你需要将切片操作作为参数传递给函数时,使用slice()函数可能更方便。
7、切片操作不会修改原始数据:无论你是使用切片语法还是slice()函数,切片操作都不会修改原始数据,它只会返回一个新的对象(可能是原始数据的视图,也可能是原始数据的副本),这个新对象包含了原始数据的切片部分。
8、注意边界条件:在使用切片时,要注意边界条件。特别是当 `start` 或 `stop` 超出数据范围时,Python会自动调整这些值。例如,如果你对一个长度为5的列表使用 `lst[10:]` 进行切片,Python会返回一个空列表,而不是抛出错误。
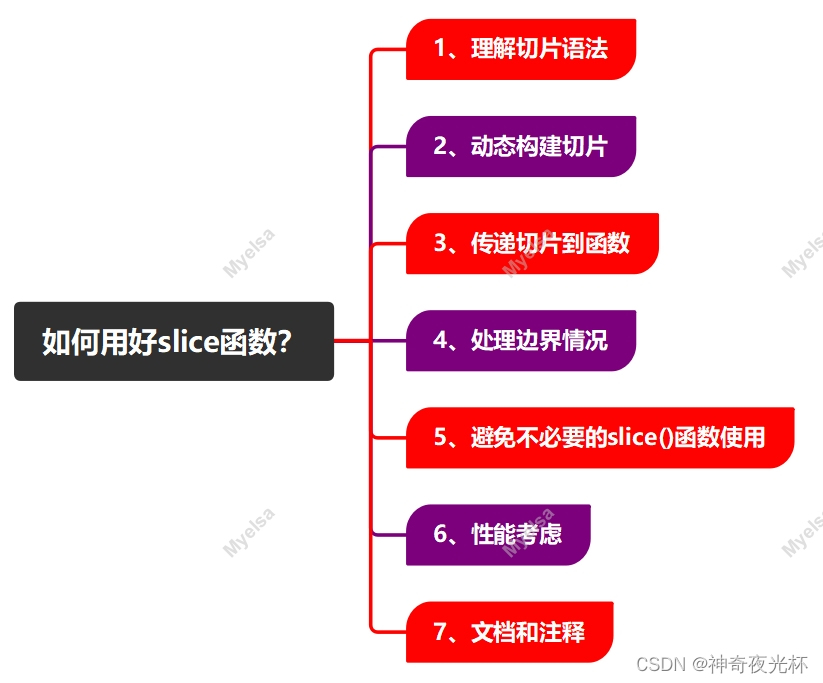
三、如何用好slice函数?
虽然Python中的slice()函数不直接用于数据切片,但它确实在某些情况下很有用,特别是当你需要动态地构建切片操作或将其作为参数传递给其他函数时。以下是一些使用slice()函数的建议:
1、理解切片语法:在使用slice()函数之前,确保你理解 Python 中的切片语法([start:stop:step]),这将有助于你更好地理解slice()函数的参数和用途。
2、动态构建切片:如果你需要根据某些条件动态地构建切片,slice()函数会非常有用。例如,你可以根据用户输入或某个计算的结果来确定切片的开始、结束和步长。
3、传递切片到函数:如果你正在编写一个需要接受切片作为参数的函数,你可以使用slice()函数来创建切片对象,并将该对象作为参数传递,这样,你的函数就可以更灵活地处理不同的切片操作。
4、处理边界情况:当使用slice()函数时,要注意处理边界情况。例如,如果stop小于start并且step为正数,或者stop大于start并且step为负数,那么切片将返回一个空列表,确保你的代码能够正确处理这些情况。
5、避免不必要的slice()函数使用:在大多数情况下,直接使用切片语法(如lst[start:stop:step])比使用slice()更简洁、更直观,只有在需要动态构建切片或将其作为参数传递时,才考虑使用slice()函数。
6、性能考虑:虽然slice()函数本身并不会对性能产生显著影响,但过度使用它可能会使代码变得难以阅读和维护,在性能关键的场景中,确保你的切片操作是高效的,并考虑使用其他数据结构或算法来优化性能。
7、文档和注释:当你使用slice()或其他不常见的Python功能时,确保为你的代码添加适当的文档和注释,这将有助于其他开发人员理解你的代码,并减少出错的可能性。
1、slice函数:
1-1、Python:
# 1.函数:slice
# 2.功能:用于实现切片对象,主要用在切片操作函数里的参数传递,返回值为一个切片对象
# 3.语法:
# 3-1、slice(stop)
# 3-2、slice(start, stop[, step=None])
# 4.参数:
# 4-1、start(可选):切片开始的索引(包含);如果省略或为None,则默认为0
# 4-2、stop(必需):切片结束的索引(不包含);如果省略或为None,则默认为序列的长度
# 4-3、step(可选):切片的步长;如果省略或为None,则默认为1;如果为负值,则切片会从后向前进行
# 5.返回值:返回一个切片对象
# 6.说明:
# 7.示例:
# 用dir()函数获取该函数内置的属性和方法
print(dir(slice))
# ['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getstate__',
# '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__ne__', '__new__', '__reduce__', '__reduce_ex__',
# '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'indices', 'start', 'step', 'stop']# 用help()函数获取该函数的文档信息
help(slice)# 应用一:动态切片
# 示例1:基于用户输入的切片
def slice_based_on_input(lst):start = int(input("请输入开始索引(包含):"))stop = int(input("请输入结束索引(不包含):"))step = int(input("请输入步长(默认为1):") or 1) # 如果用户没有输入,则使用默认值1slice_obj = slice(start, stop, step)return lst[slice_obj]
my_list = [3, 5, 6, 8, 10, 10, 24]
print(slice_based_on_input(my_list))
# 请输入开始索引(包含):0
# 请输入结束索引(不包含):4
# 请输入步长(默认为1):2
# [3, 6]# 示例2:函数接受slice对象作为参数
def process_slice(lst, slice_obj):return lst[slice_obj]
my_list = [3, 5, 6, 8, 10, 10, 24]
slice_obj = slice(1, 6, 2)
print(process_slice(my_list, slice_obj))
# [5, 8, 10]# 示例3:使用列表推导式创建动态切片
def dynamic_slice(lst, start_cond, end_cond):# 假设start_cond和end_cond是函数,用于确定切片的开始和结束索引start = next(i for i, val in enumerate(lst) if start_cond(val))# end的计算方式,使其总是基于lst的索引end_gen = (i for i, val in enumerate(lst, start) if end_cond(val))end = next(end_gen, None) # 尝试获取第一个满足end_cond的索引,如果没有则默认为Noneend = end if end is not None else len(lst) # 如果end是None,则设置为lst的长度return lst[start:end]
my_list = [0, 1, 1, 2, 2, 3, 4, 4, 5]
# 定义条件函数
def is_two(val):return val == 2
