目录
1、集合函数
1.1、size:集合中元素的个数
1.2、map:创建map集合
1.3、map_keys: 返回map中的key
1.4、map_values: 返回map中的value
1.5、array 声明array集合
1.6、array_contains: 判断array中是否包含某个元素
1.7、sort_array:将array中的元素排序
1.8、struct声明struct中的各属性
1.9、named_struct声明struct的属性和值
2、高级聚合函数
2.1、collect_list 收集并形成list集合,结果不去重
2.2、collect_set 收集并形成set集合,结果去重
3、炸裂函数
3.1、UDTF函数
3.2、案例演示
3.3、需求
4、窗口函数
4.1、概述
编辑
4.2、常用的窗口函数
4.3、案例演示
1、集合函数
1.1、size:集合中元素的个数
hive> select size(friends) from test; -- 每一行数据中的friends集合里的个数
1.2、map:创建map集合
语法:map (key1, value1, key2, value2, …)
说明:根据输入的key和value对构建map类型
案例实操:
hive> select map('xiaohai',1,'dahai',2);
输出:
hive> {"xiaohai":1,"dahai":2}
1.3、map_keys: 返回map中的key

1.4、map_values: 返回map中的value

1.5、array 声明array集合

1.6、array_contains: 判断array中是否包含某个元素

1.7、sort_array:将array中的元素排序

1.8、struct声明struct中的各属性

1.9、named_struct声明struct的属性和值

2、高级聚合函数
2.1、collect_list 收集并形成list集合,结果不去重

2.2、collect_set 收集并形成set集合,结果去重

3、炸裂函数
3.1、UDTF函数
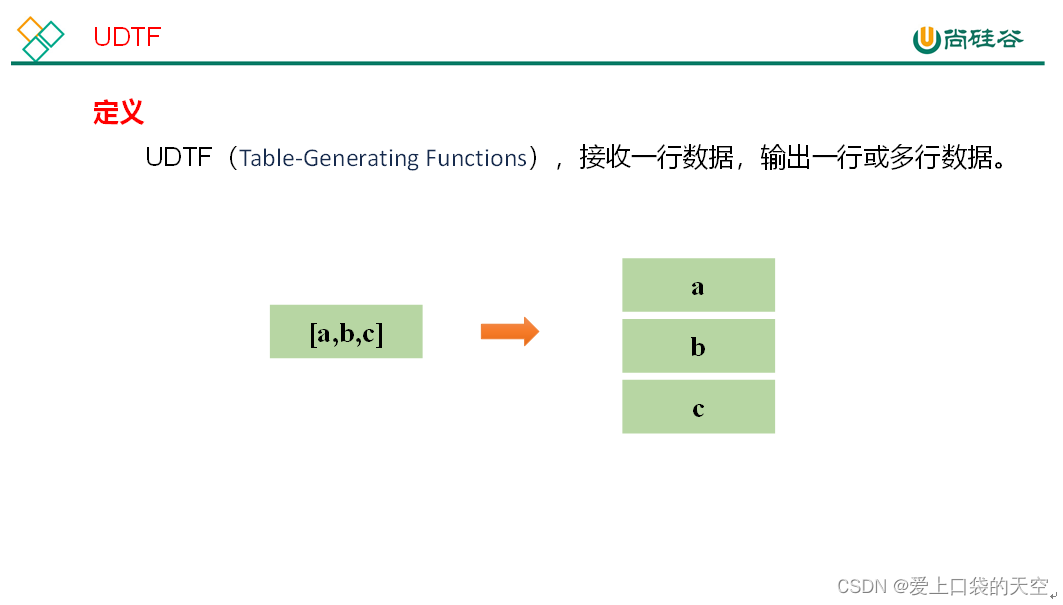
3.2、案例演示
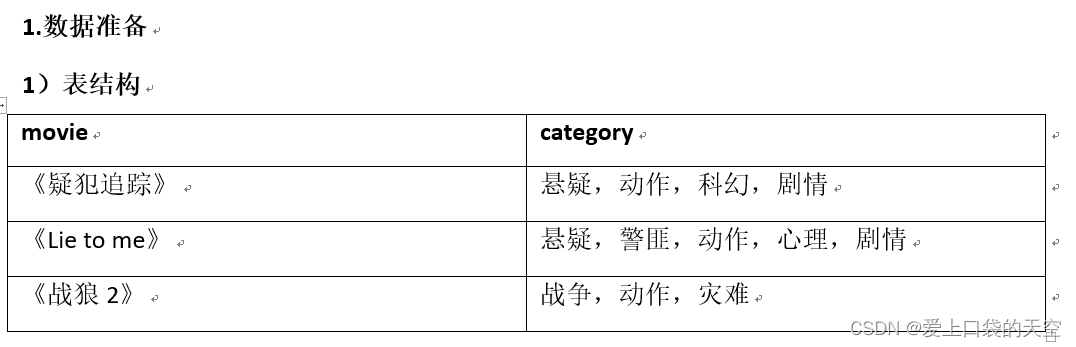


