文章目录
- 表的增删改查
- 一、CRUD
- 1.新增(Create)
- 1.插入多行
- 2.指定列多行插入
- 3.插入datetime类型
- 4.插入当前时间
- 5.插入查询的结果
- 2.查询(Retrieve)
- 1.全列查询 *
- 2.指定列查询
- 3.查询字段为表达式
- 4.指定别名 as
- 5.去重 distinct
- 6.排序 order by
- 7.条件查询 where
- 8.分页查询:limit
- 3.修改(Update)
- 4.删除(Delete)
- 数据库的备份方式:
- 二、数据库约束
- not null
- unique:唯一的
- default:
- primary key 主键
- 如何保证主键唯一?
- foreign 外键
- 表的设计
表的增删改查
一、CRUD
1.新增(Create)
insert into 表名 values(值,值);
insert into student values(1,'zhangsan');
- 此处的值要和列(个数和类型)相匹配
- 如果只插入了一个name,id这一列就是默认值null
1.插入多行
个数和类型要和表结构匹配。
insert into 表名 values(值,值),(值,值),(值,值);
insert into techer values(1,'小明'),(3,'李四'),(4,'王五');
2.指定列多行插入
insert into 表名 (列名,列名...)values(值,值),(值,值),(值,值);
-- 插入两条记录,value_list 数量必须和指定列数量及顺序一致
INSERT INTO student (id, sn, name) VALUES (102, 20001, '曹孟德'),(103, 20002, '孙仲谋');
3.插入datetime类型
使用字符串来表示时间的日期
create table student (id int ,name varchar(20),birthday datetime);
insert into student values(1,'张三','2000-01-11 12:00:00');
4.插入当前时间
now()方法
insert into student values(2,'李四',now());
mysql> select * from student;
+------+------+---------------------+
| id | name | birthday |
+------+------+---------------------+
| 1 | 张三 | 2000-01-11 12:00:00 |
| 2 | 李四 | 2024-05-13 14:03:02 |
+------+------+---------------------+
5.插入查询的结果
- 查询的结果集合,列数和类型要和插入的表匹配。
mysql> select * from student;
+------+------+
| id | name |
+------+------+
| 1 | 张三 |
| 2 | 李四 |
| 3 | 王五 |
+------+------+
3 rows in set (0.00 sec)mysql> select * from student2;
Empty set (0.00 sec)mysql> insert into student2 select *from student;
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0mysql> select * from student2;
+------+------+
| id | name |
+------+------+
| 1 | 张三 |
| 2 | 李四 |
| 3 | 王五 |
+------+------+
2.查询(Retrieve)
创建表并插入数据:
-- 创建考试成绩表
DROP TABLE IF EXISTS exam_result;
CREATE TABLE exam_result (id INT,name VARCHAR(20),chinese DECIMAL(3,1),math DECIMAL(3,1),english DECIMAL(3,1)
);
-- 插入测试数据
INSERT INTO exam_result (id,name, chinese, math, english) VALUES(1,'唐三藏', 67, 98, 56),(2,'孙悟空', 87.5, 78, 77),(3,'猪悟能', 88, 98.5, 90),(4,'曹孟德', 82, 84, 67),(5,'刘玄德', 55.5, 85, 45),(6,'孙权', 70, 73, 78.5),(7,'宋公明', 75, 65, 30);1.全列查询 *
查询表中的所有行和所有列。
- 在生成环境下要谨慎使用。
select * from 表名;
mysql> select * from exam_result;
+------+--------+---------+------+---------+
| id | name | chinese | math | english |
+------+--------+---------+------+---------+
| 1 | 唐三藏 | 67.0 | 98.0 | 56.0 |
| 2 | 孙悟空 | 87.5 | 78.0 | 77.0 |
| 3 | 猪悟能 | 88.0 | 98.5 | 90.0 |
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
| 5 | 刘玄德 | 55.5 | 85.0 | 45.0 |
| 6 | 孙权 | 70.0 | 73.0 | 78.5 |
| 7 | 宋公明 | 75.0 | 65.0 | 30.0 |
+------+--------+---------+------+---------+
