提示:需要完整版ppt请私信
文章目录
- 一、大会主旨报告
- 主旨报告-1:大模型时代的机遇和挑战
- 主旨报告-2:以深度学习框架为牵引促进自主 AI生态发展
- 主旨报告-3:从洞穴的影子到智能的光辉--连接和交互方式的改变塑造未来生活 (未完成)
- 二、大会特邀报告
- 1:图像生成和视频生成若干前沿技术探索
- 2:混合模型驱动的内容生成与具身智能
- 3:多模态视觉融合方法:是否存在性能极限
- 4:三维场景理解的前世、今生与未来
- 三、年度进展评述
- 1.符号知识和大模型
- 2.智能体视觉
- 3.视觉通用人工智能
- 4.视频生成
- 5.面向具身智能的多模态感知与交互具身
- 6.三维高斯泼溅(3D GS)
- 8.面向大模型的新型高效率网络架构
- 9.视觉基础大模型
一、大会主旨报告
主旨报告-1:大模型时代的机遇和挑战
讲者:沈向洋(香港科技大学)




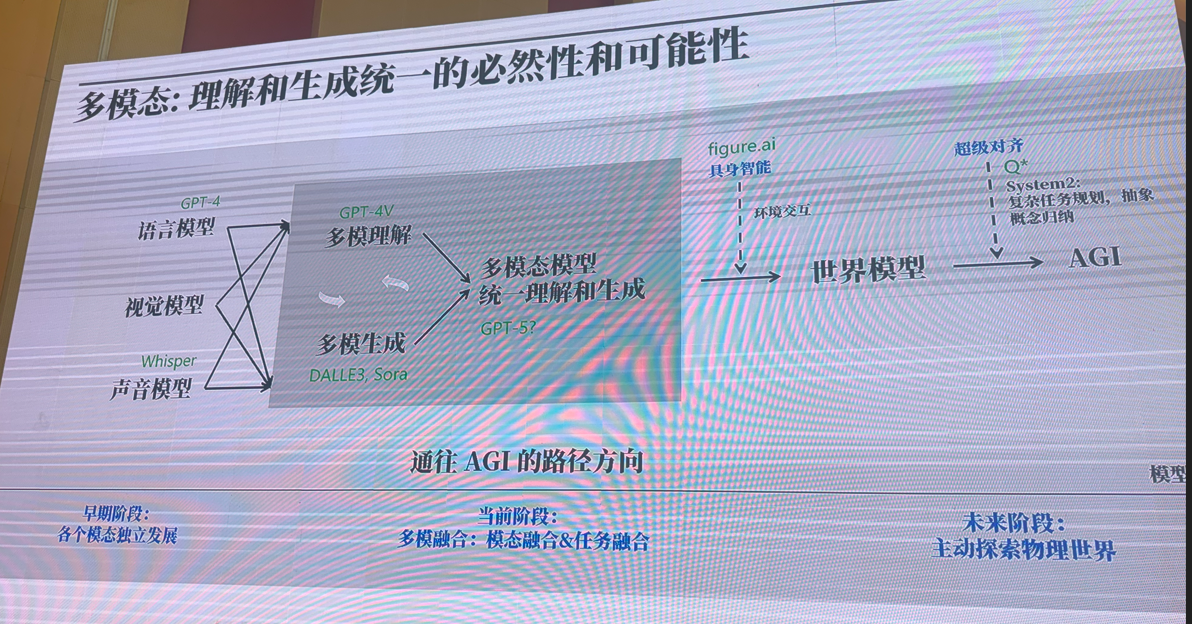




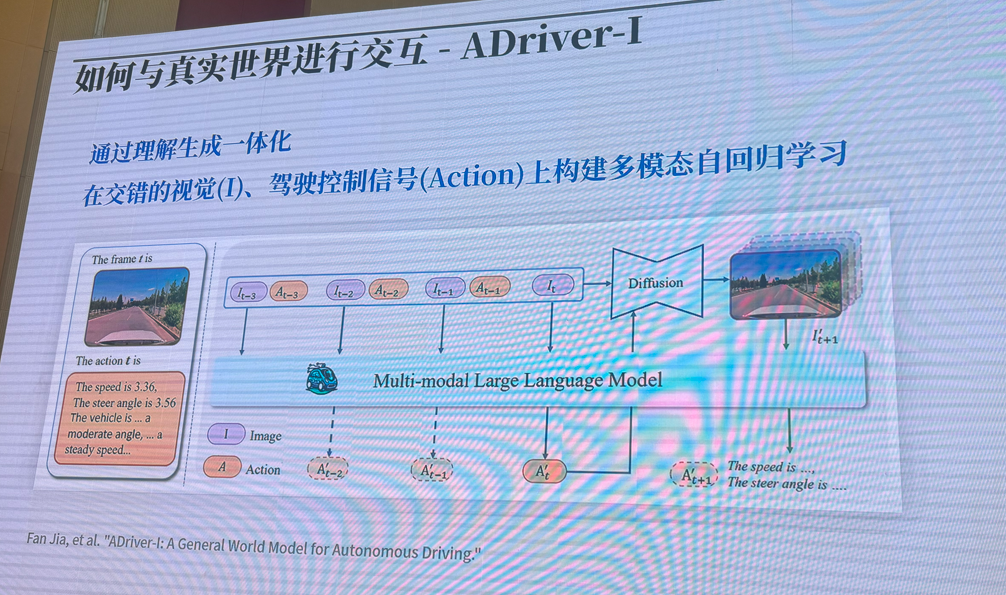
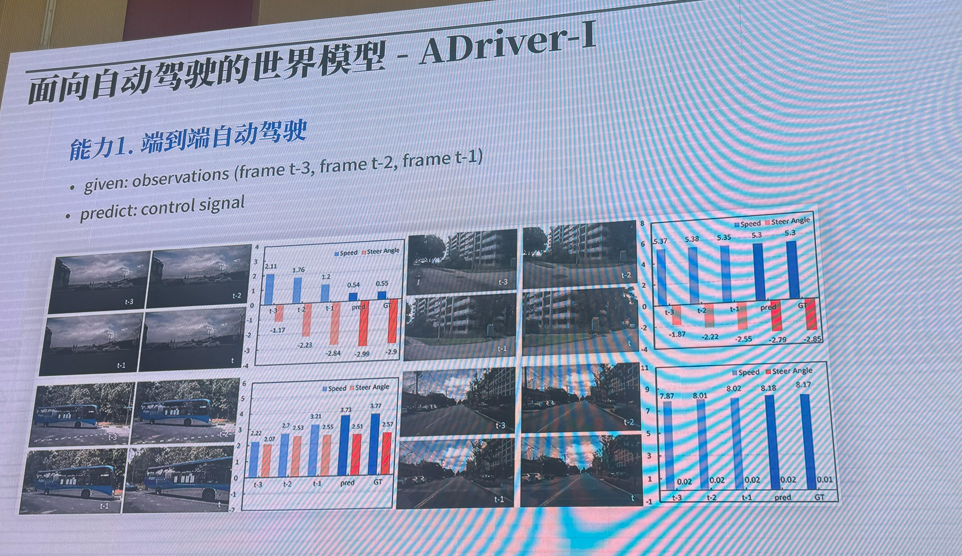






主旨报告-2:以深度学习框架为牵引促进自主 AI生态发展
胡事民(清华大学)





















































主旨报告-3:从洞穴的影子到智能的光辉–连接和交互方式的改变塑造未来生活 (未完成)
主讲:李学龙(中国电信人工智能研究院(TeleAI)
二、大会特邀报告
1:图像生成和视频生成若干前沿技术探索
李鸿升(香港中文大学)
2:混合模型驱动的内容生成与具身智能
杨 易(浙江大学)

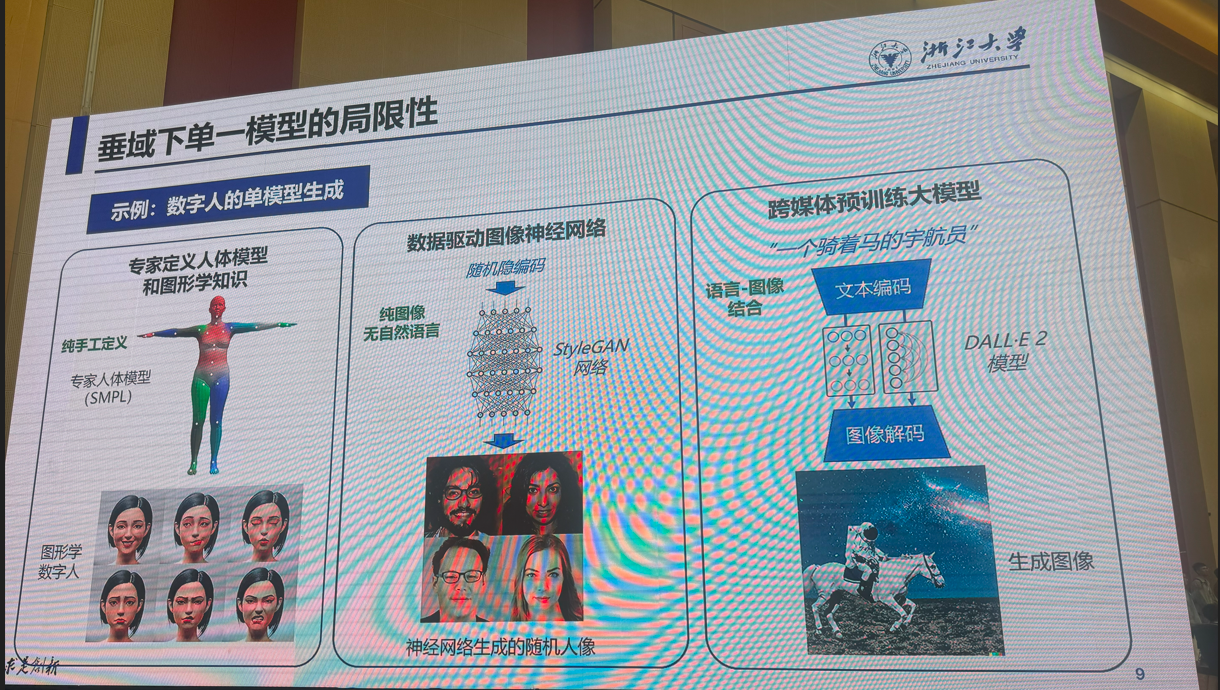
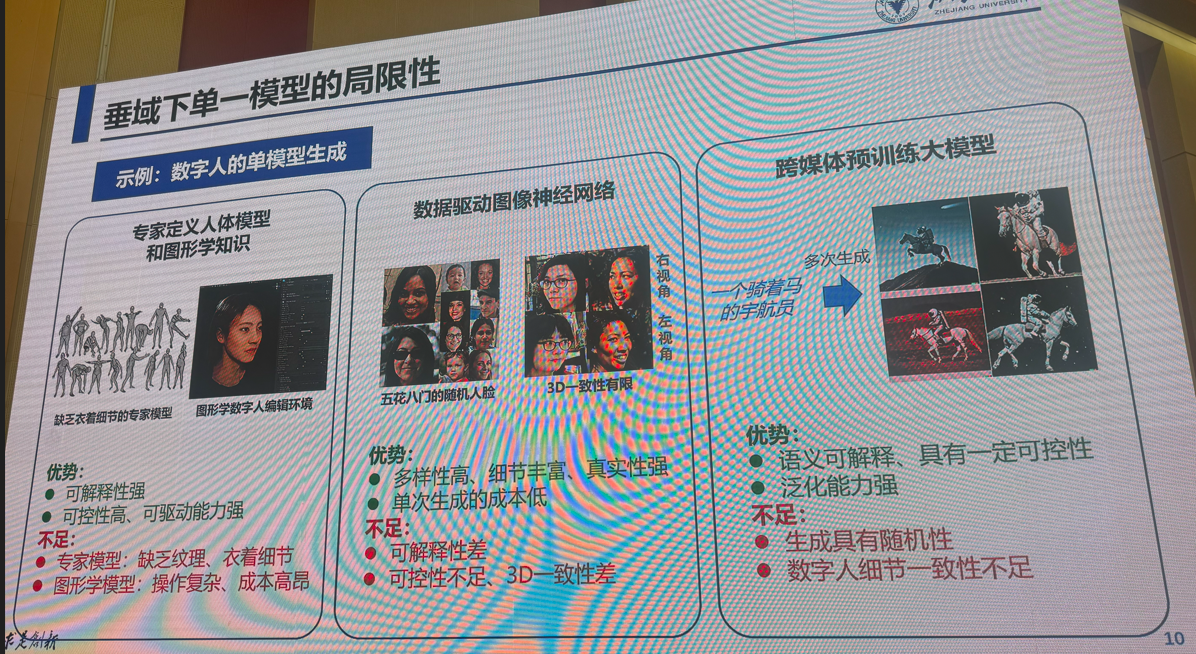

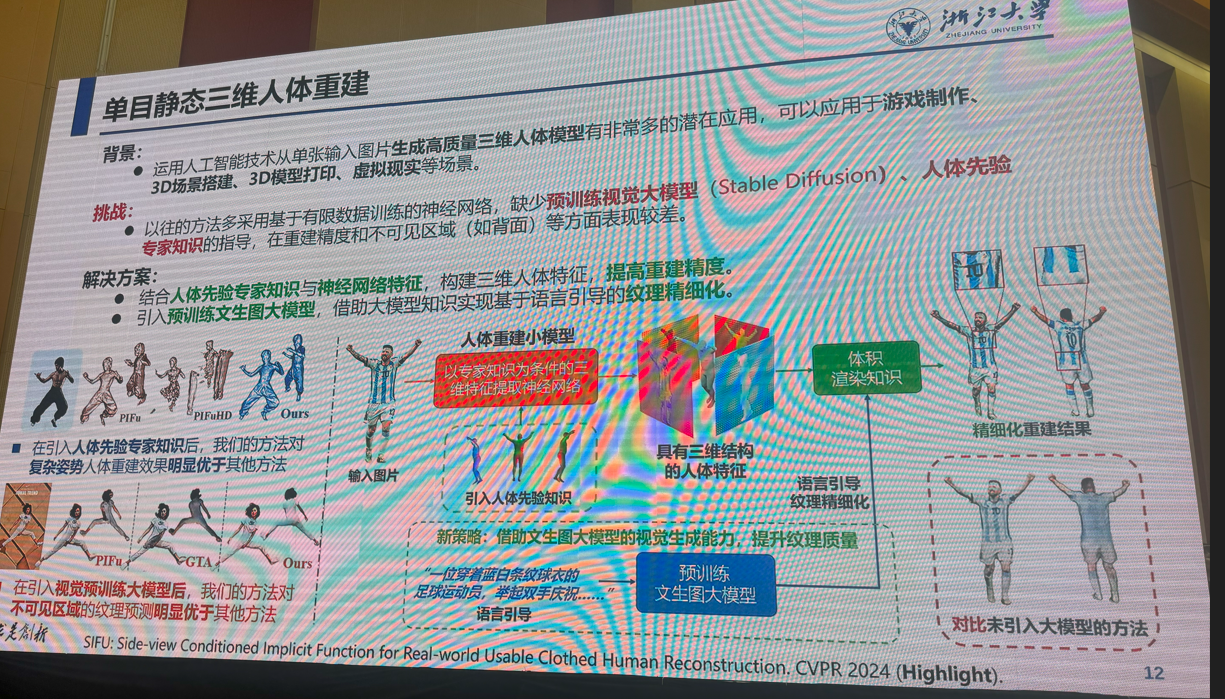
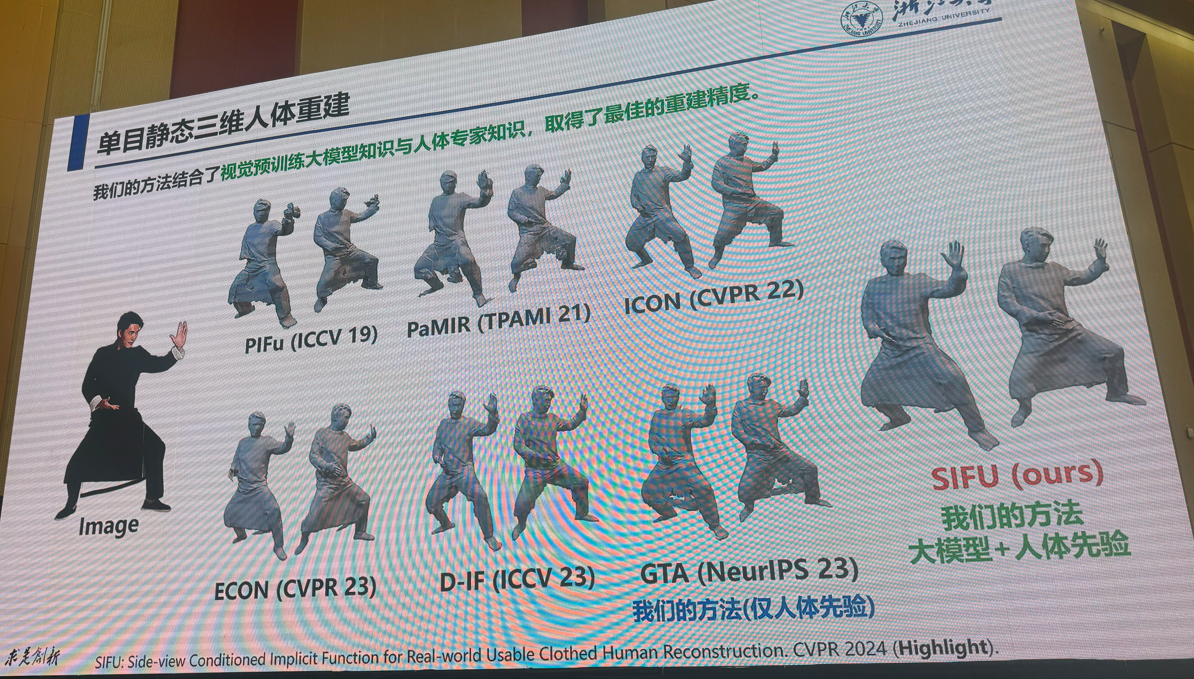