# 注意:这个例子没有严格遵循“不包含结束索引”的切片规则
print(dynamic_slice(my_list, lambda val: val > 0, is_two)) # 输出可能是 [1, 1, 2] 或 [1, 1, 2, 2] 等,取决于end_cond何时为真
# [1, 1, 2]# 示例4:在循环中使用slice对象进行多次切片
def slice_multiple_times(lst, slices_list):results = []for slice_obj in slices_list:results.append(lst[slice_obj])return results
my_list = list(range(10))
slices = [slice(0, 3), slice(3, 7, 2), slice(-2, None)] # 创建一个包含多个slice对象的列表
print(slice_multiple_times(my_list, slices))
# [[0, 1, 2], [3, 5], [8, 9]]# 应用二:作为函数参数
# 示例1:简单的列表切片函数
def slice_list(lst, slice_obj):return lst[slice_obj]
my_list = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 使用slice()对象进行切片
slice_obj = slice(2, 7, 2)
result = slice_list(my_list, slice_obj)
print(result)
# [2, 4, 6]# 示例2:具有默认参数的切片函数
def slice_list_with_defaults(lst, start=0, stop=None, step=1):slice_obj = slice(start, stop, step)return lst[slice_obj]
my_list = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 使用默认参数
result1 = slice_list_with_defaults(my_list) # 输出: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 使用自定义的开始和结束索引
result2 = slice_list_with_defaults(my_list, 2, 7) # 输出: [2, 3, 4, 5, 6]
# 使用自定义的步长
result3 = slice_list_with_defaults(my_list, 1, 9, 2) # 输出: [1, 3, 5, 7]
print(result1)
print(result2)
print(result3)
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# [2, 3, 4, 5, 6]
# [1, 3, 5, 7]# 示例3:动态创建slice()对象并传递给函数
def create_slice_obj(start=None, stop=None, step=None):return slice(start, stop, step)
def slice_and_print(lst, slice_obj):print(lst[slice_obj])
my_list = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 动态创建slice对象并传递给函数
slice_obj = create_slice_obj(start=3, stop=8, step=2)
slice_and_print(my_list, slice_obj)
# [3, 5, 7]# 应用三:构建自定义的序列类型
class CustomSequence:def __init__(self, data):self.data = datadef __getitem__(self, index):if isinstance(index, slice):# 使用slice对象的start, stop, step属性进行切片start = index.start if index.start is not None else 0stop = index.stop if index.stop is not None else len(self.data)step = index.step if index.step is not None else 1return self.data[start:stop:step]else:# 处理单个索引return self.data[index]def __len__(self):return len(self.data)
# 还可以定义其他序列类型的方法,如 __setitem__, __delitem__, __iter__, __reversed__ 等
# 使用示例
custom_seq = CustomSequence([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
# 访问单个元素
print(custom_seq[3]) # 输出: 3
# 使用切片
print(custom_seq[2:7:2]) # 输出: [2, 4, 6]
# 使用slice对象进行切片
s = slice(2, 7, 2)
print(custom_seq[s]) # 输出: [2, 4, 6]
# 获取长度
print(len(custom_seq)) # 输出: 10
# 3
# [2, 4, 6]
# [2, 4, 6]
# 10# 应用四:处理多维数据结构
# 示例1:直接使用slice()函数
def slice_2d_list(lst, row_slice, col_slice):return [row[col_slice] for row in lst[row_slice]]
# 创建一个二维列表
two_d_list = [[1, 2, 3, 4],[5, 6, 7, 8],[9, 10, 11, 12],[13, 14, 15, 16]
]
# 定义行和列的切片
row_slice = slice(1, 3) # 选择第2行到第3行(不包括第4行)
col_slice = slice(1, 3) # 选择第2列到第3列(不包括第4列)
