Spark概述

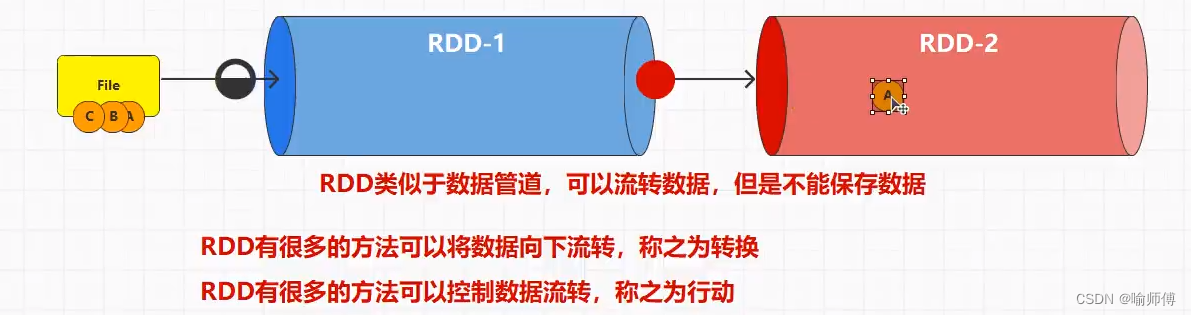
Spark-RDD概述
Spark RDD 提供了丰富的方法来对数据进行转换和操作。
对 RDD(Resilient Distributed Dataset)的操作可以分为两大类:转换算子(Transformations)和行动算子(Actions)。
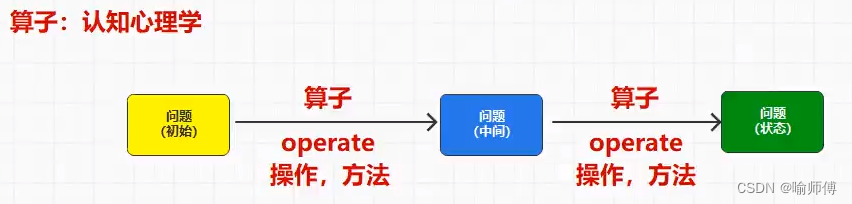
“算子”通常指代一种操作符号或函数,它用于对数据进行操作、处理或转换。
一.Transformation转换算子
- 转换算子是指对现有的RDD进行某种操作,生成一个新的RDD,但原有的RDD保持不变。
- 这些操作是惰性的,只有在遇到行动算子时才会真正被执行。
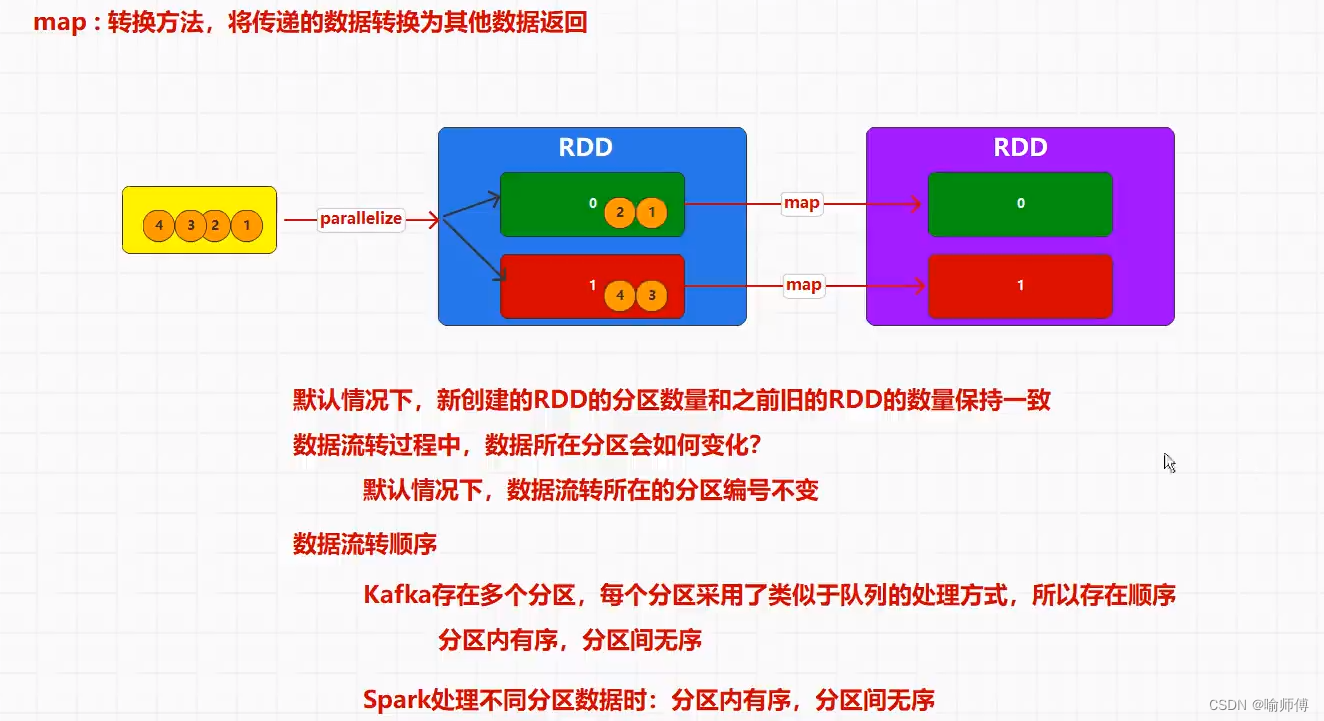
1.map(func)
map方法是RDD(Resilient Distributed Dataset)的一个转换操作,它允许对RDD中的每个元素应用一个函数,并返回一个新的RDD,其中包含应用函数后的结果.
JavaRDD<T> map(Function<T, R> f)
-
Function<T, R>:一个函数接口,定义了一个输入类型为T,输出类型为R的函数。 -
示例
假设有一个包含整数的RDD,我们想要对每个整数进行平方操作。
package com.yushifu.spark.rdd.func;import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.SparkConf;import java.util.Arrays;
import java.util.List;import org.apache.spark.api.java.function.Function;public class MapExample {public static void main(String[] args) {// 创建SparkConf对象SparkConf conf = new SparkConf().setAppName("MapExample").setMaster("local");// 创建JavaSparkContext对象JavaSparkContext sc = new JavaSparkContext(conf);// 创建一个包含整数的RDDJavaRDD<Integer> rdd = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5));// 使用map方法对RDD中的每个元素进行平方操作JavaRDD<Integer> squaredRDD = rdd.map(new Function<Integer, Integer>() {@Overridepublic Integer call(Integer x) throws Exception {return x * x;}});// 收集并打印转换后的RDDList<Integer> squaredList = squaredRDD.collect();for (Integer num : squaredList) {System.out.println(num);}// 关闭SparkContextsc.close();}
}

2.filter(func)
JavaRDD<T> filter(Function<T, Boolean> f)
JavaRDD:返回一个新的 JavaRDD,其中包含满足条件的元素。Function<T, Boolean>:用于对 RDD 中的每个元素进行评估的函数接口。这里的 T 表示 RDD 中元素的类型。该函数接受一个参数,代表 RDD 中的一个元素,返回一个布尔值,表示是否保留该元素。
工作原理:
- 对 RDD 中的每个元素应用给定的函数 func。
- 如果函数 func 返回 true,则将该元素保留在结果 RDD 中;否则,将其过滤掉。
- 示例:
假设有一个包含整数的 RDD,我们希望过滤出所有的偶数。
package com.yushifu.spark.rdd.func;import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;import java.util.Arrays;
import java.util.List;public class RDDFilterExample {public static void main(String[] args) {// 创建 SparkConf 并设置应用名称SparkConf conf = new SparkConf().setAppName("RDD Filter Example").setMaster("local[*]");// 创建 JavaSparkContext,它是 Spark 功能的入口点JavaSparkContext sc = new JavaSparkContext(conf);// 创建一个包含整数的 RDDList<Integer> data = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);JavaRDD<Integer> numbersRDD = sc.parallelize(data);// 使用 filter 方法过滤出所有的偶数JavaRDD<Integer> evenNumbersRDD = numbersRDD.filter(new EvenFilter());// 打印过滤后的结果List<Integer> evenNumbers = evenNumbersRDD.collect();for (Integer num : evenNumbers) {System.out.println(num);}// 停止 JavaSparkContextsc.stop();}// 自定义函数类,用于判断整数是否为偶数static class EvenFilter implements org.apache.spark.api.java.function.Function<Integer, Boolean> {public Boolean call(Integer num) {return num % 2 == 0;}}
}

3.flatMap(func)
flat-扁平化

对 RDD 中的每个元素应用函数 func,并将结果扁平化为一个新的 RDD。
flatMap方法和map方法类似,不同之处在于flatMap会将每个输入元素映射为一个或多个输出元素。
具体来说,flatMap会对输入RDD中的每个元素应用一个函数,然后将所有函数返回的元素合并成一个新的RDD。


JavaRDD<T> flatMap(Function<T, Iterator<R>> f)
-
Function<T, Iterator<R>> f: 表示接受类型为T的输入元素,返回一个Iterator<R>的函数。

-
示例
假设有一个包含字符串的RDD,现在我们想将每个字符串按空格分割,并返回分割后的单词:
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(new SparkConf().setAppName("FlatMapExample").setMaster("local"));// 创建一个包含字符串的RDD
JavaRDD<String> rdd = sc.parallelize(Arrays.asList("Hello World", "Spark FlatMap Example", "Java Programming"));// 使用flatMap对每个字符串按空格分割