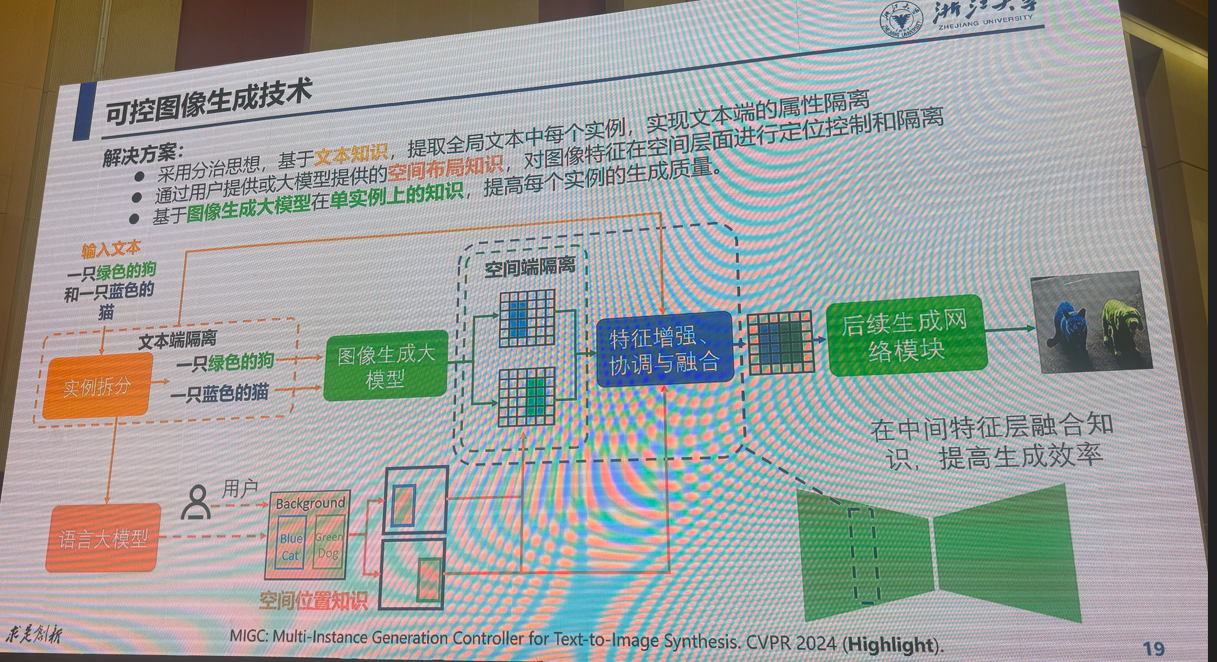













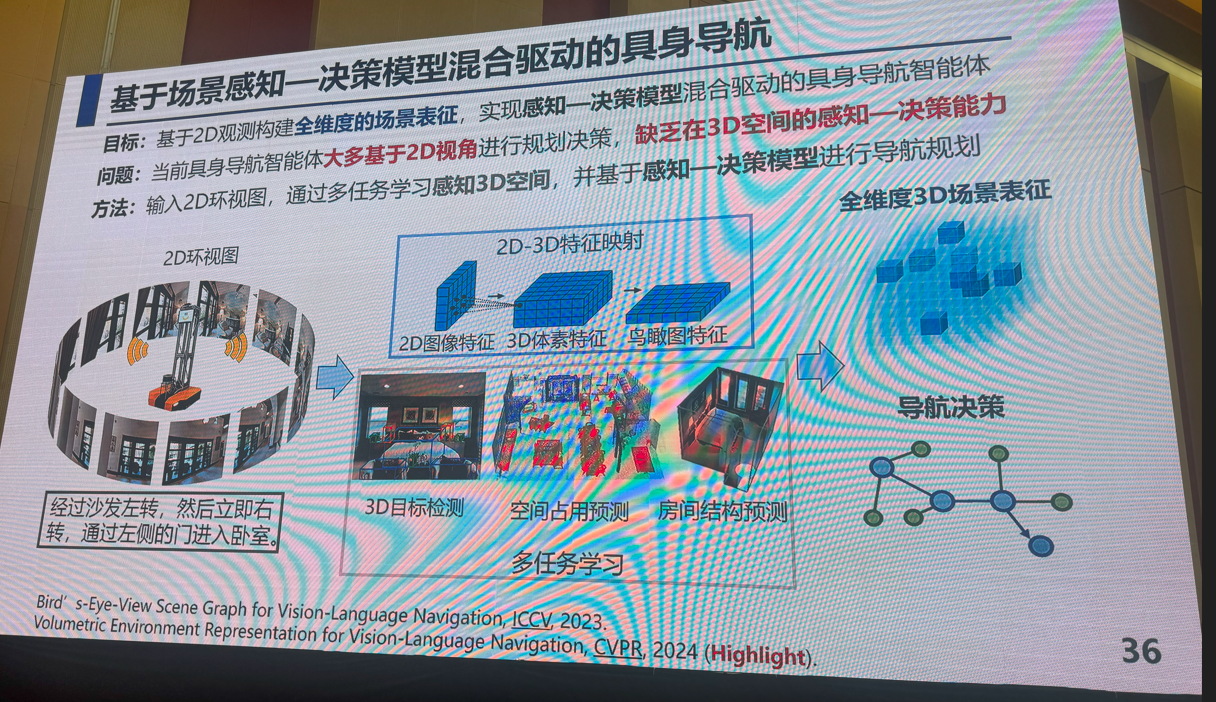
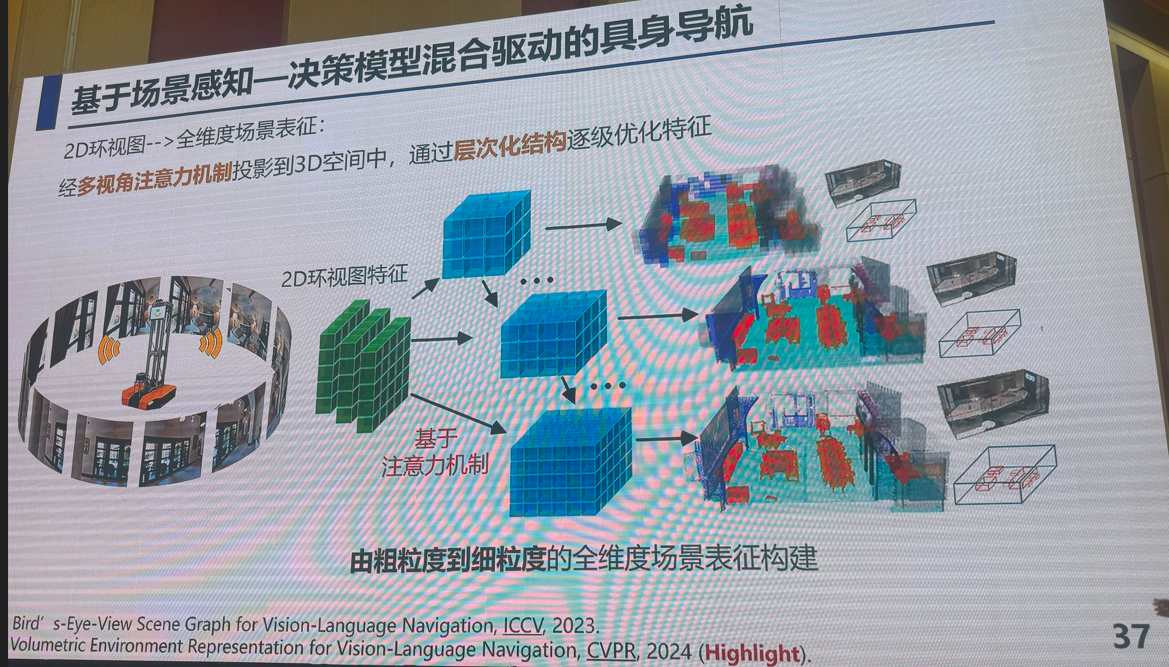
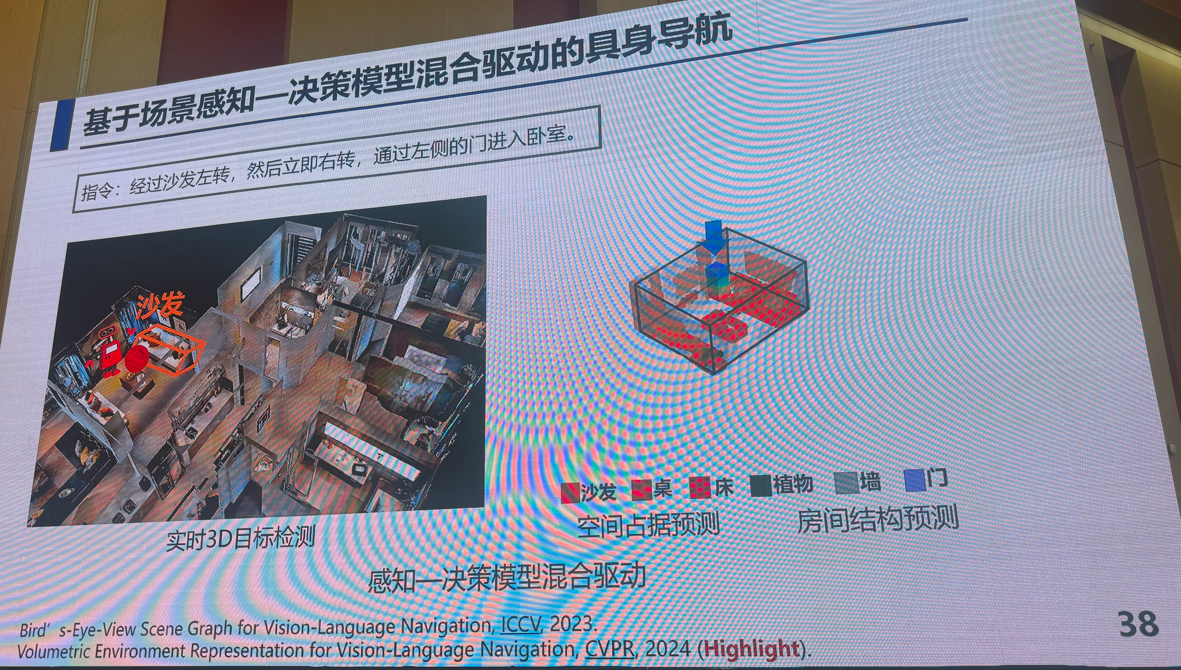


