参考资料:活用pandas库
导入基础数据
# 导入库
import pandas as pd
# 读取数据集
df=pd.read_csv(r"..\data\scientists.csv")
df.head()1、DataFrame
DataFrame是Pandas中最常见的对象。可以把它看作python存储电子表格式数据的方式。Series数据结构的许多特征同样存在于DataFrame中。
(1)布尔子集
我们可以借助布尔向量获取DataFrame的子集。
# 使用布尔向量获取部分数据行
print(df[df["Age"]>df["Age"].mean()])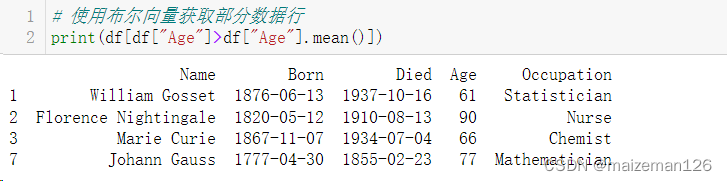
(2)操作自动对齐和向量化(广播)
pandas支持广播,广播源自numpy库。它实际描述的是在类数组对象(比如Seires和DataFrame)之间执行操作的效果。这些行为取决于对象的类型、长度以及与对象关联的标签。
当DataFrame和标量进行运算时,DataFrame中的每个元素会分别和标量进行运算。本例中,df乘2之后,数值会变为原来的两倍,而字符串长度也会翻倍。
# DataFrame和标量相乘
print(df*2)
2、更改Series和DataFrame
(1)添加列
df中Born和Died列的数据类型是object,表明它们是字符串。可以把字符串转换成合适的datetime类型,这样可以执行常见的日期和时间操作了(例如计算两个日期之差或人的年龄)。如果日期有特定格式,可以提供自定义的格式。
print(df["Born"].dtype)
print(df["Died"].dtype)
# 把Born和Died列格式化为datetime
born_datetime=pd.to_datetime(df["Born"],format="%Y-%m-%d")
died_datetime=pd.to_datetime(df["Died"],format="%Y-%m-%d")
# 增加列
df["born_dt"]=born_datetime
df["died_dt"]=died_datetime
print(df.head())
print(df.shape)
print(df.dtypes)
(2)直接更改列
random.shuffle方法可以直接作用于序列,实现序列的“洗牌”。当然sample和reset_sample相结合也能实现“洗牌”的效果。
# Age列更改前
print(df.Age)
# 导入random库,用于产生随机数
import random
# 设置随机种子,产生相同的随机数序列
random.seed(42)
random.shuffle(df["Age"])
print(df.Age)# 使用random_state减少随机化
df["Age"]=df["Age"].sample(len(df.Age),\random_state=24).reset_index(drop=True)下面计算年龄,并将日期的差值转换为年
# Died_dt减去Born_dt得到的是天数
df["age_days_dt"]=df["died_dt"]-df["born_dt"]
print(df)
# 使用astype方法把天数转换为年
df["age_days_dt"]=df["age_days_dt"].astype("timedelta64[Y]")
print(df)(3)删除值
删除列时,可以使用选取列子集的方法选择所有希望删除的列表,也可以使用DataFrame的drop方法指定要删除的列表。
# 展示当前数据中的所有列
print(df.columns)
# 删除Age列
# 设置参数axis=1,删除列
df_dropped=df.drop(["Age"],axis=1)
# 展示删除指定列之后的列
print(df_dropped.columns)

![[单机]成吉思汗3_GM工具_VM虚拟机](https://img-blog.csdnimg.cn/img_convert/ee9be78a18d7d5bc082500017469ba5b.webp?x-oss-process=image/format,png)




![[Kotlin]创建一个私有包并使用](https://img-blog.csdnimg.cn/direct/4e36deef31504124a6bf6d1212d3feef.png)