文章目录
- 🍃前言
- 🎋命令介绍
- 🚩hset
- 🚩hget
- 🚩hexists
- 🚩hdel
- 🚩hkeys
- 🚩hvals
- 🚩hgetall
- 🚩hmget
- 🚩hlen
- 🚩hsetnx
- 🚩hincrby
- 🚩hincrbyfloat
- 🌳命令小结
- 🌲内部编码
- 🎍使用场景
- 🚩做为缓存
- ⭕总结
🍃前言
⼏乎所有的主流编程语⾔都提供了哈希(hash)类型,它们的叫法可能是哈希、字典、关联数组、映射。
在 Redis 中,哈希类型是指值本⾝⼜是⼀个键值对结构,形如
key = "key",value = { { field1, value1 }, ..., {fieldN, valueN } }
Redis 键值对和哈希类型⼆者的关系可以下图表示:

哈希类型中的映射关系通常称为 field-value,⽤于区分 Redis 整体的键值对(key-value),注意这⾥的 value 是指field 对应的值,不是键(key)对应的值,请注意 value 在不同上下⽂的作⽤
下面我将从以下三个方面对哈希类型进行介绍:
- 哈希类型常用命令
- 哈希类型的内部编码
- 哈希类型的使用场景
🎋命令介绍
🚩hset
设置 hash 中指定的字段(field)的值(value)。
语法如下:
hset key field value [field value ...]
时间复杂度:
- 插⼊⼀组 field 为 O(1), 插⼊ N 组 field 为 O(N)
返回值:
- 添加的字段的个数

🚩hget
获取hash中指定字段的值
语法:
hget key field
时间复杂度:
- O(1)
返回值:
- 字段对应的值或者 nil

🚩hexists
判断 hash 中是否有指定的字段。
语法:
hexists key field
时间复杂度:
- O(1)
返回值:
- 1 表⽰存在,0 表⽰不存在。

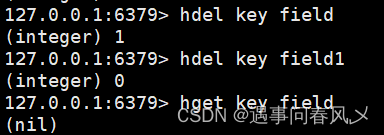
🚩hdel
删除 hash 中指定的字段
语法:
hdel key field [field ...]
时间复杂度:
- 删除⼀个元素为 O(1). 删除 N 个元素为 O(N).
返回值:
- 本次操作删除的字段个数
🚩hkeys
获取 hash 所有字段
语法:
hkeys key
时间复杂度:
- O(N), N 为 field 的个数.
返回值:
- 字段列表。

🚩hvals
获取 hash 中的所有的值
语法:
hvals key
时间复杂度:
- O(N),N 为 field 的个数.
返回值:
- 所有的值

🚩hgetall
获取 hash 中的所有字段以及对应的值
语法:
hgetall key
时间复杂度:
- O(N), N 为 field 的个数.
返回值:
- 字段和对应的值。

🚩hmget
⼀次获取 hash 中多个字段的值
语法:
hmget key field [field ...]
时间复杂度:
- 只查询⼀个元素为 O(1), 查询多个元素为 O(N), N 为查询元素个数.
返回值:
- 字段对应的值或者nil。

🚩hlen
获取 hash 中的所有字段的个数。
语法:
hlen key

🚩hsetnx
在字段不存在的情况下,设置 hash 中的字段和值。
语法:
hsetnx key field value
时间复杂度:
- O(1)
返回值:
- 1表⽰设置成功,0表⽰失败。

🚩hincrby
将 hash 中字段对应的数值添加指定的值
语法:
hincrby key field increment
时间复杂度:
- O(1)
返回值:
- 该字段变化之后的值

🚩hincrbyfloat
hincrby的浮点数版本
语法:
hincrbyfloat key field increment
时间复杂度:
- O(1)
返回值:
- 该字段变化之后的值
🌳命令小结
| 命令 | 执⾏效果 | 时间复杂度 |
|---|---|---|
| hset key field value | 设置值 | O(1) |
| hget key field | 获取值 O(1) | |
| hdel key field [field …] | 删除 field | O(k), k 是 field个数 |
| hlen key | 计算 field 个数 | O(1) |
| hgetall key | 获取所有的 field-value | O(k), k 是 field个数 |
| hmget field [field …] | 批量获取 field-value | O(k),k是field个数 |
| hmset field value [field value…] | 批量获取 field-value | O(k), 个数 k 是 field |
| hexists key field | 判断 field 是否存在 | O(1) |
| hkeys key | 获取所有的 field | O(k), k 是 field个数 |
| hvals key | 获取所有的 value | O(k), k 是 field个数 |
| hsetnx key field value | 设置值,但必须在 field 不存在时才能设置成功 | O(1) |
| hincrby key field n | 对应field-value +n | O(1) |
| hincrbyfloat key field n | 对应 field-value +n | O(1) |
| hstrlen key field | 计算 value 的字符串⻓度 | O(1) |
🌲内部编码
哈希的内部编码有两种:
-
ziplist(压缩列表):当哈希类型元素个数⼩于 hash-max-ziplist-entries 配置(默认 512 个)、同时所有值都⼩于 hash-max-ziplist-value 配置(默认 64 字节)时,Redis 会使⽤ ziplist 作为哈希的内部实现,ziplist 使⽤更加紧凑的结构实现多个元素的连续存储,所以在节省内存⽅⾯⽐ hashtable更加优秀。
-
hashtable(哈希表):当哈希类型⽆法满⾜ ziplist 的条件时,Redis 会使⽤ hashtable 作为哈希的内部实现,因为此时 ziplist 的读写效率会下降,⽽hashtable 的读写时间复杂度为O(1)。
🎍使用场景
🚩做为缓存
比如我们有一个关系型数据表记录的两条⽤⼾信息,⽤⼾的属性表现为表的列,每条⽤⼾信息表现为⾏。我们如何映射这两条用户的信息呢?

映射关系如下:

相⽐于使⽤ JSON 格式的字符串缓存⽤⼾信息,哈希类型变得更加直观,并且在更新操作上变得更灵活。可以将每个⽤⼾的 id 定义为键后缀,多对field-value对应⽤⼾的各个属性。
那么有些人就说了,既然 redis 可以通过这些方式表示关系表,那么是不是就可以直接用 Redis 哈希来表示关系型数据库了呢?
需要注意的是哈希类型和关系型数据库有两点不同之处:
- 哈希类型是稀疏的,⽽关系型数据库是完全结构化的,例如哈希类型每个键可以有不同的 field,⽽关系型数据库⼀旦添加新的列,所有⾏都要为其设置值,即使为 null。
- 关系数据库可以做复杂的关系查询,⽽ Redis 去模拟关系型复杂查询,例如联表查询、聚合查询等基本不可能,维护成本⾼
⭕总结
关于《【Redis】 哈希类型》就讲解到这儿,感谢大家的支持,欢迎各位留言交流以及批评指正,如果文章对您有帮助或者觉得作者写的还不错可以点一下关注,点赞,收藏支持一下









![[数组查找]1.图解线性查找及其代码实现](https://img-blog.csdnimg.cn/direct/849e0bba932747fe83a56d0aa18bad82.png)