文章目录
- 1.云计算基础知识
- 1.1 基本概念
- 1.2 云计算分类
- 2.大数据处理基础知识
- 2.1 基础知识
- 2.3 大数据处理技术
1.云计算基础知识
1.1 基本概念
云计算是一种提供资源的网络,使用者可以随时获取“云”上的资源,按需求量使用,并且可以看成是无限扩展的,只要按使用量付费就可以。
云计算是与信息技术、软件、互联网相关的一种服务,把许多计算资源集合起来,通过软件实现自动化管理,只需要很少的人参与,就能让资源被快速提供。
云计算是以一种方便的使用方式和服务模式,通过互联网按需访问资源池模型(例如网络、服务器、存储、应用程序和服务),以快速和最少的管理工作为用户提供服务。采用“量入为出”的计费方式,即根据用户使用云服务情况收费。
整体而言,云计算时一种将可伸缩、弹性、共享的物理和虚拟资源池以按需自服务的方式供应和管理,并提供网络访问的模式。
按照ISO/EG17788标准,云计算的关键特征有:广泛的网络接入、可测量的服务、多租户、按需自服务、快速的弹性和可扩展性、资源池化。
- 广泛的网络接入。用户可以通过网络,采用标准机制访问云中的物理和虚拟资源的特性。标准机制有助于用户通过异构平台使用资源。用户可以在任何有网络的地方,利用各种不同类型的客户端,如手机、电脑、工作站等设备,方便地访问云中的资源。
- 可测量的服务。通过可计量的服务交付使得服务使用情况可监控、控制和计费的特性。这个特性强调用户只为自己使用的服务付费,降低用户成本,为用户带来价值。
- 多租户。通过对物理或虚拟资源的分配保证多个租户以及他们的计算和数据彼此隔离和不可访问的特性。
- 按需自服务。客户能够根据自身的实际需求,自动或在最少交互的情况下,配置计算能力的特性。该特性降低了用户的时间成本和操作成本,实现了企业业务的快速实现、部署与应用,降低了企业信息系统的运维成本,提高了企业快速响应市场的能力。
- 快速的弹性和可扩展性。物理或虚拟资源能够快速、弹性,有时是自动化地供应,以达到快速增减资源目的的特性。
- 资源池化。将云服务提供者的物理或虚拟资源进行集成,以便服务于一个或多个云服务客户的特性。 该特性通过抽象对用户屏蔽了资源处理和分配的复杂性,用户无需知道资源是如何分布,如何分配的。
其他关键特征:虚拟化技术(应用虚拟和资源虚拟)、可靠性高、性价比高。
1.2 云计算分类
1)根据云部署模式和云应用范围分类
云计算常见的部署模式有公有云、社区云、私有云和混合云。
- 公有云。云的基础设施一般是被一个云计算服务提供商所拥有,该组织将云计算服务销售给公众,公有云通常在远离客户建筑物的地方托管(一般为云计算服务提供商建立的数据中心),可实现灵活的扩展,提供一种降低客户风险和成本的方法。
- 社区云。云的基础设施被一些组织共享,并为一个有共同关注点的社区服务(例如任务、安全要求、政策和遵守的考虑)。可以是该组织或某个第三方负责管理。
- 私有云。云的基础设施是为一个客户单独使用而构建的,因而提供对数据、安全性和服务质量的最有效控制。私有云可部署在企业数据中心中,也可部署在一个主机托管场所,被一个单一的组织拥有或租用。
- 混合云。基础设施是由两种或两种以上的云(私有、社区或公有)组成,每种云仍然保持独立,但用标准的或专有的技术将它们组合起来,具有数据和应用程序的可移植性(例如,可以用来处理突发负载),混合云有助于提供按需和外部供应方面的扩展。
2)根据云计算的服务层次和服务类型分类
根据云计算的服务类型可将云分为三层:基础设施即服务、平台即服务和软件即服务。
- 基础设施即服务(Infrastructure as a Service, Iaas),提供虚拟化计算资源,如虚拟机、存储、网络和操作系统。
- 平台即服务(Platform as a Service, PaaS),为开发人员提供通过全球互联网构建应用程序和服务的平台。Paas为开发、测试和管理软件应用程序提供按需开发环境。其核心技术是分布式并行计算。
- 软件即服务(Software as a Service, SaaS),通过互联网提供按需软件付费应用程序,云计算提供商托管和管理软件应用程序,并允许其用户连接到应用程序并通过互联网访问应用程序。
3)云关键技术
云核心的关键技术有虚拟化技术、分布式数据存储、并行计算、运营支撑管理等。