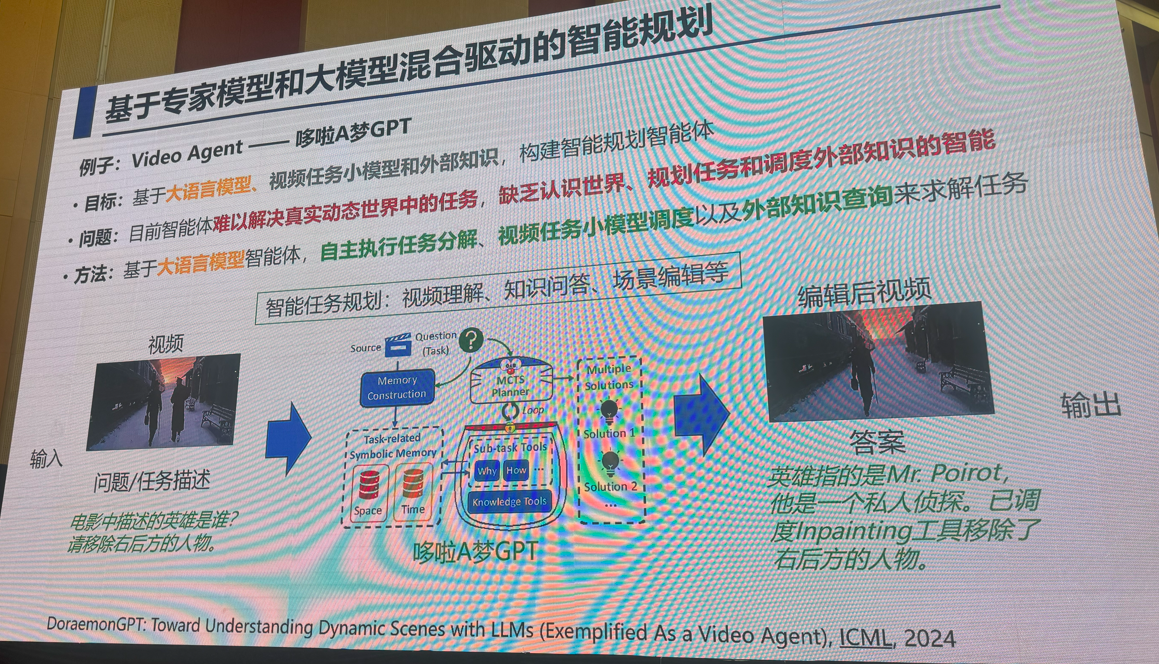
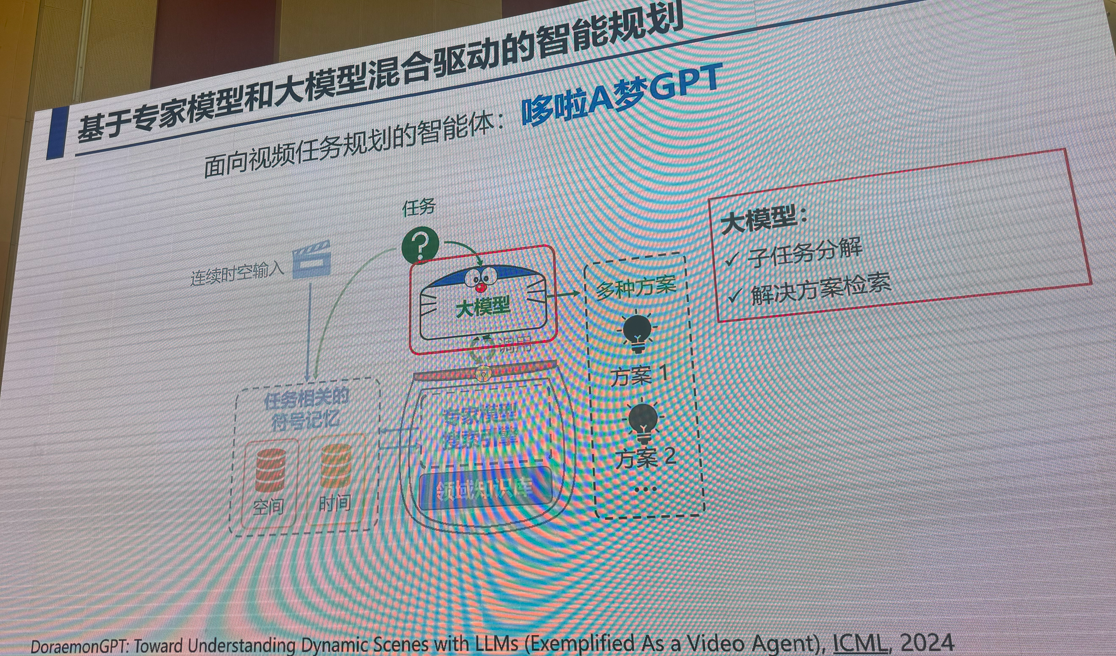
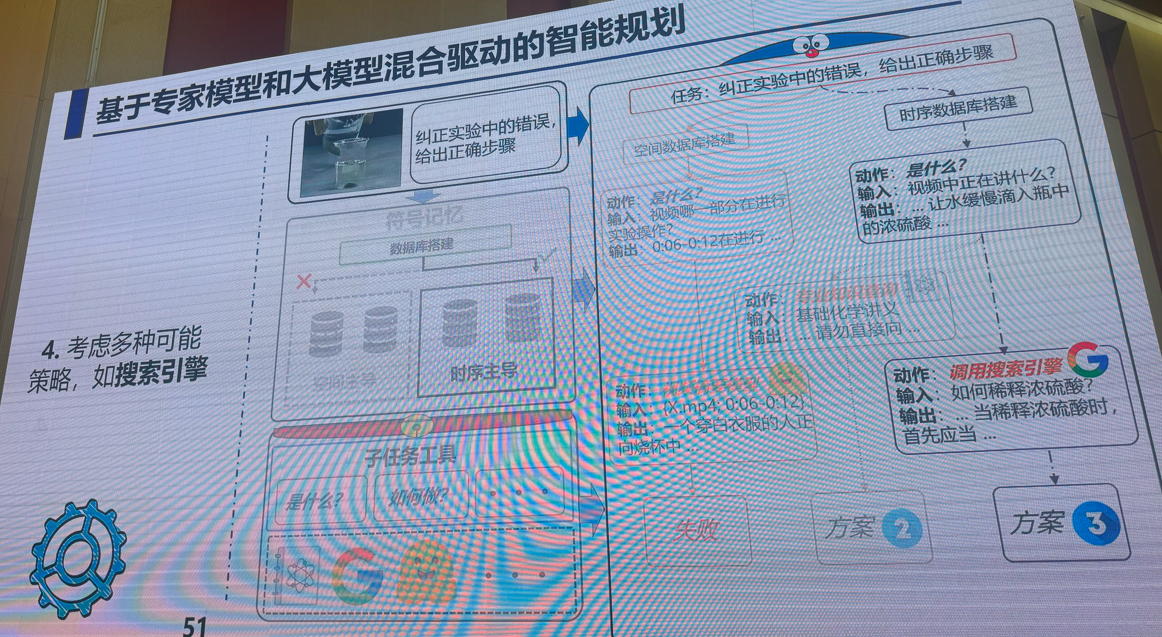


3:多模态视觉融合方法:是否存在性能极限
吴小俊(江南大学)

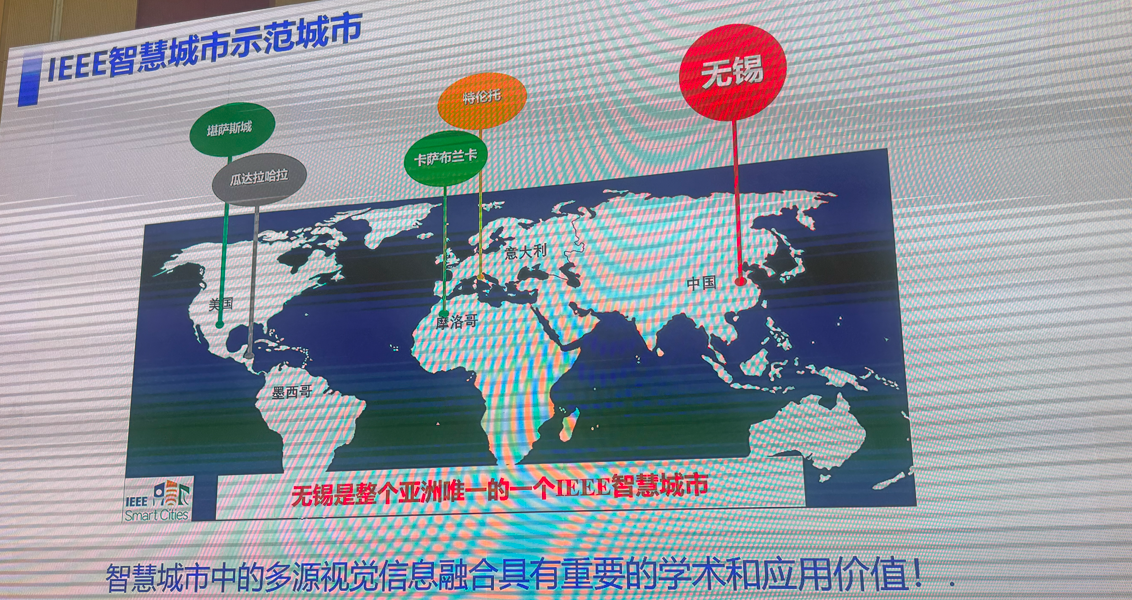
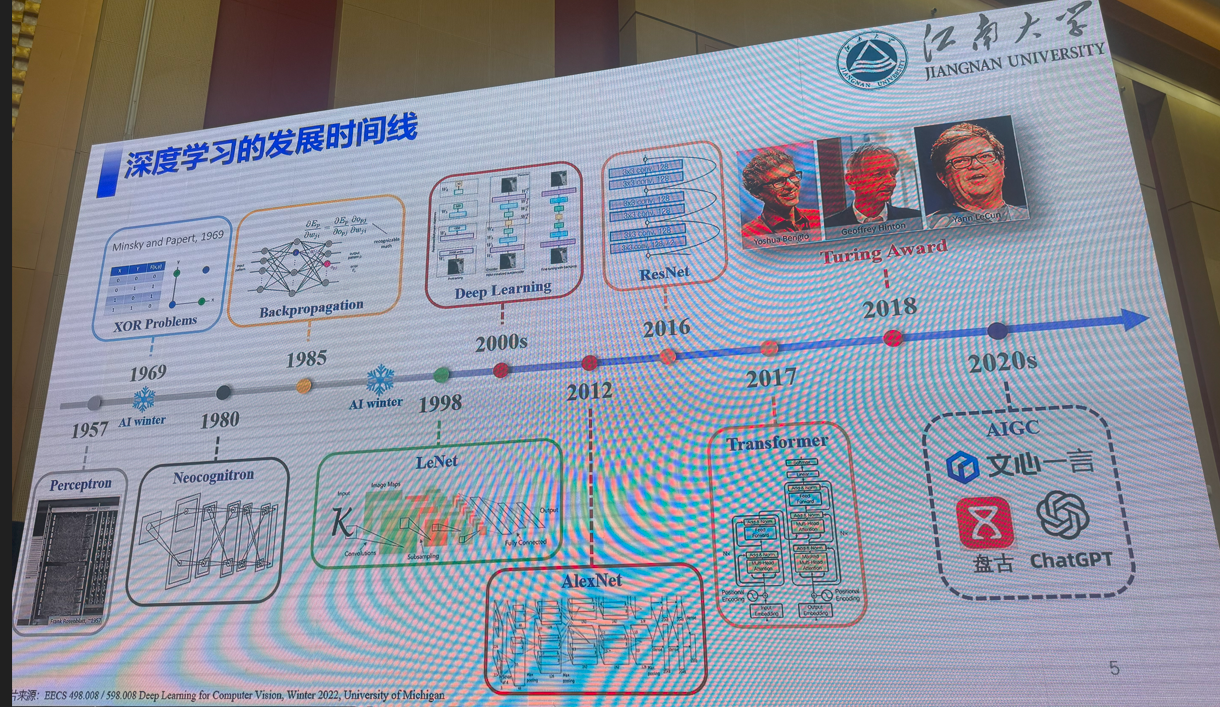
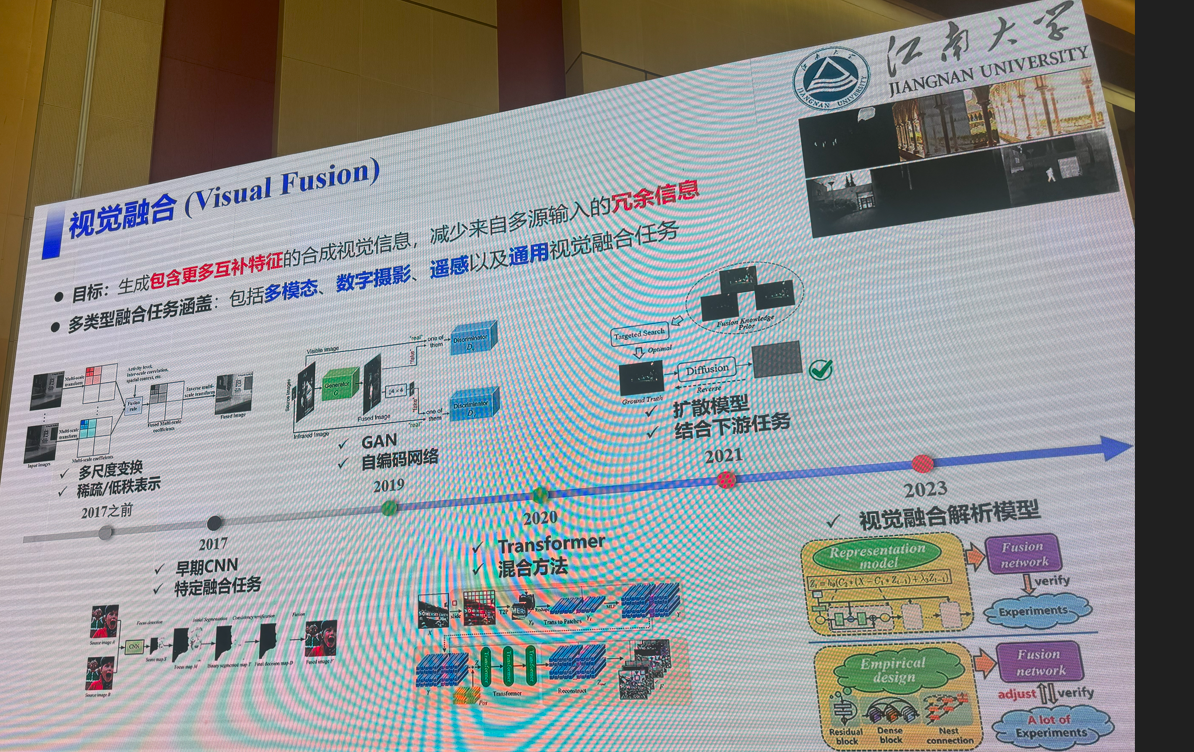

