
万卡 GPU 集群互联:硬件配置和网络设计
一、背景
自从 OpenAI 推出 ChatGPT 以来,LLM 迅速成为焦点关注的对象,并取得快速发展。众多企业纷纷投入 LLM 预训练,希望跟上这一波浪潮。然而,要训练一个 100B 规模的 LLM,通常需要庞大的计算资源,例如拥有万卡 GPU 的集群。以 Falcon 系列模型为例,其在 4096 个 A100 组成的集群上训练 180B 模型,训练 3.5T Token 耗时将近 70 天。随着数据规模不断膨胀,对算力的需求也日益增长。例如,Meta 在训练其 LLaMA3 系列模型时使用了 15T 的 Token,这一过程是在 2 个 24K H100 集群上完成的。
本文深入探讨构建大规模GPU集群的关键组件与配置。涵盖多样GPU类型与服务器配置,网络设备(网卡、交换机、光模块)调优,以及数据中心网络拓扑设计(如3-Tier、Fat-Tree)。特别聚焦NVIDIA DGX A100与DGX H100 SuperPod的精准配置与网络布局,同时概览业界万卡集群标准拓扑。助您全面理解,高效构建大规模GPU集群。
构建超万卡GPU集群是一项复杂的挑战,涉及存储网络、管理网络等多个维度。尽管本文仅触及冰山一角,但已深入探讨了广泛采用的树形拓扑结构。值得注意的是,电力与冷却系统作为集群稳定运行的关键,同样不可或缺。未来,集群的构建与维护还需在这些方面持续精进。
二、相关组件
2.1 GPU
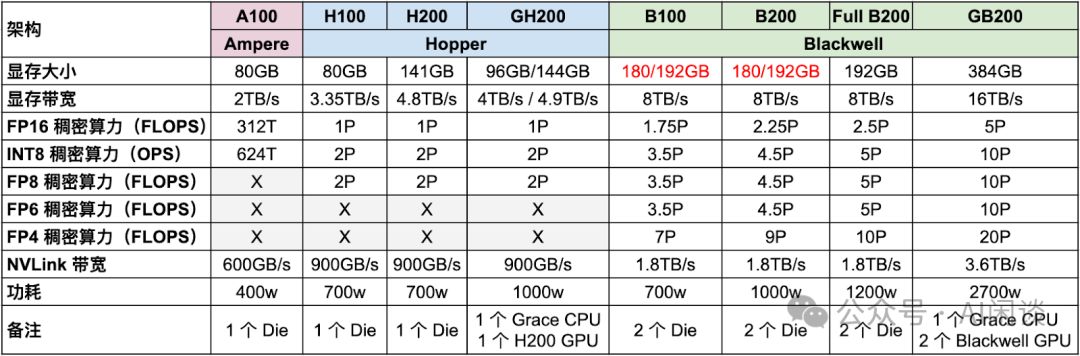
Ampere、Hopper及最新Blackwell系列GPU持续进化,如图表所示,显存、算力及NVLink性能均显著增强,彰显其强大的技术迭代与性能提升。
- A100升级至H100,FP16稠密算力提升超3倍,功耗从400w增至700w,效能显著提升,为高性能计算注入新动力。
- H200升级至B200,FP16稠密算力翻倍,功耗仅从700w增至1000w,性能提升显著,能效比优异。
- Blackwell GPU以其FP4精度支持,算力高达FP8的两倍。NVIDIA报告中,FP4算力与Hopper架构FP8算力对比,凸显了显著的加速优势,展现了Blackwell GPU的卓越性能。
- GB200搭载完整的Full B200芯片,而B100和B200则是其简化版本,确保性能与成本的精准平衡。
2.2 HGX
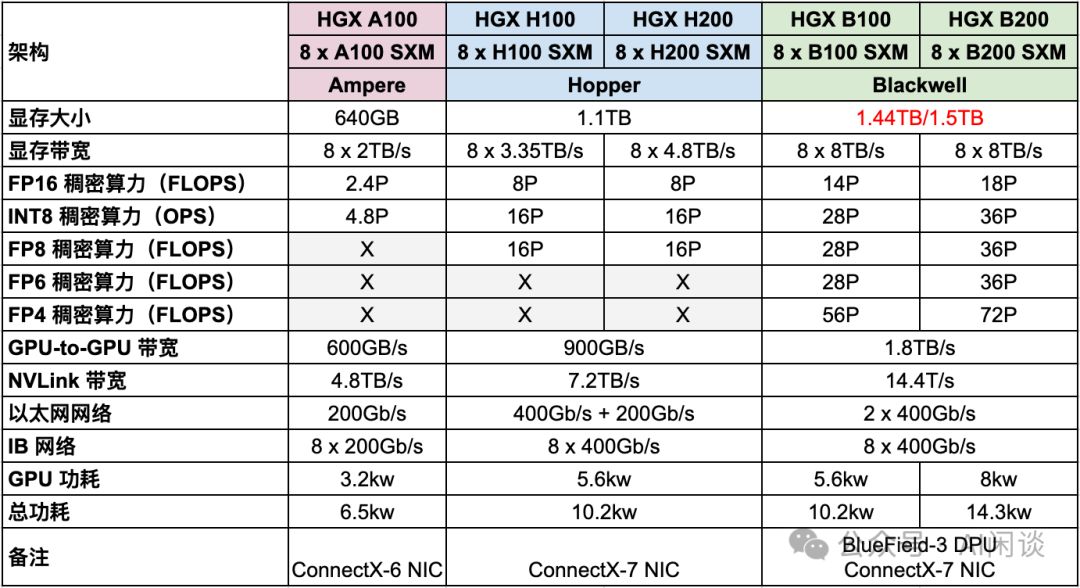
HGX,NVIDIA倾力打造的高性能服务器,集8或4个GPU于一身,搭载Intel或AMD CPU。其NVLink与NVSwitch技术实现全面互联,确保性能极致释放(8个GPU为NVLink全互联上限)。散热系统采用风冷设计,确保稳定运行。HGX,引领服务器性能新纪元。
- HGX A100升级至HGX H100和HGX H200,FP16稠密算力激增3.3倍,同时功耗控制不到原两倍,性能卓越,效率领先。