JavaRDD<String> wordsRDD = rdd.flatMap(new FlatMapFunction<String, String>() {@Overridepublic Iterator<String> call(String s) throws Exception {return Arrays.asList(s.split(" ")).iterator();}
});// 输出结果
System.out.println(wordsRDD.collect());// 关闭JavaSparkContext
sc.close();
使用flatMap方法将每个字符串按空格分割为单词,并返回一个包含所有单词的新RDD。最终输出的结果是所有单词的集合。
通过flatMap方法,我们可以方便地处理需要将一个元素映射为多个元素的情况,比如将一行文本拆分为单词、将一组数据展开为多个数据等。
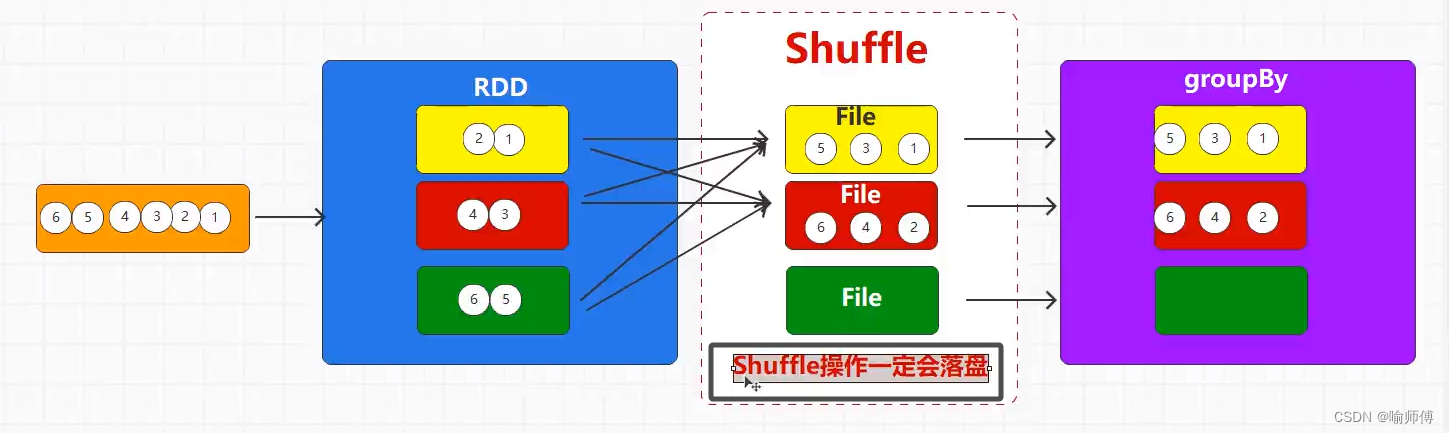
4.groupBy()
在Spark中,groupBy操作用于对RDD中的元素进行分组。
具体来说,它会将RDD中的元素按照指定的标准进行分组,并返回一个包含分组结果的RDD。
- 语法
JavaPairRDD<K, Iterable<V>> groupBy(Function<T, K> f)
-
Function<T, K> f: 表示接受类型为T的输入元素,返回类型为K的键值的函数。 -
示例
假设有一个包含整数的RDD,我们希望根据元素的奇偶性进行分组:
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(new SparkConf().setAppName("GroupByExample").setMaster("local"));// 创建一个包含整数的RDD
JavaRDD<Integer> rdd = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5, 6));// 根据元素的奇偶性进行分组
JavaPairRDD<String, Iterable<Integer>> groupedRDD = rdd.groupBy(new Function<Integer, String>() {@Overridepublic String call(Integer v1) throws Exception {return (v1 % 2 == 0) ? "even" : "odd";}
});// 输出分组结果
groupedRDD.collectAsMap().forEach((k, v) -> System.out.println(k + ": " + v));// 关闭JavaSparkContext
sc.close();





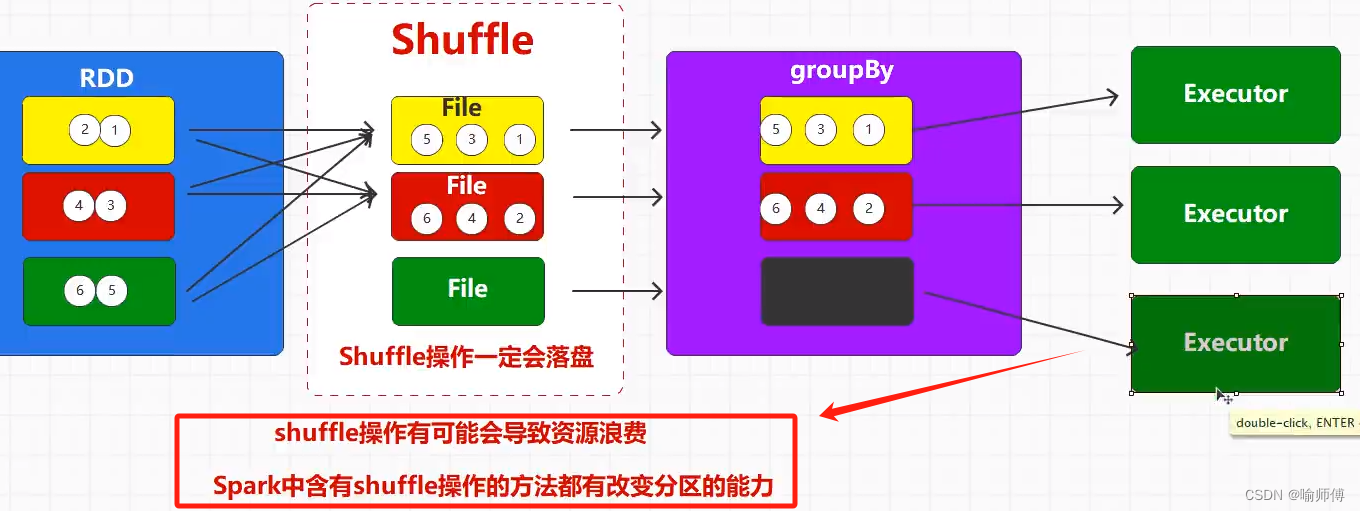
5.filter()
filter() 是 Apache Spark 中的一个转换操作,用于筛选 RDD 中的元素。它接受一个函数作为参数,这个函数决定了哪些元素会被保留下来,哪些会被过滤掉。在 Java 中,这个函数通常是一个实现了 Function 接口的匿名函数或 Lambda 表达式。
- 签名
JavaRDD<T> filter(Function<T, Boolean> f)
- 参数
f: 一个函数,接受类型为 T 的元素作为输入,并返回一个布尔值,表示该元素是否应该被保留。
- 返回值
一个新的 JavaRDD,其中包含通过筛选条件的元素。
- 功能解释
筛选元素: filter() 方法会对 RDD 中的每个元素应用给定的函数 f,如果函数返回 true,则该元素会被保留下来,否则会被过滤掉。
- 保留符合条件的元素:
函数 f 应该返回一个布尔值,表示元素是否应该被保留。如果返回 true,元素将保留在结果 RDD 中;如果返回 false,元素将被过滤掉。

- 示例
假设有一个 RDD 包含了一些整数,我们想要筛选出所有的偶数:
JavaRDD<Integer> numbers = ...; // 假设已经创建了包含整数的RDD
JavaRDD<Integer> evenNumbers = numbers.filter(x -> x % 2 == 0);
在这个示例中,我们使用 filter() 方法来保留所有满足条件 x % 2 == 0 的元素,即所有的偶数。
- 注意事项
(1)filter() 方法只能应用于包含元素的 RDD(JavaRDD),如果你的 RDD 是键值对形式的,你应该使用 filterByKey 或 filterValues 方法。
(2)函数 f 的评估是延迟的(lazy evaluation),只有在执行操作动作时才会真正进行计算。这意味着 filter() 只会在遍历 RDD 时应用过滤条件,而不会立即计算结果。
(3)filter() 不会改变原始 RDD,而是返回一个新的 RDD,其中包含满足过滤条件的。
6.distinct()
distinct() 是 Apache Spark 中的一个转换操作,用于从 RDD 中去除重复的元素,并返回一个包含唯一元素的新 RDD。这个操作对于需要进行去重的情况非常有用。
- 签名
JavaRDD<T> distinct()
- 参数
该方法不接受任何参数。
- 返回值
一个新的 JavaRDD,其中包含了去除了重复元素的结果。
- 功能解释
去除重复元素: distinct() 方法会对 RDD 中的元素进行去重操作,确保返回的 RDD 中不包含重复的元素。
保留唯一元素: 返回的 RDD 中每个元素都是唯一的,不会出现重复。
- 示例
假设有一个 RDD 包含了一些整数,我们想要去除其中的重复元素:
JavaRDD<Integer> numbers = ...; // 假设已经创建了包含整数的RDD
JavaRDD<Integer> uniqueNumbers = numbers.distinct();
在这个示例中,我们使用 distinct() 方法来生成一个新的 RDD,其中包含了原始 RDD 中的唯一元素,重复的元素被去除了。
- 注意事项
(1)distinct() 操作是一个转换操作,它并不会立即执行计算,而是在遇到动作操作时才会执行去重操作。
(2)原始 RDD 中元素的顺序不保证会被保留在结果 RDD 中,因为在分布式环境下,元素的去重可能会导致重新分区或重新排序。
(3)distinct() 操作可能会导致数据的重新分区,因为去重操作需要对数据进行全局排序或分组,以确保每个元素只出现一次。
(4)对于大规模的数据集,distinct() 操作可能会导致性能问题,因为它需要将所有数据进行全局排序或分组,以查找和删除重复的元素。

7.sortBy()
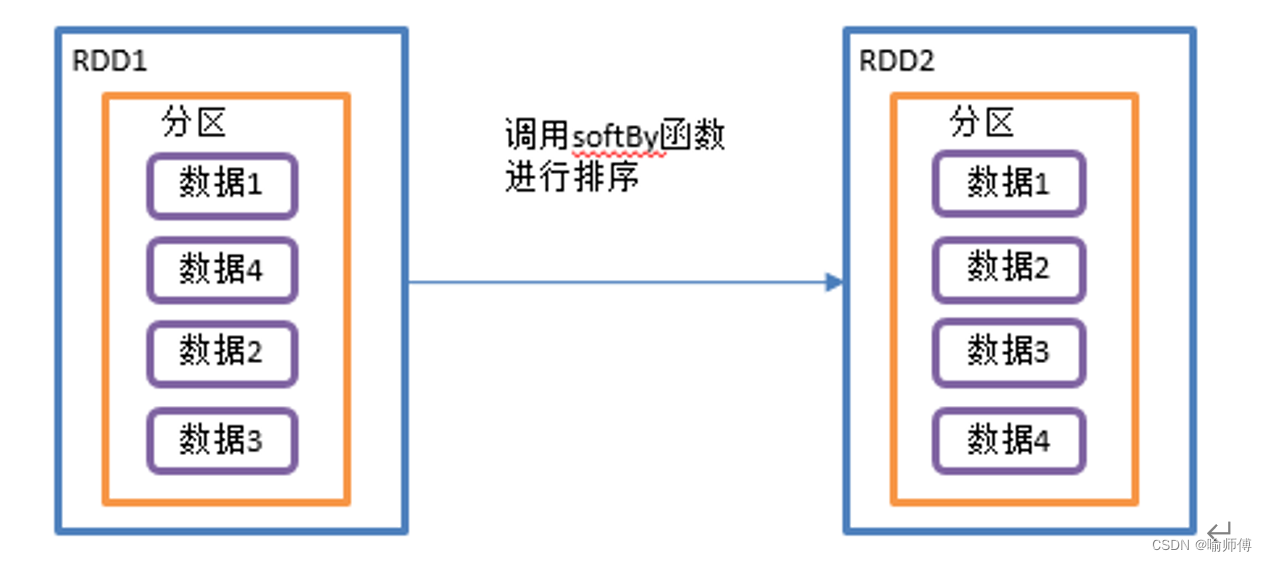
sortBy() 是 Apache Spark 中的一个转换操作,用于对 RDD 中的元素进行排序,并返回一个根据指定条件排序后的新 RDD。这个操作对于需要对数据进行排序的情况非常有用。
- 签名
JavaRDD<T> sortBy(Comparator<T> comp, boolean ascending, int numPartitions)
- 参数
comp:一个比较器,用于指定元素的比较规则。这个比较器用于确定元素的顺序。
ascending:一个布尔值,指定排序顺序。如果为 true,则升序排序;如果为 false,则降序排序。
numPartitions:一个整数,指定结果 RDD 的分区数.

- 返回值
一个新的 JavaRDD,其中包含根据指定比较器排序后的结果。
- 功能解释
排序元素: sortBy() 方法会根据指定的比较器对 RDD 中的元素进行排序。
