目录
前言
一、认识URL
二、认识HTTP样例
三、HTTP的报头内容
1.url
2. Content-Type
3.Method 方法
1.GET方法
2.POST方法
4、状态码
前言
我们知道,协议就是一种约定,客户端与服务端统一的用这种约定进行传输数据。我们也进行了自定义协议的序列化与反序列化,了解到了协议是如何进行约定的。今天我们来学习一下被广泛运用的应用层协议——HTTP(超文本传输协议)。
一、认识URL
在我们访问别人的网站时,通常会输入网址或者点击别人的链接(跳转到该网址)进行访问,我们平时说的网址也就是url。

比如说百度的链接如下,https为他的协议方案名,比http多了加密,www.baidu.com为他的服务器地址(也是域名),会通过DNS域名解析将该域名转化为一个IP地址,"/"为访问他的web根目录。
https://www.baidu.com/

再比如说我们百度搜索caixukun,就会访问到"/s目录","?"后面就可以带参数了,"wd=caixunkun"为我们的搜索内容,"&"后面又跟着很多参数
https://www.baidu.com/s?wd=caixukun&rsv_spt=1&rsv_iqid=0xa125eeac0124f4d8&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&rqlang=cn&tn=baiduhome_pg&rsv_enter=1&rsv_dl=tb&oq=%25E8%2594%25A1%25E5%25BE%2590%25E5%259D%25A4&rsv_btype=t&inputT=1356&rsv_t=30ce7B8KPAgBA5MzP%2Fj0%2Bouk7Tznt866T6e0B%2Fv5EUHIzUkxc34g%2BwyPnOzHtYLvNupJ&rsv_pq=b89a996d00b45a5c&rsv_sug3=38&rsv_sug1=22&rsv_sug7=100&rsv_sug2=0&rsv_sug4=1356&rsv_sug=1
因此,我们平时访问网站,本质上就是在进行进程间通信,只不是是跨网络的,通过域名转化为IP地址,端口号是协议默认的。
二、认识HTTP样例
如下是一个http请求样例,有 请求行、请求报头、空行、请求参数(请求参数可以为空)

GET 为http请求方法 / 为请求资源的目录(这是web更目录) HTTP/1.1是http协议版本。
请求报头中的内容我们暂时不管,等第三章来看,这里只是了解一下http的样子。

对于http协议,请求报头是按 "\r\n" 做结尾的,因此可以通过读取到空行的"\r\n"表示读完了请求报头。而正文(请求参数)的读取完毕,是在请求报头中有一个参数Content_Length来表示正文的长度,知道了长度之后,再拿着这个长度去读正文,读到了这个长度表示正文读取完毕。
反序列化也是按照"\r\n"来进行截取,至此服务器就能清楚我们的请求,同时给我们的请求做出响应。
其中http的响应字段也是类似的,其中浏览器会将响应正文做解释,就变成我们看到的网页了。
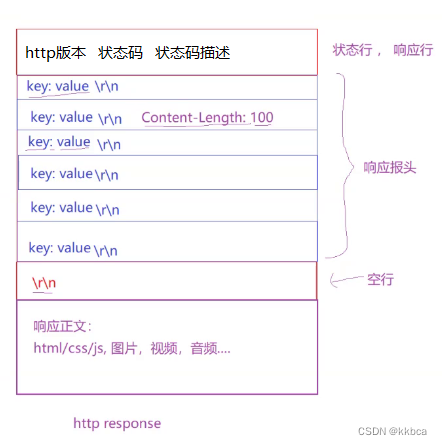
如下是http的响应字段