客户端发送请求给服务器,查询出来之后,服务器把查询到的结果,在网络中通过响应返回给客户端,并在客户端上打印出来。
如果表中的数据特别多时,可能会产生:
1.读取硬盘时,把硬盘的IO跑满了,此时程序的其他部分想访问硬盘,就会非常慢。
2.操作网络,可能会把网卡的带宽跑满,此时其他客户端想通过网络访问服务器,也会非常慢。
这样的拥堵,就有可能导致客户端无法顺利访问
2.指定列查询
- 按需求进行查询。
select 列名,列名...from 表名;
mysql> select name,math from exam_result;
+--------+------+
| name | math |
+--------+------+
| 唐三藏 | 98.0 |
| 孙悟空 | 78.0 |
| 猪悟能 | 98.5 |
| 曹孟德 | 84.0 |
| 刘玄德 | 85.0 |
| 孙权 | 73.0 |
| 宋公明 | 65.0 |
+--------+------+
3.查询字段为表达式
- 一边查询,一边进行计算(列和列之间的计算)
在查询的时候,写作由列名构成的表达式。把这一列中的所有行都代入到表达式中,参与运算。
- 并不会修改原始数据,展示的是临时表。只针对从数据库服务器查询出来的数据进行运算,不影响原有数据。
查询所有人语文分数-10的值
select name ,chinese-10 from exam_result;
+--------+------------+
| name | chinese-10 |
+--------+------------+
| 唐三藏 | 57.0 |
| 孙悟空 | 77.5 |
| 猪悟能 | 78.0 |
| 曹孟德 | 72.0 |
| 刘玄德 | 45.5 |
| 孙权 | 60.0 |
| 宋公明 | 65.0 |
+--------+------------+
查询每个人的总成绩:
mysql> select name, chinese + english + math from exam_result;
+--------+--------------------------+
| name | chinese + english + math |
+--------+--------------------------+
| 唐三藏 | 221.0 |
| 孙悟空 | 242.5 |
| 猪悟能 | 276.5 |
| 曹孟德 | 233.0 |
| 刘玄德 | 185.5 |
| 孙权 | 221.5 |
| 宋公明 | 170.0 |
+--------+--------------------------+
- SQL在查询的时候,可以进行一些简单的统计操作。
4.指定别名 as
- 查询的时候,给列/表达式/表 指定别名
select 表达式 as 别名 from 表名;select name,chinese+math+english as sum from exam_result;
+--------+-------+
| name | sum |
+--------+-------+
| 唐三藏 | 221.0 |
| 孙悟空 | 242.5 |
| 猪悟能 | 276.5 |
| 曹孟德 | 233.0 |
| 刘玄德 | 185.5 |
| 孙权 | 221.5 |
| 宋公明 | 170.0 |
+--------+-------+
5.去重 distinct
- distinct修饰某个列/多个列
- 值相同的行,只会保留一个
distinct
select distinct math from exam_result;
select distinct name,math from exam_result;
6.排序 order by
- 把行进行排序。
- 仍然是临时数据,把查询到的结果进行排序,不改变原始结构。
要明确排序的规则:1.针对哪个列作为比较规则 2. 是升序还是降序
select 列名 from 表名 order by 列名 asc
-- 升序排序(默认)select 列名 from 表名 order by 列名 desc;
-- 降序排序select name,math from exam_result order by math;
+--------+------+
| name | math |
+--------+------+
| 宋公明 | 65.0 |
| 孙权 | 73.0 |
| 孙悟空 | 78.0 |
| 曹孟德 | 84.0 |
| 刘玄德 | 85.0 |
| 唐三藏 | 98.0 |
| 唐三藏 | 98.0 |
| 猪悟能 | 98.5 |
+--------+------+
mysql> select name,math from exam_result order by math desc;
-- 降序
+--------+------+
| name | math |
+--------+------+
| 猪悟能 | 98.5 |
| 唐三藏 | 98.0 |
| 唐三藏 | 98.0 |
| 刘玄德 | 85.0 |
| 曹孟德 | 84.0 |
| 孙悟空 | 78.0 |
| 孙权 | 73.0 |
| 宋公明 | 65.0 |
+--------+------+
mysql> select name,math from exam_result;
+--------+------+
| name | math |
+--------+------+
| 唐三藏 | 98.0 |
| 孙悟空 | 78.0 |
| 猪悟能 | 98.5 |
| 曹孟德 | 84.0 |
| 刘玄德 | 85.0 |
| 孙权 | 73.0 |
| 宋公明 | 65.0 |
| 唐三藏 | 98.0 |
+--------+------+
如果不加上order by,则不应该依赖上述顺序,是“无序的”
mysql> select name,math,chinese from exam_result order by chinese desc;
