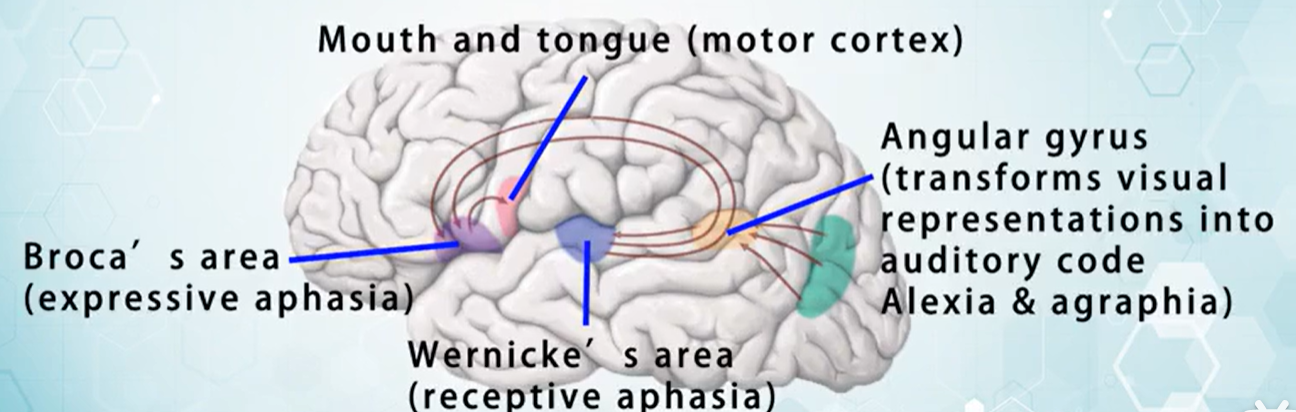
1. 查询某个索引库中数据总量
方式一:
CountRequest 鄙人喜欢这种方式
public long getTotalNum(String indexName) throws IOException {CountRequest countRequest = new CountRequest(indexName);// 如果需要,你可以在这里添加查询条件// countRequest.query(QueryBuilders.matchQuery("field_name", "value"));CountResponse countResponse = esHighLevelClient.count(countRequest, RequestOptions.DEFAULT);return countResponse.getCount();}
方式二:
SearchRequest 这种方式只能查询出10000条。
SearchRequest searchRequest = new SearchRequest();searchRequest.indices(index);SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();sourceBuilder.query(QueryBuilders.matchAllQuery());System.out.println("SDL语句:"sourceBuilder);searchRequest.source(sourceBuilder);SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);long value = response.getHits().getTotalHits().value;System.out.println("数据总量:"+value);
优化方式,设置trackTotalHits(true)则可以获取数据总量
sourceBuilder.trackTotalHits(true);
2. 分页问题
分页类型:
- 浅分页
- 深度分页
浅分页 from+size
适用场景:适用于数据量不大、实时性要求高的场景。
示例代码
SearchRequest searchRequest2 = new SearchRequest();searchRequest2.indices(index);SearchSourceBuilder sourceBuilder2 = new SearchSourceBuilder();for (int i = 1; i <= totalPage; i++) {//---------------from + sizesourceBuilder2.from((i - 1) * 300);System.out.println("起始索引是:"+(i - 1) * 300);sourceBuilder2.size(300);searchRequest2.source(sourceBuilder2);SearchResponse searchResponse = restHighLevelClient.search(searchRequest2, RequestOptions.DEFAULT);SearchHits hits = searchResponse.getHits();SearchHit[] hits1 = hits.getHits();System.out.println("xxxx");}System.out.println("完成");当起始索引+每页显示条数 from+size大于10000时,报错:
result window is too large, from + size must be less than or equal to
原因:
系统默认限制10000条。
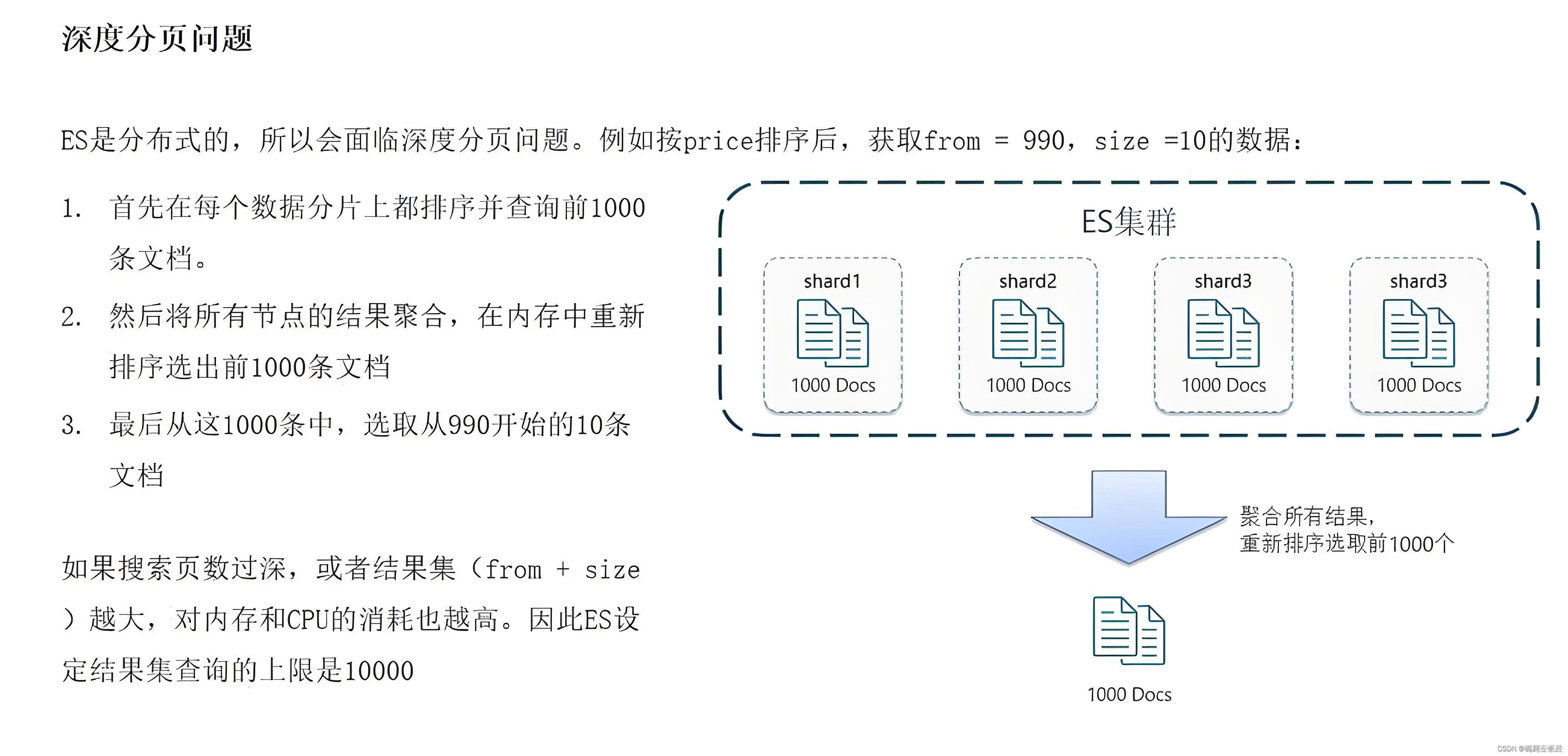
系统为什么限制10000条?
es分页原理:
------比如,现在要from为990,size为10,es会从每个分片中拿到前1000条数据,假如这个索引现在有4个分片,那么就会拿到4000条数据,然后在内存中对这4000条数据进行排序,然后从这4000条文档中取出前10条数据,4000条数据的存储,排序等操作都是在内存中完成,非常耗费资源。
------如果分页再继续深入下去,比如from为9990,size为10,那么就会从每个分片中先拿到前10000条数据,4个分片就是40000条数据,这时就要把4万条数据在内存中存储、排序等。如果分页再继续深入下去,也就是(from+size)*分片数量越大 ,越消耗资源,而且是倍数增长。
解决方案:
还是用from+size的方式进行分页,但是设置索引库index.max_result_window的值即可。
PUT yourindex/_settings
{"index.max_result_window": "1000000"
}
max_result_window 最大限制为 10亿
不推荐
参考:https://huaweicloud.csdn.net/637ee8fadf016f70ae4c9702.html
虽然这样设置在大数据量分页查询时能够解决result window is too large, from + size must be less than or equal to 这个问题,但是不推荐这样使用。
因为其会带来严重的后果,最常见的就是后期频繁的 OOM,而且很难发现原因。
看一下官方对该参数的解释:

ax_result_window本身是对JVM的一种保护机制,通过设定一个合理的阈值,避免初学者分页查询时由于单页数据过大而导致OOM。
在很多业务场景中经常需要查询10000条以后的数据,当遇到不能查询10000条以后的数据的问题之后,网上的很多答案会告诉你可以通过放开这个参数的限制,将其配置为100万,甚至1000万就行。
但是如果仅仅放开这个参数就行,那么这个参数限制的意义有何在呢?如果你不知道这个参数的意义,很可能导致的后果就是频繁的发生OOM而且很难找到原因
那么这个参数就完全不能动吗?当然不是,设置一个合理的参数阈值是需要通过你的各项指标参数来衡量确定的,比如你用户量、数据量、物理内存的大小、分片的数量等等。通过监控数据和分析各项指标从而确定一个最佳值,并非越大越好。
建议如果你不是对 ES 有足够的了解和使用经验,不要轻易修改max_result_window参数的阈值!