- HGX B100和B200在FP16稠密算力上实现近2倍提升,相较HGX H100和H200,功耗保持相当,最多节省近半,性能卓越且能效出众。
- HGX B100与B200网络保持原配,后向IB网卡维持8x400Gb/s高速传输,无需升级,确保稳定高效。
NVIDIA DGX与HGX,专为深度学习、人工智能及大规模计算打造的高性能解决方案,各具特色,满足不同设计及应用需求。
- DGX,专为普通消费者打造,提供即插即用高性能方案,配备完整软件支持,涵盖NVIDIA深度学习软件栈、驱动与工具,预构建且封闭,轻松满足您的多样化需求。
- HGX,专为云服务提供商与大规模数据中心运营商打造,构建高性能定制解决方案的利器。模块化设计,支持按需定制硬件,作为硬件平台或参考架构,助力客户构建卓越性能。
2.3 网络
2.3.1 网卡
这里主要介绍 ConnectX-5/6/7/8,是 Mellanox 的高速网卡,都支持以太网和 IB(InfiniBand)。2016 年发布 ConnectX-5,2019 年 NVIDIA 收购 Mellanox,然后 2020 年发布了 ConnectX-6,2022 年发布 ConnectX-7,2024 年 GTC 大会上老黄介绍了 ConnectX-8,还没看到详细参数。几个网卡对应的简要配置如下所示,可以看出,基本上每一代的总带宽都翻倍,下一代估计能到 1.6Tbps:

2.3.2 交换机
NVIDIA提供以太网和IB交换机,支持数十至数百端口。其总吞吐量(双向交换能力)计算为最大带宽乘以端口数再乘以2,这里的2代表双向传输。这一配置确保高性能的数据传输和处理能力。
Spectrum-X系列以太网交换机,支持高带宽数据传输,满足多样化网络需求。尽管低带宽也兼容,但总端口数固定,故在此主要展示高带宽数据。
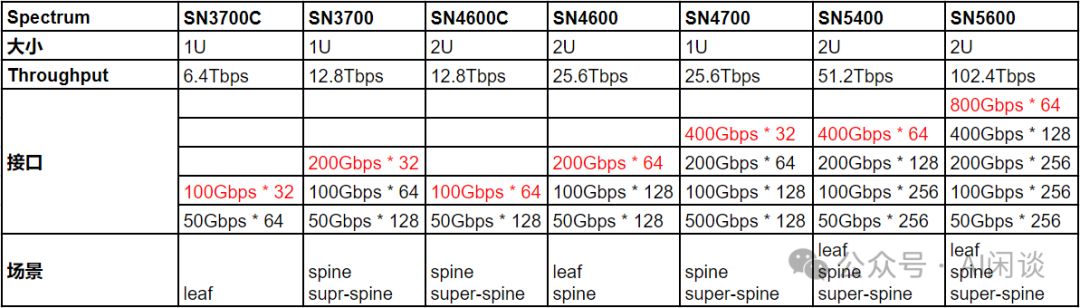
如下图为常见的 Quantum-X 系列 IB 交换机:

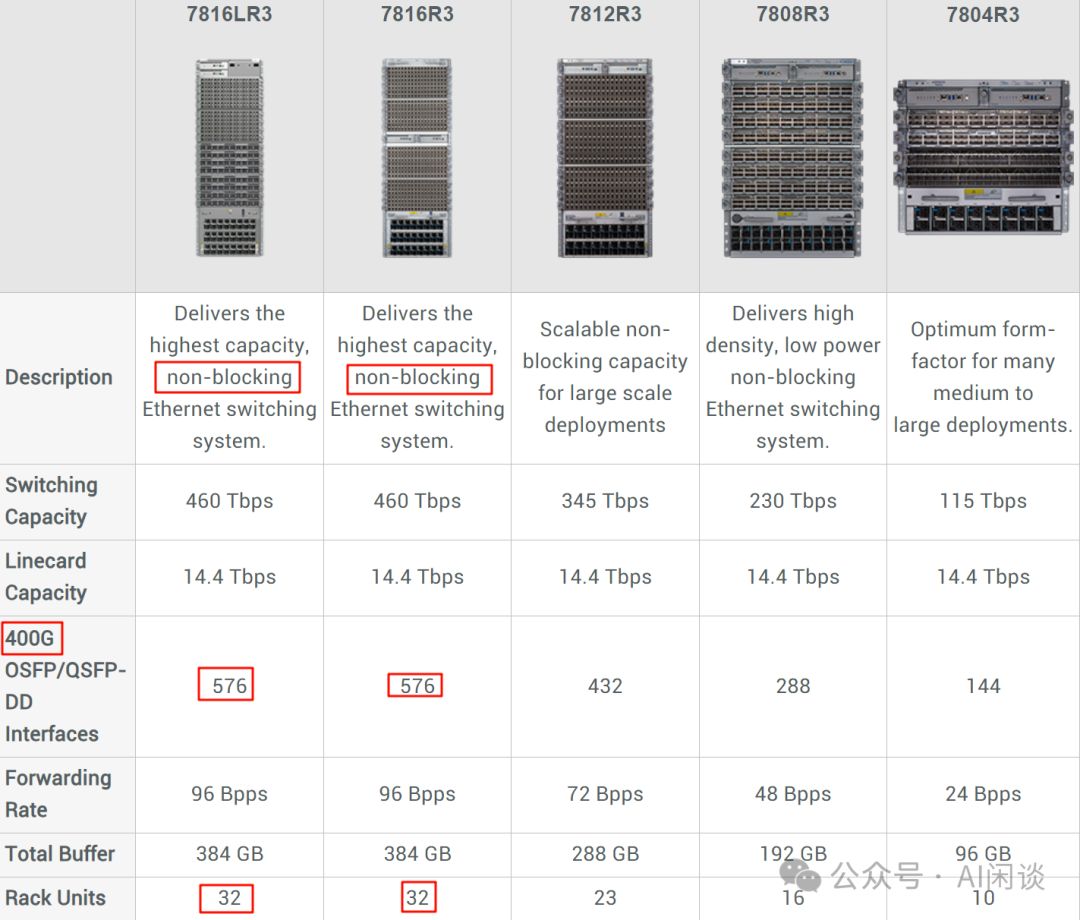
除了以上的 Mellanox 交换机外,现在也有很多数据中心会采用框式交换机(Modular Switch),比如 Meta 最近的 Building Meta's GenAI Infrastructure 中提到其构建了 2 个包含 24K H100 的 GPU 集群,其中使用了 Arista 7800 系列交换机,而 7800 系列就包含框式交换机,如下图所示,7816LR3 和 7816R3 甚至可以提供 576 Port 的 400G 高速带宽,其内部通过高效的总线或者交换背板互联,传输和处理的延迟非常低:
2.3.3 光模块
光模块是光纤通信的核心,可将电信号高效转化为光信号,通过光纤传输,实现超高速率、长距离通信,且抗电磁干扰能力强。它集成发射器与接收器,前者负责电转光,后者实现光转电,为现代通信提供坚实技术支撑。下图为光模块结构示意,展现其工作原理与卓越性能。