指定排序顺序: 通过 ascending 参数,可以指定排序的顺序,可以是升序或者
降序。
控制分区数: 可以通过 numPartitions 参数控制结果 RDD 的分区数。如果不指定,默认情况下将使用原始 RDD 的分区数。
- 示例
假设有一个 RDD 包含了一些整数,对这些整数进行升序排序:
JavaRDD<Integer> numbers = ...; // 假设已经创建了包含整数的RDD
JavaRDD<Integer> sortedNumbers = numbers.sortBy((Integer num) -> num, true, numbers.getNumPartitions());
在这个示例中,我们使用 sortBy() 方法对 RDD 中的整数进行升序排序,并且保留了原始 RDD 的分区数。
- 注意事项
(1)sortBy() 操作是一个转换操作,它不会立即执行排序,而是在遇到动作操作时才会执行排序。
(2)比较器 comp 应该能够对 RDD 中的元素进行比较,以确定它们的顺序。比较器需要实现 Comparator 接口。
(3)对于大规模的数据集,sortBy() 操作可能会导致性能问题,因为它需要将所有数据进行全局排序,以便按照指定的排序顺序重新组织数据。
8.union(other)
union() 是 Apache Spark 中用于合并两个 RDD 的转换操作之一。
它将两个 RDD 中的元素合并为一个新的 RDD,而不去除任何重复的元素。
- 签名
JavaRDD<T> union(JavaRDD<T> other)
- 参数
other:另一个要合并的 RDD。
- 返回值
一个新的 JavaRDD,包含了两个 RDD 中所有元素的合并结果。
- 功能解释
合并元素: union() 方法将两个 RDD 中的元素合并到一个新的 RDD 中。
保留重复元素: 如果某个元素在两个 RDD 中都存在,它会在结果 RDD 中重复出现。
不去重: union() 不会去除重复的元素,如果需要去重,可以使用 distinct() 转换操作。
- 示例
假设有两个 RDD,分别包含了不同的整数:
JavaRDD<Integer> rdd1 = sc.parallelize(Arrays.asList(1, 2, 3, 4));
JavaRDD<Integer> rdd2 = sc.parallelize(Arrays.asList(3, 4, 5, 6));
JavaRDD<Integer> unionRDD = rdd1.union(rdd2);
在这个示例中,union() 方法将 rdd1 和 rdd2 中的整数合并到一个新的 RDD 中,结果为包含了所有元素的 unionRDD。
- 注意事项
(1)union() 操作是一个转换操作,它不会立即执行合并,而是在遇到动作操作时才会执行合并。
(2)合并操作会保留重复的元素,因此结果 RDD 中可能会包含重复的元素。
(3)对于大规模的数据集,union() 操作可能会导致性能问题,因为它需要将两个 RDD 中的所有数据进行合并,而不考虑元素是否重复。
9.sample(withReplacement, fraction, seed)
sample() 是 Apache Spark 中用于从 RDD 中随机抽样的转换操作之一。
从 RDD 中随机选择一部分元素作为样本,以便于对数据进行预览、测试或者简化处理。
- 签名
JavaRDD<T> sample(boolean withReplacement, double fraction)
JavaRDD<T> sample(boolean withReplacement, double fraction, long seed)
- 参数
withReplacement:一个布尔值,指定抽样时是否允许有放回抽样。如果为 true,则允许同一个元素被多次抽样,如果为 false,则不允许同一个元素被重复抽样。
fraction:一个介于 0 到 1 之间的 double 值,表示抽样的比例。例如,如果 fraction 为 0.1,则表示抽样 10% 的元素。
seed:一个长整型值,用于指定随机数生成器的种子,以便于复现抽样结果。
- 返回值
一个新的 JavaRDD,包含了从原始 RDD 中抽样得到的元素。
- 功能解释
随机抽样: sample() 方法从 RDD 中随机抽样一部分元素。
控制抽样比例: 通过指定 fraction 参数,可以控制抽样的比例,即从 RDD 中抽取的元素占 RDD 总元素的比例。
可选有放回抽样: 通过设置 withReplacement 参数为 true 或 false,可以选择是否允许有放回抽样。有放回抽样允许同一个元素被多次抽样,而无放回抽样则不允许。
可复现的随机性: 可以通过指定 seed 参数来控制随机数生成器的种子,以便于复现抽样结果。
- 示例
JavaRDD<Integer> rdd = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10));
JavaRDD<Integer> sampledRDD = rdd.sample(false, 0.5);
在这个示例中,sample() 方法从 rdd 中随机抽样,抽取的比例为 50%,并且不允许有放回抽样。结果将保存在 sampledRDD 中。
- 注意事项
(1)抽样操作是一个转换操作,它不会立即执行抽样,而是在遇到动作操作时才会执行抽样。
(2)抽样的结果可能会因为随机性而变化,特别是当有放回抽样时。
(3)通过设置种子 seed 参数,可以控制随机数生成器的种子,以便于复现相同的抽样结果。
10.mapValues()只对V进行操作
mapValues() 是在 Apache Spark 中用于对键值对 RDD 中的值进行映射转换的方法之一。
在不改变键的情况下,仅对每个键对应的值应用一个函数,从而生成一个新的键值对 RDD。

- 签名
JavaPairRDD<K, V2> mapValues(Function<V, V2> f)
- 参数
f:一个函数,接受键值对 RDD 中的值作为输入,并返回一个新的值。函数的类型为 Function<V, V2>,其中 V 是原始键值对 RDD 中的值的类型,而 V2 是新值的类型。
- 返回值
一个新的键值对 RDD,其中每个键值对的值都经过了函数 f 的映射转换。
- 功能解释
值的映射转换: mapValues() 方法对键值对 RDD 中的每个值应用给定的函数,从而生成一个新的键值对
RDD,键不变,只有值发生了变化。
键保持不变: 与 map() 方法不同,mapValues() 方法只对值进行映射转换,键保持不变。
- 示例
假设有一个键值对 RDD 包含了学生姓名和对应的成绩,我们想要将成绩加上 10 分:
JavaPairRDD<String, Integer> studentScores = sc.parallelizePairs(Arrays.asList(new Tuple2<>("Alice", 80),new Tuple2<>("Bob", 75),new Tuple2<>("Charlie", 90)
));JavaPairRDD<String, Integer> adjustedScores = studentScores.mapValues(score -> score + 10);
在这个示例中,mapValues() 方法被用于对学生的成绩进行调整,每个成绩都增加了 10 分,但是学生姓名保持不变。调整后的成绩保存在 adjustedScores 中。
- 注意事项
(1)mapValues() 是一个转换操作,它不会立即执行,而是在遇到动作操作时才会执行。
(2)与 map() 方法不同,mapValues() 只对值进行映射转换,键保持不变。