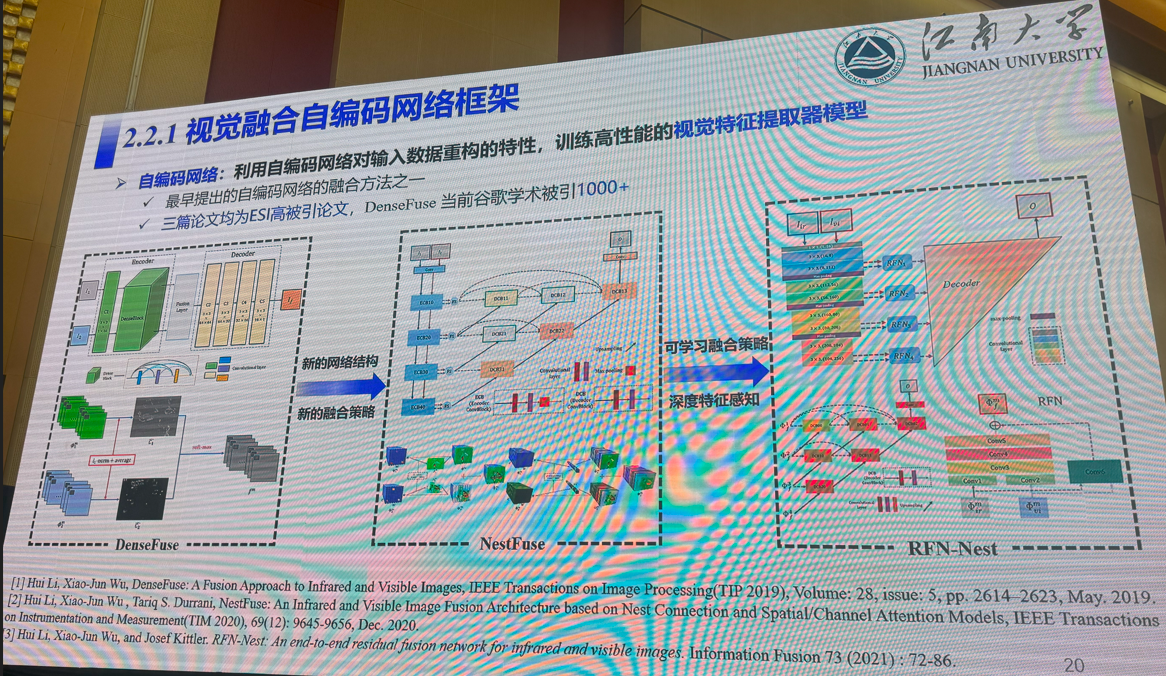



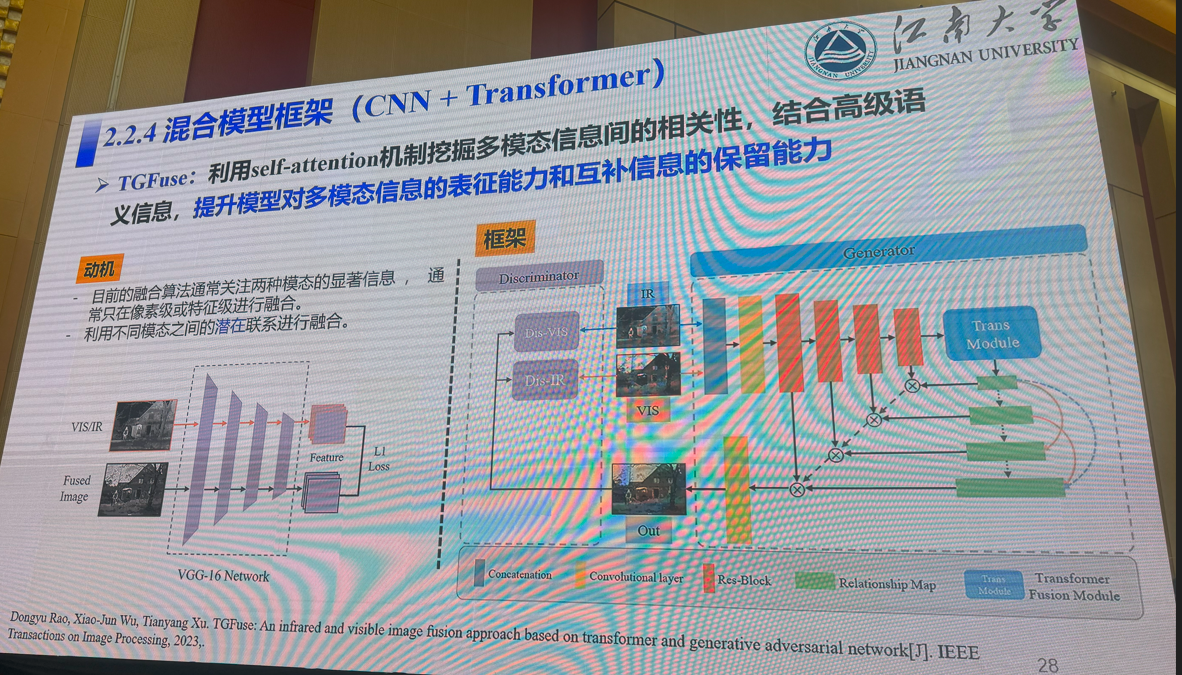
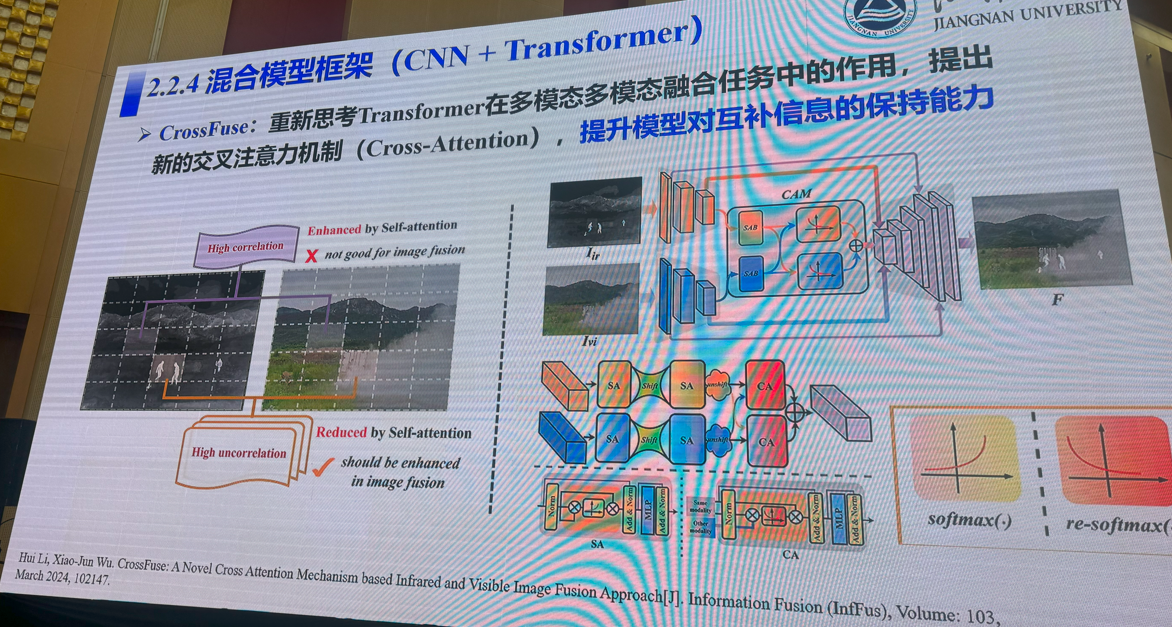
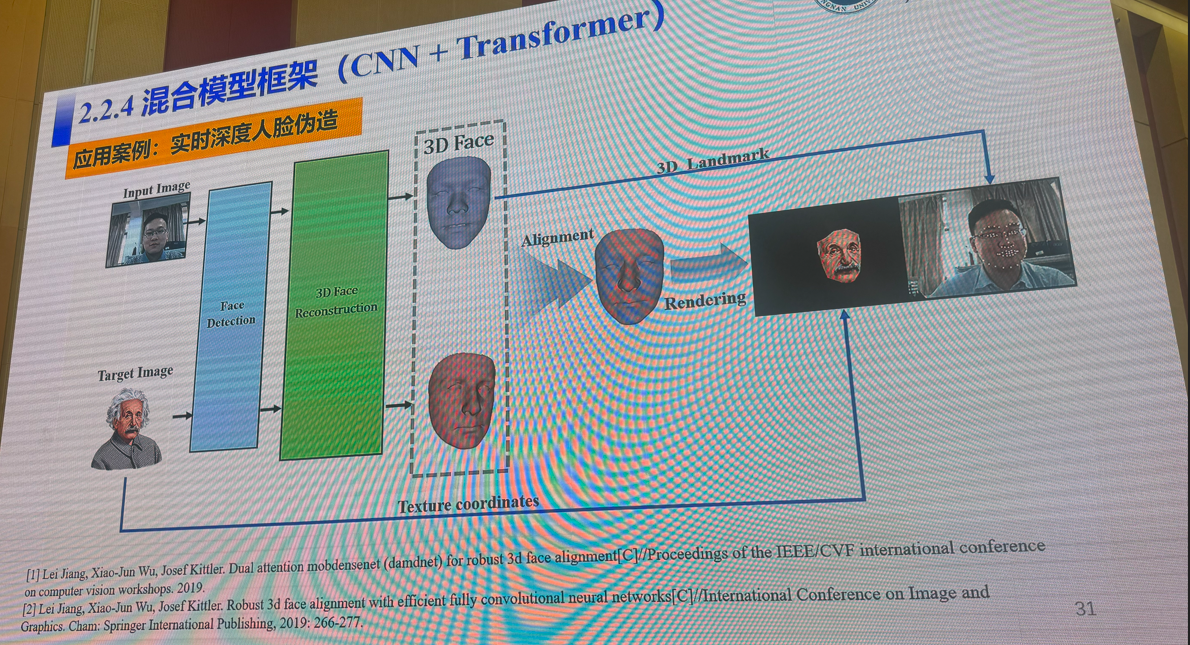
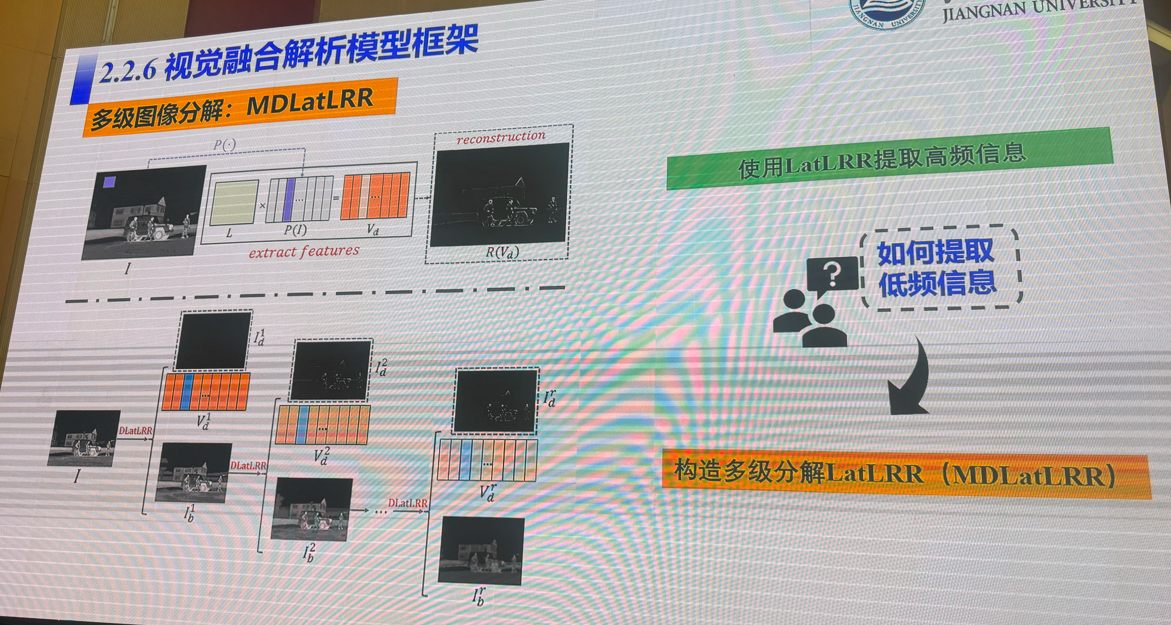
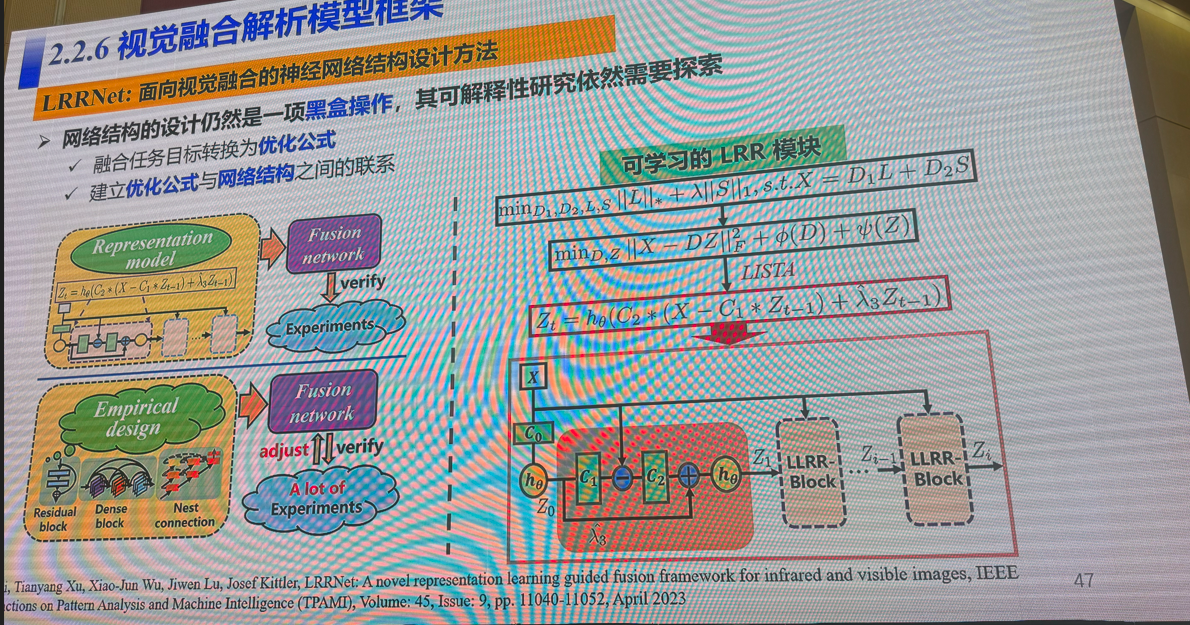
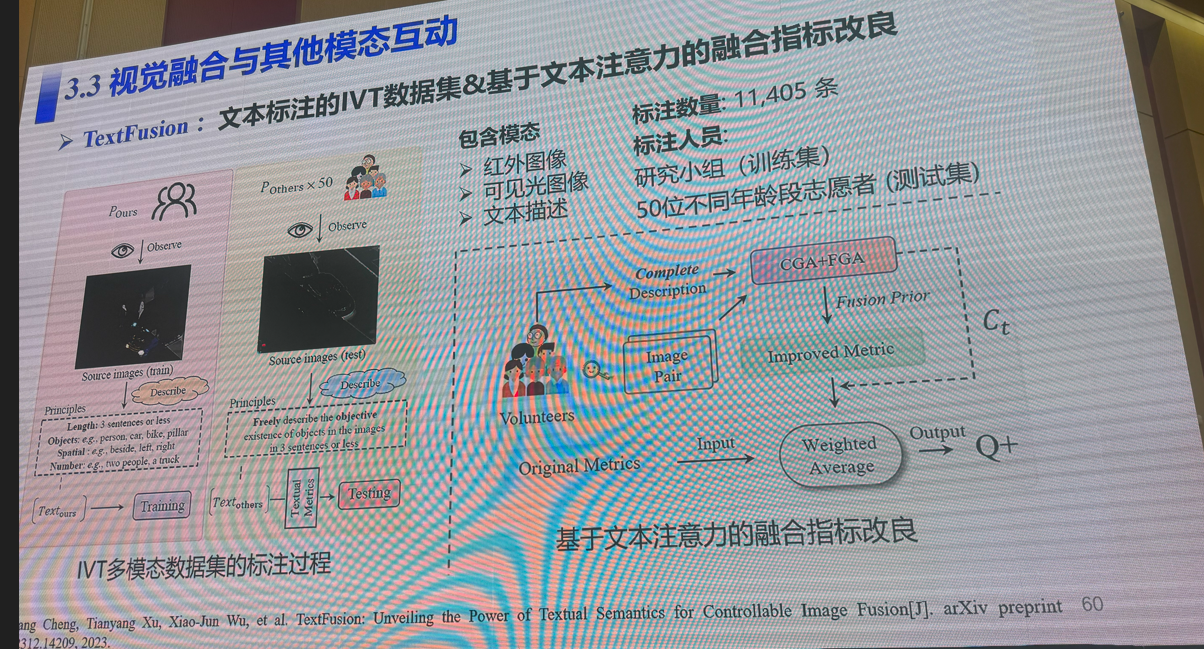
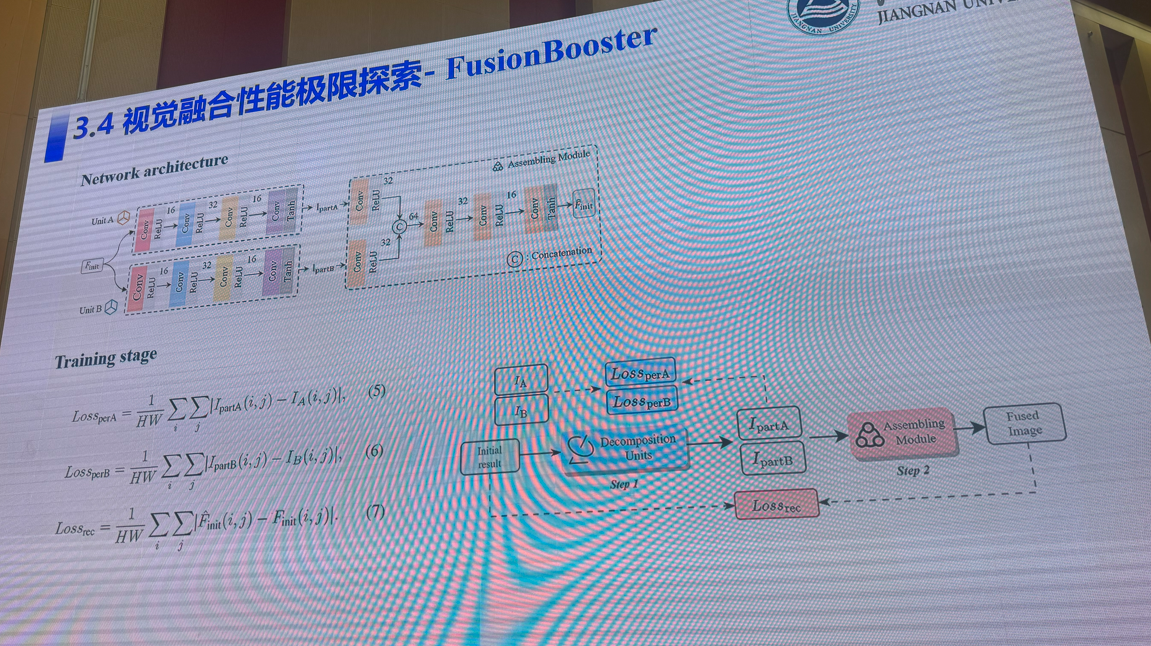