SFP与QSFP,光纤通信中两大光模块接口。SFP小巧便携,QSFP则四倍扩展。两者在尺寸、带宽及应用上各有千秋:SFP适合紧凑设计,QSFP则助力高速传输。选择适合您需求的接口,让光纤通信更高效。
- SFP 通常是单传输通道(一条光纤或一对光纤)
- QSFP作为多传输通道,其升级版QSFP-DD实现双倍密度,提供更高端口密度,通过8个信道显著提升性能,是高效数据传输的理想选择。
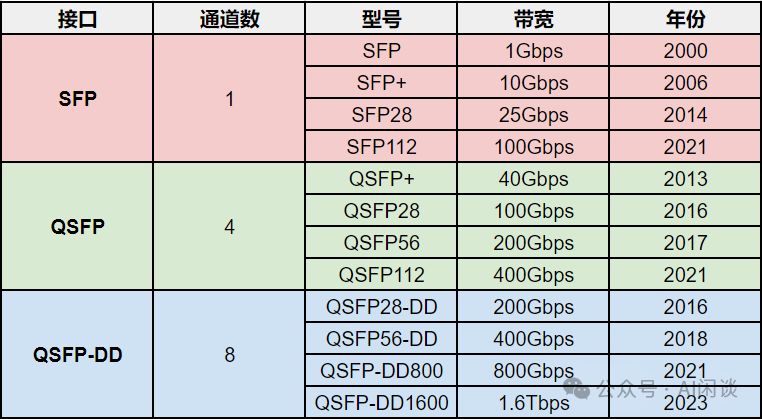
OSFP封装方式崭露头角,以其8通道数满足高带宽需求,如400Gbps和800Gbps。它专为高带宽场景设计,与SFP、QSFP接口不兼容。尺寸略大于QSFP-DD,需转换器适配。下图为适应不同传输距离(100米至10千米)的400Gbps OSFP光模块,展现了其强大的传输能力。
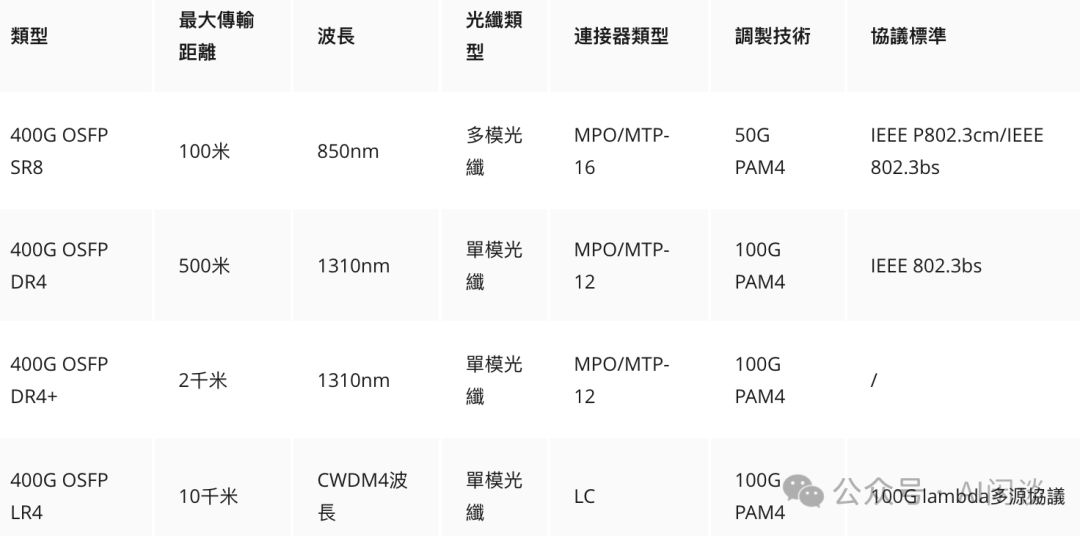
针对不同距离与场景,精选光模块至关重要。如图所示,Core与Spine间选用10Km的400G LR4及800G 2xLR4,Spine与Leaf间则选2Km的400G FR4,Leaf至ToR则推荐500m的400G DR。后文将详细解读网络拓扑布局,敬请期待。
光模块单价高昂,单个可达数千至数万人民币,与带宽和传输距离成正比。例如,FS热销的400Gbps光模块,带宽大、距离远,价格自然不菲。

光模块数量与GPU成正比,通常为其4-6倍,导致成本高昂。在每个Port都需要光模块的背景下,优化成本成为关键挑战。
2.4 数据中心网络(DCN)拓扑
2.4.1 基本概念
东西向流量,即数据中心内不同服务器间的相互访问流量,已成为现代数据中心的主要流量来源,占比高达70%-80%,是数据中心高效运作的关键驱动力。
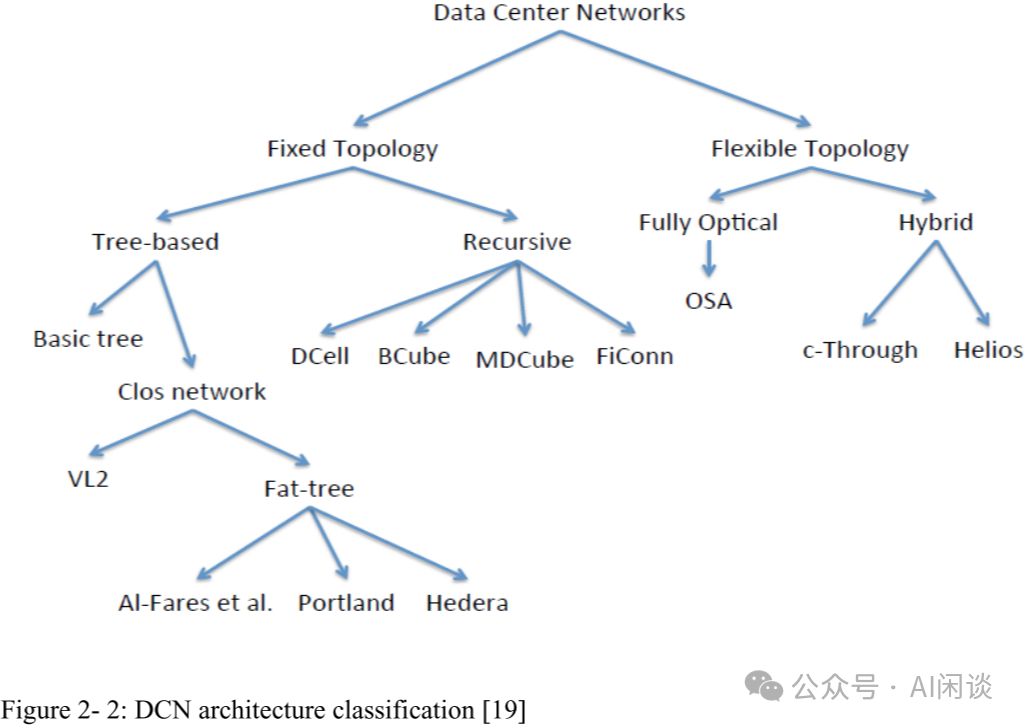
2.4.2 多层 DCN 架构
多层DCN网络架构广泛应用,尤以3层DCN架构为典型。该架构基于Tree结构,专注于管理南北向流量,包含核心层、汇聚层与接入层三层,高效且灵活。
- Core Layer:核心层,通常是高容量的路由器或交换机。
- Aggregation Layer(又称Distribution Layer)高效连接接入层设备,提供精准的路由指引、细致的过滤功能以及灵活的流量管理工程。
- 接入层(Access Layer)直接连接用户设备,是用户与网络之间的桥梁,确保用户设备顺利接入网络。
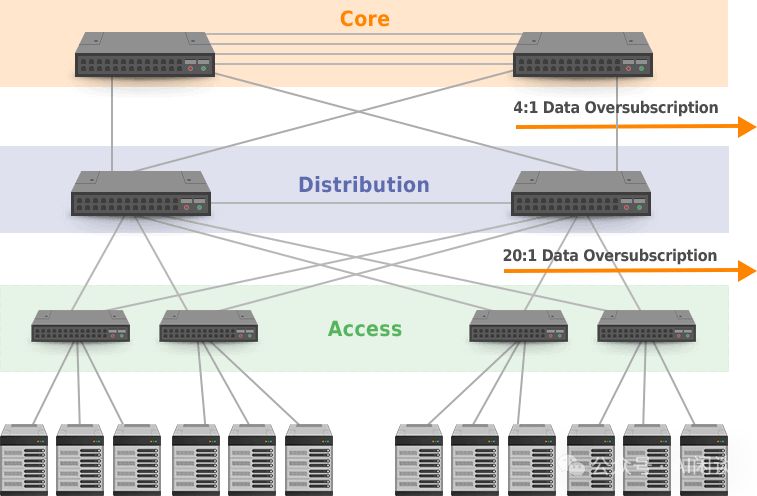
该架构中,通常会假设并非所有接入设备同时以最大带宽通信,因此,常见的做法是越往上总带宽越小,比如 Access 层的总带宽是 20 Gbps,而 Distribution 层的总带宽可能只有 1 Gbps。此时,一旦出现多个设备通信带宽总和超过设计容量,比如极端情况,所有设备都以最大带宽通信,则一定会出现 blocking,延迟增加,也将导致延迟的不可预测性。以上也就是常说的 oversubscription,其中 20:1 就是相应的 oversubscription rate。