+--------+------+---------+
| name | math | chinese |
+--------+------+---------+
| 猪悟能 | 98.5 | 88.0 |
| 孙悟空 | 78.0 | 87.5 |
| 曹孟德 | 84.0 | 82.0 |
| 宋公明 | 65.0 | 75.0 |
| 孙权 | 73.0 | 70.0 |
| 唐三藏 | 98.0 | 67.0 |
| 刘玄德 | 85.0 | 55.5 |
| 唐三藏 | 98.0 | NULL |
+--------+------+---------+
8 rows in set (0.00 sec)mysql> select name,math from exam_result order by chinese desc;
+--------+------+
| name | math |
+--------+------+
| 猪悟能 | 98.5 |
| 孙悟空 | 78.0 |
| 曹孟德 | 84.0 |
| 宋公明 | 65.0 |
| 孙权 | 73.0 |
| 唐三藏 | 98.0 |
| 刘玄德 | 85.0 |
| 唐三藏 | 98.0 |
+--------+------+
即使没有选择语文成绩,仍然可以按照语文成绩进行排序
对表达式运算的结果进行排序:
mysql> select name,chinese+math+english as total from exam_result order by total;
-- 对表达式运算的结果进行排序
+--------+-------+
| name | total |
+--------+-------+
| 唐三藏 | NULL |
| 宋公明 | 170.0 |
| 刘玄德 | 185.5 |
| 唐三藏 | 221.0 |
| 孙权 | 221.5 |
| 曹孟德 | 233.0 |
| 孙悟空 | 242.5 |
| 猪悟能 | 276.5 |
+--------+-------+
指定多个列来排序。order by后面写多个列,使用,分隔开。
mysql> select * from exam_result order by math,chinese;
-- 先按照数学成绩来排序,如果数学成绩相同,则按照语文成绩排序
+------+--------+---------+------+---------+
| id | name | chinese | math | english |
+------+--------+---------+------+---------+
| 7 | 宋公明 | 75.0 | 65.0 | 30.0 |
| 6 | 孙权 | 70.0 | 73.0 | 78.5 |
| 2 | 孙悟空 | 87.5 | 78.0 | 77.0 |
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
| 5 | 刘玄德 | 55.5 | 85.0 | 45.0 |
| 10 | 唐三藏 | NULL | 98.0 | NULL |
| 1 | 唐三藏 | 67.0 | 98.0 | 56.0 |
| 3 | 猪悟能 | 88.0 | 98.5 | 90.0 |
+------+--------+---------+------+---------+
7.条件查询 where
- 会指定具体的条件,按照条件对数据进行筛选。
- where:遍历这个表的每一行记录,把每一行的数据分别代入条件中。如果条件成立,则会把数据放进结果集合中。
select 列名 from 表名 where 条件;
比较运算符:

- sql中没有==,而是使用=来比较相等(null不安全 null=null的结果是null.null参与的运算结果也是null)
- <=> 比较相等 (null安全 null<=>null的结果是true)
- != 、 <> 不等
- between a1 and a2 : 范围[a1,a2] 如果 a1<= value <=a2 ,返回true
- in(option…) :当前值如果是option中任意一种情况,返回true
- like : 模糊匹配 %表示任意多个任意字符;_表示任意一个字符
逻辑运算符:
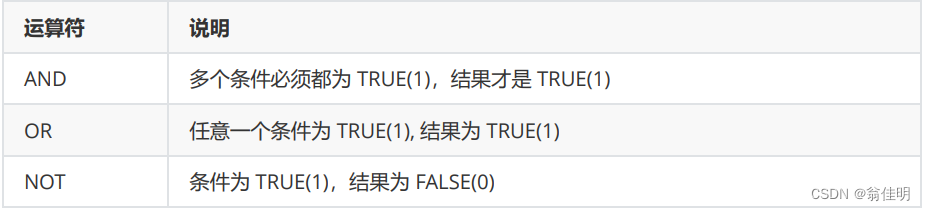
- and 优先级 高于or 。在同时使用时,需要小括号来区别。
-- 基本查询
-- 查询英语不及格的同学及英语成绩 ( < 60 )
mysql> select name,english from exam_result where english<60;
+--------+---------+
| name | english |
+--------+---------+
| 唐三藏 | 56.0 |
| 刘玄德 | 45.0 |
| 宋公明 | 30.0 |
+--------+---------+-- 查询语文成绩好于英语成绩的同学select name,chinese,english from exam_result where chinese>english;
+--------+---------+---------+
| name | chinese | english |
+--------+---------+---------+
| 唐三藏 | 67.0 | 56.0 |
| 孙悟空 | 87.5 | 77.0 |
| 曹孟德 | 82.0 | 67.0 |
| 刘玄德 | 55.5 | 45.0 |
| 宋公明 | 75.0 | 30.0 |
+--------+---------+---------+-- 查询总分在 200 分以下的同学
select name,math+chinese+english as total from exam_result where chinese+math+english<200;
