513.找树左下角的值
力扣链接
给定一个二叉树的 根节点 root,请找出该二叉树的 最底层 最左边 节点的值。
思路 层序遍历
层序遍历之后,取最后一个数组的第一个元素
class Solution:def findBottomLeftValue(self, root: Optional[TreeNode]) -> int:levels = []self.helper(root, 0, levels)return levels[-1][0]def helper(self, node, level, levels):if node == None:returnif len(levels)== level:levels.append([])levels[level].append(node.val)self.helper(node.left, level+1,levels)self.helper(node.right, level+1,levels)
112. 路径总和
力扣链接
给你二叉树的根节点 root 和一个表示目标和的整数 targetSum 。判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。如果存在,返回 true ;否则,返回 false 。
思路
和二叉树的所有路径一样需要用到回溯,一直遍历到叶子节点,判断这一路上的和是否符合条件,如果不符合则回溯到上一个节点,以此重复。
判断和是否符合要求,可以用target递减的方式,判断最终结果是否为0
class Solution:def hasPathSum(self, root: Optional[TreeNode], targetSum: int) -> bool:if root == None:return Falsereturn self.traversal(root, targetSum-root.val)def traversal(self, node, cnt):if node.left == None and node.right == None and cnt == 0: # 遇到叶子结点并且计数为0return Trueif node.left == None and node.right == None and cnt != 0: # 遇到叶子结点并且计数不为0return Falseif node.left:cnt -= node.left.valif self.traversal(node.left, cnt): return Truecnt += node.left.val # 回溯if node.right:cnt -= node.right.valif self.traversal(node.right, cnt): return Truecnt += node.right.val # 回溯return False
113. 路径总和II
力扣链接
给你二叉树的根节点 root 和一个整数目标和 targetSum ,找出所有 从根节点到叶子节点 路径总和等于给定目标和的路径。
思路
和上一题及二叉树的所有路径很像,为了避免参数混乱可以创建全局变量
class Solution:def __init__(self):self.result = []self.path = []def traversal(self, cur, count):if not cur.left and not cur.right and count == 0: # 遇到了叶子节点且找到了和为sum的路径self.result.append(self.path[:])returnif not cur.left and not cur.right: # 遇到叶子节点而没有找到合适的边,直接返回returnif cur.left: # 左 (空节点不遍历)self.path.append(cur.left.val)count -= cur.left.valself.traversal(cur.left, count) # 递归count += cur.left.val # 回溯self.path.pop() # 回溯if cur.right: # 右 (空节点不遍历)self.path.append(cur.right.val) count -= cur.right.valself.traversal(cur.right, count) # 递归count += cur.right.val # 回溯self.path.pop() # 回溯returndef pathSum(self, root: TreeNode, sum: int) -> List[List[int]]:self.result.clear()self.path.clear()if not root:return self.resultself.path.append(root.val) # 把根节点放进路径self.traversal(root, sum - root.val)return self.result