该架构设计冗余备份机制,Core与Distribution层交换机互联易形成环路。为确保稳定,需采用生成树协议(SFP)避免环路,但此举可能带来带宽冗余浪费,需精细管理优化资源利用。
2.4.3 CLOS 网络
CLOS网络,由Charles Clos于1953年首创,是一种革命性的多级交换架构,专为大型电话交换系统的连通与扩展而生。如今,其原理已广泛应用于数据中心和高性能计算领域。CLOS网络凭借多级互联结构,提供高带宽、低延迟服务,确保网络高效且可扩展,引领现代通信技术的潮流。
如下图所示,CLOS 网络通常为三级结构:
- 输入层(Ingress):负责接收外部输入信号。
- 中间层(Middle):负责连接输入层和输出层交换机。
- 输出层(Egress):负责发送数据到最终目的地。
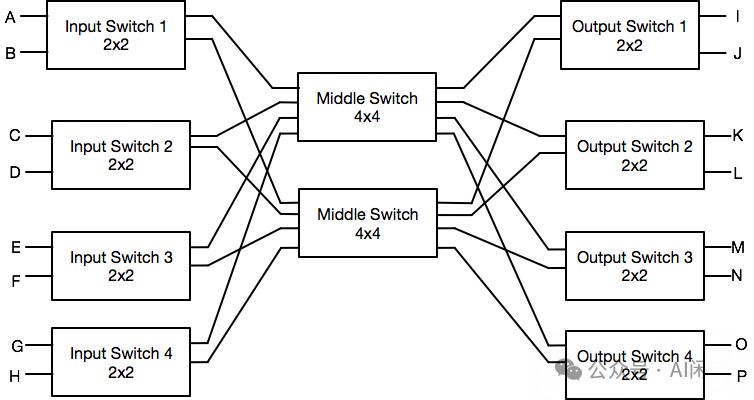
CLOS 网络有如下特点和优势:
- 非阻塞设计:CLOS网络采用无收敛结构,确保数据传输畅通无阻,有效避免交换机瓶颈引发的延迟或数据丢失,保障网络性能卓越。
- CLOS网络具备卓越的可扩展性,通过层级和交换机的增加,可轻松支持更多输入输出连接,且性能无损,实现高效扩展。
- 冗余设计确保网络多路径通畅,即使部分交换机或连接失效,数据也能迅速转至其他路径,显著提升整体网络可靠性。
2.4.4 Fat-Tree 拓扑
Fat-Tree DCN架构,源自Charles Leiserson于1985年的创新,是高性能计算和大型数据中心中不可或缺的CLOS网络。此架构以多层交换机为核心,构建独特的树形结构,超越传统3-tier网络。Fat-Tree以其卓越的设计和性能,成为行业领先的DCN解决方案。
- 所有层交换机都被替换为低端交换机,成本更低。
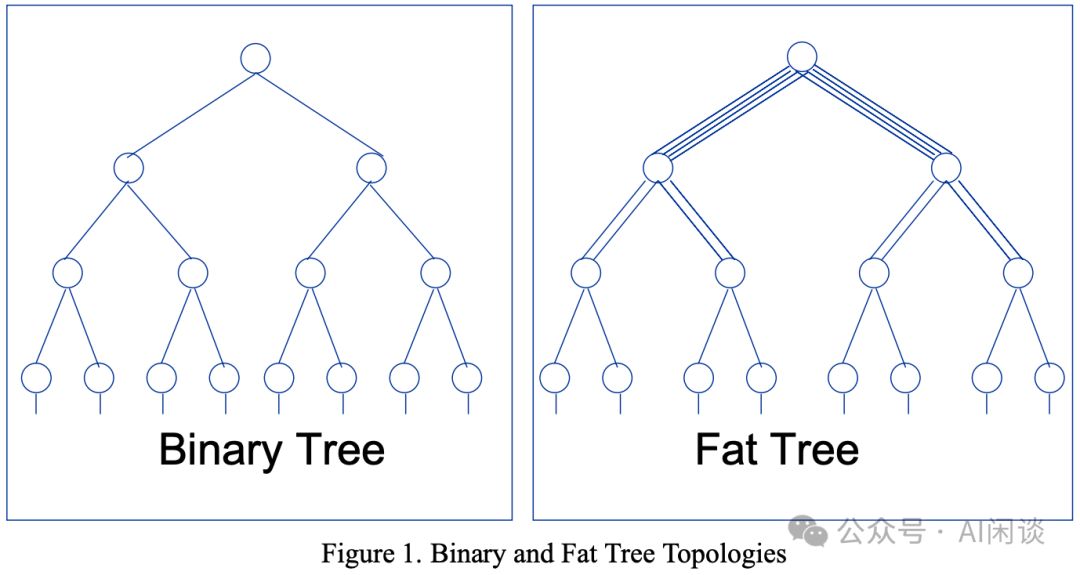
Fat-Tree DCN 架构的目的是最大化端到端带宽,提供 1:1 的 oversubscripition ratio,也就是实现无阻塞(Non-Blocking)网络。因此,在 Fat-Tree 中,交换机的数目会比 3-Tier 多的多,一般情况 Fat-Tree 中所有交换机都有相同个数的 Port,比如 K 个,相应的称为 K-port Fat-Tree 网络拓扑。2 层 Fat-Tree 和 3 层 Fat-Tree 拓扑如下所示:
- 2 层 Fat-Tree 拓扑
- Spine Switch:K/2 个,对应 K*(K/2) 个 Port。
- Leaf Switch:K 个,对应 K*K 个 Port。
- 实现高达K*K/2个Server的无阻塞网络,仅需3*K/2个Network Switch,确保高效、流畅的通信体验。
- 3 层 Fat-Tree 拓扑
- 核心交换机(Super Spine Switch)拥有(K/2)^2台,共计K*(K/2)^2个端口,提供高效、强大的网络连通能力。
