之前介绍过,在任何数据库中,一条DML操作执行都需要在内存中执行,但当操作越来越多,总有时候内存会写满,这时候就需要把内存中的块写入到磁盘,释放内存,保存数据。
写入到磁盘这一步,在不同的数据库中有不同的进程来处理,oracle中有dbwr进程,在PG中有bg writer进程和ckpt(检查点进程)。
在PG中,内存中的块共有三个状态
1.pending:正在修改
2.dirty:已经修改
3.free:已经保存
CKPT触发机制:
1.检查点时间间隔由checkpint_timeout 设置(默认五分钟)。
2.WAL目录(可以看作oracle中的redo)文件的总大小超过参数max_WAL_size的值
3.用户手动发出检查点。
4.数据库正常关闭的情况下。(其实这点oracle中也会做,在oracle中执行shutdown immediate之后会自动发出检查点命令,讲内存中的脏块写入到数据文件,相当于alter system checkpoint)。

PG检查点的作用
与Oracle类似:
1.定期保存修改过的数据块,内存中的数据会丢失,如果定期的把内存中的数据写入到磁盘就可以预防断电等故障的发生。
2.作为实例恢复时其实位置,这点和Oracle也很类似,每次发生检查点都会发一个号码记录在控制文件中,控制文件中记录了检查点如下相关信息:
1.最新检查点记录的LSN位置
2.先前检查点记录的LSN位置
(Oracle中叫做SCN号,PG中叫做LSN号。)
查看PG控制文件的命令:
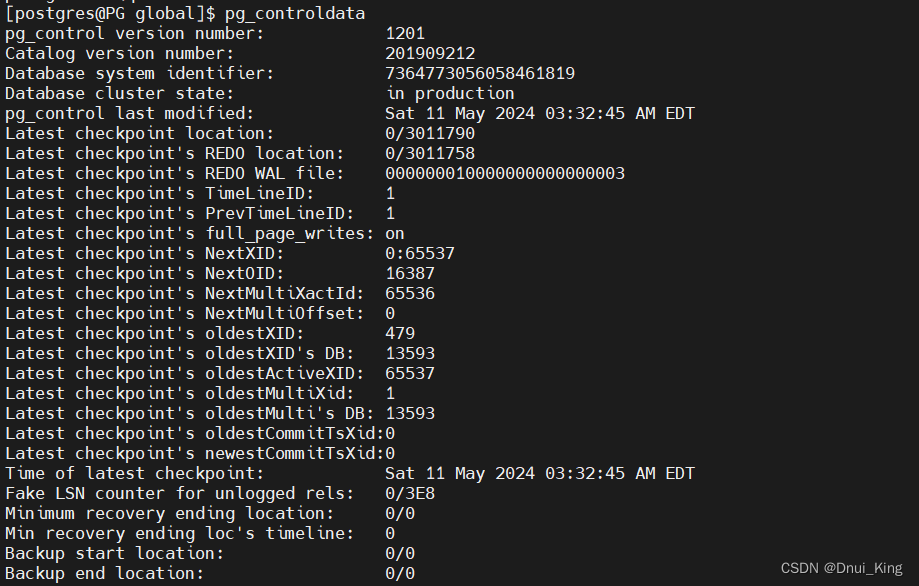
关于PG的控制文件之前有写过博客:
PG控制文件的管理与重建-CSDN博客
3.作为介质恢复的起始位置。
检查点的处理过程:
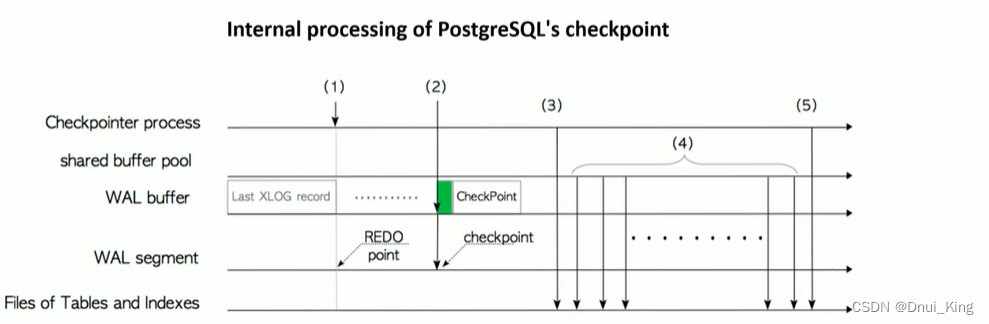
当触发一个检查点
1.首先会记录一个redo点,用来当作将来恢复的起始位置。
2.第二步再做一个检查点,所以可以这样理解,检查点记录了redo点的位置。
所以在将来恢复的时候,PG会先找到检查点的位置,再根据检查点的位置找到redo点的位置,然后从这个redo点,根据WAL日志 里面的内容重新做一遍。
3.把最近的脏块写入到数据文件。
如何利用检查点作为recovery的起始位置:

检查点该如何设置?
checkpoint timeout(检查点发生的频率)
检査点发生的间隔时间决定了实例恢复需要的时长, checkpoint timeout设置的值应该根据业务的需求设置,以实例崩溃时,下一次打开数据库时长的容忍度而设置。
间隔时间短,则实例恢复需要的时间就短,可提高数据库的可用性,但是会增加/O操作,降低数据库状态性能,检査点发生时属于密集型/O操作,会占用大量系统资源。
间隔时间长,则实例恢复需要的时间就长,会降低数据库的可用性,但是会减少/O操作,提高数据库状态性能。
checkpoint_completion_target(检查点完成目标)
参数的意思是:控制每次检查点发生时i/o的吞吐量
值越高,则i/o占用的资源越少。
值越低,则i/o占用的资源越多,影响数据块性能,但是提高检查点完成速度。