-- where条件可以使用表达式,但是不能使用别名
+--------+-------+
| name | total |
+--------+-------+
| 刘玄德 | 185.5 |
| 宋公明 | 170.0 |
+--------+-------+
where条件可以使用表达式,但是不能使用别名
select条件查询执行的顺序:
1.遍历表中的每一个记录
2.把当前记录的值,代入条件,根据条件进行筛选
3.如果这个记录成立,就要保留,进行列上的表达式计算
4.如果有order by,会在所有行都被获取到之后(表达式也算完了)再针对所有的结果进行排序。
第三步定于的别名,where是第二部执行的
and or
-- 查询语文成绩大于80分,且英语成绩大于80分的同学
mysql> select name,english,chinese from exam_result where chinese>80 and english >80;
+--------+---------+---------+
| name | english | chinese |
+--------+---------+---------+
| 猪悟能 | 90.0 | 88.0 |
+--------+---------+---------+-- 查询语文成绩大于80分,或英语成绩大于80分的同学
mysql> select name,english,chinese from exam_result where chinese>80 or english >80;
+--------+---------+---------+
| name | english | chinese |
+--------+---------+---------+
| 孙悟空 | 77.0 | 87.5 |
| 猪悟能 | 90.0 | 88.0 |
| 曹孟德 | 67.0 | 82.0 |
+--------+---------+---------+-- 观察AND 和 OR 的优先级:
mysql> SELECT * FROM exam_result WHERE chinese > 80 or math>70 and english > 70;
+------+--------+---------+------+---------+
| id | name | chinese | math | english |
+------+--------+---------+------+---------+
| 2 | 孙悟空 | 87.5 | 78.0 | 77.0 |
| 3 | 猪悟能 | 88.0 | 98.5 | 90.0 |
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
| 6 | 孙权 | 70.0 | 73.0 | 78.5 |
+------+--------+---------+------+---------+
4 rows in set (0.00 sec)mysql> SELECT * FROM exam_result WHERE (chinese > 80 or math>70) and english > 70;
+------+--------+---------+------+---------+
| id | name | chinese | math | english |
+------+--------+---------+------+---------+
| 2 | 孙悟空 | 87.5 | 78.0 | 77.0 |
| 3 | 猪悟能 | 88.0 | 98.5 | 90.0 |
| 6 | 孙权 | 70.0 | 73.0 | 78.5 |
+------+--------+---------+------+---------+
between and
-- 查询语文成绩在 [80, 90] 分的同学及语文成绩
mysql> select name,chinese from exam_result where chinese between 80 and 90;
+--------+---------+
| name | chinese |
+--------+---------+
| 孙悟空 | 87.5 |
| 猪悟能 | 88.0 |
| 曹孟德 | 82.0 |
+--------+---------+
-- 使用 AND 也可以实现
mysql> select name,chinese from exam_result where chinese >=80 and chinese <=90;
+--------+---------+
| name | chinese |
+--------+---------+
| 孙悟空 | 87.5 |
| 猪悟能 | 88.0 |
| 曹孟德 | 82.0 |
+--------+---------+
in
-- 查询数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩
mysql> select name,math from exam_result where math in(58,59,98,99);
+--------+------+
| name | math |
+--------+------+
| 唐三藏 | 98.0 |
| 唐三藏 | 98.0 |
+--------+------+
-- 使用 OR 也可以实现
mysql> SELECT name, math FROM exam_result WHERE math = 58 OR math = 59 OR math-> = 98 OR math = 99;
+--------+------+
| name | math |
+--------+------+
| 唐三藏 | 98.0 |
| 唐三藏 | 98.0 |
+--------+------+
模糊查询:like
-- % 匹配任意多个(包括 0 个)字符