- Spine Switch拥有2*(K/2)^2个单元,支持K*2*(K/2)^2个端口,高效满足大规模网络部署需求。
- Leaf Switch高达2*(K/2)^2个,支持K*2*(K/2)^2个端口,高效扩展,满足大规模网络需求。
- 采用本方案,可实现高达K^3/4个Server的无阻塞网络,显著提升通信效率。同时,仅需5*K^2/4个Switch即可支撑整个网络架构,确保高效且稳定的数据传输。高效能设计,满足大规模网络需求。
具体的计算方式如下表所示:

PS:关于 Fat-Tree 架构与 Spine-Leaf 架构的说法各异,有说 Fat-Tree 都是 3 层的,Spine-Leaf 是 2 层的,但很多场景也会介绍 Fat-Tree 的多层级拓扑。对于 Spine-Leaf 架构,也存在 SuperSpine-Spine-Leaf 的拓扑。我们这里就不再区分,都统一为 Fat-Tree 架构。此外,即使 Fat-Tree,也有场景提到无阻塞 Fat-Tree 和 有阻塞 Fat-Tree,这里如果没有特殊说明,都指无阻塞 Fat-Tree。
三、NVIDIA DGX SuperPod - A100
3.1 DGX A100 System
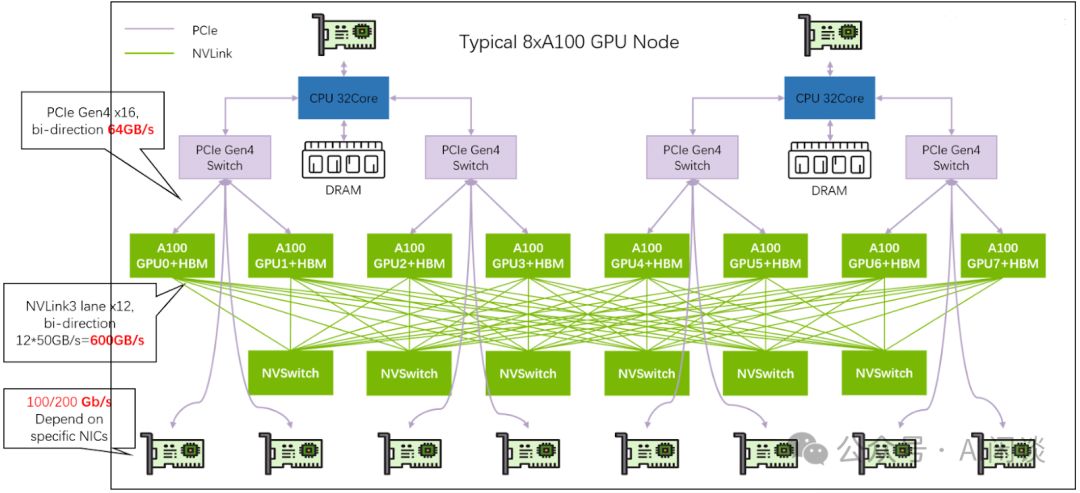
如图Figure 3所示,DGX A100 System(6U)展现了NVIDIA的尖端技术。详细介绍请参阅《Introduction to the NVIDIA DGX A100 System》,系统内含强大配置,为您的AI计算需求提供卓越支持。
- 8 个 A100 GPU,每个 GPU 600 GB/s NVLink 带宽。
- 搭载4.8TB/s NVSwitch带宽与640GB HBM2显存,卓越性能尽在掌握,助力您轻松应对各类计算挑战。
- 高效配置:8个Compute Connection(IB)搭载ConnectX-6网卡,实现8倍200Gbps总带宽,极速互联,满足高性能计算需求。
- 2 个 Storage Connection(IB)。
- 1 个 In-Band Connection(Ethernet)。
- 1 个 Out-Band Connection(Ethernet)。
如下图 Figure 3 所示为相应的网络接口:
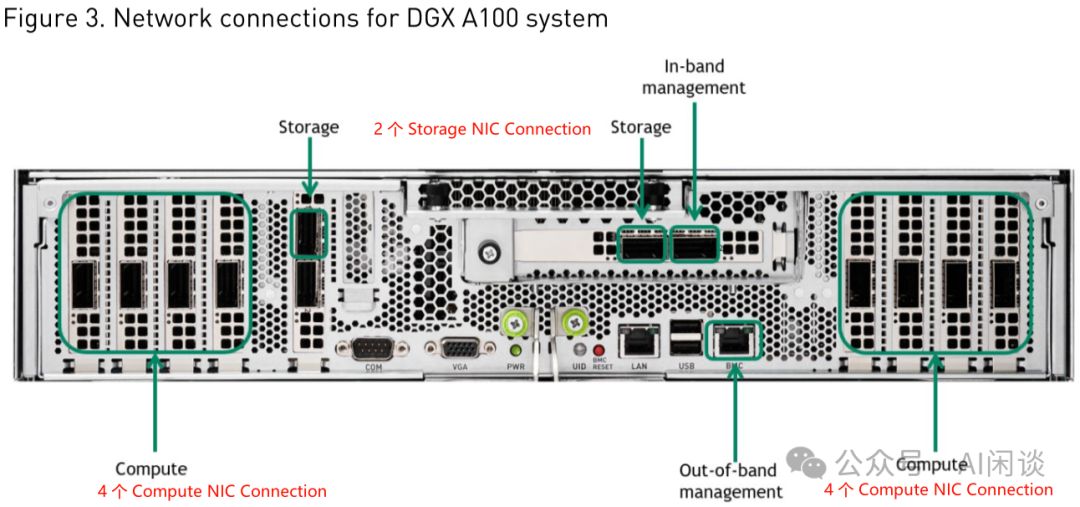
8×A100配置通过6个NVSwitch实现8个GPU的全互联。重要提示:NVLink带宽以Byte为单位,而网络带宽以bit为单位。DGX A100系统机内总带宽高达4.8TB/s,而网络带宽仅为1.6Tbps,两者相差24倍。这一配置彰显了卓越的数据传输能力,为高性能计算领域树立了新标杆。
3.2 SuperPod SU
如图Figure 14所示,DGX-SuperPod-A100的核心基础单元为SuperPod SU(Scalable Unit),展示了其高效且可扩展的构建方式。