(3)由于只对值进行转换,mapValues() 在某些情况下比 map() 更高效,因为它避免了重新创建键。
11. groupByKey()按照K重新分组
将具有相同键的所有值聚合到一个集合中,生成一个新的键值对 RDD。
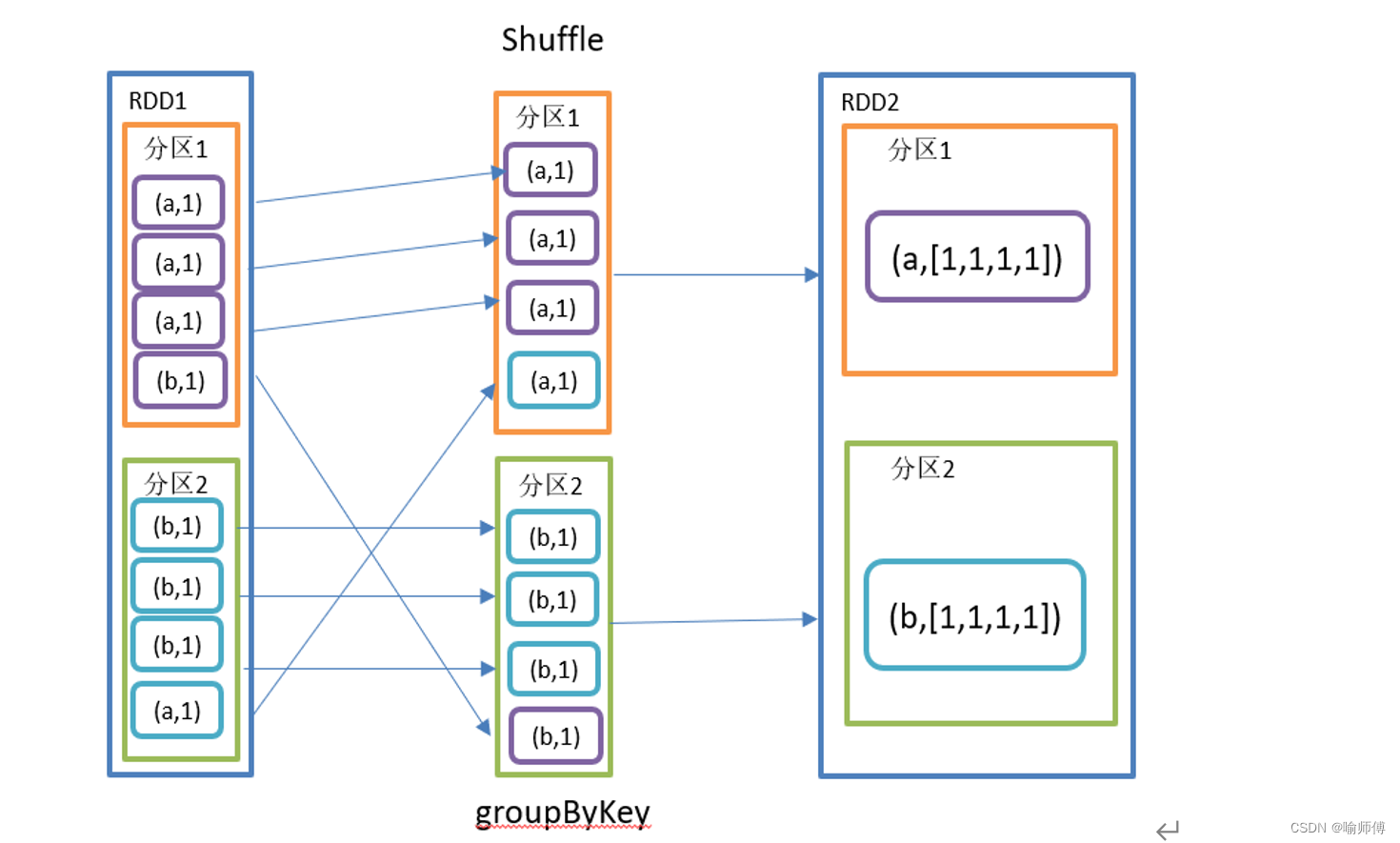
- 签名
JavaPairRDD<K, Iterable<V>> groupByKey()
- 返回值
一个新的键值对 RDD,其中每个键都对应一个 Iterable,包含具有相同键的所有值。
- 功能解释
按键分组: groupByKey() 方法根据键对 RDD 进行分组,将具有相同键的所有值聚合到一个 Iterable 中。
键的保持: 生成的新 RDD 中,键保持不变,而与之对应的值是一个 Iterable,其中包含具有相同键的所有原始值。
惰性计算: 与大多数 Spark 转换操作一样,groupByKey() 是惰性的,只有在遇到动作操作时才会执行。
- 示例
假设有一个键值对 RDD 包含了学生姓名和对应的科目成绩,我们想要按学生姓名将成绩进行分组:
JavaPairRDD<String, Integer> studentScores = sc.parallelizePairs(Arrays.asList(new Tuple2<>("Alice", 80),new Tuple2<>("Bob", 75),new Tuple2<>("Alice", 90),new Tuple2<>("Charlie", 85)
));JavaPairRDD<String, Iterable<Integer>> groupedScores = studentScores.groupByKey();
在这个示例中,groupByKey() 方法被用于按学生姓名将成绩进行分组,生成了一个新的键值对 RDD groupedScores,其中每个键是学生姓名,对应的值是一个 Iterable,包含该学生所有的成绩。
- 注意事项
(1)groupByKey() 会将具有相同键的所有值都聚合到一个 Iterable 中,这可能导致内存使用问题,特别是当某些键对应的值很多时。
(2)在使用 groupByKey() 时,应该考虑数据分布是否均匀,以避免某些键对应的值过多而导致性能问题。
(3)在大多数情况下,应该优先使用 reduceByKey()、aggregateByKey() 或 combineByKey() 等更高效的聚合操作来替代 groupByKey()。
12.reduceByKey()按照K聚合V

- 方法签名和参数
reduceByKey() 方法属于 JavaPairRDD 类,它的方法签名如下:
JavaPairRDD<K, V> reduceByKey(Function2<V, V, V> func, int numPartitions)
- func:用于对值进行聚合的函数,它接受两个相同类型的参数,并返回一个相同类型的结果。
- numPartitions:(可选)指定结果 RDD 的分区数。
- 工作原理
reduceByKey() 方法的工作原理可以概括为以下几个步骤:
(1)分区数据:如果指定了 numPartitions,Spark 将根据该值对数据进行分区,这有助于并行处理数据。
(2)局部聚合:在每个分区上,Spark 首先对具有相同键的值对进行局部聚合。这是通过将键值对分组,并对每个组应用指定的聚合函数来实现的。
(3)全局聚合:随后,Spark 将每个分区的局部聚合结果合并为全局聚合结果。这一步是在各个分区间进行的数据交换和合并,最终得到每个键对应的单个结果。
- 示例
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;import java.util.Arrays;
import java.util.List;public class ReduceByKeyExample {public static void main(String[] args) {// 创建 SparkContextJavaSparkContext sc = new JavaSparkContext("local", "reduceByKeyExample");// 创建一个包含键值对的 JavaPairRDDList<Tuple2<String, Integer>> data = Arrays.asList(new Tuple2<>("A", 1),new Tuple2<>("B", 2),new Tuple2<>("A", 3),new Tuple2<>("B", 4),new Tuple2<>("A", 5));JavaPairRDD<String, Integer> rdd = sc.parallelizePairs(data);// 使用 reduceByKey() 方法计算每个键对应的值的总和JavaPairRDD<String, Integer> result = rdd.reduceByKey((x, y) -> x + y);// 输出结果result.foreach(pair -> System.out.println(pair._1() + ": " + pair._2()));// 关闭 SparkContextsc.stop();}
}
使用 reduceByKey() 方法对一个包含键值对的 RDD 进行聚合操作,计算每个键对应的值的总和。
Lambda 表达式 (x, y) -> x + y 用于将具有相同键的值相加,然后得到每个键的聚合结果。
- 注意事项
(1)传递给 reduceByKey() 方法的函数必须是可交换和可结合的,以确保在分布式环境中正确执行。
(2)如果不需要指定结果 RDD 的分区数,可以使用 reduceByKey(Function2<V, V, V> func) 的重载方法。
- reduceByKey和groupByKey区别
(1)reduceByKey:按照key进行聚合,在shuffle之前有combine(预聚合)操作,返回结果是RDD[K,V]。
(2)groupByKey:按照key进行分组,直接进行shuffle。
(3)开发指导:在不影响业务逻辑的前提下,优先选用reduceByKey。求和操作不影响业务逻辑,求平均值影响业务逻辑。影响业务逻辑时建议先对数据类型进行转换再合并。
13.sortByKey()按照K进行排序
根据键(Key)的自然顺序或者自定义的排序规则对RDD中的键值对进行排序,并返回一个新的排序后的RDD。
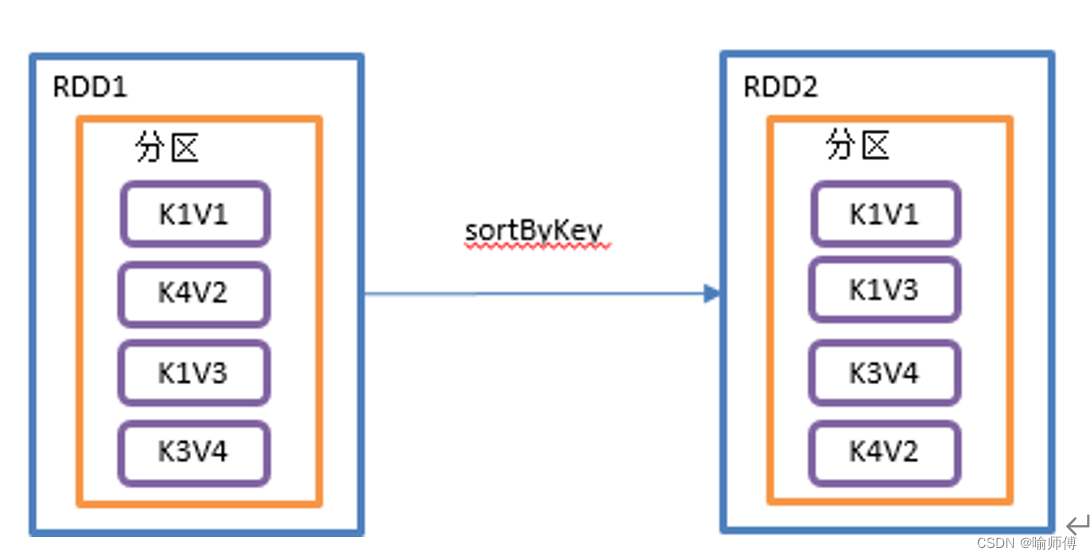
- 方法签名和参数
sortByKey()方法属于JavaPairRDD类,其方法签名如下:
JavaPairRDD<K, V> sortByKey(boolean ascending, int numPartitions)
ascending:一个布尔值,指示排序顺序,true表示升序,false表示降序。
numPartitions:(可选)指定结果RDD的分区数。
- 工作原理
(1)分区数据:如果指定了numPartitions,Spark将根据该值对数据进行分区,以便并行处理。
(2)按键排序:对RDD中的键值对按照键进行排序。如果ascending为true,则按照升序排列,如果为false,则按照降序排列。
(3)合并排序:在排序完成后,Spark将各个分区的排序结果进行合并排序,从而得到全局排序的结果。
- 示例
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;import java.util.Arrays;