3.3、需求
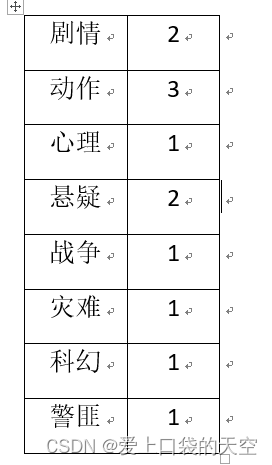
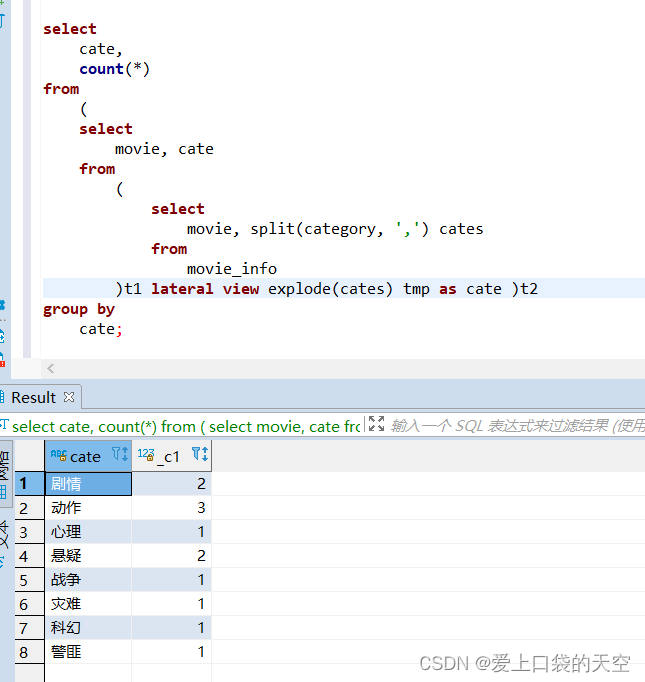
1)需求说明
根据上述电影信息表,统计各分类的电影数量,期望结果如下:
4、窗口函数
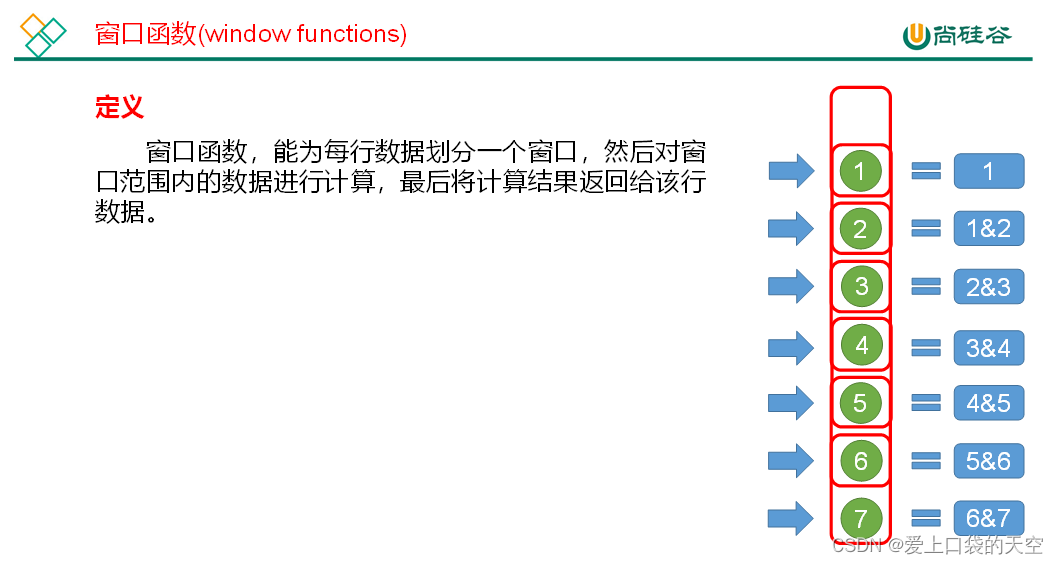
4.1、概述
4.2、常用的窗口函数