4:三维场景理解的前世、今生与未来
马月昕(上海科技大学)






















































三、年度进展评述
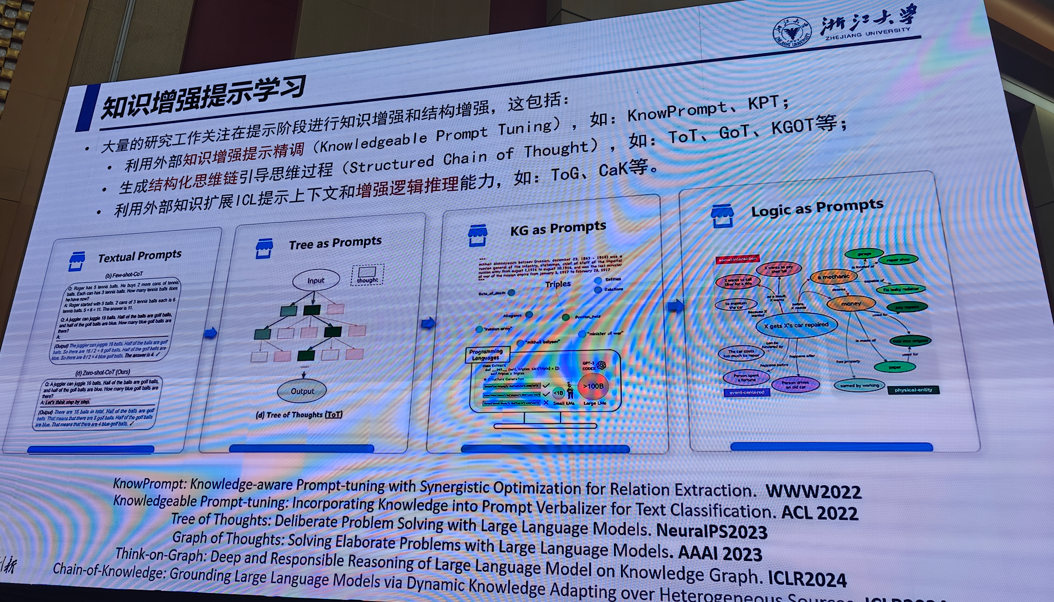
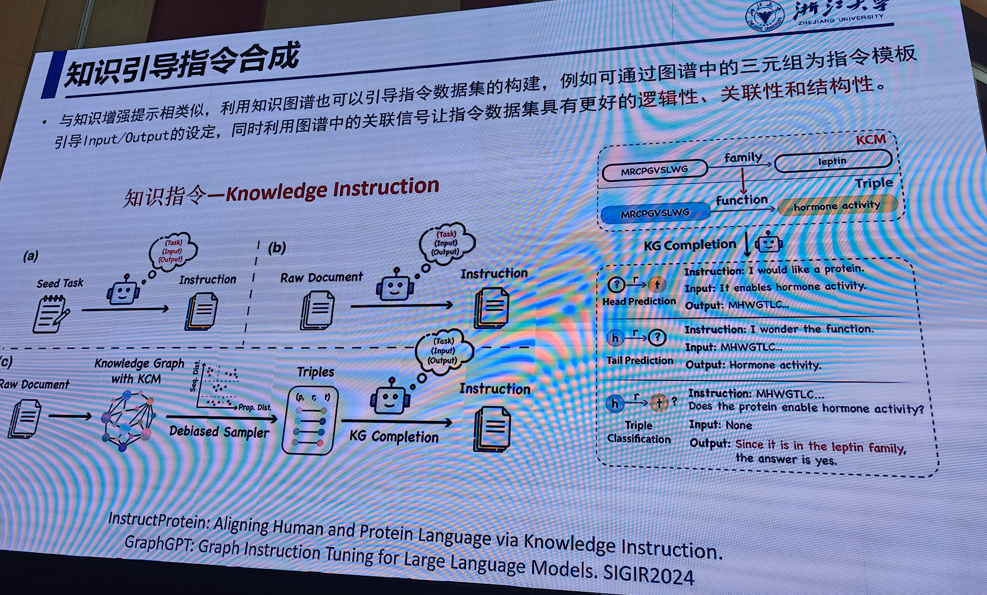
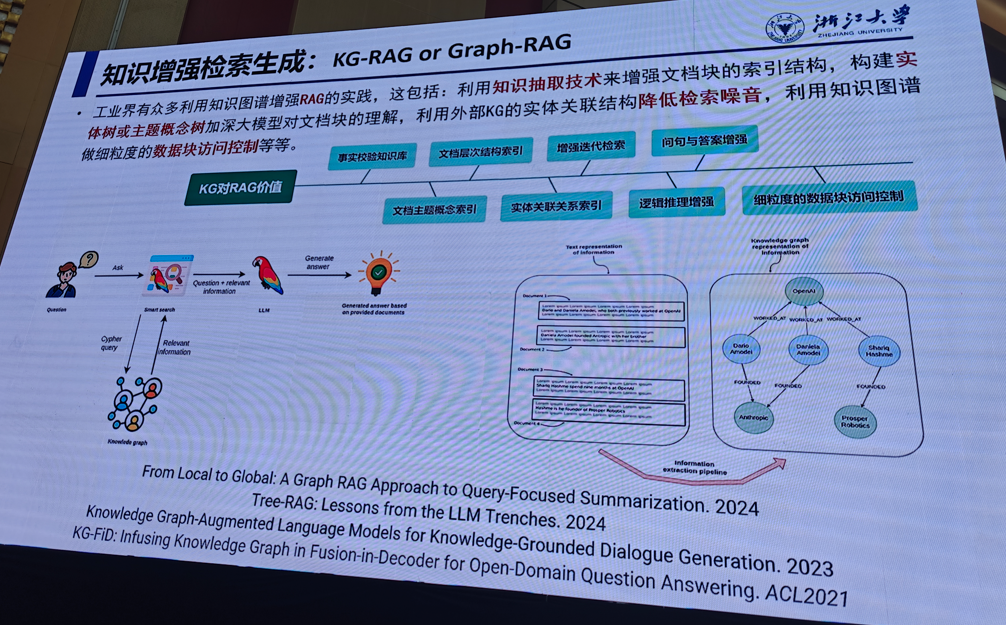
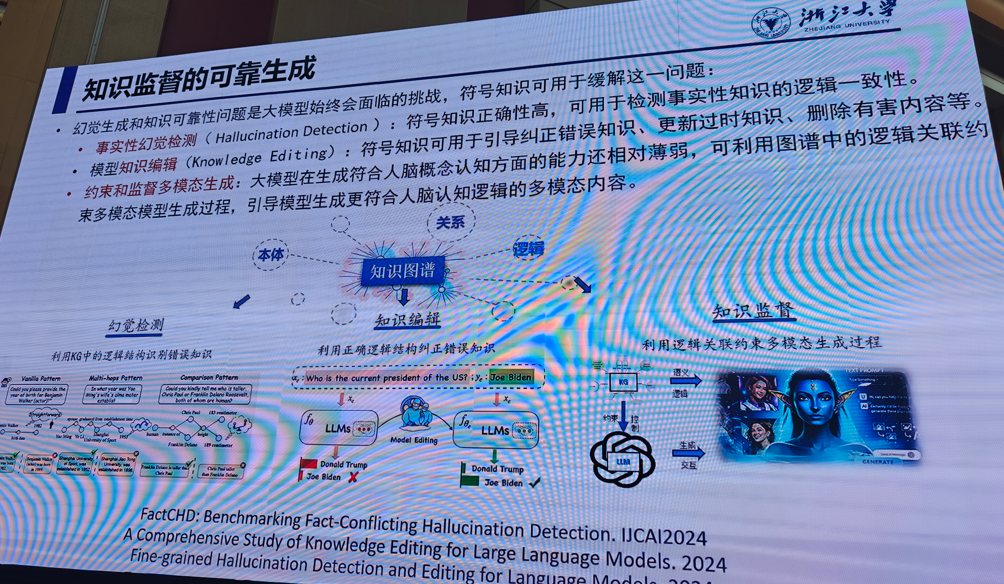
1.符号知识和大模型
陈华钓(浙江大学)


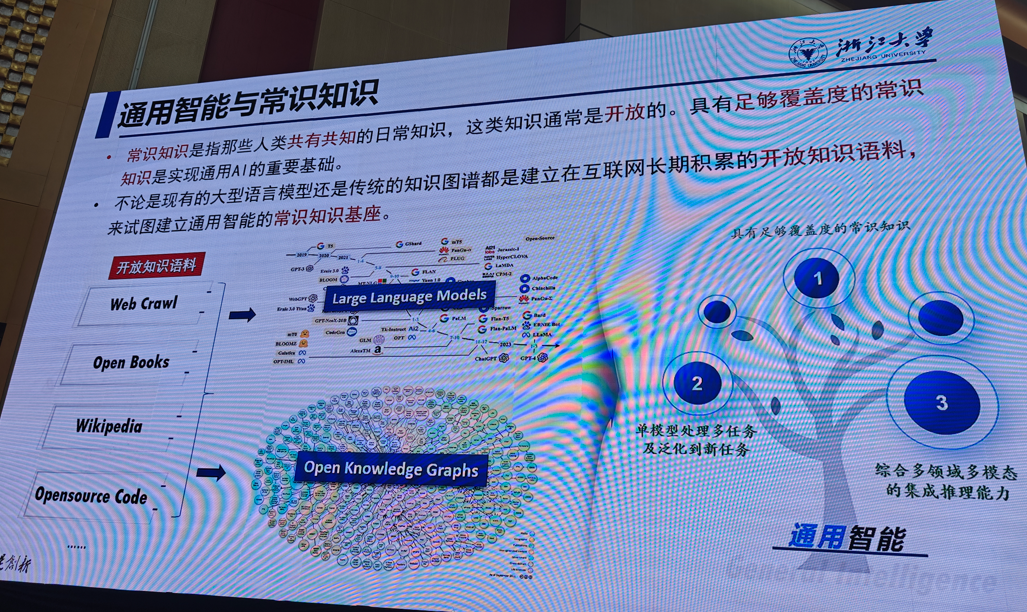
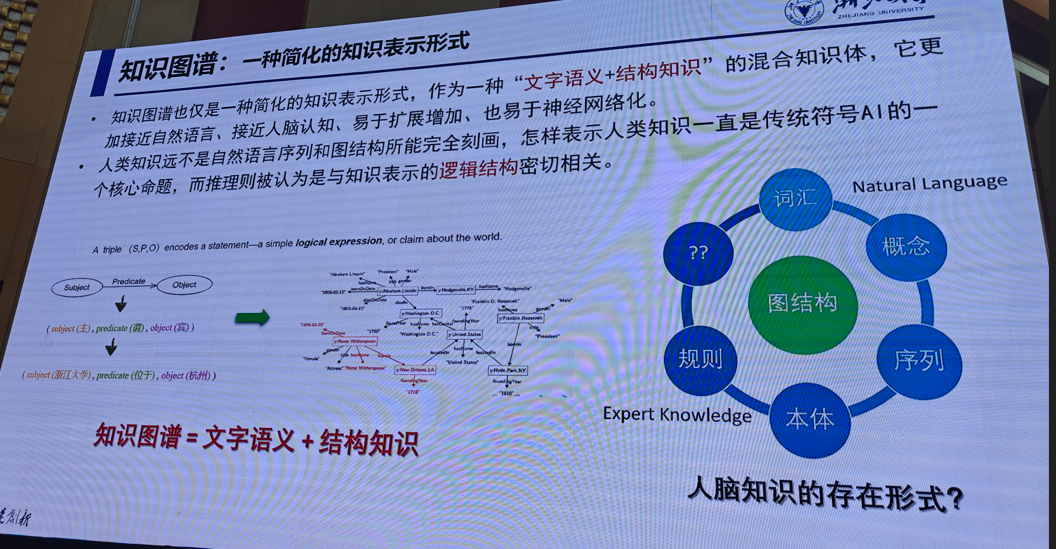

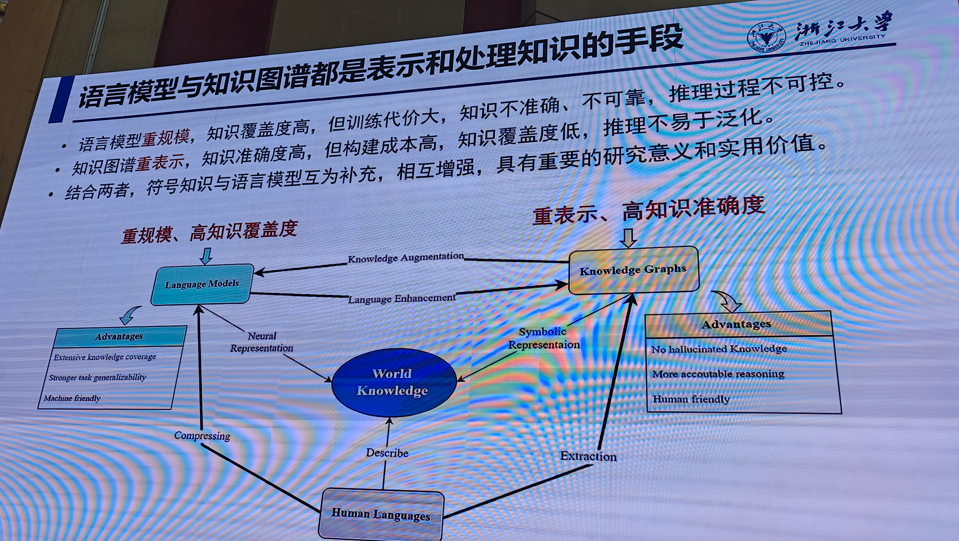

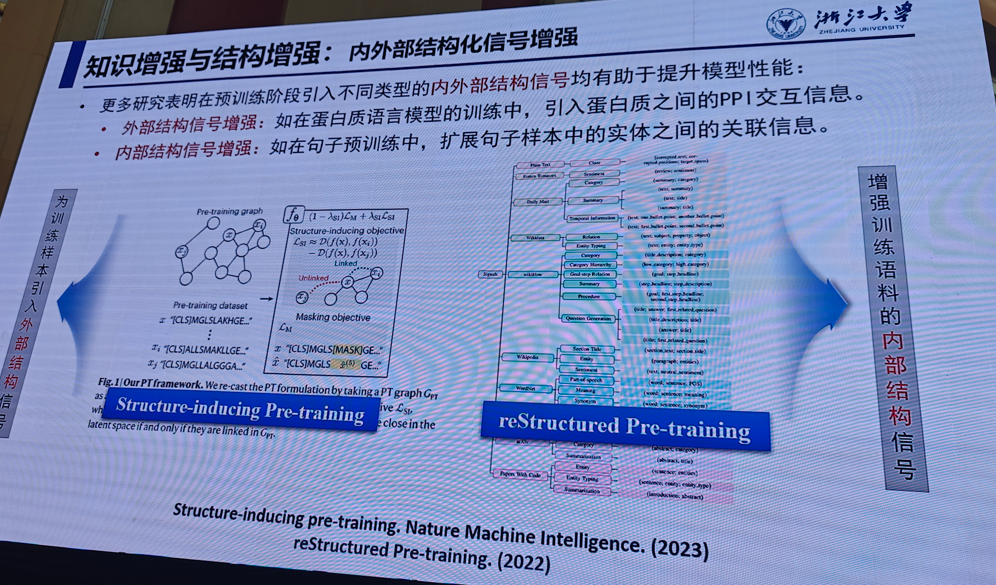
提示:后续ppt请私信,这里不完整
2.智能体视觉
代季峰(清华大学)