mysql> select name from exam_result where name like '孙%';
+--------+
| name |
+--------+
| 孙悟空 |
| 孙权 |
+--------+-- _ 匹配严格的一个任意字符
mysql> select name from exam_result where name like '孙_';
+------+
| name |
+------+
| 孙权 |
+------+
mysql> select name from exam_result where name like '孙__';
+--------+
| name |
+--------+
| 孙悟空 |
+--------+
NULL 的查询:IS [NOT] NULL
select * from exam_result where chinese = null;
-- =的话,查询到的还是空
Empty set (0.00 sec)mysql> select * from exam_result where chinese <=> null;
+------+--------+---------+------+---------+
| id | name | chinese | math | english |
+------+--------+---------+------+---------+
| 10 | 唐三藏 | NULL | 98.0 | NULL |
+------+--------+---------+------+---------+mysql> select * from exam_result where chinese <=> english;
+------+--------+---------+------+---------+
| id | name | chinese | math | english |
+------+--------+---------+------+---------+
| 10 | 唐三藏 | NULL | 98.0 | NULL |
+------+--------+---------+------+---------+
1 row in set (0.00 sec)mysql> select * from exam_result where chinese is null;
-- is null只能顾及到一个列
+------+--------+---------+------+---------+
| id | name | chinese | math | english |
+------+--------+---------+------+---------+
| 10 | 唐三藏 | NULL | 98.0 | NULL |
+------+--------+---------+------+---------+
1 row in set (0.00 sec)
8.分页查询:limit
-
使用select * 这种查询方式,比较危险,要保障一次查询的数量有限,避免堵塞。
-
limit可以限制这次查询最多能查出多少个结果
mysql> select * from exam_result limit 3;
mysql> select * from exam_result limit 3 offset 0;
-- 显示前三条记录
-- limit 表示这次查询查几条记录
-- offset:偏移量,也就是一个下标,从0开始
+------+--------+---------+------+---------+
| id | name | chinese | math | english |
+------+--------+---------+------+---------+
| 1 | 唐三藏 | 67.0 | 98.0 | 56.0 |
| 2 | 孙悟空 | 87.5 | 78.0 | 77.0 |
| 3 | 猪悟能 | 88.0 | 98.5 | 90.0 |
+------+--------+---------+------+---------+mysql> select * from exam_result limit 3 offset 3;
+------+--------+---------+------+---------+
| id | name | chinese | math | english |
+------+--------+---------+------+---------+
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
| 5 | 刘玄德 | 55.5 | 85.0 | 45.0 |
| 6 | 孙权 | 70.0 | 73.0 | 78.5 |
+------+--------+---------+------+---------+mysql> select * from exam_result limit 3 offset 6;
+------+--------+---------+------+---------+
| id | name | chinese | math | english |
+------+--------+---------+------+---------+
| 7 | 宋公明 | 75.0 | 65.0 | 30.0 |
| 10 | 唐三藏 | NULL | 98.0 | NULL |
+------+--------+---------+------+---------+
3.修改(Update)
update 表名 set 列名 = 值 where 条件;-- 将孙悟空同学的数学成绩变更为 80 分
mysql> update exam_result set math = 80 where name = '孙悟空';-- 将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