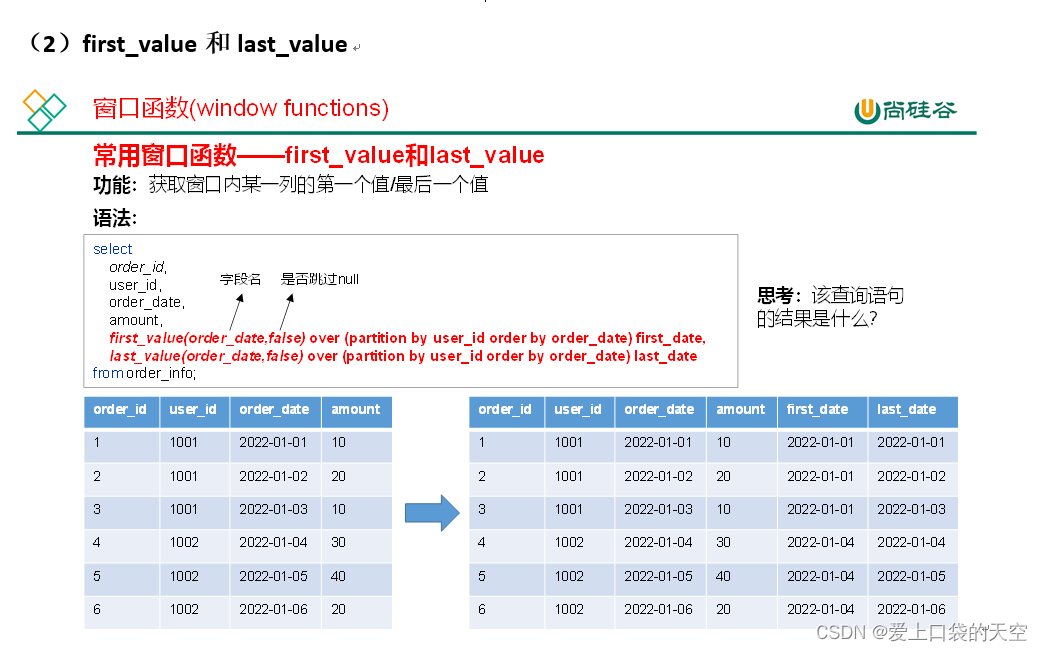
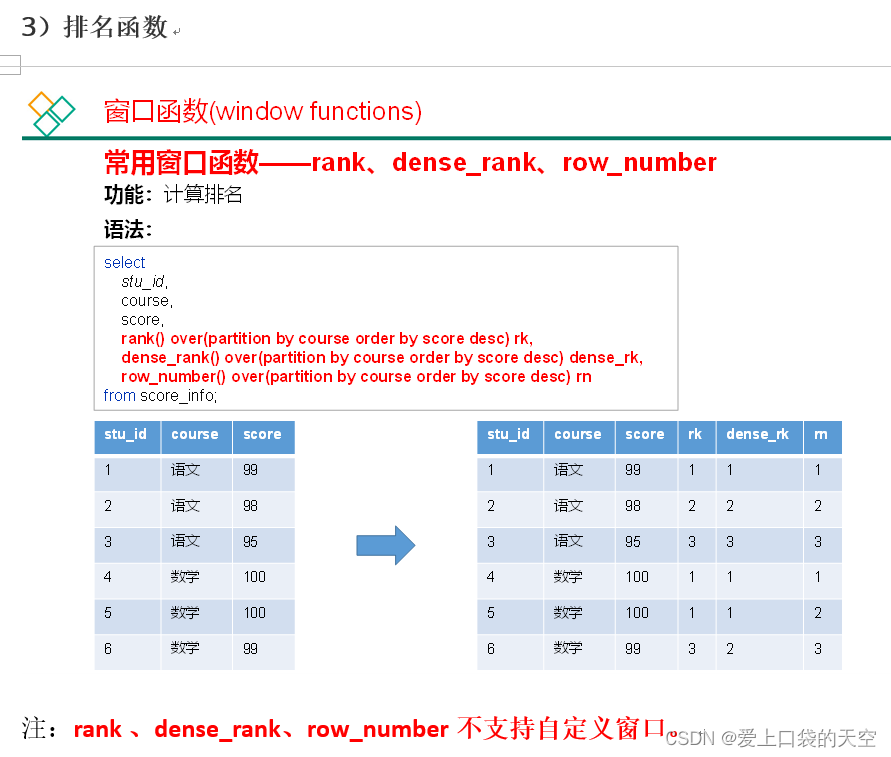
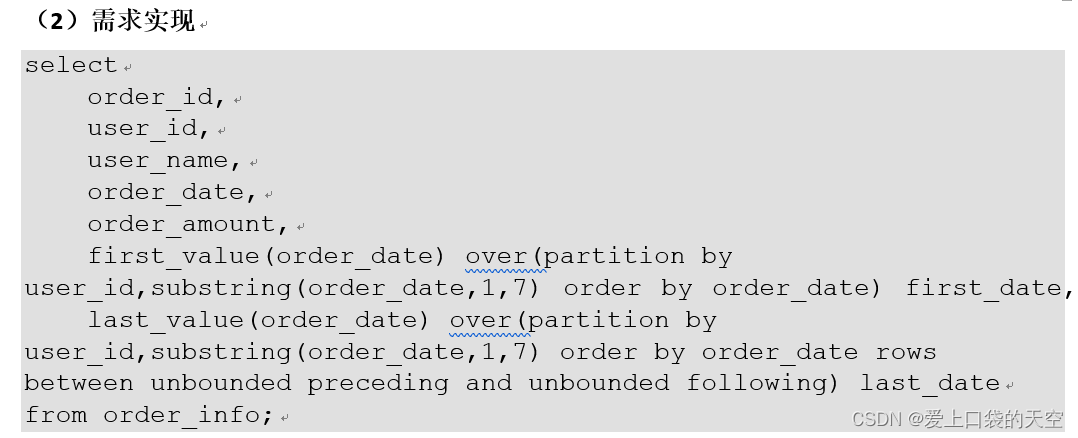