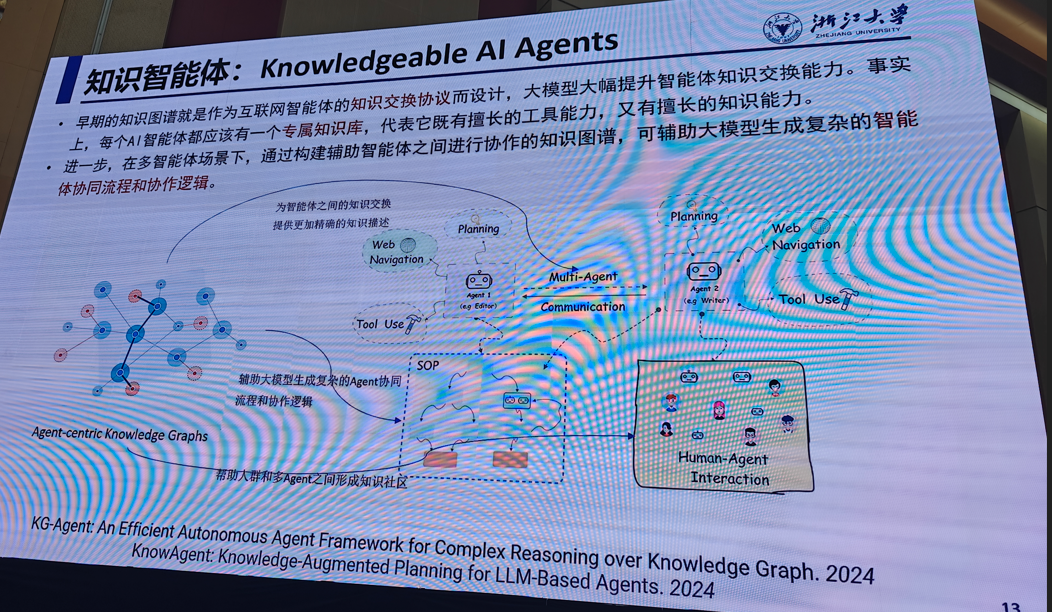
提示:后续ppt请私信,这里不完整
3.视觉通用人工智能
谢凌曦-华为























4.视频生成
卢志武-中国人名大学










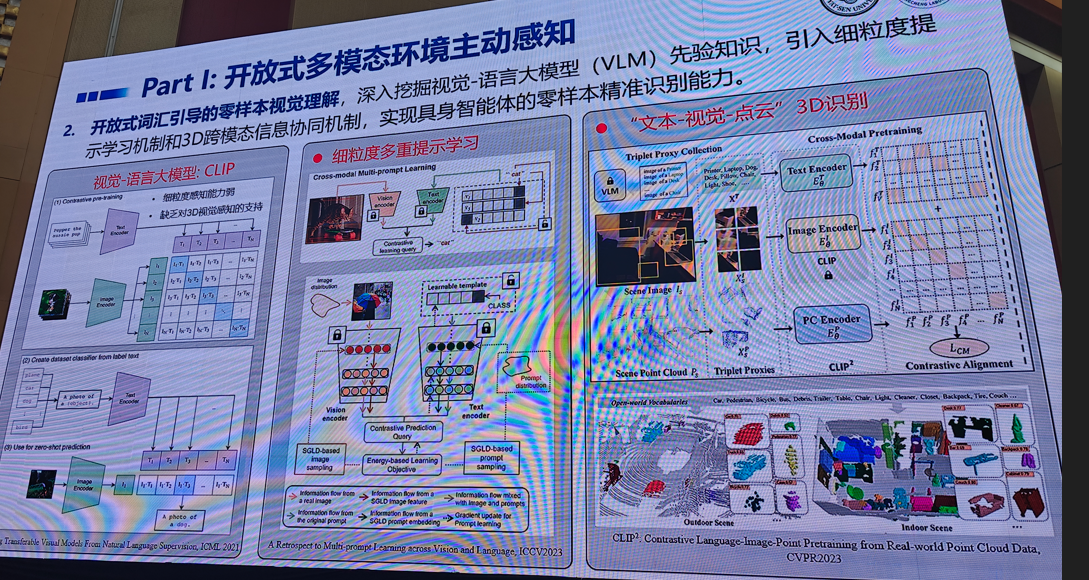
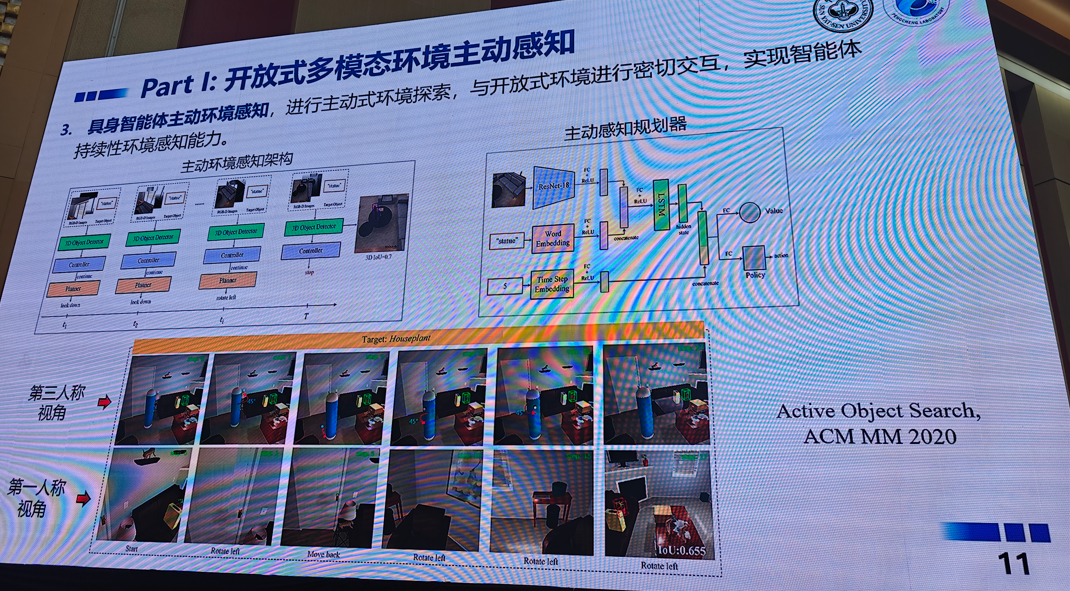
5.面向具身智能的多模态感知与交互具身


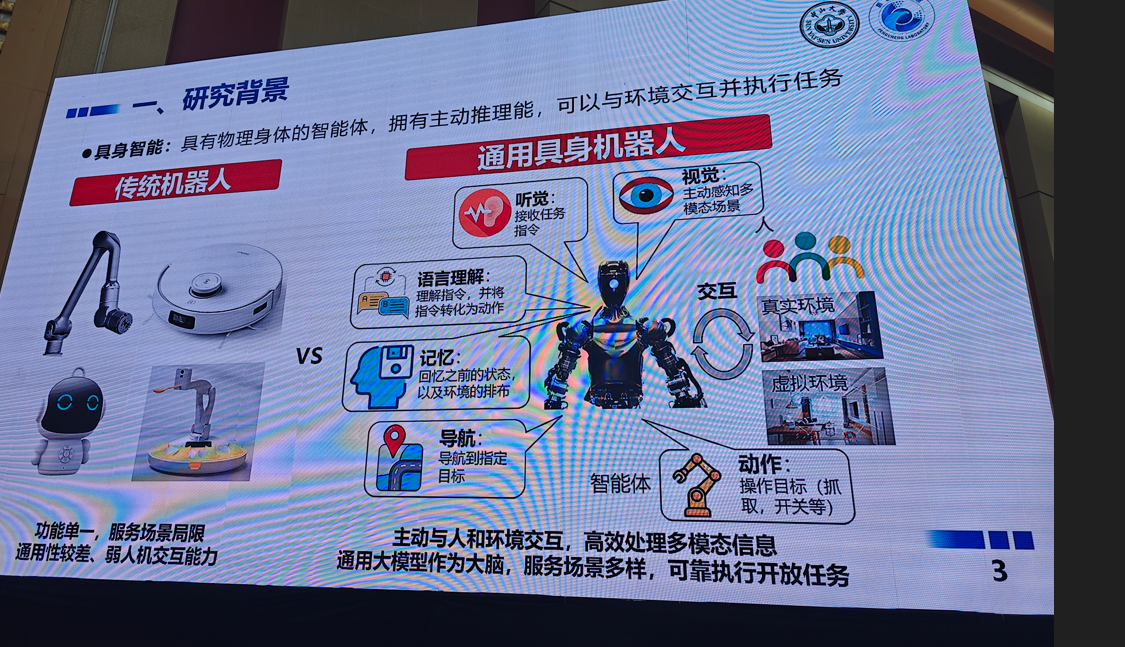


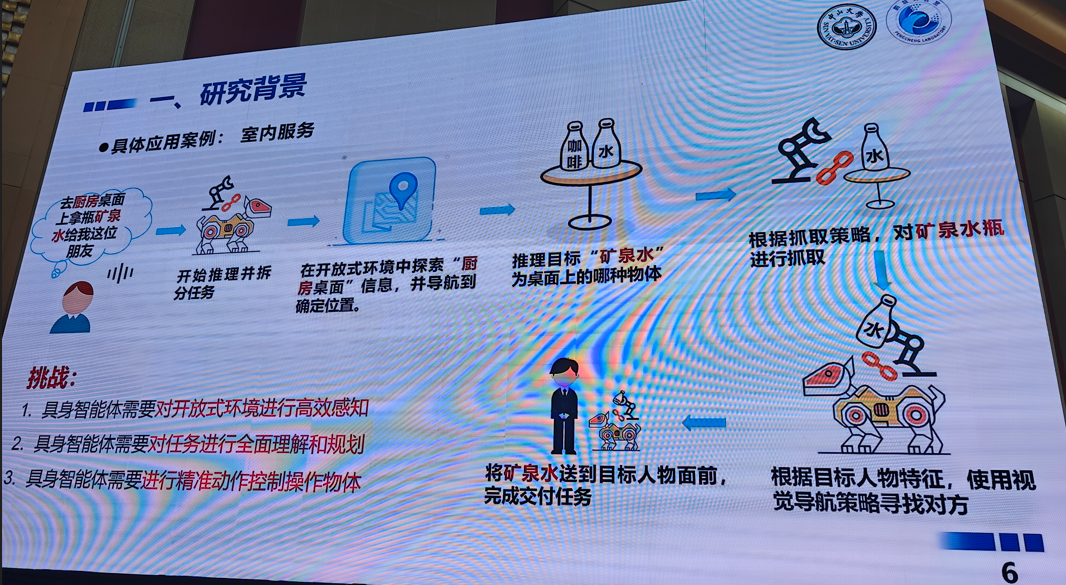
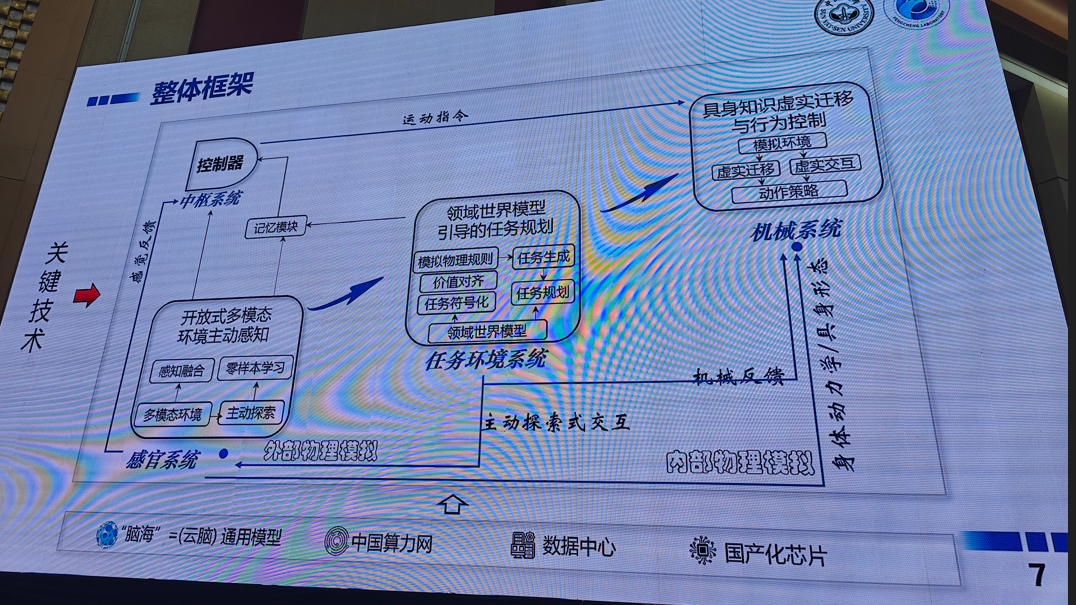

6.三维高斯泼溅(3D GS)




























