ICML 2023
paper
code
Intro
文章提出了一种用于无监督基于模型强化学的方法,称为可预测MDP抽象(Predictable MDP Abstraction, PMA)。在MBRL中,一个关键部分是能够准确建模环境动力学动态模型。然而,这个预测模型误差可能会降低策略性能,并且在复杂的马尔可夫决策过程中(MDPs),准确的预测可能非常困难。
为了缓解这个问题,作者提出了PMA,它不是在原始MDP上训练预测模型,而是在一个变换后的MDP上训练模型,这个变换后的MDP通过学习动作空间中可预测和易于建模的动作,同时尽可能覆盖原始的状态-动作空间。这样,模型学习变得更容易和更准确,从而允许鲁棒、稳定的基于模型的规划或基于模型的RL。这种变换是在无监督的方式下学习的,在用户指定任何任务之前。然后,可以零样本(zero-shot)解决下游任务,而无需额外的环境交互。作者从理论上分析了PMA,并通过一系列基准环境证明了PMA相对于以前的无监督MBRL方法有显著的改进。
Method
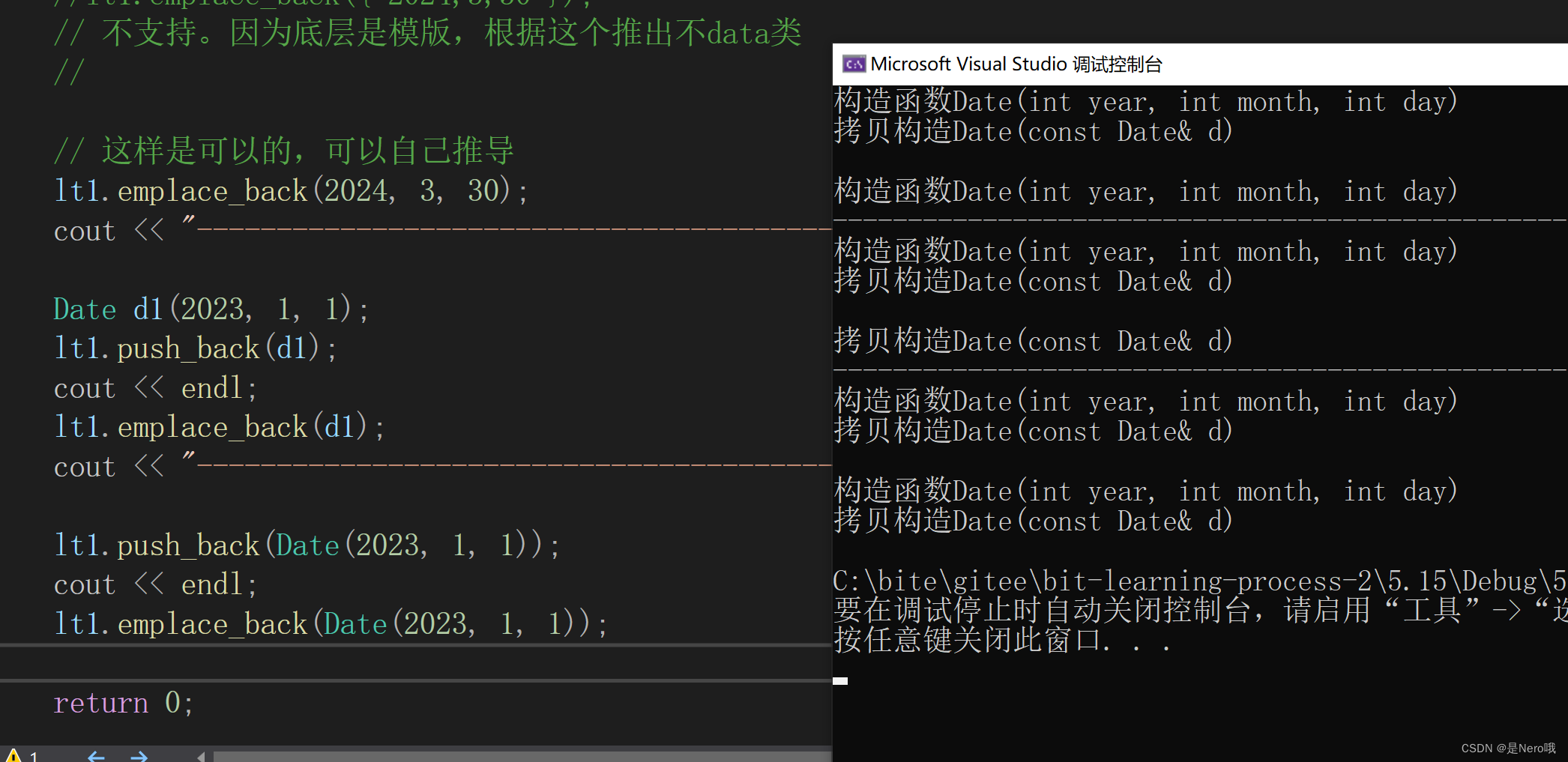
PMA 所构建的MDP过程结构如下

而对于可预测的MDP抽象需要满足三个需求
- 基于隐变量的状态转移函数 p ( s ′ ∣ s , z ) p(s'|s,z) p(s′∣s,z)得到的状态能够尽可能被预测到, 即最小化预测不确定性
- 潜在动作的结果应该彼此尽可能不同(即最大化动作多样性以保持原始 MDP 的大部分表现力)
- 潜在 MDP 中的转换应尽可能覆盖原始转换(即最小化认知不确定性来鼓励探索)
基于上述需求构建如下信息论目标
max π z , π e I ( S ′ ; ( Z , Θ ) ∣ D ) , \max_{\pi_z,\pi_e}I(S';(Z,\Theta)|\mathcal{D}), πz,πemaxI(S′;(Z,Θ)∣D),
其中D表示训练数据集以及Z, Θ \Theta Θ表示潜在预测模型 p ^ z ( s ′ ∣ s , z ; θ ) \hat{p}_z(s^{\prime}|s,z;\theta) p^z(s′∣s,z;θ)参数。该式子进一步分解为:

这三项就分别满足上述的三个需求。特别的是第三项中,在已知状态转移后最小化参数的不确定性。
原始的互信息估计计算困难,因此对等式(4)第一项做如下近似估计

而对于information gain部分则是采用对ensemble model的不确定性估计近似

上述两个部分相加得到额外的奖励函数。结合基于模型的算法训练策略以及潜在动力学模型。而在下游任务进行zero-shot的实验,因为出现OOD的问题,这里加入了集成模型间最大分歧作为惩罚项
u ( s , z ) = − λ ⋅ max i , j ∈ [ E ] ∥ μ ( s , z ; θ i ) − μ ( s , z ; θ j ) ∥ 2 . ( 11 ) u(s,z)=-\lambda\cdot\max_{i,j\in[E]}\|\mu(s,z;\theta_i)-\mu(s,z;\theta_j)\|^2.(11) u(s,z)=−λ⋅i,j∈[E]max∥μ(s,z;θi)−μ(s,z;θj)∥2.(11)
伪代码

结果