mysql> update exam_result set math = 60,chinese = 70 where name = '曹孟德';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0-- 将总成绩倒数前三的 3 位同学的数学成绩减上 30 分
update exam_result set math = math - 30 order by math+chinese+english limit 3;4.删除(Delete)
delete from 表名 where 条件/ order by / limit;
- 把符合条件的行,从表中删除掉。
-- 删除孙悟空同学的考试成绩delete from exam_result where name = '孙悟空';-- 删除整张表数据
delete from exam_result ;-- (清空整张表->空表)
drop table exam_result; -- (删除表信息,表没了)
-- 准备测试表
DROP TABLE IF EXISTS for_delete;
CREATE TABLE for_delete (id INT,name VARCHAR(20)
);
-- 插入测试数据
INSERT INTO for_delete (name) VALUES ('A'), ('B'), ('C');
-- 删除整表数据
DELETE FROM for_delete;数据库的备份方式:
1.数据库的数据最终是以文件(二进制)的形式,存储在硬盘上。将文件之间拷贝到新的机器上(全量备份)
2.mysqldump工具,将mysql中的数据导出成一系列insert语句,再把这些insert 语句放在新的mysql上执行。(全量&增量)
3.mysql的binlog功能,把mysql的各种操作,都通过日志记录下来,借住binlog,让另一个数据库按照binlog的内容执行(增量备份/实时备份)
二、数据库约束
有的时候,数据库中的数据,是有一定要求的。有些数据认为是合法数据,有些是非法的数据。数据库会自动的对数据的合法性进行校验检查。目的就是为了保证数据库中避免被插入/修改一些非法的数据。

- not null :表示某列不能填空值。
- unique : 表示某列的某行必须有唯一的值,不能重复。
- default : 设置默认值。
- primary key 主键 : 唯一标识(not null + unique)
- foreign key 外键: 保证一个表中的数据匹配另一个表中的值的参照完整性。
not null
mysql> create table student(id int not null,name varchar(20));
Query OK, 0 rows affected (0.01 sec)mysql> insert into student values(null,null);
ERROR 1048 (23000): Column 'id' cannot be nullmysql> update student set id = null where name = '张三';
ERROR 1048 (23000): Column 'id' cannot be null
unique:唯一的
- unique约束,会让后续插入数据/修改数据的时候,都先触发一次查询操作。通过查询来确定当前记录是否已经存在
- 引入约束后,执行效率就会受到影响,可能会降低很多。
mysql> create table student(id int unique,name varchar(20));
Query OK, 0 rows affected (0.01 sec)mysql> insert into student values(1,'张三');
Query OK, 1 row affected (0.00 sec)mysql> insert into student values(1,'张三');
ERROR 1062 (23000): Duplicate entry '1' for key 'id'-- 重复 -- 条目
default:
- 描述某一列的默认值. 默认的默认值是null,可以通过default约束来修改默认值。
mysql> desc student;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | UNI | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+mysql> create table student(id int ,name varchar(20) default '未命名');
Query OK, 0 rows affected (0.01 sec)mysql> desc student;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(20) | YES | | 未命名 | |
+-------+-------------+------+-----+---------+-------+
alter table 可以修改表的结构,进而修改约束
primary key 主键
-
一行记录的身份标识
-
一张表只能有一个主键。
-
主键不一定只有一个列,可以用多个列共同构成一个主键(联合主键)
-
带有主键的表,每次插入/修改数据,也会先进行查询的操作。
mysql会把带有unique和primary key的列自动生成索引,从而加快查询的速度。
mysql> create table student(id int primary key,name varchar(20));
Query OK, 0 rows affected (0.01 sec)mysql> desc student;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
如何保证主键唯一?