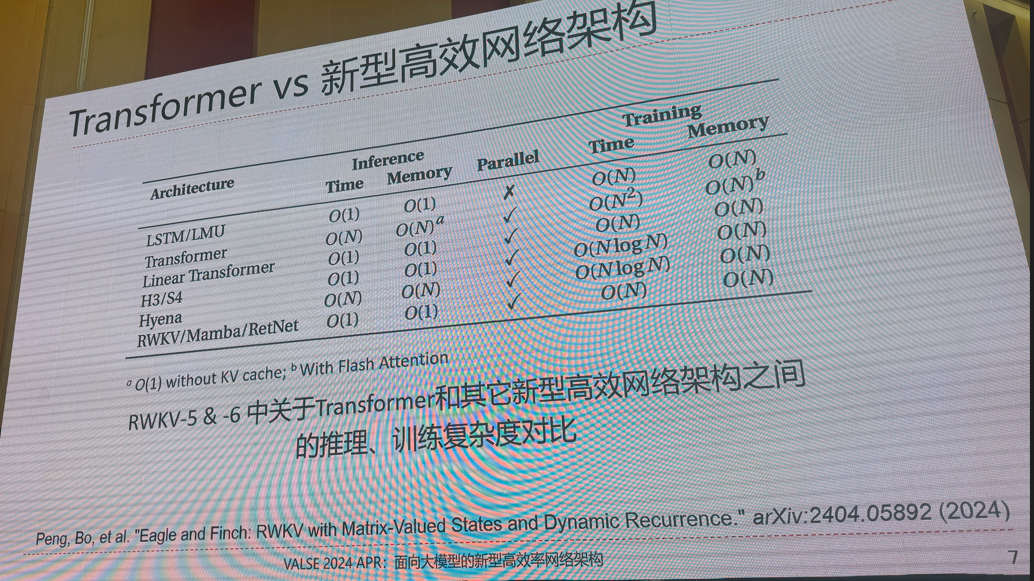
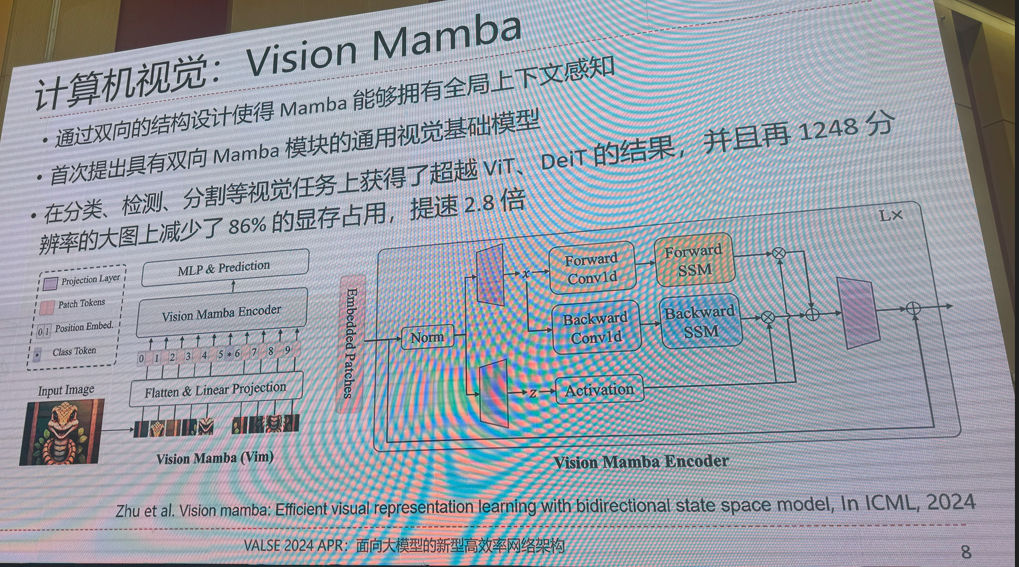
8.面向大模型的新型高效率网络架构






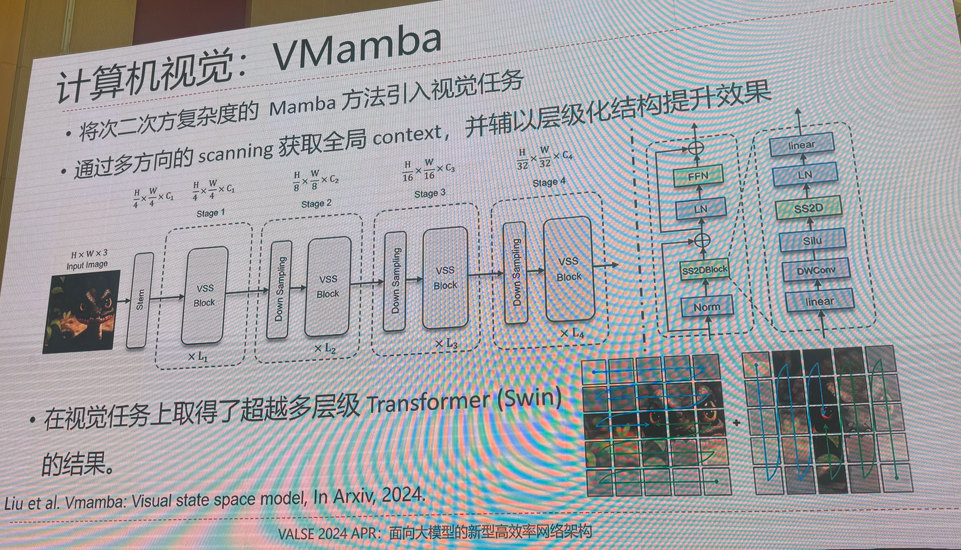
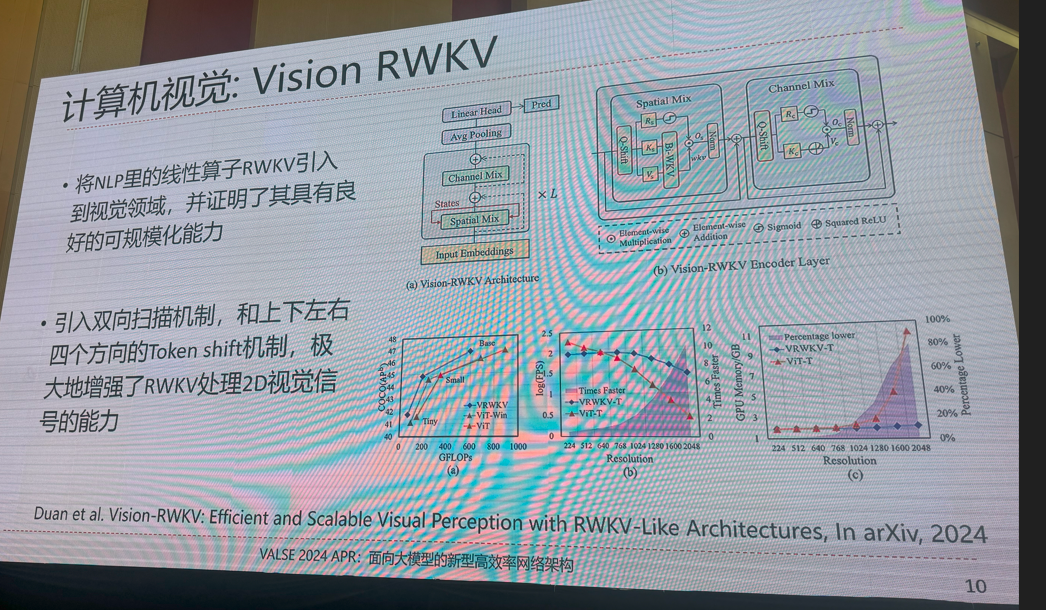

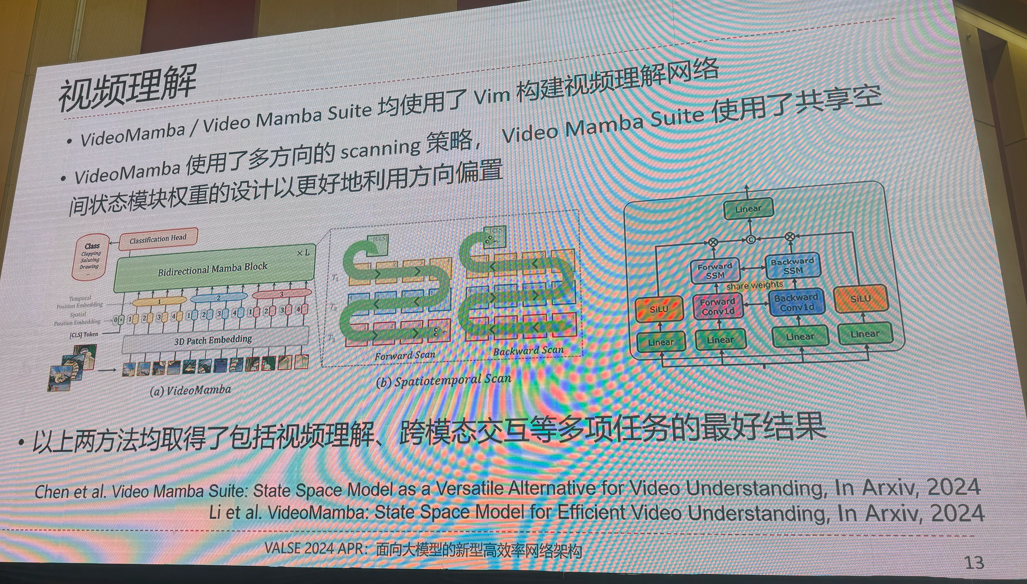



提示:需要完整版ppt请私信
9.视觉基础大模型


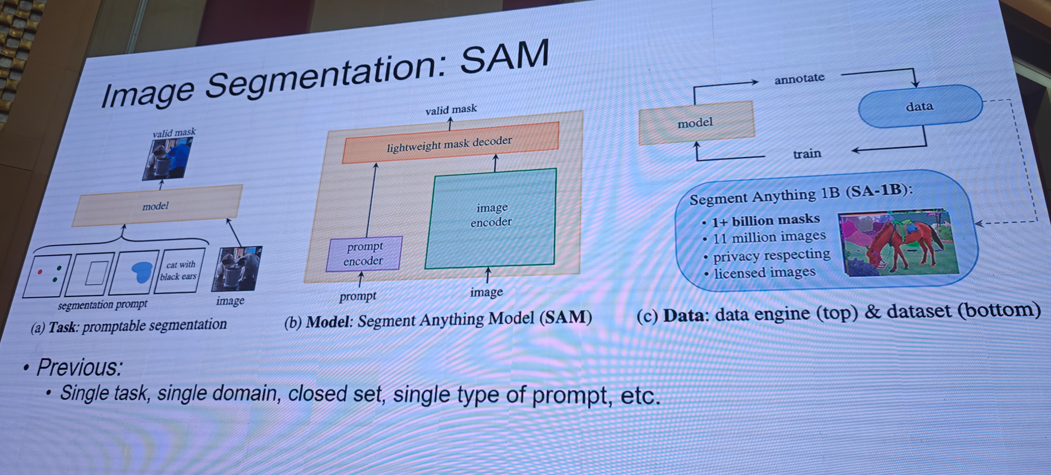





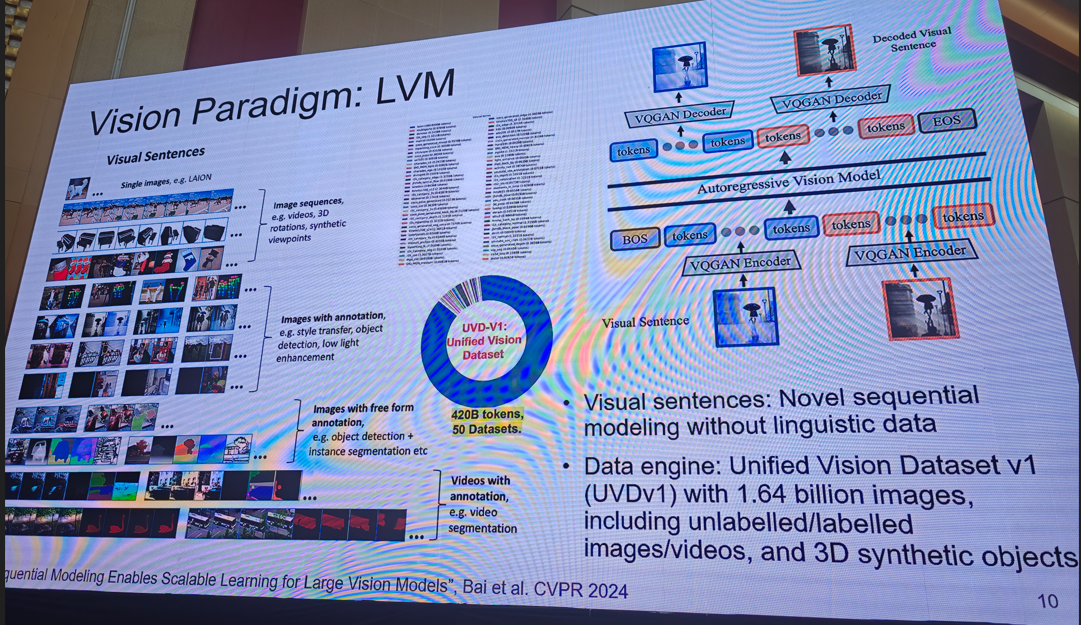

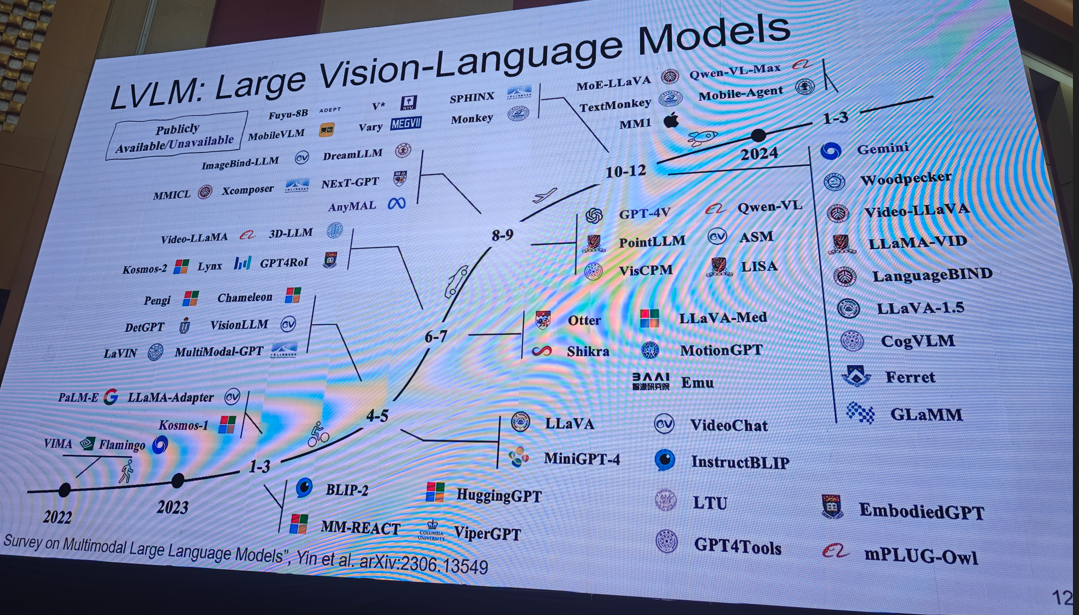
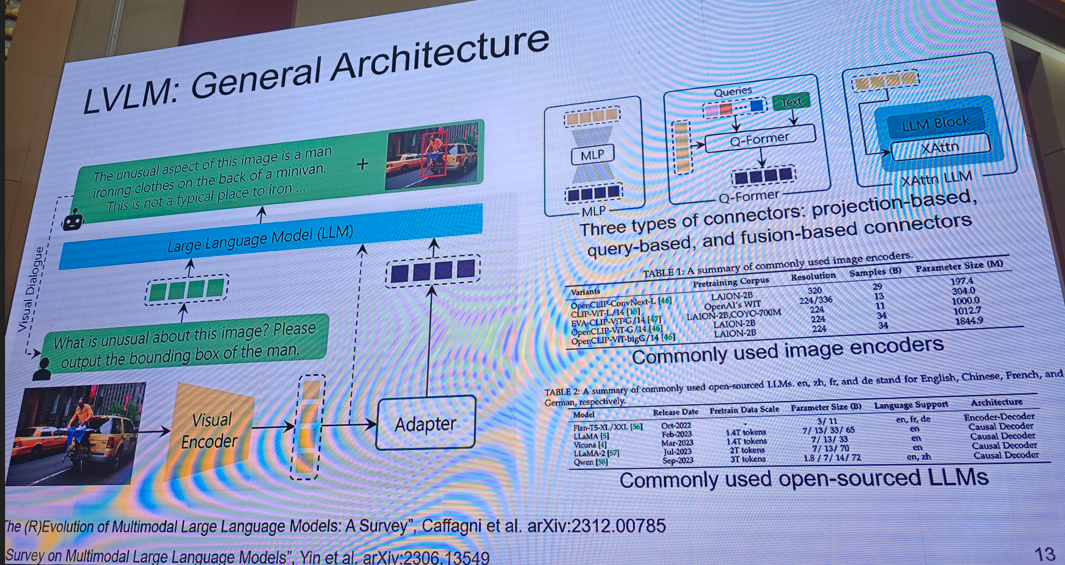