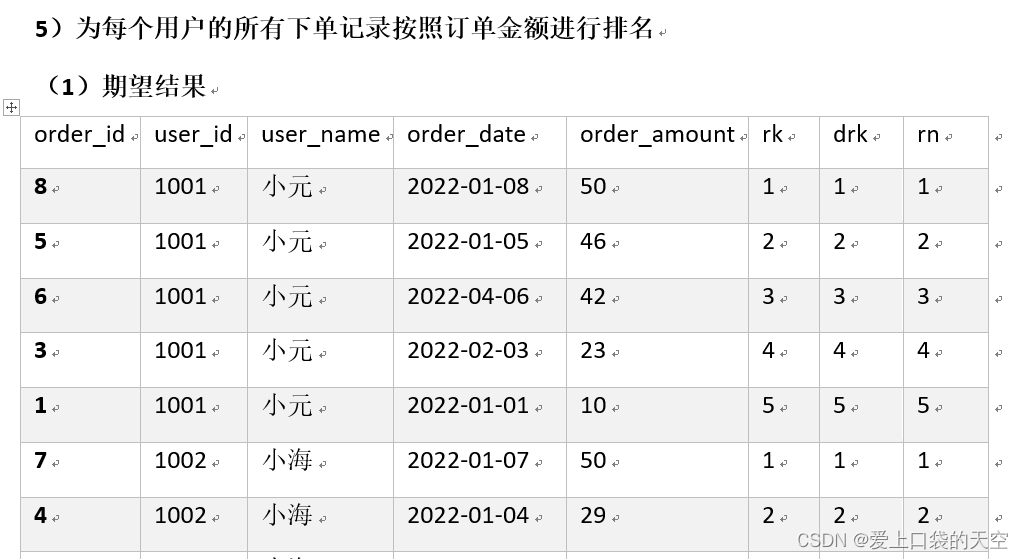
4.3、案例演示
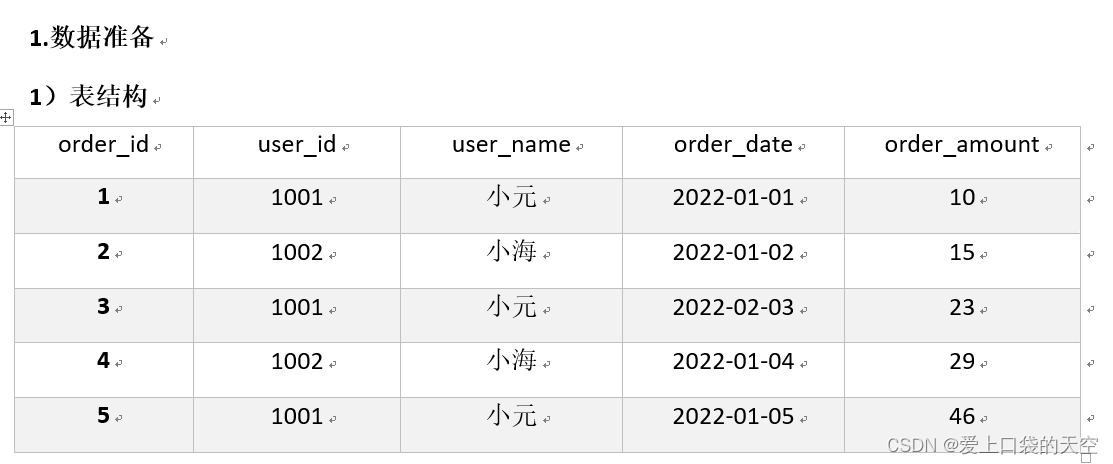