所以当数据量非常大时,分页就不要用form+size,推荐使用深度分页
深度分页 scroll
使用方式:
scroll 原理:
scroll 分页方式的原理与游标(cursor)类似。当你执行一个带有 scroll 参数的搜索查询时,Elasticsearch会为这次搜索创建一个快照(snapshot),并存储相关的搜索上下文(search context)。这个上下文包括查询本身、排序方式、聚合等所有与搜索相关的信息。
- 首次POST /_search/scroll请求会返回一部分结果(基于size参数)以及一个scroll_id。
- 使用这个scroll_id,你可以通过后续的POST /_search/scroll请求来获取更多的结果。
- scroll参数定义了在多长时间内可以保持scroll上下文有效。如果在这个时间内没有新的scroll请求,那么scroll上下文就会被删除,无法再获取更多结果。
使用RestHighLevelClient
适用场景:如日志导出、数据迁移等,当不适用于用户界面的分页。因为scroll获取的数据不是实时性的,而是保存快照那一刻的数据,也就意味着即使有新数据写入,也不会被包含在查询结果中。
// 初始化scroll搜索
POST /_search/scroll
{"size": 100, // 每次返回的文档数量"scroll": "1m", // 保持scroll上下文的活动时间,这里是1分钟"query": {"match_all": {} // 可替换为任何需要的查询条件}
}// 后续的scroll请求(在第一次请求返回后)
POST /_search/scroll
{"scroll": "1m", // 保持与第一次请求相同的scroll上下文时间"scroll_id": "你的scroll_id" // 第一次请求返回的scroll_id
}
public void TestScroll() throws IOException {SearchRequest searchRequest = new SearchRequest(index);//创建查询条件SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.query(QueryBuilders.matchAllQuery());// 设置每批获取的数量searchSourceBuilder.size(1000);searchRequest.source(searchSourceBuilder);// 设置滚动时间searchRequest.scroll(TimeValue.timeValueMinutes(5));SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);String scrollId = searchResponse.getScrollId();do {for (SearchHit hit : searchResponse.getHits().getHits()) {//TODO 处理搜索结果System.out.println(hit.getSourceAsMap());}// 使用当前的滚动ID进行下一个批次的搜索SearchScrollRequest scrollRequest = new SearchScrollRequest(scrollId);scrollRequest.scroll(TimeValue.timeValueMinutes(5));scrollId = searchResponse.getScrollId();searchResponse = restHighLevelClient.scroll(scrollRequest, RequestOptions.DEFAULT);} while (searchResponse.getHits().getHits().length != 0);//清除Scroll请求状态ClearScrollRequest clearScrollRequest = new ClearScrollRequest();clearScrollRequest.addScrollId(scrollId);restHighLevelClient.clearScroll(clearScrollRequest, RequestOptions.DEFAULT);}
深度分页 search_after
参考:https://blog.csdn.net/u011250186/article/details/125483759
原理
实现原理:
search_after 分页的方式是根据上一页的最后一条数据来确定下一页的位置,同时在分页请求的过程中,如果有索引数据的增删改查,这些变更也会实时的反映到游标上。
说明:
为了找到每一页最后一条数据,每个文档必须有一个全局唯一值,官方推荐使用 _uid 作为全局唯一值,其实使用业务层的 id 也可以。
说明:使用search_after查询需要将from设置为0或-1,当然也可以不写。
需要注意的是:
1)sort字段的选择
如果search_after中的关键字为***,那么***123的文档也会被搜索到,所以在选择search_after的排序字段时需要谨慎,可以使用比如文档的id或者时间戳等。另外,search_after并不是随机的查询某一页数据,而是并行的滚屏查询;search_after的查询顺序会在更新和删除时发生变化,也就是说支持实时的数据查询。
2)无法跳页请求
因为每一页的数据依赖于上一页最后一条数据,所以无法跳页请求。
public void TestSearchAfter() throws Exception {SearchRequest searchRequest = new SearchRequest();searchRequest.indices(index);SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.from(0).size(1000);searchSourceBuilder.query(QueryBuilders.matchAllQuery());// 指定排序,并设置sort values为上一次查询的最后一条记录的sort valuessearchSourceBuilder.sort("_id", SortOrder.ASC);List<Map<String, Object>> mapList = new ArrayList<>();this.search(searchRequest,searchSourceBuilder,mapList, null);System.out.println(mapList.size());}private void search(SearchRequest searchRequest,SearchSourceBuilder searchSourceBuilder,List<Map<String, Object>> totalList, Object[] objects) throws Exception{if(Objects.nonNull(objects)){searchSourceBuilder.searchAfter(objects);}searchRequest.source(searchSourceBuilder);System.out.println(searchSourceBuilder);SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);SearchHit[] hits = searchResponse.getHits().getHits();if(Objects.nonNull(hits) && hits.length > 0){List<Map<String, Object>> collect = Arrays.stream(hits).map(SearchHit::getSourceAsMap).collect(Collectors.toList());//TODO 处理数据 ,可以不要 totalList参数 totalList.addAll(collect);search(searchRequest,searchSourceBuilder,totalList,hits[hits.length - 1].getSortValues());}}