# 使用定义的切片来从二维列表中提取数据
result = slice_2d_list(two_d_list, row_slice, col_slice)
# 打印结果
for row in result:print(row)
# [6, 7]
# [10, 11]# 示例2:使用numpy库(替代方案)
import numpy as np
# 创建一个NumPy二维数组
two_d_array = np.array([[1, 2, 3, 4],[5, 6, 7, 8],[9, 10, 11, 12],[13, 14, 15, 16]
])
# 使用切片选择第2行到第3行(不包括第4行),以及第2列到第3列(不包括第4列)
result = two_d_array[1:3, 1:3]
# 打印结果
print(result)
# [[ 6 7]
# [10 11]]# 应用五:创建可重用的切片对象
# 创建一个slice对象
my_slice = slice(1, 4, 2) # 创建一个从索引1开始,到索引4之前结束(不包括4),步长为2的切片
# 定义一些序列
my_list1 = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
my_list2 = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
# 在列表上应用slice对象
print(my_list1[my_slice])
print(my_list2[my_slice])
# 你可以将slice对象作为函数参数传递,以创建可重用的切片功能
def slice_and_print(sequence, s):print(sequence[s])
# 使用定义的函数和slice对象
slice_and_print(my_list1, my_slice)
slice_and_print(my_list2, my_slice)
# 你可以根据需要修改slice对象的值,并再次使用它
my_slice = slice(2, 8, 3)
print(my_list1[my_slice])
print(my_list2[my_slice])
# [1, 3]
# ['b', 'd']
# [1, 3]
# ['b', 'd']
# [2, 5]
# ['c', 'f']# 应用六:与第三方库集成
import pandas as pd
# 创建一个Pandas DataFrame
data = {'A': [1, 2, 3, 4, 5],'B': [10, 20, 30, 40, 50],'C': ['a', 'b', 'c', 'd', 'e']
}
df = pd.DataFrame(data)
# 创建一个slice对象
# 注意:在这个例子中,我们实际上不需要显式地创建slice对象,
# 因为Pandas DataFrame和Series直接支持Python的切片语法。
# 但为了说明,我们可以创建一个slice对象来模拟这个过程。
row_slice = slice(1, 4) # 选择第2行到第4行(不包括第5行)
col_slice = slice(1, 3) # 选择第2列到第3列(不包括第4列)
# 通常,我们直接使用切片语法而不是slice对象
# 但为了演示,我们可以将slice对象转换为切片元组
rows = df.index[row_slice]
cols = df.columns[col_slice]
# 使用Pandas的loc方法(或者iloc方法,但iloc使用整数位置索引)进行切片
# 注意:这里我们并没有直接使用slice对象,而是使用了基于slice对象选择的行和列索引
sliced_df = df.loc[rows, cols]
# 打印结果
print(sliced_df)
direct_sliced_df = df.iloc[1:4, 1:3]
print(direct_sliced_df)
# B C
# 1 20 b
# 2 30 c
# 3 40 d
# B C
# 1 20 b
# 2 30 c
# 3 40 d# 应用七:切片操作的可视化和调试
def visualize_slice(data, slice_obj):"""Visualize the result of a slice operation on a given data structure.:param data: The data structure to be sliced (e.g., list, tuple, str, etc.):param slice_obj: A slice object or a tuple of slice objects for multi-dimensional slicing:return: None (prints the visualization)"""# Handle single-dimensional slicingif isinstance(slice_obj, slice):result = data[slice_obj]print(f"Original data: {data}")print(f"Slice object: {slice_obj}")print(f"Sliced data: {result}")# Handle multi-dimensional slicing (assuming data is a list of lists)elif isinstance(data, list) and all(isinstance(sub, list) for sub in data) and isinstance(slice_obj, tuple):# Check if all elements of the tuple are slice objectsif all(isinstance(s, slice) for s in slice_obj):result = [row[slice_obj[1]] for row in data[slice_obj[0]]]print(f"Original 2D data:\n{data}")print(f"Slice objects: {slice_obj}")print(f"Sliced 2D data:\n{result}")else:print("Invalid slice objects for multi-dimensional slicing.")else:print("Invalid data or slice object for visualization.")