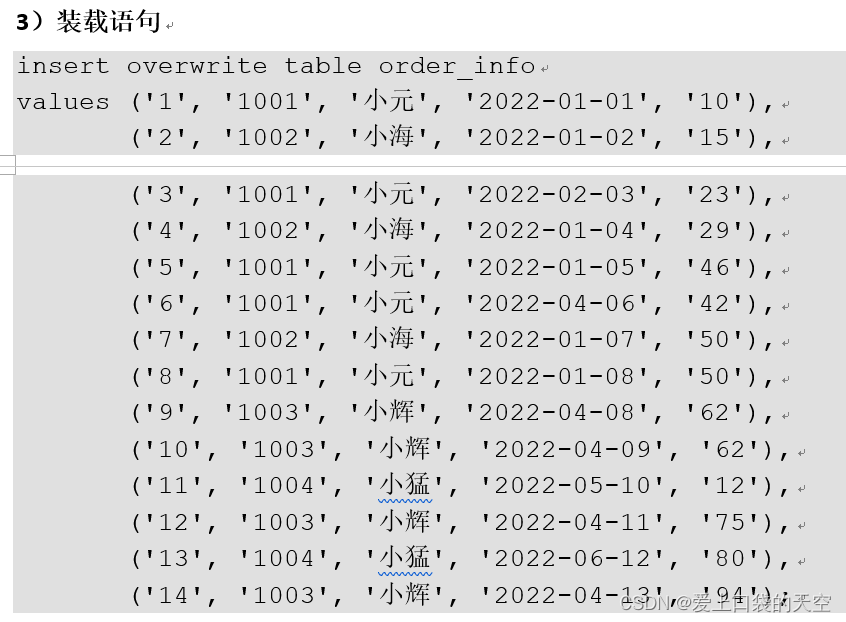

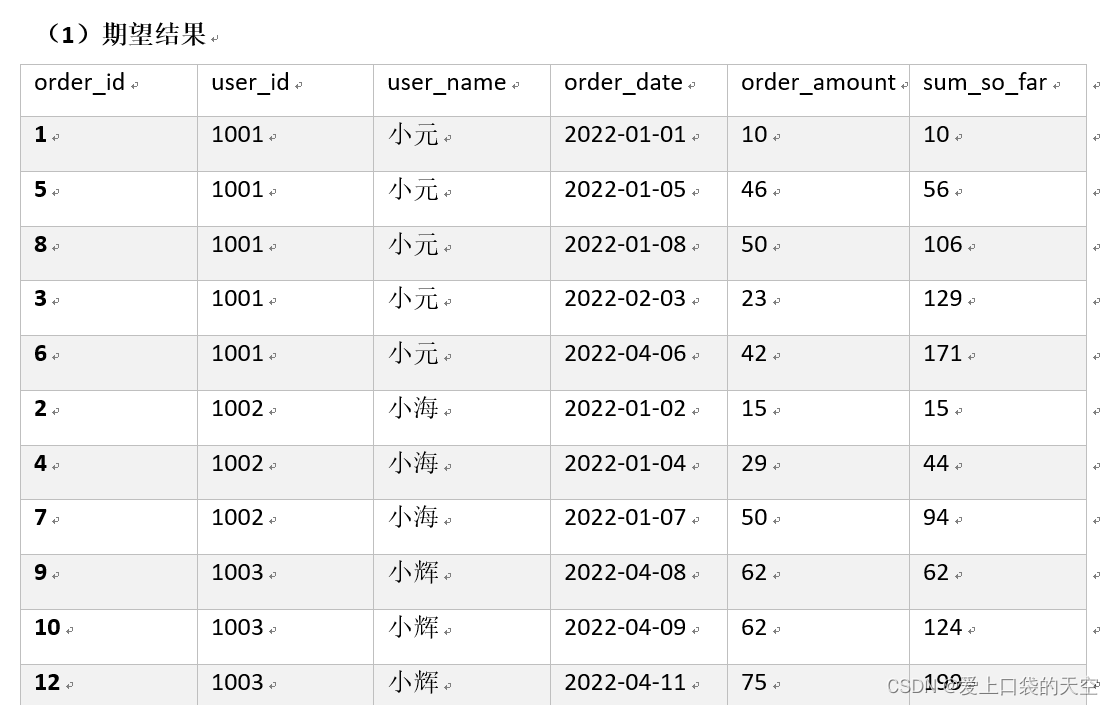