import java.util.List;public class SortByKeyExample {public static void main(String[] args) {// 创建 SparkContextJavaSparkContext sc = new JavaSparkContext("local", "sortByKeyExample");// 创建一个包含键值对的 JavaPairRDDList<Tuple2<Integer, String>> data = Arrays.asList(new Tuple2<>(5, "E"),new Tuple2<>(3, "C"),new Tuple2<>(1, "A"),new Tuple2<>(4, "D"),new Tuple2<>(2, "B"));JavaPairRDD<Integer, String> pairRDD = sc.parallelizePairs(data);// 使用 sortByKey() 方法对 Pair RDD 中的键进行升序排序JavaPairRDD<Integer, String> sortedPairRDD = pairRDD.sortByKey(true, 1);// 输出排序后的结果List<Tuple2<Integer, String>> sortedData = sortedPairRDD.collect();System.out.println("Sorted data: " + sortedData);// 关闭 SparkContextsc.stop();}
}
这个示例演示了如何使用sortByKey()方法对一个包含整数作为键的Pair RDD进行升序排序。最终得到的结果是按照键的升序排列的键值对列表。
- 注意事项
(1)与sortBy()方法不同,sortByKey()方法只能用于键值对RDD(Pair RDD)。
(2)默认情况下,sortByKey()方法使用键的自然顺序进行排序。如果需要自定义排序规则,可以使用sortByKey(Comparator comp, boolean ascending)方法。
(3)如果不需要指定结果RDD的分区数,可以使用sortByKey(boolean ascending)的重载方法。
二.Action行动算子
行动算子是指对RDD执行计算并返回结果到驱动程序(Driver Program)中,触发实际的计算过程。行动算子会触发Spark作业的执行。
1.collect()
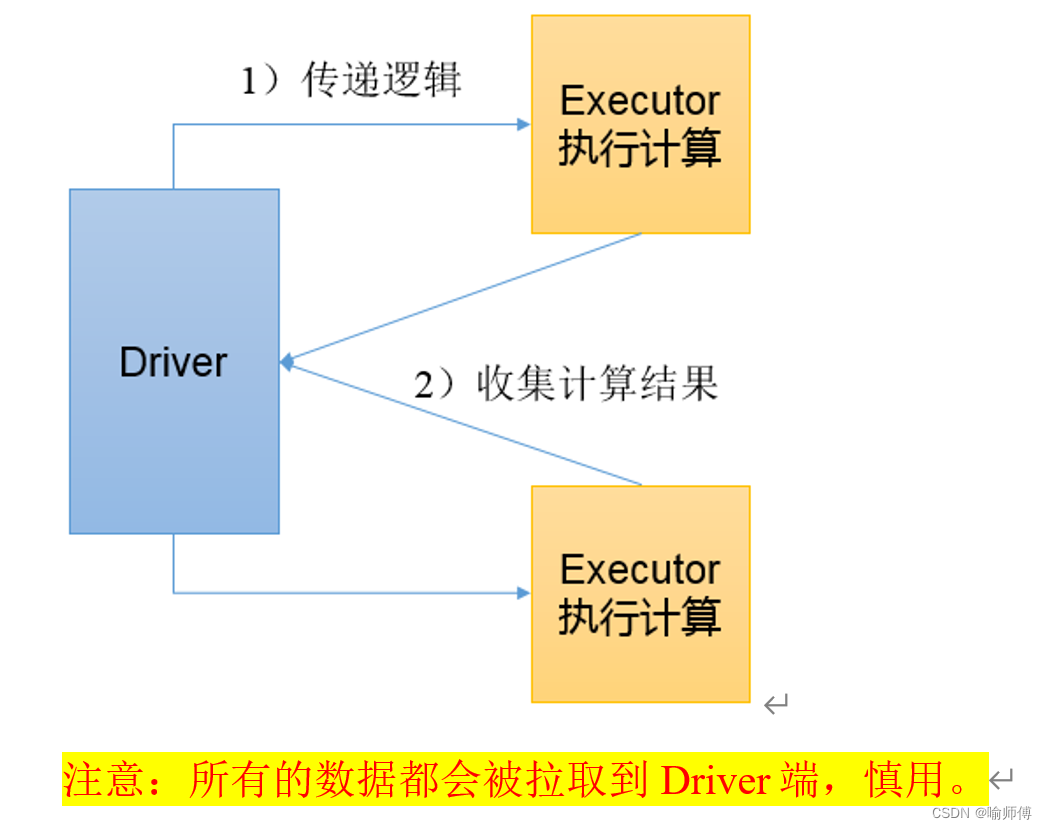
collect()是Apache Spark中的一个动作(action),用于将RDD中的数据收集到驱动节点(Driver Node)上,并以数组的形式返回给驱动程序(Driver Program)。
这个操作会触发Spark的计算,因此在大规模数据集上使用时需要谨慎,因为它会将所有数据都传输到驱动节点,可能导致内存不足或性能问题。
- 方法签名和参数
List<T> collect()
- 工作原理
(1)驱动程序请求:当调用collect()方法时,驱动程序会发送请求到集群上的各个执行节点(Executor Nodes)。
(2)数据收集:各个执行节点上的数据被收集到驱动程序所在的节点上。
(3)数据组装:收集到的数据被组装成一个数组,并返回给调用collect()方法的程序。
- 示例
使用collect()方法将RDD中的数据收集到驱动节点上:
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;import java.util.List;public class CollectExample {public static void main(String[] args) {// 创建 SparkContextJavaSparkContext sc = new JavaSparkContext("local", "collectExample");// 创建一个包含整数的RDDJavaRDD<Integer> rdd = sc.parallelize(List.of(1, 2, 3, 4, 5));// 使用 collect() 方法将数据收集到驱动节点上List<Integer> collectedData = rdd.collect();// 输出收集到的数据System.out.println("Collected data: " + collectedData);// 关闭 SparkContextsc.stop();}
}
- 注意事项
(1)collect()操作会将所有数据传输到驱动节点上,因此仅适用于数据量较小的情况。对于大规模数据集,应该谨慎使用,以避免内存不足或性能问题。
(2)如果数据集很大,而驱动节点的内存有限,则可能会导致内存溢出或驱动节点崩溃。
在调试和小规模数据集上进行试验时,collect()是一个有用的工具,但在生产环境中,应该避免在大规模数据集上使用它。
2.count()
count()是Apache Spark中的一个动作(action),用于计算RDD中元素的数量。这个操作会触发Spark的执行,并返回RDD中元素的总数。
- 方法签名和参数
long count()
- 工作原理
(1)分布式计算:当调用count()方法时,Spark会在集群的各个执行节点上并行地计算RDD中元素的数量。
(2)局部计数:每个执行节点上的局部计数结果会被发送到驱动节点。
(3)总计数:驱动节点将收到的局部计数结果相加,得到RDD中元素的总数,并返回给调用count()方法的程序。
- 示例
使用count()方法计算RDD中元素的数量:
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;public class CountExample {public static void main(String[] args) {// 创建 SparkContextJavaSparkContext sc = new JavaSparkContext("local", "countExample");// 创建一个包含整数的RDDJavaRDD<Integer> rdd = sc.parallelize(List.of(1, 2, 3, 4, 5));// 使用 count() 方法计算RDD中元素的数量long count = rdd.count();// 输出计数结果System.out.println("Count: " + count);// 关闭 SparkContextsc.stop();}
}
- 注意事项
(1)count()操作会触发Spark的执行,并且需要遍历整个RDD来计算元素的数量。因此,在大规模数据集上使用时需要注意性能。
(2)如果RDD中的数据量非常大,count()操作可能会耗费较长的时间。
(3)在分布式计算环境下,count()操作是一个开销较大的动作,因为它需要协调各个执行节点上的计数结果。
(4)尽管count()操作提供了RDD中元素的准确数量,但在大规模数据集上执行时需要谨慎,可以考虑使用近似计数算法(如HyperLogLog算法)来加速计数过程。
3.first():返回 RDD 中的第一个元素。
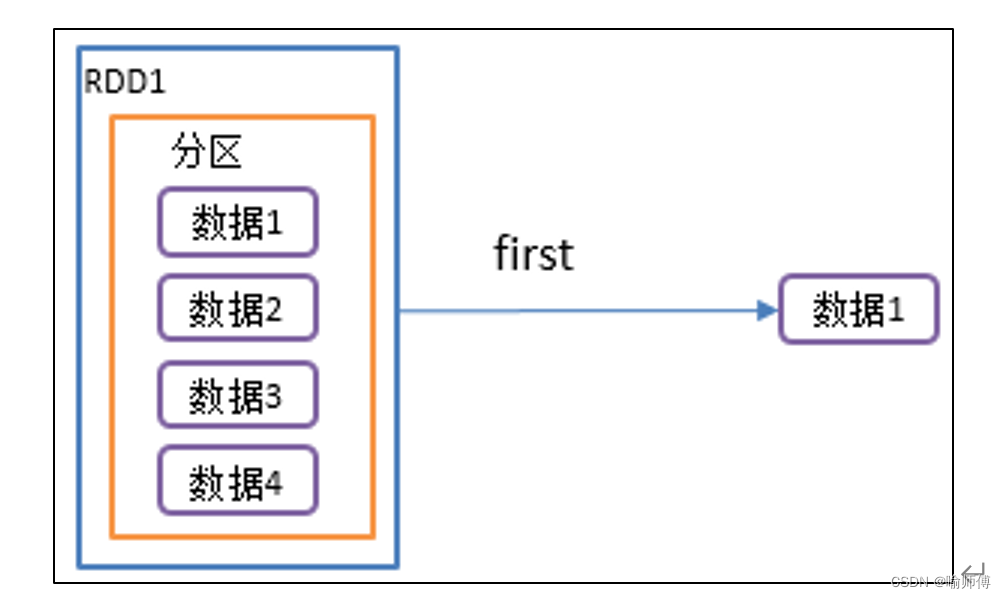
first()是Apache Spark中的一个动作(action),用于获取RDD中的第一个元素。这个操作会触发Spark的执行,并返回RDD中的第一个元素。
- 方法签名和参数
T first()
其中,T表示RDD中元素的类型。
- 工作原理
(1)分布式计算:当调用first()方法时,Spark会在集群的各个执行节点上并行地获取RDD中的数据。
(2)获取第一个元素:Spark会从RDD的分区中获取第一个元素,并返回给调用first()方法的程序。通常情况下,它会选择第一个分区中的第一个元素作为RDD的第一个元素。