三、HTTP的报头内容
1.url
前面我们的请求行,中间的内容为目录,默认访问的是web根目录,代表默认访问该网站的首页
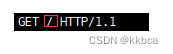
如果我们指定访问某个文件夹下某个资源,那么请求行中url内容也会随之改变,参数也可以这样传递
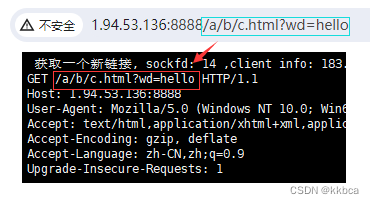
实际上我们可以通过http协议,截取出你的url是什么,如果是根目录,那么就拼接首页并给你首页网站。
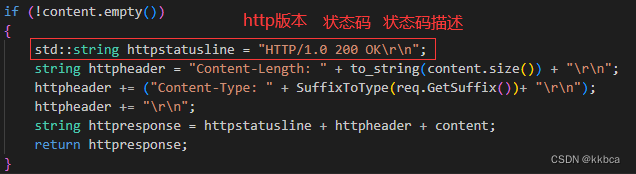
如果是其他目录,只要我有该目录下的该文件,我就给你,如果没有,我就404 not fount。代码逻辑如下。
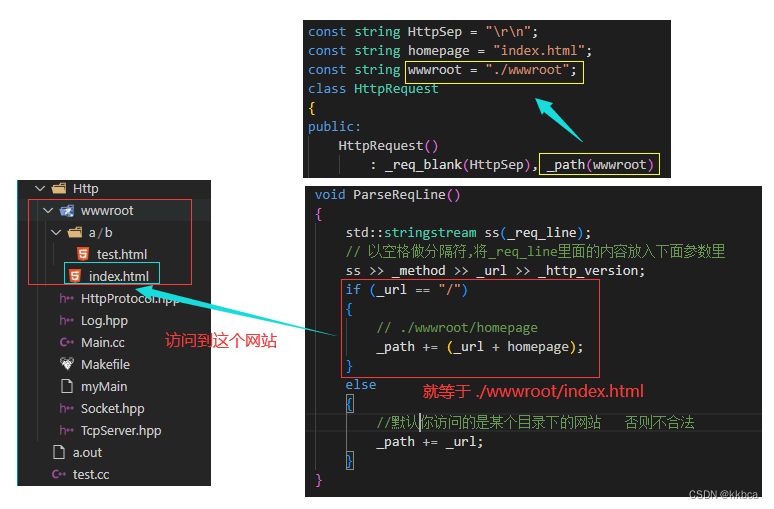

2. Content-Type
Content-Type 用于指示响应中包含的数据的类型,如果你的html里面有图片、视频等链接,http进行解析正文的时候发现有链接,那么他会再次发送请求该链接。如下

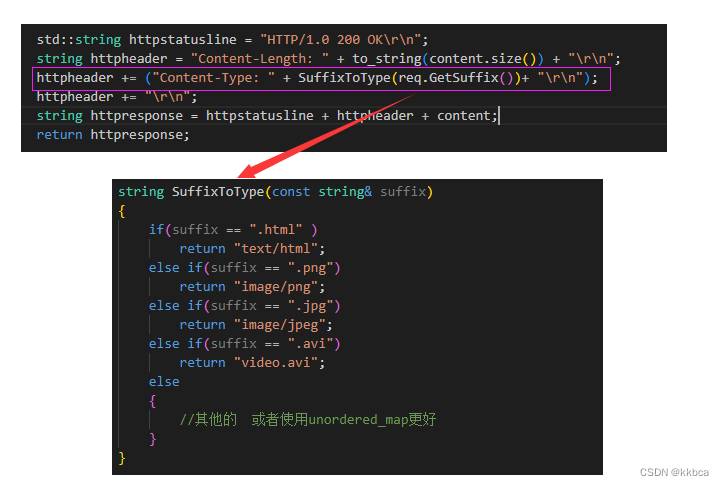
浏览器虽然足够智能,但是仍需要我们指定类型让浏览器进行渲染,因此我们需要给响应字段添加Content-Type,让浏览器知道如何渲染。
Content-Type 扩展名对照表
因此我们需要截取出请求报头中的url,分析url的后缀是什么,根据后缀进行返回内容
3.Method 方法
请求行的第一个参数就Method方法,最重要、也是最常见的是 GET 和 POST 。
我们通常使用GET 请求去获取资源,比如网页、图片等。
POST请求通常用于提交表单数据、上传文件等操作。
1.GET方法
GET方法请求参数通常以 URL 的查询字符串的形式附加在 URL 后面,html中如果不写method,默认方法也是“GET”

