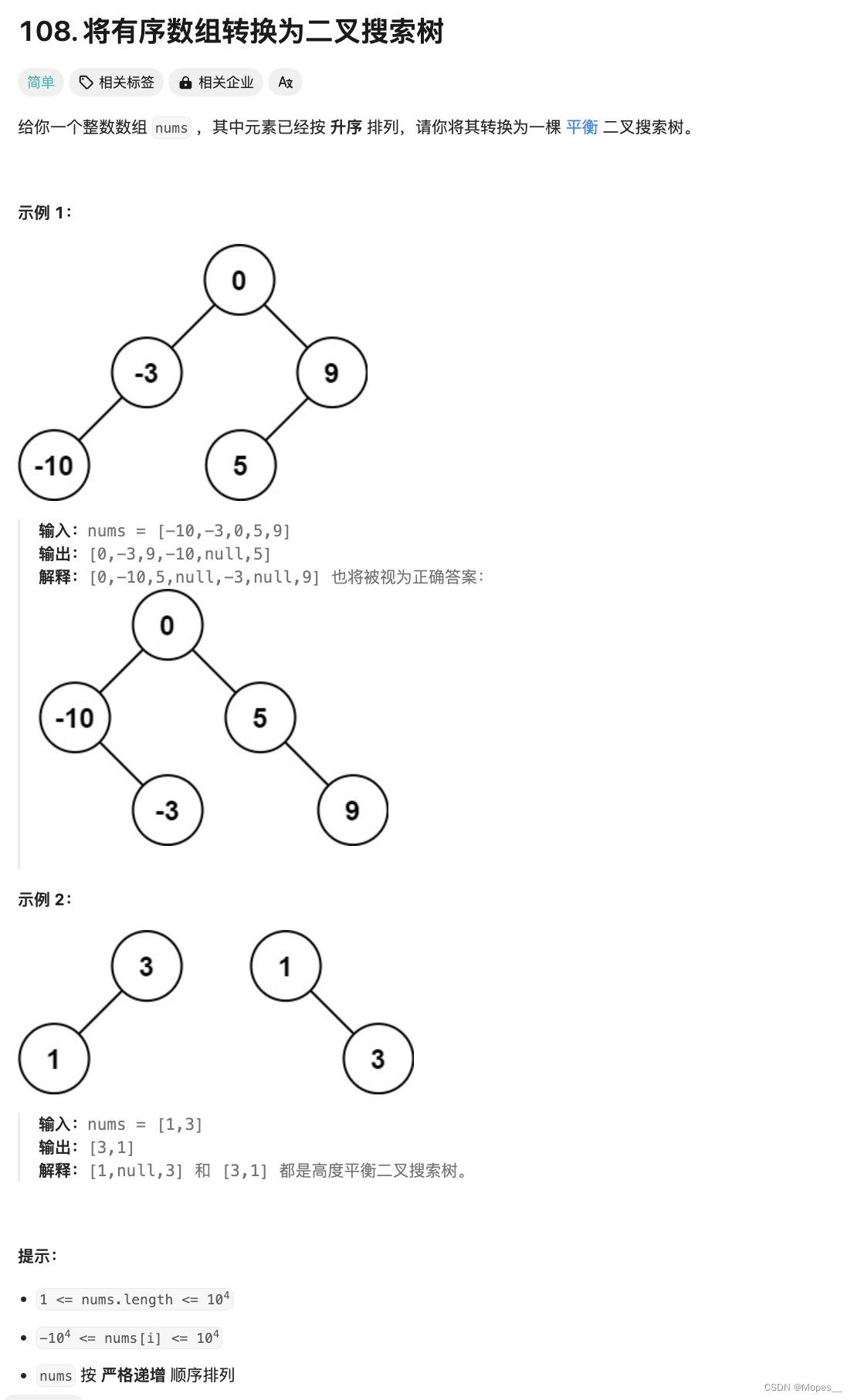
今天上课讲R语言,要干什么没讲,分析什么,目的是什么没讲。助教基本上就是让我们打开窗口,按要求抄代码指令,代码原理也没讲......再加上最近正好在学概率论与数理统计,肯定是有用的,所以还是学习总结一下吧。
概述:
R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
与其说R是一种统计软件,还不如说R是一种数学计算的环境,因为R并不是仅仅提供若干统计程序、使用者只需指定数据库和若干参数便可进行一个统计分析。R的思想是:它可以提供一些集成的统计工具,但更大量的是它提供各种数学计算、统计计算的函数,从而使使用者能灵活机动的进行数据分析,甚至创造出符合需要的新的统计计算方法。
目录
1.安装
2. 简单例程上手以及部分学习
R预备知识
简单指令上手
1.因子化数据帧
2.交叉制表
3.卡方检验
4.二项式检验
返回值
适用场景
注意事项
示例
1.安装
先安装R,再安装Rstudio



2. 简单例程上手以及部分学习
R预备知识
##1-变量名的命名
### 数字不能开头;
### %号是非法字符,不可以用来命名;
### .号后面不可以跟数字;
##2-赋值(赋值给谁,箭头就指向谁)
### 分别是左箭头<-(<键+-键(等号左边的那个,不要按Shift)),等号=,右箭头->
higth<-c(175,169,179,175,180,183)
higth_mean<-mean(higth)#对身高求均值
##3-变量的显示
a<-2
a #命令行直接输入变量名
print(a) #利用print()函数
##4-安装R包
install.packages()
library()
##5-文件的读取
readLines()
read.csv()#推荐使用
read.table()
read.xlsx()
##6-软件的推出与保存
### 可以直接输入q()函数;也可以右上角直接叉掉
### 有.R、.Rdata等后缀,.R一般是保存代码的,.Rdata是保存处理后的数据的。
##7-快捷键介绍
## 运行当前/被选中的代码:`Ctrl`+`Enter`
## 设置工作环境:`Ctrl`+`Shift`+`H`
## 快捷赋值 <- :`alt`+`-`
## 查找不懂的函数:`?函数`,如`?plot`
## R会自动提示你需要的东西
简单指令上手
Tools->Global options->Pane layout 面板设置##读取文件
getwd() 获取工作目录
setwd("G:/工效学/class_R") 设置工作目录,记得引号
prefsAB <-read.csv("prefsAB.csv")
ide2 <- read.csv("ide2.csv") 读取文件##查看数据
View(prefsAB)#分类变量,需做因子化
prefsAB$Subject = factor(prefsAB$Subject)
prefsAB$Pref = factor(prefsAB$Pref) 在R中使用factor函数来创建因子
str(prefsAB)#需要对类别数据进行因子化,以实现研究对象的分组、分类计算
#可以看到有多少类别和水平##基本统计
summary(prefsAB)
plot(prefsAB$Pref) # 画一个基本的柱状图##执行检验
prfs = xtabs( ~ Pref, data=prefsAB)
prfs
chisq.test(prfs)
binom.test(prfs)install.packages("plyr") 下载程序包
library(plyr) 加载包ddply(ide2,~IDE,summarise,Time.mean=mean(Time),Time.sd=sd(Time))
hist(ide2[ide2$IDE == "VStudio",]$Time)