- 每个Compute Rack融合4台DGX A100系统,配备2个3U PDU,单Rack即拥有高达32个A100 GPU的强大算力。汇聚成超级单元(SU),其GPU总量更跃升至160个A100,展现无与伦比的计算能力,为您的数据中心注入澎湃动力。
- Leaf Network Rack高效集成,包含8个1U Compute Switch与2个1U Storage Switch,配置强大,空间优化,满足多元化网络需求。
- Compute Switch搭载高性能QM8790 200 Gb/s IB交换机,提供惊人的320个端口(8*40),满足您高带宽、高效能的网络需求。
- 通过160个光模块,ConnectX-6网卡高效连接Compute Rack,每个GPU独享200Gbps带宽,实现极速数据传输,性能卓越。
- 其余 160 个通过光模块连接 Spine Rack。
- Compute Switch搭载高性能QM8790 200 Gb/s IB交换机,提供惊人的320个端口(8*40),满足您高带宽、高效能的网络需求。

ToR Switch(柜顶交换机)常用于充当Leaf Switch,因其与Server同柜,布线简化但或致Switch Port浪费。在有限空间的机柜中,尤其是随着GPU Server功耗上升,冷却系统面临挑战,导致GPU Server部署受限,进而减少网卡需求。这一配置策略旨在实现高效冷却与资源优化。
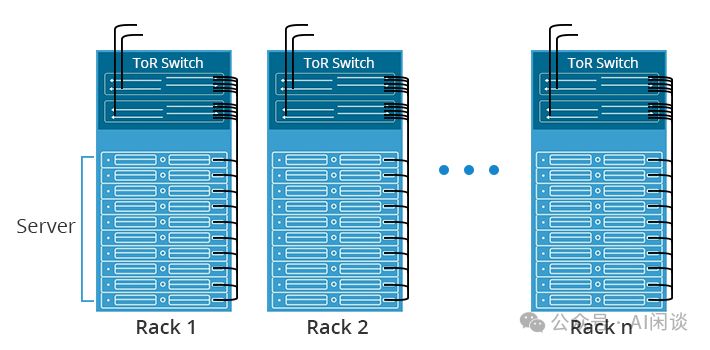
在工业场景中,虽然存在8*A100 System中使用较少网卡(如4x200 Gbps)的情况,导致所需端口和交换机减半,但整体网络拓扑结构相似。为简化说明,本文暂不考虑这种特殊情况。
3.3 Spine Rack
如图Figure 15所示,Spine Rack内集成20台1U的QM8790 200 Gb/s IB交换机,即Compute Switch,总计拥有800个端口(20*40)。此外,Out-of-band和In-band两种Switch并行运行,有效保障管理网络的高效与安全,实现了强大的数据交换与管理功能。

3.4 DGX SuperPod 100-node
如图Figure 4,展示了一个由100个节点构建的DGX-SuperPOD,其架构包含5个SU以及一个额外的Spine Rack,彰显强大性能与扩展性。
- SU集成8个高性能Leaf Compute Switch(QM7890,200Gbps),构建高效计算网络核心。
- 每节点配备8个ConnectX-6网卡,分别直连8个Leaf Compute Switch,实现一对一GPU高效互联,确保数据传输的极致速度与稳定性。
- Leaf Compute Switch的20个Port精准对接SU内20个Node,实现一对一连接。同时,另20个Port无缝连接Spine中的20个Spine Compute Switch,构建高效的数据传输网络。精准配置,确保网络流畅无阻。