- 虚拟化或虚拟技术(Virtualization)是一种资源管理技术,是将计算机的各种实体资源(CPU、内存、磁盘空间、网络适配器等)予以抽象、转换后呈现出来,并可供分割、组合为一个或多个电脑配置环境。云计算中的虚拟化往往指的是系统虚拟化。
- 分布式数据存储技术包含非结构化数据存储和结构化数据存储。其中,非结构化数据存储主要采用文件存储和对象存储技术,而结构化数据存储主要采用分布式数据库技术,特别是NOSQL数据库。
- 并行计算,海量数据分布到多个结点上,将计算并行化,利用多机的计算资源,加快数据处理的速度。关键问题有
任务划分、任务调度和自动容错处理机制。 - 运营支撑管理,支持规模巨大的云计算环境,需要成千上万台服务器来支撑,那就需要运营支撑管理。注意因素有负载管理和监控、计量计费。
2.大数据处理基础知识
2.1 基础知识
大数据定义:大数据是具有数量巨大、来源多样、生成极快且多变等特征且难以使用传统数据体系结构有效处理的包含大量数据集的数据。
大数据的5V特征:
- Variet,多样性。数据类型繁多,除了结构化数据外,还包括种类繁多的非结构化数据,例如文本、音频、视频、文件记录等,也包括半结构化数据,例如 Email、word、ppt 文档等。
- Velocity,速度。一方面是数据的增长速度快,另一方面是要求数据访问、处理、交付的速度快,通常要求具有时效性。
- Volume,数量。聚合在一起供分析的数据规模非常庞大。各种业务系统产生的数据量急剧增长。
- Value,价值。从海量低价值密度的数据中挖掘出具有高价值的数据。本质是获取数据价值,关键在于商业价值,即如何有效利用好数据。
- Veracity,真实性。一方面,对于虚拟网络环境下如此大量的数据需要采取措施确保其真实性、客观性,这是大数据技术与业务发展的迫切需求;另一方面,通过大数据分析,真实地还原和预测事物的本来面目也是大数据未来发展的趋势。
2.3 大数据处理技术
大数据处理的基本流程包括:数据采集、数据分析和数据解释。
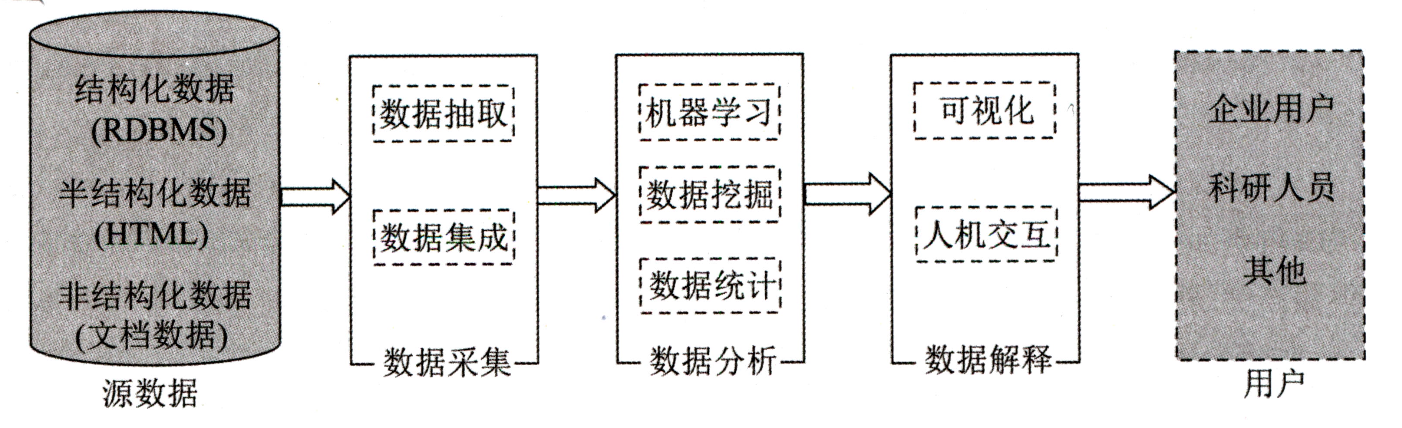
1)数据采集
数据采集阶段的主要任务就是获取各个不同数据源的各类数据,按照统一的标准进行数据的转换、清洗等工作,以形成后续数据处理的符合标准要求的数据集。
ETL(Extract Transform Load)用来描述将数据从来源端经过抽取 (extract)、转换 (transform)、加载(load)至目的端的过程。目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据。
常用的ETL工具有三种:DataStage、Informatica PowerCenter和Kettle。
- DataStage: IBM公司的DataStage是一种数据集成软件平台,专门针对多种数据源的ETL过程进行了简化和自动化,同时提供图形框架,用户可以使用该框架来设计和运行用于变换和清理、加载数据的作业。它能够处理的数据源有主机系统的大型数据库、开发系统上的关系数据库和普通的文件系统。
- Informatica PowerCenter: Informatica公司开发的为满足企业级需求而设计的企业数据集成平台。可以支持各类数据源,包括结构化、半结构化和非结构化数据。提供丰富的数据转换组件和工作流支持。
- Kettle: Kettle是一款国外开源的ETL工具,纯Java编写,可以在 Windows、Linux、UNIX 上运行,数据抽取高效稳定。管理来自不同数据库的数据,提供图形化的操作界面,提供工作流支持。
爬虫技术也称为数据采集阶段的一个主要基础性的技术。网络爬虫(又称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取互联网信息的程序或者脚本。

爬虫调度器主要负责统筹其他四个模块的协调工作。URL管理器负责管理URL链接,维护已经爬取的URL集合和未爬取的URL集合,提供获取新URL链接的接口。HTML下载器用于从URL管理器中获取未爬取的URL链接并下载HTML网页。HTML解析器用于从HTML下载器中获取已经下载的HTML网页,并从中解析出新的URL链接交给URL管理器,解析出有效数据交给数据存储器。