hist(ide2[ide2$IDE == "Eclipse",]$Time)
plot(Time ~ IDE,data=ide2)#首先是正态性假设
# Shapiro-Wilk normality test(夏皮罗-威尔克检验)
shapiro.test(ide2[ide2$IDE == "VStudio",]$Time) #H0:研究对象符合正态分布。
shapiro.test(ide2[ide2$IDE == "Eclipse",]$Time)
## 满足正态性假设
m = aov(Time ~ IDE, data=ide2) # fit model
shapiro.test(residuals(m)) # test residuals
qqnorm(residuals(m)); qqline(residuals(m))
读取CSV文件、查看数据框、对数据框的特定列进行因子化,并对因子化后的数据进行摘要和绘图。
1.因子化数据帧
因子是用于表示分类数据的类型,这对于分类分析和统计建模非常有用。
factor 函数用于向量或单个列,而不是整个数据框。如果你尝试对整个数据框应用 factor 函数,会遇到错误。你需要对数据框中的特定列进行因子化,而不是对整个数据框。
# 读取CSV文件
prefsAB <- read.csv("prefsAB.csv")
ide2 <- read.csv("ide2.csv")# 查看数据框内容
View(prefsAB)
View(ide2)# 对prefsAB数据框中的列进行因子化
prefsAB$Subject <- factor(prefsAB$Subject)
prefsAB$Pref <- factor(prefsAB$Pref)# 查看因子化后的数据框
View(prefsAB)# 获取数据框的摘要信息
summary(prefsAB)# 绘制prefsAB$Pref的图表
plot(prefsAB$Pref)
plot(prefsAB$Pref)绘制 prefsAB 数据框中 Pref 列的条形图有助于可视化每个因子水平的频数。
summary(ide2) 用于生成并显示数据框的摘要信息,包括每列的统计信息。对于因子列,这将显示每个因子水平的频数。

head() 函数用于查看数据集的开头部分,它默认显示数据框的前六行。这对于快速查看数据集的结构和内容非常有用,可以帮助你了解数据的组织方式和其中包含的信息。
str(ide2) 函数显示了关于数据框 ide2 结构的摘要信息。在这个摘要中,我们可以看到:
- 数据框
ide2包含了 40 行观察值(observation)和 3 个变量(variables)。 - 第一个变量是
Subject,是一个整数(int),表示实验参与者的编号。 - 第二个变量是
IDE,是一个字符向量(chr),表示实验中使用的集成开发环境(IDE)的名称。 - 第三个变量是
Time,是一个整数(int),表示实验中使用该 IDE 所花费的时间(以某个单位表示,可能是秒)。
summary(ide2) 函数提供了关于数据框 ide2 中数值变量的摘要统计信息。让我们逐一解释这个摘要:
-
Subject: 这是实验参与者的编号。摘要显示了每个不同值的频数。例如,出现了1次的有1、2、3、4等,没有显示的Subject编号表示频数为1。"Other"行表示其他出现次数少于5次的编号。
-
IDE: 这是实验中使用的集成开发环境(IDE)的名称。摘要显示了每个不同值的频数。在你的数据中,有20次使用Eclipse和20次使用VStudio。
-
Time: 这是实验中使用每个IDE所花费的时间。摘要包括了五个统计量:最小值(Min.)、第一四分位数(1st Qu.)、中位数(Median)、平均值(Mean)、第三四分位数(3rd Qu.)和最大值(Max.)。
2.交叉制表
prfs = xtabs(~Pref,data=prefsAB)