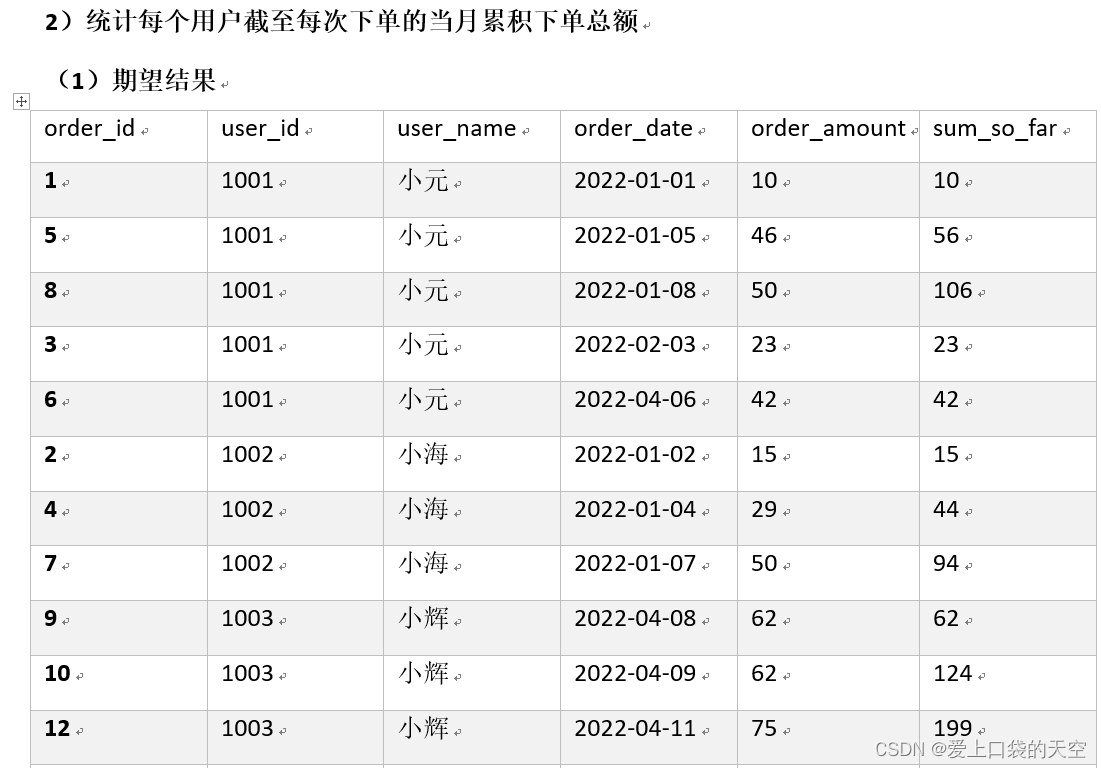

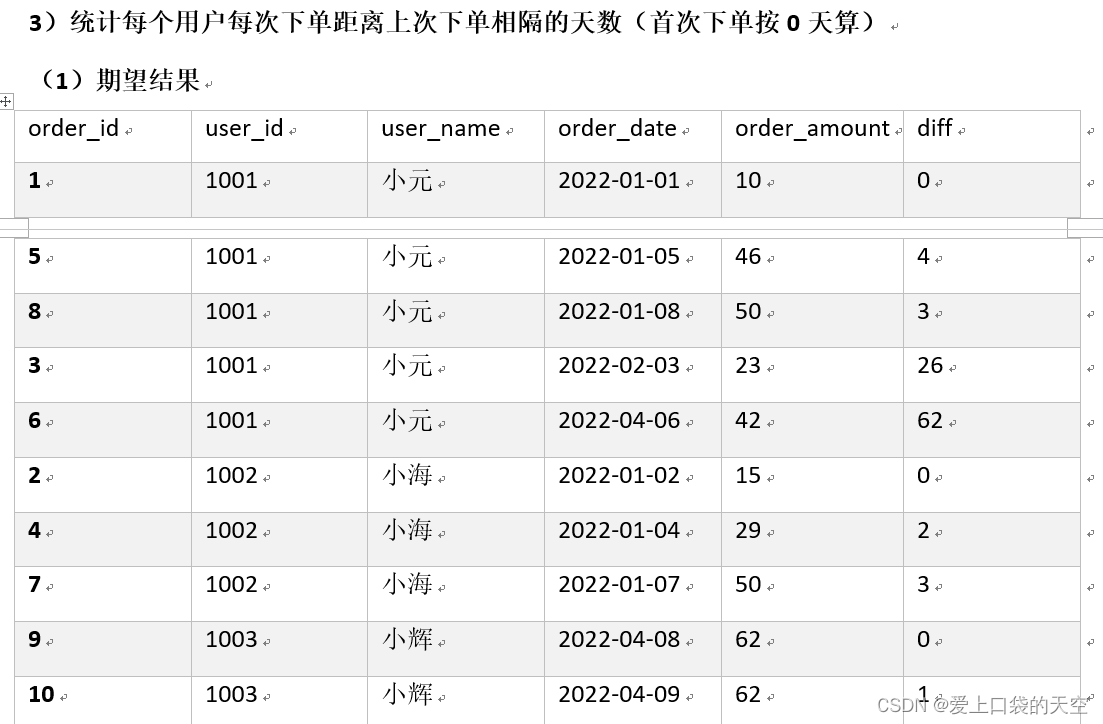
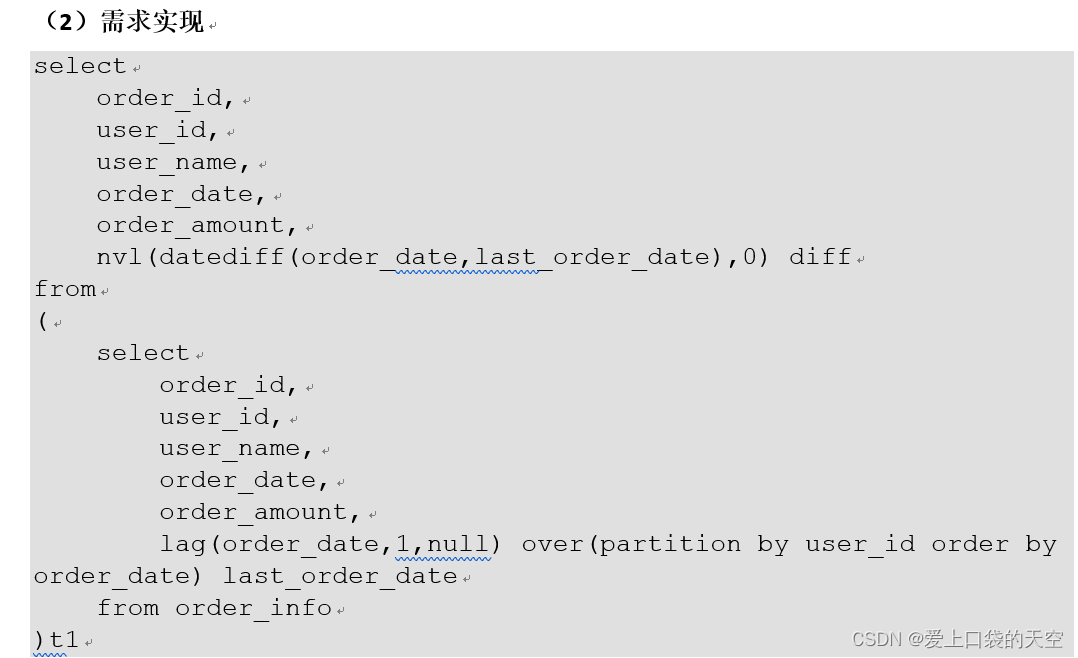