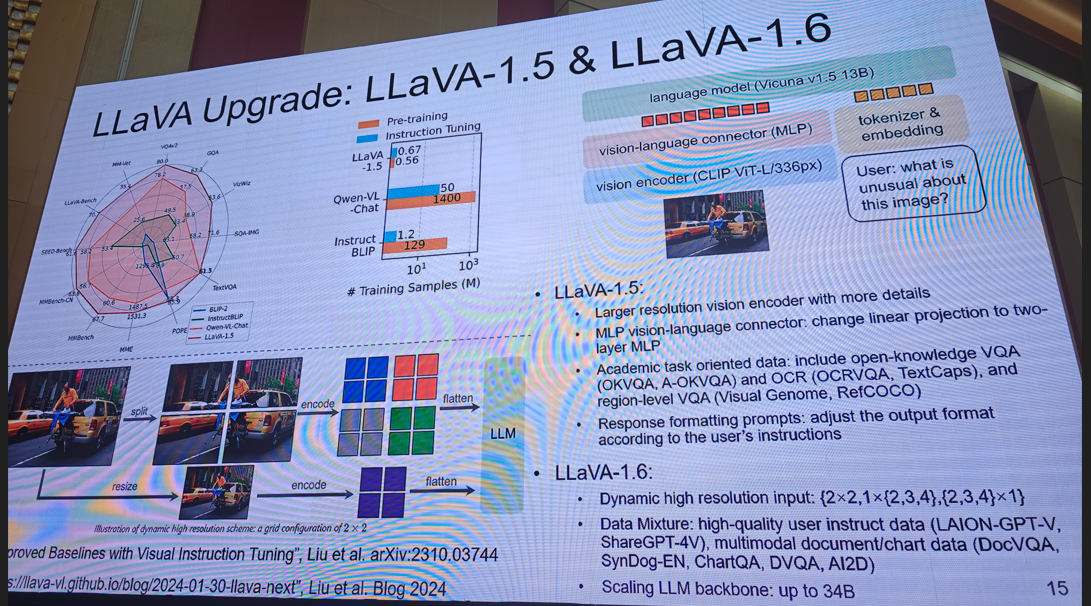
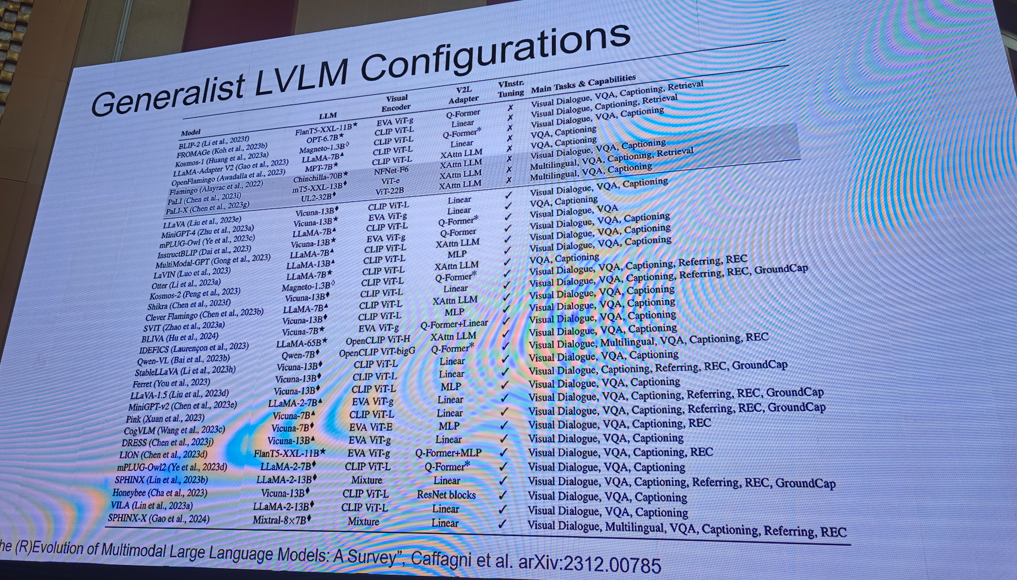


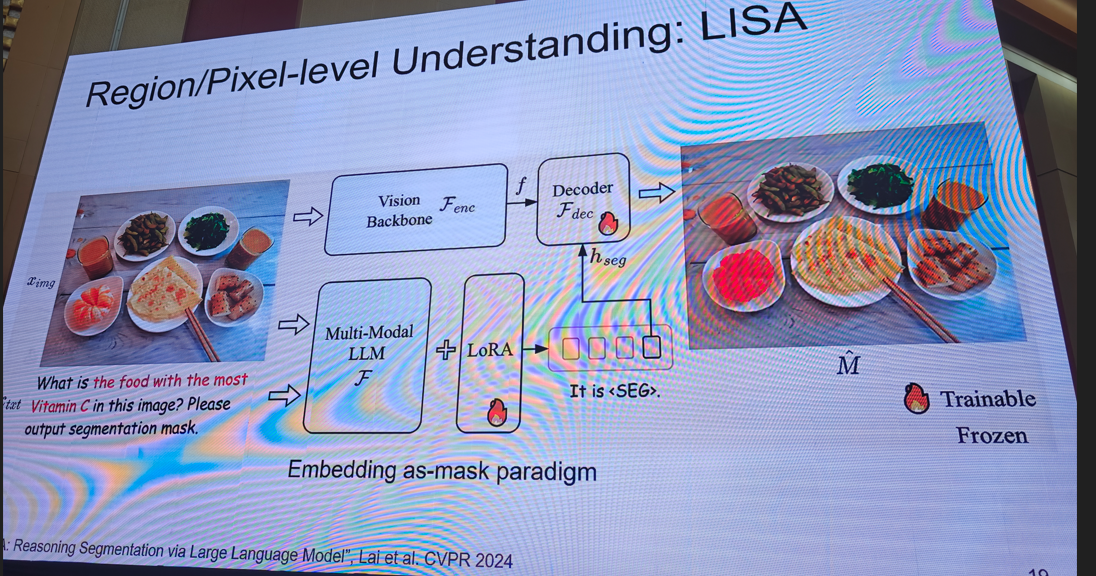

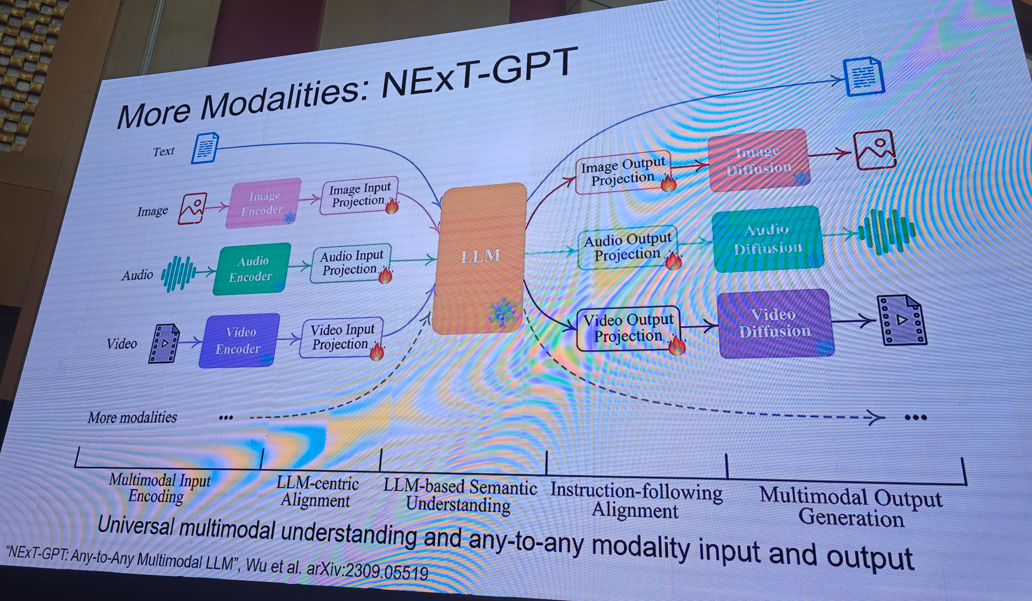
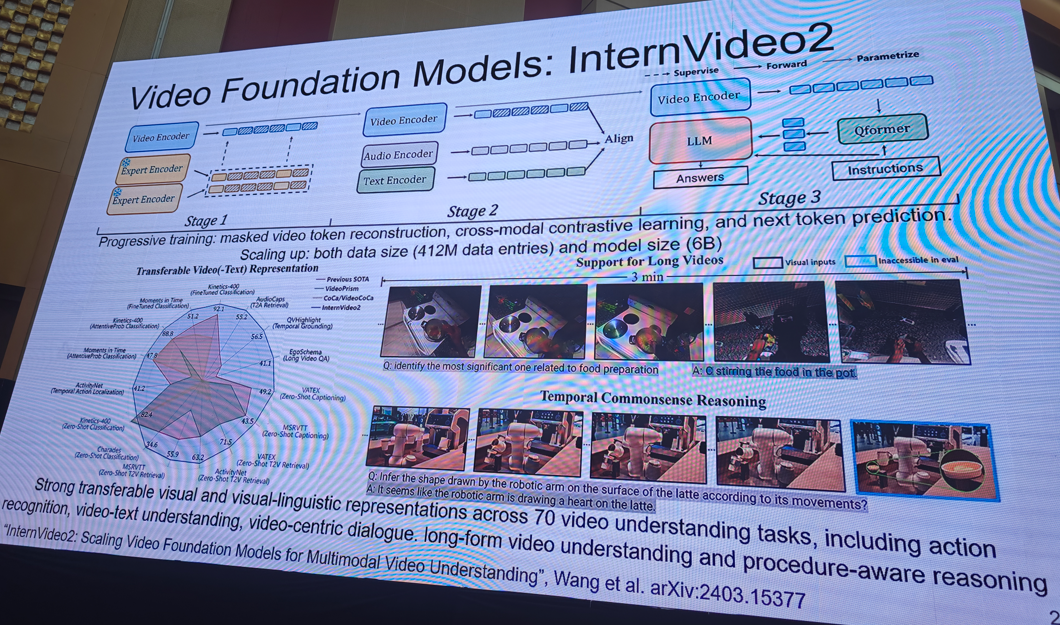






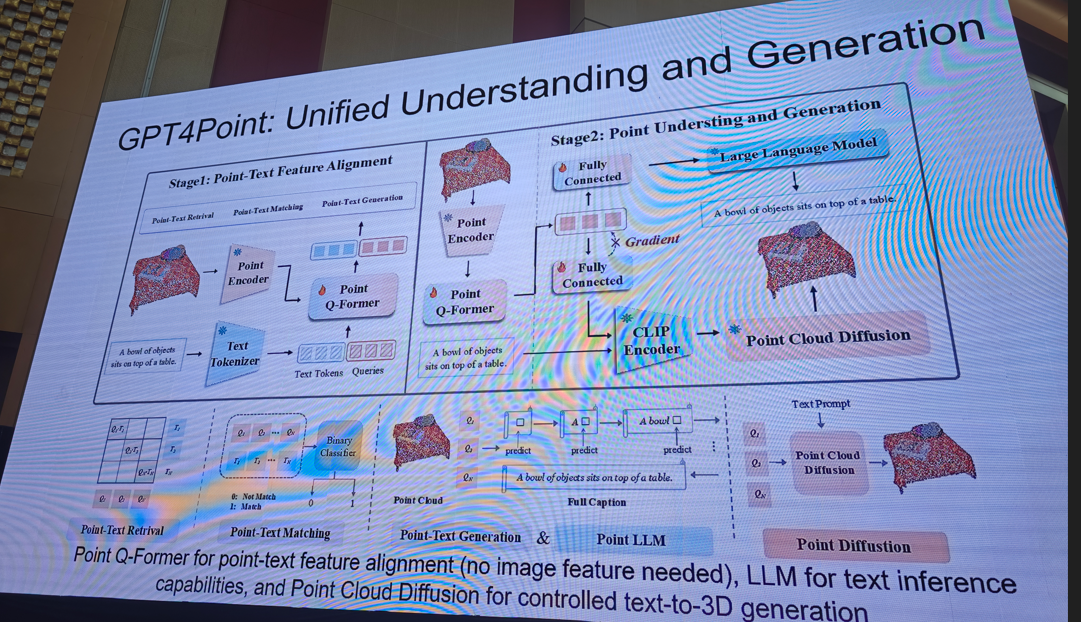
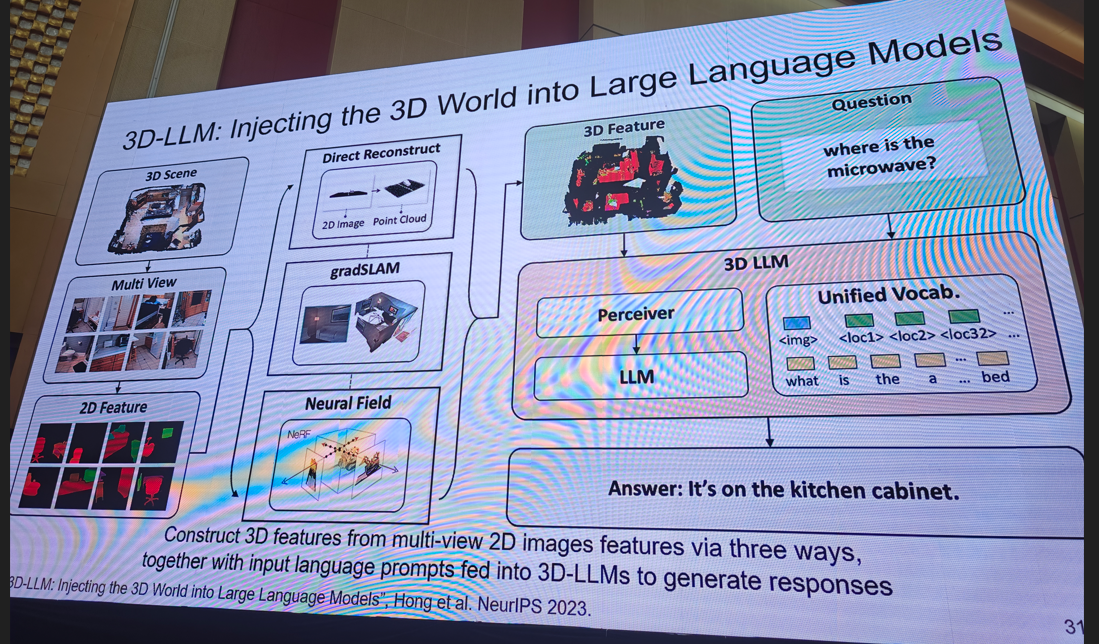
提示:需要完整版ppt请私信







![[leetcode] 68. 文本左右对齐](https://img-blog.csdnimg.cn/direct/a36c1b59f2eb48eebd27dc7ba26116ca.png)