chisq.test(prfs)
prfs = xtabs(~Pref, data=prefsAB) 执行了一个交叉制表的操作,它会创建一个交叉制表,显示了在 prefsAB 数据框中 Pref 列中各个水平(A 和 B)的频数。xtabs函数用于快速计算一个或多个变量的频率,响应变量~自变量。
xtabs函数是 R 中用来创建交叉制表的函数。~Pref表示要对数据框prefsAB中的列Pref进行交叉制表。data=prefsAB表示这个操作应该在prefsAB数据框中进行。
因此,prfs 变量中存储了一个交叉制表的结果,显示了在 prefsAB 数据框中 Pref 列中各个水平(A 和 B)的频数。
3.卡方检验
卡方检验的目的: 卡方检验用于检验观察到的类别数据是否与期望频率有显著差异。其基本思想是比较观察到的频数(observed frequencies)和期望频数(expected frequencies),并通过计算一个统计量来评估这种差异是否显著。


chisq.test 函数对 prfs 执行卡方检验
输出如下:
Chi-squared test for given probabilities
data: prfs
X-squared = 17.067, df = 1, p-value = 3.609e-05
结果分析:
- X-squared = 17.067:这是计算出的卡方统计量。
- df = 1:这是自由度。
- p-value = 3.609e-05:这是计算出的p值。
由于p值非常小(远小于0.05),我们可以拒绝零假设,认为 Pref 变量中的A和B类别的出现频率有显著差异。
通过卡方检验,能够确定 prefsAB 数据中 Pref 列的两个类别(A和B)是否存在显著的频数差异。结果显示,A和B的出现频率差异显著,这表明在这个数据集中A和B的分布并不是随机的,可能存在某种偏好或影响因素。
4.二项式检验
binom.test 函数用于执行二项式检验,也称为精确二项检验。它用于检验一个二项分布中的成功概率是否等于某个给定的值。
binom.test(x, n, p = 0.5, alternative = c("two.sided", "less", "greater"), conf.level = 0.95)
- x: 成功的次数,或者是一个长度为2的向量,包含两个元素,分别是成功的次数和总的试验次数。
- n: 总的试验次数。如果
x是一个长度为2的向量,则该参数被忽略。 - p: 假设的成功概率。默认为0.5。
- alternative: 检验的备择假设类型,可以是
"two.sided"(双侧检验,默认)、"less"(左侧检验)、或者"greater"(右侧检验)。 - conf.level: 置信水平,默认为0.95,表示95%的置信水平。
返回值
函数返回一个包含二项式检验的结果的列表,其中包括:
- estimate: 成功概率的估计值。
- p-value: 检验的p值。
- conf.int: 成功概率估计的置信区间。
- method: 使用的检验方法的名称。
适用场景
- 当你有一组二项分布的数据,想要检验其中的成功概率是否等于某个给定的值时,可以使用二项式检验。
- 常见的应用场景包括医学研究、产品测试、市场调查等。
注意事项
- 在执行二项式检验之前,确保你的数据满足二项分布的假设,即每次试验之间是相互独立的,且成功概率在各次试验中保持不变。
- 对于小样本数据
示例
假设你有一组硬币抛掷的数据,你想要检验硬币正面朝上的概率是否等于0.5。你可以使用
binom.test函数来进行检验: -
# 假设你投掷了100次硬币,正面朝上的次数是45次 binom.test(45, 100, p = 0.5)binom.test(45, 100, p = 0.5)这将会执行一个双侧的二项式检验,检验硬币正面朝上的概率是否等于0.5,返回相应的检验结果。