- Spine Rack集成20台高性能Spine Compute Switch(QM8790,200 Gbps),构筑强大计算网络,满足高效数据传输需求。
- Spine Compute Switch的40个Port精准对接5组、每组8个的Leaf Compute Switch,构建高效、精准的计算网络,确保数据流通畅无阻。
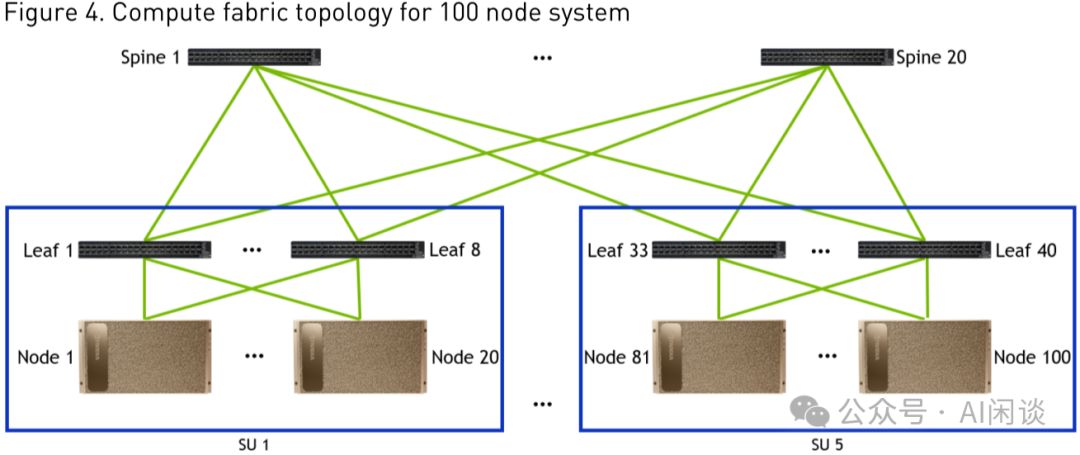
利用先进拓扑,我们构建了无阻塞(Non-Blocking)网络,支持高达800 GPU的互联,确保任意两个GPU间畅通无阻,实现高效通信。
- 高效连接不同SU的GPU,通过ConnectX-6直连Leaf Switch,再经Spine Switch扩展,最终回归Leaf Switch并连接至另一ConnectX-6,形成流畅无阻的数据传输路径。
- 通过ConnectX-6至Leaf Switch再至ConnectX-6的链路,实现同一SU内不同Node间GPU的高效互联,确保数据传输畅通无阻。
- 同一个 Node 内的 GPU 可以通过 NVLink 连通。
利用QM8790实现的2级Fat-Tree无阻塞网络,支持最多800个GPU,即每个GPU配备一个200 Gbps NIC Port,总数由Port数计算得出:40*(40/2)=800。若需扩展至更多GPU,可采用3级Fat-Tree架构,支持高达16000 GPU,上限计算为:40*(40/2)*(40/2)。这一架构优化为大规模GPU集群提供了强大的网络支撑。
3.5 DGX SuperPod 140-node
在100节点系统中,Compute Switch端口满载。为满足更多GPU需求,需升级架构,将二层Switch扩展为三层,增设一层Core Compute Switch。采用QM8790 200 Gbps技术,不仅提升系统扩展性,还能确保高性能的数据传输,助力GPU资源充分利用。
如下图 Figure 4 所示为 140-node 的 SuperPod,共包含 7 个 SU,所以总共 7*8=56 个 Leaf Switch。正常来说,56 个 Leaf Switch 只需要 56 个 Spine Switch,28 个 Core Switch 即可。而实际上用了 80 个 Spine Switch,并分为 8 个 Group,每个 SG 中 10 个 Spine Switch,每个 CG 中 14 个 Core Switch。(PS:也许是因为这样可以实现对称式的 Fat-Tree 拓扑,更好管理)
- 每个SU的第k个Leaf Switch直连至第k个SG的10个Spine Switch,实现高效网络互联。
- 每个Leaf Switch配备2个端口,均连接至SG中的Spine Switch,总计连接数为10*2=20,确保高效数据传输与稳定网络架构。
- Spine Switch配备14个Port,实现与Leaf Switch的2倍7端口高效连接,确保数据传输畅通无阻。