(3)返回结果:获取到第一个元素后,Spark会将其返回给调用first()方法的程序。
- 示例
使用first()方法获取RDD中的第一个元素:
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;public class FirstExample {public static void main(String[] args) {// 创建 SparkContextJavaSparkContext sc = new JavaSparkContext("local", "firstExample");// 创建一个包含字符串的RDDJavaRDD<String> rdd = sc.parallelize(List.of("apple", "banana", "orange", "grape"));// 使用 first() 方法获取RDD中的第一个元素String firstElement = rdd.first();// 输出第一个元素System.out.println("First element: " + firstElement);// 关闭 SparkContextsc.stop();}
}
- 注意事项
(1)first()操作会触发Spark的执行,并且需要获取RDD的第一个元素。因此,在大规模数据集上使用时需要注意性能。
(2)如果RDD中没有元素,调用first()方法会抛出NoSuchElementException异常。因此,在调用first()方法之前,最好使用isEmpty()方法检查RDD是否为空。
(3)在分布式计算环境下,first()操作会选择第一个分区中的第一个元素作为RDD的第一个元素。因此,如果RDD的分区顺序发生变化,可能会导致不同的元素被选为第一个元素。
4.take(n):返回 RDD 中的前 n 个元素。

take(n)是Apache Spark中的一个动作(action),用于获取RDD中的前n个元素,并将它们返回为一个数组。
这个操作不会触发完整的RDD计算,而是只获取所需数量的元素。
- 方法签名和参数
List<T> take(int n)
其中,T表示RDD中元素的类型,n表示要获取的元素数量。
- 工作原理
(1)分布式计算:当调用take(n)方法时,Spark会并行地在集群的各个执行节点上获取RDD中的元素。
(2)获取前n个元素:Spark会从RDD的分区中获取前n个元素,并将它们组合成一个数组。
(3)返回结果:获取到前n个元素后,Spark会将这些元素组成的数组返回给调用take(n)方法的程序。
- 示例
使用take(n)方法获取RDD中的前三个元素:
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;import java.util.List;public class TakeExample {public static void main(String[] args) {// 创建 SparkContextJavaSparkContext sc = new JavaSparkContext("local", "takeExample");// 创建一个包含整数的RDDJavaRDD<Integer> rdd = sc.parallelize(List.of(1, 2, 3, 4, 5, 6));// 使用 take(n) 方法获取RDD中的前三个元素List<Integer> elements = rdd.take(3);// 输出前三个元素System.out.println("First 3 elements: " + elements);// 关闭 SparkContextsc.stop();}
}
- 注意事项
(1)take(n)操作会返回一个包含RDD中前n个元素的数组,这意味着它会拉取部分数据但不会触发完整的计算。
(2)如果RDD中的元素不足n个,take(n)方法会返回RDD中所有的元素。
与first()不同,take(n)方法可以获取RDD中的前n个元素,而不仅仅是第一个元素。
5.countByKey()统计每种key的个数
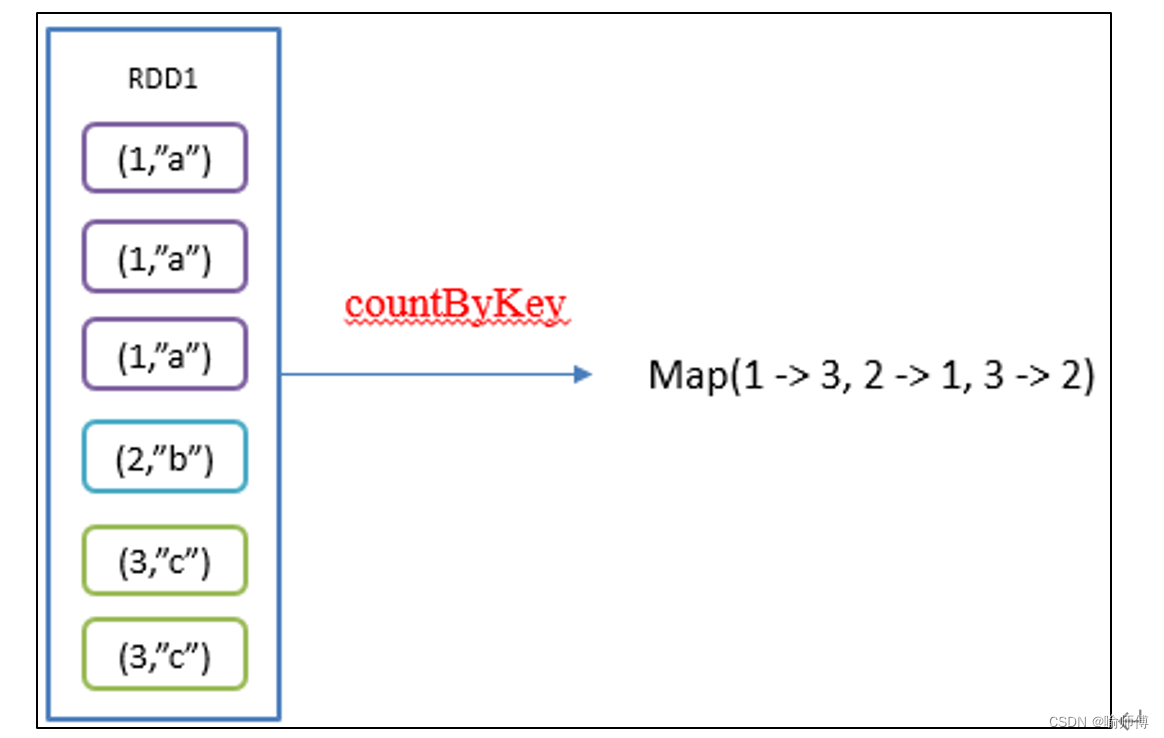
countByKey()是Apache Spark中的一个动作(action),用于对RDD中的键值对进行计数。
这个操作仅适用于RDD中的元素是键值对(key-value pairs)的情况,它返回一个由键和对应计数值组成的Map。
- 方法签名和参数
Map<K, Long> countByKey()
其中,K表示键的类型,Long表示计数的类型。该方法没有参数。
- 工作原理
(1)分布式计算:当调用countByKey()方法时,Spark会并行地在集群的各个执行节点上对RDD中的键进行计数。
(2)统计键的出现次数:Spark会对RDD中的每个键进行计数,并将结果保存在一个Map中,其中键是RDD中的唯一键,值是该键在RDD中出现的次数。
(3)返回结果:计数完成后,Spark会将包含键和对应计数值的Map返回给调用countByKey()方法的程序。
- 示例
使用countByKey()方法对RDD中的键进行计数:
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;import java.util.Map;public class CountByKeyExample {public static void main(String[] args) {// 创建 SparkContextJavaSparkContext sc = new JavaSparkContext("local", "countByKeyExample");// 创建一个包含键值对的RDDJavaPairRDD<String, Integer> pairRDD = sc.parallelizePairs(List.of(new Tuple2<>("a", 1),new Tuple2<>("b", 2),new Tuple2<>("a", 3),new Tuple2<>("c", 1),new Tuple2<>("b", 2)));// 使用 countByKey() 方法对RDD中的键进行计数Map<String, Long> counts = pairRDD.countByKey();// 输出键的计数结果for (Map.Entry<String, Long> entry : counts.entrySet()) {System.out.println(entry.getKey() + ": " + entry.getValue());}// 关闭 SparkContextsc.stop();}
}
- 注意事项
(1)countByKey()操作只能应用于RDD中的键值对元素。
(2)返回的结果是一个Map,其中包含了RDD中每个键以及对应的出现次数。
(3)由于countByKey()是一个动作操作,会触发完整的RDD计算,因此在处理大型数据集时需要谨慎使用。
6.takeSample(withReplacement, num, seed):从 RDD 中随机采样 num 个元素,并以数组的形式返回。
takeSample是Apache Spark中的一个动作(action),用于从RDD中随机抽取指定大小的样本。
这个操作可用于从大型数据集中提取一个较小的样本,以便进行测试、调试或快速预览数据。
- 方法签名和参数
List<T> takeSample(boolean withReplacement, int num, long seed)