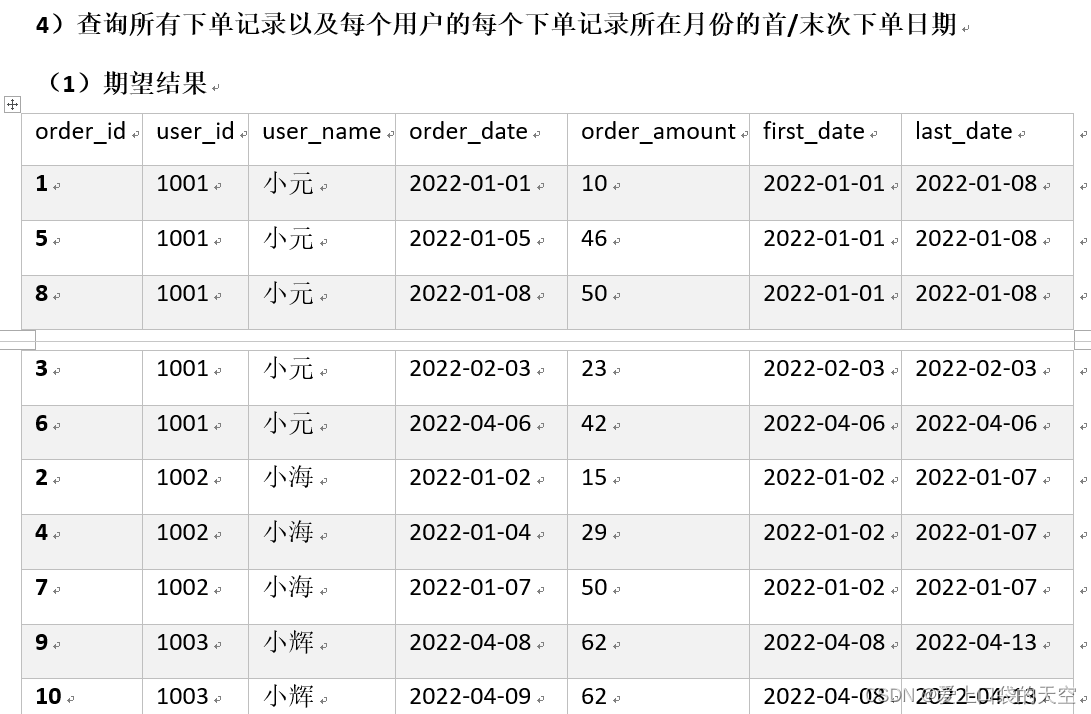








![【Pip】pip 安装第三方包异常:[SSL:CERTIFICATE_VERIFY_FAILED]解决方案](https://img-blog.csdnimg.cn/direct/a86a587fb65842c3a078c4dd54938aed.jpeg)