这样就可以通过截取的方式把用户输入的数据给到后台。后台根据数据再给你提供服务。
2.POST方法
post方法会将表单的请求参数放在正文部分,私密性会更强一些。
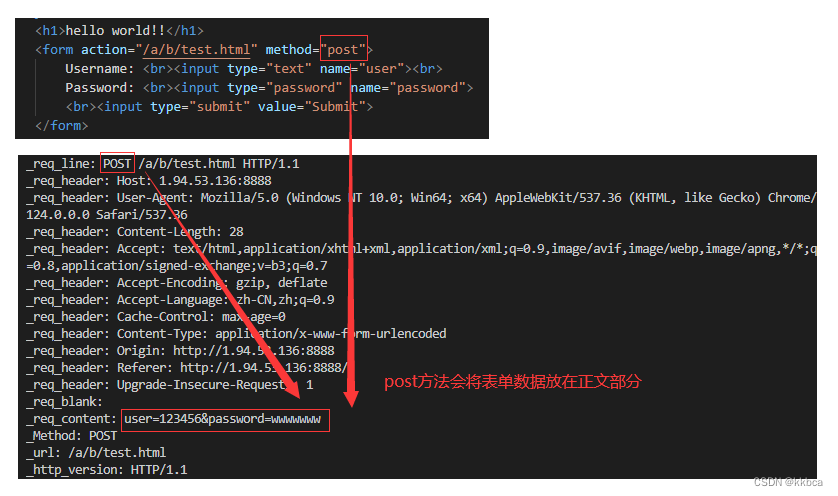
GET与POST的区别
- GET是在url传递参数,POST是在请求正文传参
- GET在url传参字节个数有限,POST参数字节没有限制
- GET请求通常用于请求服务器发送某个资源,POST请求通常用于向服务器提交数据
- GET私密性比POST差(私密性不等于安全性,GET和POST都不安全,都是明文传输,https才更安全)
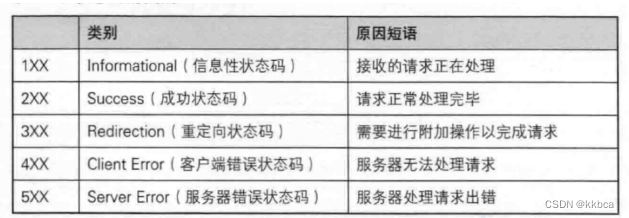
4、状态码
在http的响应行中,有状态码这个东西,访问成功状态码是通常200。
如果你请求的文件不存在,状态码通常是404 ,描述为not fount

状态码并不是固定的,而是大多是大家默认遵守的规矩,你可以逾矩,但是会让其他程序员看不懂。 重定向是例外,不能乱写。
那我们就可以去进行各种判断,看是什么问题,然后给你返回对应的状态码与状态码描述。其他的我们都能理解,这个重定向状态码是什么情况呢?
HTTP报头中还有一个Location字段,客户端会根据该字段中指定的 URL 自动进行重定向,如下代码,当你的报头中状态码为307,并且有Location字段(缺一不可),其他内容也就不重要了,访问到这个网站即会重定向到你所设置的网站内。


其中307代表临时重定向,请求的资源暂时移动到了新位置,但所有后续的请求应该继续使用原始的 URL。
如果状态码是301,表示请求的资源已永久移动到新位置,且所有后续的请求应该使用新的 URL。这意味着浏览器在收到 301 响应后,应该自动更新其缓存的链接,并使用新的 URL 进行所有后续的请求。
5.cookie和session
- http的请求是无连接和无状态的。
- 无连接代表像服务器发送请求,服务器对你的请求做出响应,然后就结束了,后续你要再次跳转或者做其他操作又会发送新的请求。
- 无状态是说服务器根本就不知道你请求了多少次,你是一直在做刷新操作,还是只访问了一次,我不知道耶不关心,我只知道根据你的请求做出响应。
- 但是我们实际使用的时候,比如抖音登录成功后关闭抖音,再次访问,发现他还是记得我,我仍处于登录状态,这是cookie在起作用。
当我们将账号和密码输入给服务器时,服务器会将你的账号和密码与数据库做对比,如果发现有该用户,就会response响应用户登录成功了,同时该响应里面有Set-Cookie字段,该字段的内容就是你的账号和密码。
浏览器发现response响应里面有该字段,就会利用自动保存cookie字段,当用户再次访问该服务器时,浏览器会自动将cookie里面的内容取出,并帮我们在请求报头添加Cookie字段,该字段的内容就是你之前输入的账号和密码,这样我们第一次登录后,后面都不需要再次登录。

同时后续访问时,request请求报头就自动添加上了Cookie

但是如果仅仅只有cookie,有坏人想截取我的http请求可太简单了,直接获取到我的用户名和密码,拿着我的账号去干坏事,这样肯定不好。
因此服务器在我登录之后,会把我输入的数据保存到session中,同时通过键值对的唯一性,响应回来的Set-cookie为这个session的id值,这样客户端就收到一个Set-cookie:sessionid。以后就不用在明文传输,而是依靠这个sessionid进行验证用户了。
当然这样我们能保证自己的账号不会被盗,但是别人依然可以利用sessionid去干坏事,比如把账号里面的记录删一删等等,因此还是得需要服务器通过判断客户端的ip地址是否一致、或者sessionid持续时长等来更好的保护客户端(使用者)。
重要报头字段
- Content-Type: 数据类型(text/html等)
- Content-Length: Body的长度
- Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
- User-Agent: 声明用户的操作系统和浏览器版本信息;
- referer: 当前页面是从哪个页面跳转过来的;
- location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问;
- Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能
目前已经能通过http进行数据传输了,但是黑客仍然有各种办法截取用户的信息,因此需要对http进行加密,提出了https。https我们下一章见!!

![char x[]---char*---string---sizeof](https://img-blog.csdnimg.cn/direct/58cc3f260525498d9a0704c0513ffdac.png)