withReplacement:一个布尔值,指示是否允许有放回地抽样。如果设置为true,则在抽样时允许某个元素被抽取多次;如果设置为false,则每个元素只能被抽取一次。
num:要抽取的样本大小。
seed:可选的随机种子,用于确定抽样结果的随机性。如果不指定,则使用系统时间作为默认种子。
- 工作原理
(1)随机抽样:根据参数指定的要求,在RDD中进行随机抽样。如果withReplacement参数为false,则在抽样过程中不会出现重复的元素;如果为true,则可能会出现重复元素。
(2)抽取指定大小的样本:根据num参数指定的大小,从RDD中抽取相应数量的元素作为样本。
(3)返回结果:将抽样得到的元素组成的列表返回给调用takeSample方法的程序。
- 示例
使用takeSample方法从RDD中随机抽取样本:
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.util.List;public class TakeSampleExample {public static void main(String[] args) {// 创建 SparkContextJavaSparkContext sc = new JavaSparkContext("local", "takeSampleExample");// 创建一个包含整数的RDDJavaRDD<Integer> rdd = sc.parallelize(List.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10));// 从RDD中随机抽取3个样本,不允许重复抽样List<Integer> sample = rdd.takeSample(false, 3);// 输出抽样结果System.out.println("Sampled elements: " + sample);// 关闭 SparkContextsc.stop();}
}
- 注意事项
(1)takeSample操作可以用于对大型数据集进行快速抽样,但需要注意样本大小与数据集大小之间的关系,以避免内存溢出或性能问题。
(2)如果数据集较大,建议在抽样前先进行一定的数据预处理或筛选,以确保抽样得到的样本具有代表性。
(3)可以通过指定不同的随机种子来获得不同的抽样结果,这对于调试和验证抽样的结果的随机性很有帮助。
7.foreach()遍历RDD中每一个元素
同 8。
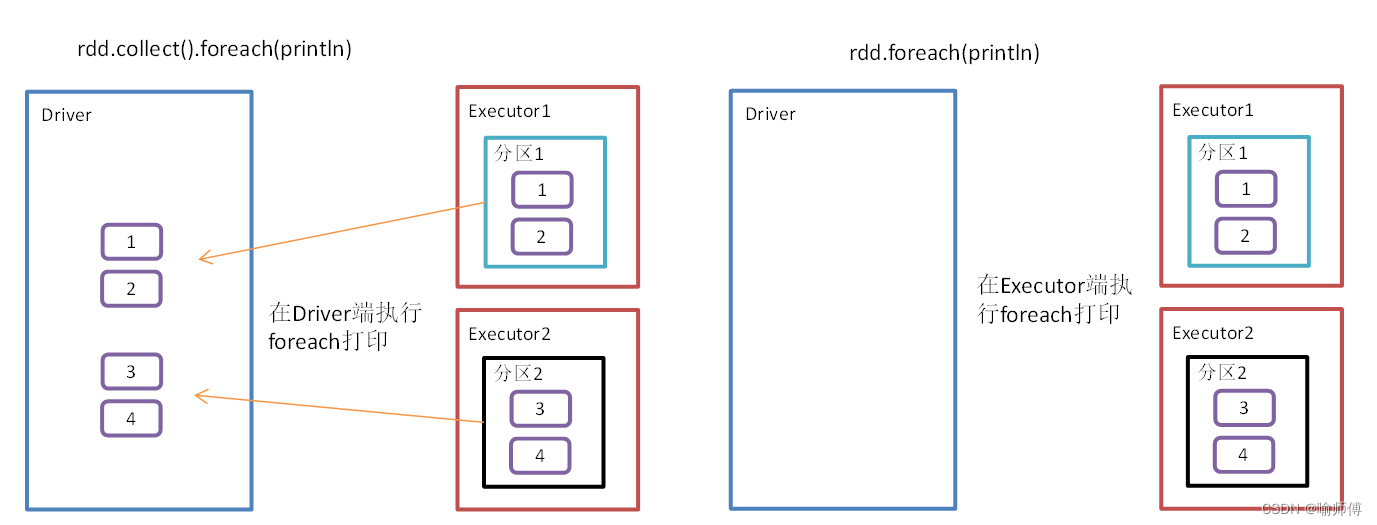
8.foreach(func):对 RDD 中的每个元素应用函数 func
foreach是Apache Spark中的一个动作(action),用于对RDD中的每个元素执行指定的操作。
与转换操作不同,动作操作会触发实际的计算,并将结果返回给驱动程序或执行一些副作用操作,如在每个元素上执行外部函数或将数据写入外部系统。
- 方法签名和参数
void foreach(VoidFunction<T> f)
其中:
f:一个接受RDD中元素类型的函数接口,通常是一个匿名函数或lambda表达式,用于指定要在每个元素上执行的操作。
- 工作原理
(1)并行迭代:Spark会将RDD中的元素分配到集群中的不同节点上进行并行处理。
(2)应用操作:对于每个分区中的元素,Spark会调用指定的函数来执行所需的操作。
(3)执行副作用:如果指定的函数产生了副作用(如写入外部系统、更新共享状态等),则这些副作用会在执行期间被触发。
- 示例
使用foreach方法对RDD中的每个元素执行操作:
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.VoidFunction;public class ForeachExample {public static void main(String[] args) {// 创建 SparkContextJavaSparkContext sc = new JavaSparkContext("local", "foreachExample");// 创建一个包含字符串的RDDJavaRDD<String> rdd = sc.parallelize(List.of("apple", "banana", "orange", "grape"));// 对RDD中的每个元素执行打印操作rdd.foreach((VoidFunction<String>) s -> System.out.println(s));// 关闭 SparkContextsc.stop();}
}
- 注意事项
(1)foreach操作通常用于执行副作用操作,如在每个元素上调用外部函数、写入外部系统等。如果不需要执行副作用操作,而只是希望对RDD中的元素进行转换或过滤,应该使用转换操作而不是动作操作。
(2)在使用foreach操作时,需要注意操作的并发性和线程安全性,确保操作不会产生竞态条件或数据不一致的情况。
(3)在使用foreach操作时,应该避免在操作中修改RDD的数据结构或共享状态,因为这可能会导致意外的行为或不可预测的结果。
9.foreachPartition ()遍历RDD中每一个分区
foreachPartition()方法与foreach()方法类似,但是它是针对RDD中的每个分区而不是每个元素。
这个方法允许您对RDD中的每个分区执行一个操作,这在某些情况下可以提高性能,特别是当您需要在每个分区上执行一些初始化或清理工作时。
- 方法签名和参数
void foreachPartition(VoidFunction<Iterator<T>> f)
其中:
f:是一个接受Iterator类型的函数,表示要在RDD的每个分区上执行的操作。
- 工作原理
(1)分区迭代:对RDD中的每个分区依次执行指定的操作。在每个分区上,会创建一个Iterator对象,其中包含了该分区的所有元素。
(2)并行执行:在分布式环境下,这些操作会在各个节点上并行执行,以提高整体的执行效率。
(3)初始化和清理:foreachPartition()方法通常用于执行一些需要在每个分区上进行初始化或清理的操作,例如在分区开始时打开数据库连接,在分区结束时关闭连接。
- 示例
使用foreachPartition()方法遍历RDD中的每个分区:
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;import java.util.Iterator;public class ForeachPartitionExample {public static void main(String[] args) {// 创建 SparkContextJavaSparkContext sc = new JavaSparkContext("local", "foreachPartitionExample");// 创建一个包含整数的RDDJavaRDD<Integer> rdd = sc.parallelize(List.of(1, 2, 3, 4, 5), 2); // 将RDD划分为2个分区// 对RDD中的每个分区执行打印操作rdd.foreachPartition(partition -> {while (partition.hasNext()) {System.out.println(partition.next());}});// 关闭 SparkContextsc.stop();}
}
RDD被划分为2个分区,并且对每个分区执行了打印操作。
- 注意事项
(1)与foreach()方法类似,foreachPartition()方法也是一个动作操作,会触发作用于RDD上的转换操作立即执行。
(2)由于在每个分区上执行的操作是独立的,因此可以在foreachPartition()中执行一些与分区相关的初始化或清理工作,例如在分区开始时打开数据库连接,在分区结束时关闭连接。