# 单维切片示例
my_list = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
slice_obj = slice(2, 7, 2)
visualize_slice(my_list, slice_obj)
# 二维切片示例(列表的列表)
my_2d_list = [[1, 2, 3, 4],[5, 6, 7, 8],[9, 10, 11, 12],[13, 14, 15, 16]
]
row_slice = slice(1, 3)
col_slice = slice(1, 3)
slice_obj_2d = (row_slice, col_slice)
visualize_slice(my_2d_list, slice_obj_2d)
# Original data: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# Slice object: slice(2, 7, 2)
# Sliced data: [2, 4, 6]
# Original 2D data:
# [[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], [13, 14, 15, 16]]
# Slice objects: (slice(1, 3, None), slice(1, 3, None))
# Sliced 2D data:
# [[6, 7], [10, 11]]# 应用八:结合内置函数或方法使用
# 示例1:与列表结合使用
# 创建一个列表
my_list = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 创建一个slice对象
s = slice(2, 7, 2)
# 使用slice对象对列表进行切片
sliced_list = my_list[s]
# 打印结果
print(sliced_list)
# [2, 4, 6]# 示例2:与字符串结合使用
# 创建一个字符串
my_string = "Hello, world!"
# 创建一个slice对象,用于切片字符串
s = slice(7, 12)
# 使用slice对象对字符串进行切片
sliced_string = my_string[s]
# 打印结果
print(sliced_string)
# world# 示例3:与NumPy数组结合使用
import numpy as np
# 创建一个NumPy数组
my_array = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
# 创建一个slice对象
s = slice(2, 7, 2)
# 使用slice对象对NumPy数组进行切片
sliced_array = my_array[s]
# 打印结果
print(sliced_array)
# [2 4 6]# 示例4:与Pandas DataFrame结合使用(多维切片)
import pandas as pd
# 创建一个Pandas DataFrame
df = pd.DataFrame({'A': [1, 2, 3, 4, 5],'B': [10, 20, 30, 40, 50],'C': ['a', 'b', 'c', 'd', 'e']
}, index=['row1', 'row2', 'row3', 'row4', 'row5'])
# 使用标签列表来选择行
rows = ['row2', 'row3', 'row4']
cols = ['A', 'C']
# 使用Pandas的.loc[]方法进行切片
sliced_df = df.loc[rows, cols]
# 打印结果
print(sliced_df)
# A C
# row2 2 b
# row3 3 c
# row4 4 d# 应用九:自定义数据处理的流水线
class CustomData:def __init__(self, data):self.data = datadef slice_data(self, start, stop, step=1):# 这里我们简单地返回数据的一个子集return self.data[start:stop:step]
class DataProcessingPipeline:def __init__(self):self.steps = []def add_step(self, instance, method_name, *args, **kwargs):# 将处理步骤作为元组添加到流水线中# 元组包含实例、方法名、参数和关键字参数self.steps.append((instance, method_name, args, kwargs))def process(self, data):# 按照流水线中的步骤处理数据for instance, method_name, args, kwargs in self.steps:# 使用getattr获取方法,并调用它method = getattr(instance, method_name)data = method(*args, **kwargs) # 注意:这里我们不再传递data给方法return data
# 示例用法
data_instance = CustomData(list(range(10)))
pipeline = DataProcessingPipeline()
pipeline.add_step(data_instance, "slice_data", 2, 7) # 传递实例和方法名
processed_data = pipeline.process(None) # 因为slice_data不需要外部传入的data,所以这里传入None
print(processed_data)
# [2, 3, 4, 5, 6]1-2、VBA:
略,待后补。2、推荐阅读:
2-1、Python-VBA函数之旅-setattr()函数
Python算法之旅:Algorithm
Python函数之旅:Functions