网络爬虫大致可以分为通用网络爬虫、聚焦网络爬虫、深层网络(Deep Web)爬虫:
- 通用网络爬虫,爬行对象从一些种子URL扩充到整个Web,主要为门户站点搜索引擎和大型Web服务提供商采集数据。
- 聚焦网络爬虫,是指选择性地爬行那些与预先定义好的主题相关页面的网络爬虫。
- 深层网络爬虫用于专门爬取那些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户提交一些关键词才能获得的Web页面。
常见的爬虫工具:
- Nutch:一个开源Java实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。Nutch有Hadoop支持,可以进行分布式抓取、存储和索引。Nutch采用插件结构设计,高度模块化,容易扩展。
- Scrapy:是Python开发的一个快速、高层次的屏幕抓取和Web抓取框架,用于抓取Web站点并从页面中提取结构化的数据。
- Larbin:Larbin是一种开源的网络爬虫/网络蛛,用C++语言实现。Larbin目的是能够跟踪页面的URL进行扩展的抓取,最后为搜索引擎提供广泛的数据来源。
2)数据分析
机器学习一般分为监督学习和非监督学习(或无监督学习)。
监督学习是指利用一组已知类别的样本调整分类器的参数,使其达到所要求性能的过程,也称为监督训练,是从标记的训练数据来推断一个功能的机器学习任务。根据训练集中的标识是连续的还是离散的,可以将监督学习分为回归和分类。
- 回归是研究一个或一组随机变量对一个或一组属性变量的相依关系的统计分析方法。线性回归模型是假设自变量和因变量满足线性关系。Logistic 回归一般用于分类问题,而其本质是线性回归模型,只是在回归的连续值结果上加了一层函数映射。
- 分类是机器学习中的一个重要问题,其过程也是从训练集中建立因变量和自变量的映射过程,与回归问题不同的是,分类问题中因变量的取值是离散的,根据因变量的取值范围,可将分类问题分为二分类问题、三分类问题和多分类问题。根据分类采用的策略和思路的不同,分类算法大致包括:
- 基于示例的分类方法,如K最近邻(K-Nearest Neighbor,KNN)方法;
- 基于概率模型的分类方法,如朴素贝叶斯、最大期望算法EM等;
- 基于线性模型的分类方法,如SVM;基于决策模型的分类方法,如C4.5、AdaBoost、随机森林等。
无监督学习是根据类别未知(没有被标记)的训练样本解决模式识别中的各种问题。常见的算法有:关联规则挖掘,是从数据背后发现事物之间可能存在的关联或联系。比如数据挖掘领域著名的“啤酒-尿不湿”的故事。K-means算法,基本思想是两个对象的距离越近,其相似度越大;相似度接近的若干对象组成一个簇;算法的目标是从给定数据集中找到紧凑且独立的簇。
深度学习算法是基于神经网络发展起来的,包括BP神经网络、深度神经网络。
- BP神经网络是一种反向传播的前馈神经网络,所谓前馈神经网络就是指各神经元分层排列,每个神经元只与前一层的神经元相连,接收前一层的输出,并输出给下一层。所谓反向传 播是指从输出层开始沿着相反的方向来逐层调整参数的过程。BP神经网络由输入层、隐含层和输出层组成。
- 深度神经网络主要包括卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurrent Neural Network,RNN)等。
3)数据解释
数据解释的主要工作是对大数据处理后产生的输出数据进行处理,采用合理合适的人机交互方式将结果展现给用户,帮助用户做出相应的决策。
信息可视化是指对抽象数据使用计算机支持的、交互的、可视化的表示形式以增强认知能力。为了清晰有效地传递信息,数据可视化使用统计图形、图表、信息图表和其他工具。可以使用点、线或条对数字数据进行编码,以便在视觉上传达定量信息。有效的可视化可以帮助用户分析和推理数据和证据。它使复杂的数据更容易理解和使用。用户可能有特定的分析任务 (如进行比较或理解因果关系),以及该任务要遵循的图形设计原则。
常见的大数据可视化工具主要分为三类:底层程序框架,如OpenGL、Java2D等;第三方库,如D3、ECharts、HighCharts、Google ChartAPI等;软件工具,如Tableau、Gephi等。