(3)在使用foreachPartition()方法时,要注意避免在操作中引入共享状态或副作用,以避免竞态条件或不确定的行为。
10.saveAsTextFile(path):将 RDD 中的元素保存为文本文件
saveAsTextFile(path)是Apache Spark中用于将RDD中的数据保存到文本文件的方法。
它将RDD中的每个元素转换为字符串,并将这些字符串写入到指定路径的文本文件中。
- 方法签名和参数
void saveAsTextFile(String path)
其中:
path:指定要保存数据的目标路径。
- 工作原理
(1)将RDD转换为文本行:对于RDD中的每个元素,Spark会调用toString()方法将其转换为一个字符串。
(2)写入文件:将转换后的字符串行写入到指定路径的文本文件中。如果指定的路径已存在,则会覆盖现有文件;如果路径不存在,则会创建新文件。
(2)分区写入:如果RDD是分区的,Spark会将每个分区的数据写入到单独的文件中,并以分区编号作为文件名的一部分。
- 示例
使用saveAsTextFile方法将RDD中的数据保存到文本文件中:
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;public class SaveAsTextFileExample {public static void main(String[] args) {// 创建 SparkContextJavaSparkContext sc = new JavaSparkContext("local", "saveAsTextFileExample");// 创建一个包含整数的RDDJavaRDD<Integer> rdd = sc.parallelize(List.of(1, 2, 3, 4, 5));// 将RDD中的数据保存到文本文件中rdd.saveAsTextFile("output");// 关闭 SparkContextsc.stop();}
}
RDD中的整数元素被转换为字符串,并保存到名为"output"的目录中。
- 注意事项
(1)使用saveAsTextFile方法保存RDD数据时,需要确保RDD中的元素都具有合适的toString()方法,以便正确转换为字符串形式。
(2)如果RDD的数据量很大,保存为文本文件可能会生成大量小文件,这可能会导致文件系统的性能问题。在这种情况下,可以考虑使用更适合大数据量的文件格式,如Parquet或ORC。
(3)在集群环境下使用saveAsTextFile方法时,要确保目标路径是集群中所有节点都能够访问的位置。
11.saveAsObjectFile(path) 序列化成对象保存到文件
与saveAsTextFile(path)不同的是,它将数据序列化成对象保存到文件中,而不是将数据转换为字符串形式。
这个方法可以用于保存任意类型的对象,而不仅仅是字符串。
- 方法签名和参数
void saveAsObjectFile(String path)
其中:
path:指定要保存数据的目标路径。
- 工作原理
(1)序列化对象:对于RDD中的每个元素,Spark会使用Java的序列化机制将其序列化为字节流。
(2)写入文件:将序列化后的字节流写入到指定路径的文件中。如果指定的路径已存在,则会覆盖现有文件;如果路径不存在,则会创建新文件。
(3)分区写入:如果RDD是分区的,Spark会将每个分区的数据写入到单独的文件中,并以分区编号作为文件名的一部分。
- 示例
使用saveAsObjectFile方法将RDD中的数据保存到文件中:
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;public class SaveAsObjectFileExample {public static void main(String[] args) {// 创建 SparkContextJavaSparkContext sc = new JavaSparkContext("local", "saveAsObjectFileExample");// 创建一个包含字符串对象的RDDJavaRDD<String> rdd = sc.parallelize(List.of("apple", "banana", "orange"));// 将RDD中的数据保存为对象文件rdd.saveAsObjectFile("output");// 关闭 SparkContextsc.stop();}
}
RDD中的字符串对象被序列化,并保存到名为"output"的目录中。
- 注意事项
(1)使用saveAsObjectFile方法保存RDD数据时,要确保RDD中的元素都是可序列化的对象,否则会抛出序列化错误。
(2)序列化的数据会占用更多的存储空间,并且不易阅读。因此,如果数据需要人类可读的格式或者需要进行跨平台交互,可能更适合使用saveAsTextFile方法。
(3)在集群环境下使用saveAsObjectFile方法时,要确保目标路径是集群中所有节点都能够访问的位置。
12.reduce()
在Java中,Apache Spark的RDD(Resilient Distributed Dataset)类提供了reduce()方法,用于将RDD中的元素通过指定的函数进行聚合。
这个函数必须是可交换和可结合的,以确保在分布式环境中正确执行。
- 签名
public T reduce(Function2<T,T,T> func)
在这里,Function2<T,T,T>是一个接口,它表示接受两个类型为T的参数,并返回类型为T的结果的函数。参数func是用于聚合RDD元素的函数。
- 参数:
func:用于聚合RDD元素的函数。这个函数接受两个类型为T的参数,并返回一个类型为T的结果。
- 返回值:
T:聚合后的结果。
- 功能:
reduce()方法用于将RDD中的元素通过指定的函数进行聚合。
它从RDD的第一个元素开始,将函数应用于每一对元素,然后将结果继续与下一个元素进行聚合,直到遍历完整个RDD,得到最终的结果。
- 示例
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Function2;import java.util.Arrays;public class Main {public static void main(String[] args) {JavaSparkContext sc = new JavaSparkContext("local", "ReduceExample");JavaRDD<Integer> rdd = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5));// 使用reduce方法计算RDD中所有元素的总和Integer totalSum = rdd.reduce((Function2<Integer, Integer, Integer>) (x, y) -> x + y);System.out.println("Total sum: " + totalSum);}
}
在这个示例中,我们首先创建了一个包含整数的RDD,然后使用reduce()方法计算了RDD中所有元素的总和。Lambda表达式(x, y) -> x + y用于将两个元素相加,然后reduce()方法将此函数应用于RDD中的每对元素,最终得到了总和。
- 注意事项:
(1)传递给reduce()方法的函数必须是可交换和可结合的。这是因为在分布式环境中,Spark会将RDD分割成多个分区,每个分区在不同的计算节点上执行。
(2)可交换和可结合的函数可以确保在不同分区上执行聚合操作时,得到的最终结果是确定的和可预期的。