106.从中序与后序遍历序列构造二叉树
力扣链接
给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。
思路
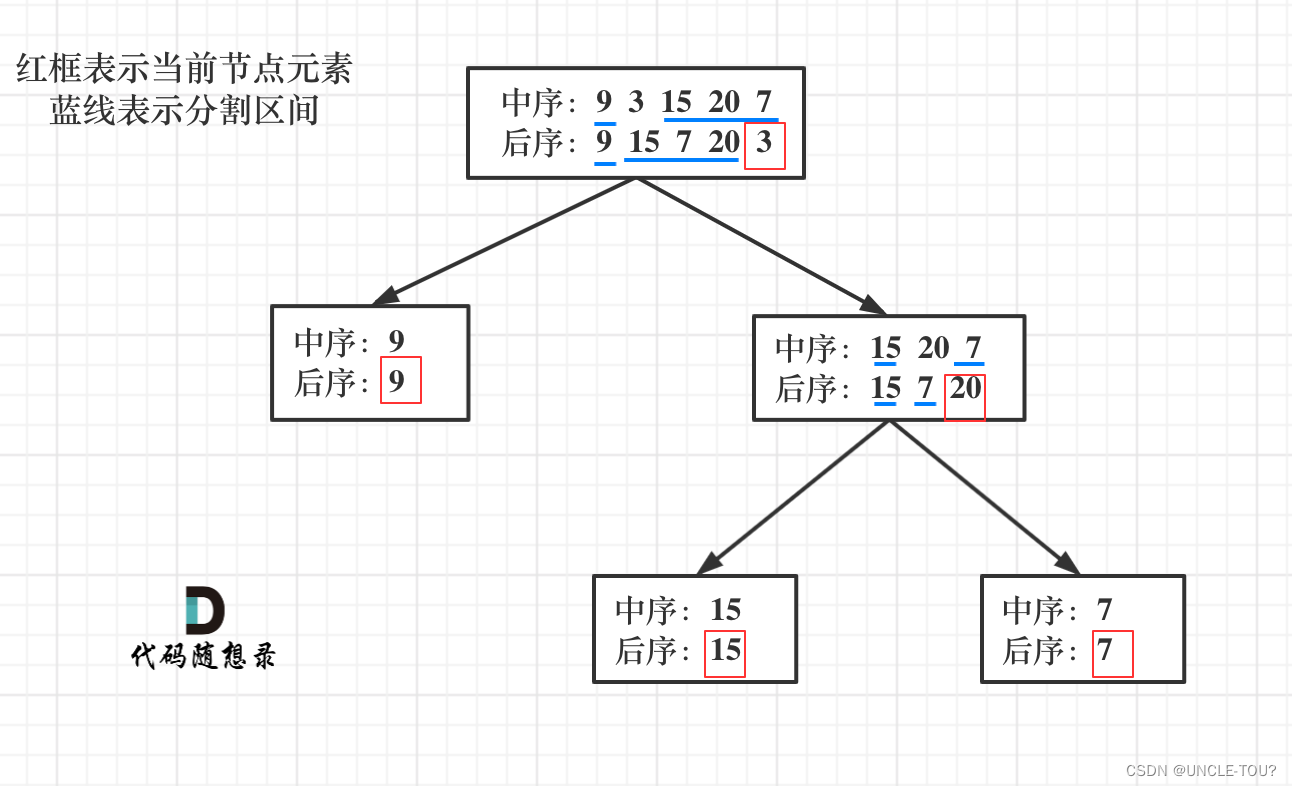
第一步:如果数组大小为零的话,说明是空节点了。
第二步:如果不为空,那么取后序数组最后一个元素作为根节点元素。
第三步:找到后序数组最后一个元素在中序数组的位置,作为切割点
第四步:切割中序数组,切成中序左数组和中序右数组 (顺序别搞反了,一定是先切中序数组)
第五步:切割后序数组,切成后序左数组和后序右数组
第六步:递归处理左区间和右区间
class Solution:def buildTree(self, inorder: List[int], postorder: List[int]) -> TreeNode:# 1.判断是否空if postorder == []:return None# 2.后序遍历的最后一个是当前中间节点root_val = postorder[-1]root = TreeNode(root_val)# 3.切割点separtor_idx = inorder.index(root_val)# 4.切分inorderinorder_l = inorder[:separtor_idx]inorder_r = inorder[separtor_idx+1:]# 5.切分postorderpostorder_l = postorder[:len(inorder_l)]postorder_r = postorder[len(inorder_l):len(postorder)-1]# 6.递归root.left = self.buildTree(inorder_l, postorder_l)root.right = self.buildTree(inorder_r, postorder_r)return root
105.从前序与中序遍历序列构造二叉树
力扣链接
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。
思路
与上一题思路类似
第一步:如果数组大小为零的话,说明是空节点了。
第二步:如果不为空,那么取前序数组第一个元素作为根节点元素。
第三步:找到前序数组第一个元素在中序数组中的位置,作为切割点
第四步:切割中序数组,切成中序左数组和中序右数组
第五步:切割前序数组,切成前序左数组和前序右数组
第六步:递归处理左区间和右区间
class Solution:def buildTree(self, preorder: List[int], inorder: List[int]) -> Optional[TreeNode]:# 1.判断是否为空if inorder == []:return None# 2.前序遍历的第一个是当前中间节点root_val = preorder[0]root = TreeNode(root_val)# 3.切割点separtor_idx = inorder.index(root_val)# 4.切分inorderinorder_l = inorder[:separtor_idx]inorder_r = inorder[separtor_idx+1:]# 5.切分preorderpreorder_l = preorder[1:1+len(inorder_l)]preorder_r = preorder[1+len(inorder_l):]# 6.递归root.left = self.buildTree(preorder_l,inorder_l)root.right = self.buildTree(preorder_r,inorder_r)return root