mysql提供了一种“自增主键”的机制。主键经常会使用int/bigint来进行设置。程序员在插入数据的时候,不必手动指定主键的值,由数据库服务器自动分配一个主键。从1开始,依次递增的分配主键的值。
mysql> create table student(id int primary key auto_increment,name varchar(20));
Query OK, 0 rows affected (0.00 sec)mysql> desc student;
+-------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+----------------+mysql> insert into student values(null,'张三');
-- 不设置id,让自增主键自行分配
Query OK, 1 row affected (0.01 sec)mysql> insert into student values(null,'张三');
Query OK, 1 row affected (0.01 sec)mysql> select * from student;
+----+------+
| id | name |
+----+------+
| 1 | 张三 |
| 2 | 张三 |
+----+------+
mysql> insert into student values(10,'李四');
Query OK, 1 row affected (0.01 sec)
-- 从最大值开始,后续自动分配
-- 相当于使用了一个变量,保存了表的最大id值,后续根据最大id来进行自增分配
mysql> insert into student values(null,'王五');
Query OK, 1 row affected (0.01 sec)mysql> select * from student;
+----+------+
| id | name |
+----+------+
| 1 | 张三 |
| 2 | 张三 |
| 3 | 李四 |
| 10 | 李四 |
| 11 | 王五 |
+----+------+
这里的自动分配具有局限性,如果是单个的mysql服务器,是没有问题的。但是如果是一个分布式系统,有多个mysql服务器构成的集群,就不能依靠自增主键了。
要保证在分布式的musql服务器中,其中一个主机存储的id,具有唯一性。往往要进行一定的算法处理。可以运用时间戳+机房编号/主机编号+随机因子的字符串拼贴,来得到唯一的id.
foreign 外键
-
描述了两个表之间的关联关系
class(classid ,name)2101 计科2102 计科2103 计科 student(id ,name,classid)01 张三 210102 李四 210205 王五 2107(不在class表中)class表中的数据,约束了student表中的数据。
create table student(id int primary key,name varchar(20),classid int,foreign key(classid) references class(classid));把class表称为父表(约束别人),把student表称为子表(被别人约束)
mysql> create table class(classid int primary key,name varchar(20));
Query OK, 0 rows affected (0.01 sec)mysql> insert into class values(2101,'计科1班'),(2102,'计科2班'),(2103,'计科3班');
create table student(id int primary key,name varchar(20),classid int,foreign key(classid) references class(classid));mysql> insert into student values (1,'张三',2101);
Query OK, 1 row affected (0.01 sec)mysql> insert into student values (2,'李四',2109);
ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`day5_14`.`student`, CONSTRAINT `student_ibfk_1` FOREIGN KEY (`classid`) REFERENCES `class` (`classid`))
-
references 引用,表示这一列的数据出自另一个表的那一列
-
如果针对父表进行修改/删除 操作,如果当前要操作的值已经被子表引用了,就会操作失败。
-
外键要始终保持,子表的数据在对应的父表的列中始终存在。
在操作子表时,要保证在父表的范围内。操作父表时,要保证没有被子表引用。同理,如果父表已经被子表引用,就无法进行父表的删除。只能先删子表,再删父表。
- 指定外键约束的时候,要求父表中被该关联的这一列,必须是主键或者是unique。
表的设计
根据实际的场景需求,明确当前要创建几个表,每个表的内容和表之间的联系
1.梳理清楚 需求中的“实体”(对象)
每个实体都需要安排一个表,表的列对应到实体的各个属性。
2.确定好实体之间的“关系”
1对1、1对多、多对多
点击移步博客主页,欢迎光临~