- Spine Switch 中奇数位置的 Switch 与 Core Switch 中奇数位置相连,偶数位置与偶数位置相连。比如 Spine Switch 1 的 14 个 Port 分别有 1 个 Port 与 Core Switch 1,3,5,...,25,27(CG1) 相连;Spine Switch 2 的 14 个 Port 分别有 1 个 Port 与 Core Switch 2,3,6,...,26,28(CG2) 相连。
- 每个核心交换机(Core Switch)均与40个脊柱交换机(Spine Switch)相连,构建高效网络架构。
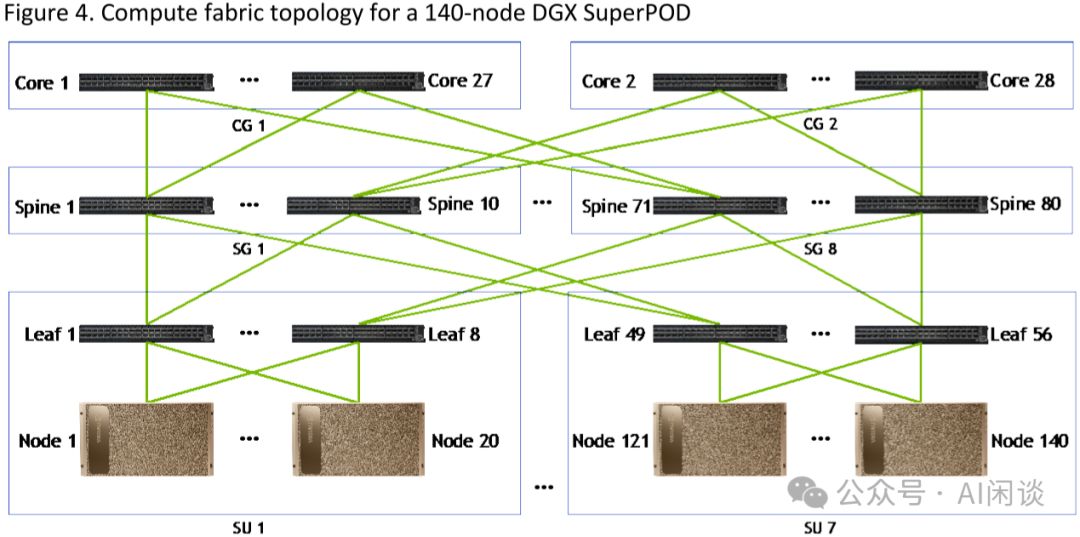
高效搭建1120 GPU集群,仅需140台设备,每台配置8个GPU与1个ConnectX-6 200Gbps网卡,轻松实现高性能计算与数据处理。
3.7 Storage Rack
如图Figure 16,Storage Rack配备了4个QM8790 200 Gbps IB交换机(即Storage Switch),合计拥有160个Port(4*40),构成高效存储架构。Rack内还设有相应的存储单元,确保数据的高效管理与访问。
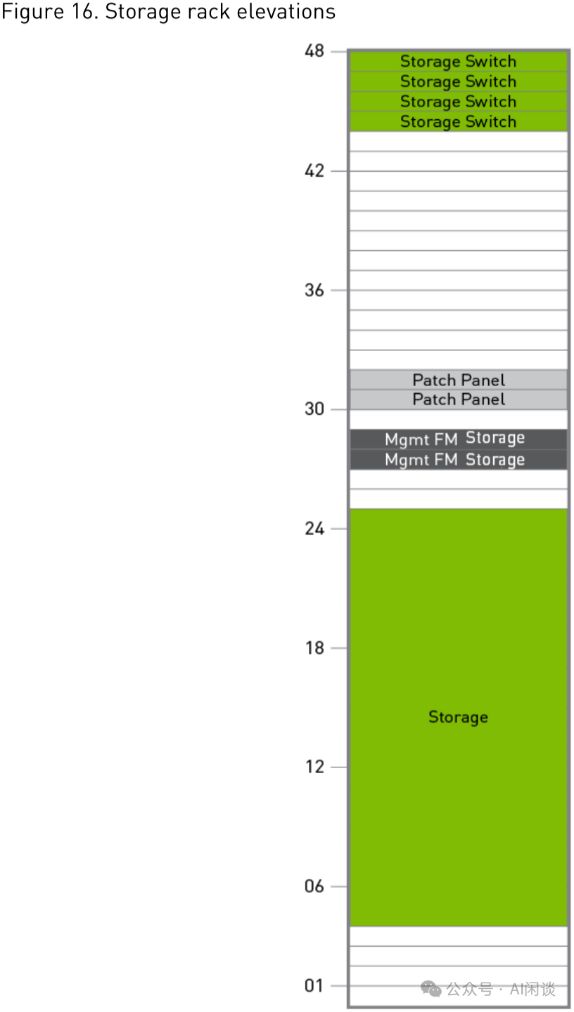
3.8 DGX SuperPod Storage Fabric
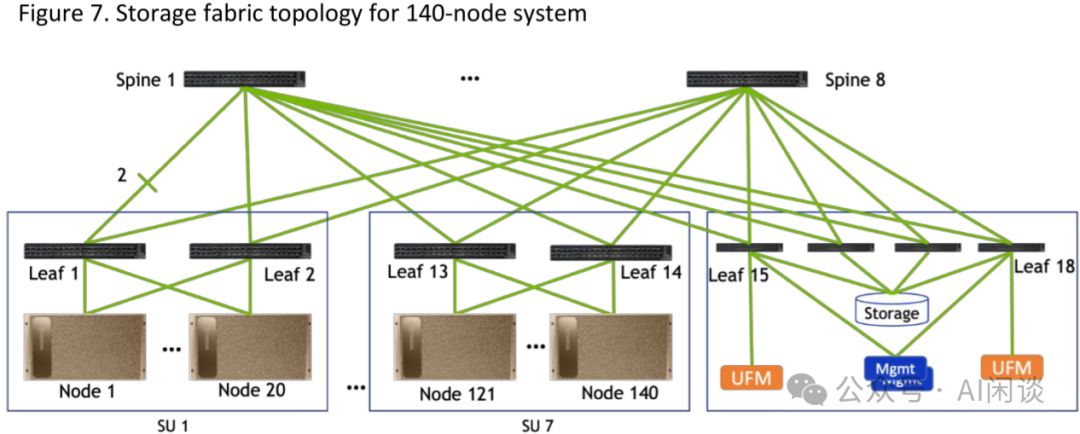
如图Figure 7所示,140节点的Storage Fabric架构由18个Leaf Switch构成。每SU内的Leaf Network Rack配备2个,而Storage Rack则包含4个。此外,架构中还配置了8个Spine Switch,确保了高效的网络连接与数据存储能力。
3.9 更多配置
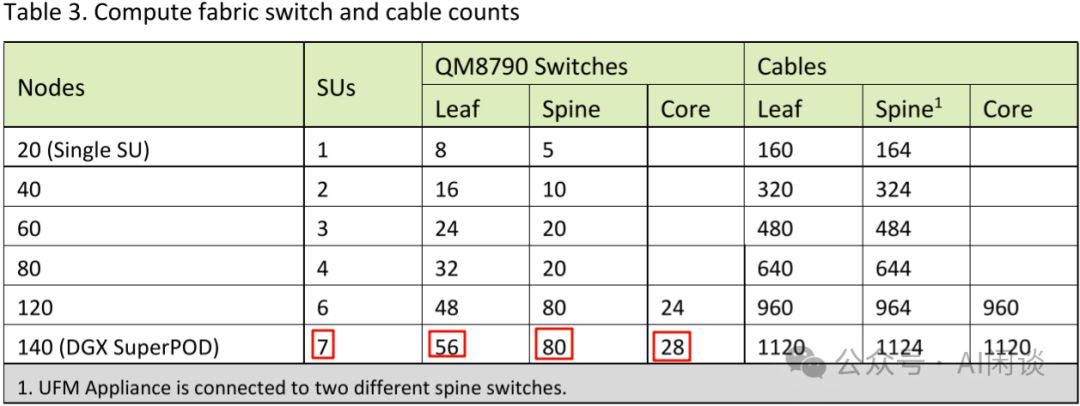
如下图 Table 3 所示为不同 node 对应的 Compute 配置:
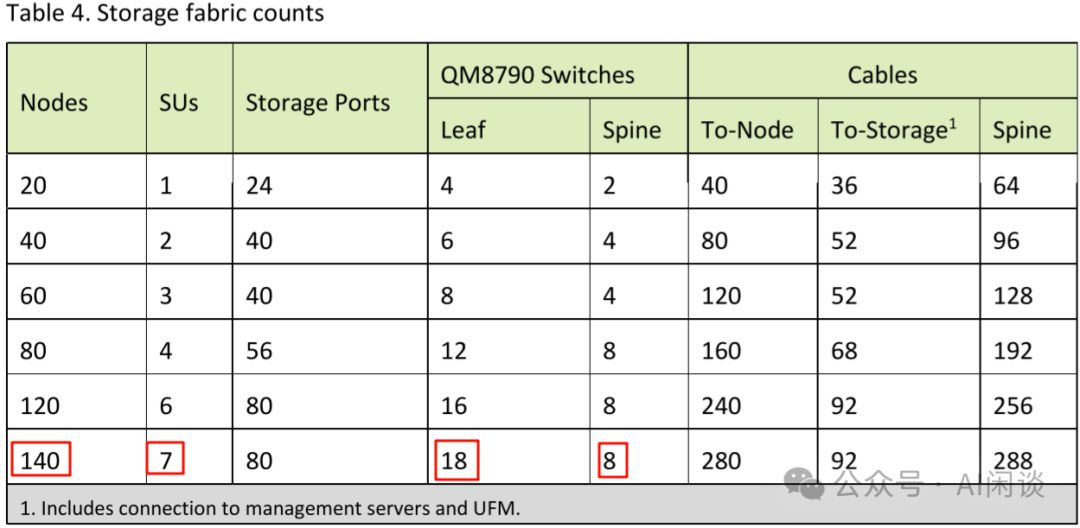
如下图 Table 4 所示为不同 node 对应的 Storage 配置:
四、NVIDIA DGX SuperPod - H100
4.1 DGX H100 System
DGX H100 System(6U)展示图如下,详情请参阅NVIDIA DGX H100 System介绍,内含关键配置信息,为您呈现高效能计算的未来之选。
- 8 个 H100 GPU,每个 GPU 900 GB/s NVLink 带宽。
- 900*8高达7.2TB/s的NVSwitch带宽,搭配80*8共640GB HBM3显存,性能卓越,满足高端计算需求。
- 采用4个OSFP端口(IB)与8个ConnectX-7网卡相连,实现高达8×400 Gbps的卓越带宽性能。
- 1 个 In-Band Connection(Ethernet)。

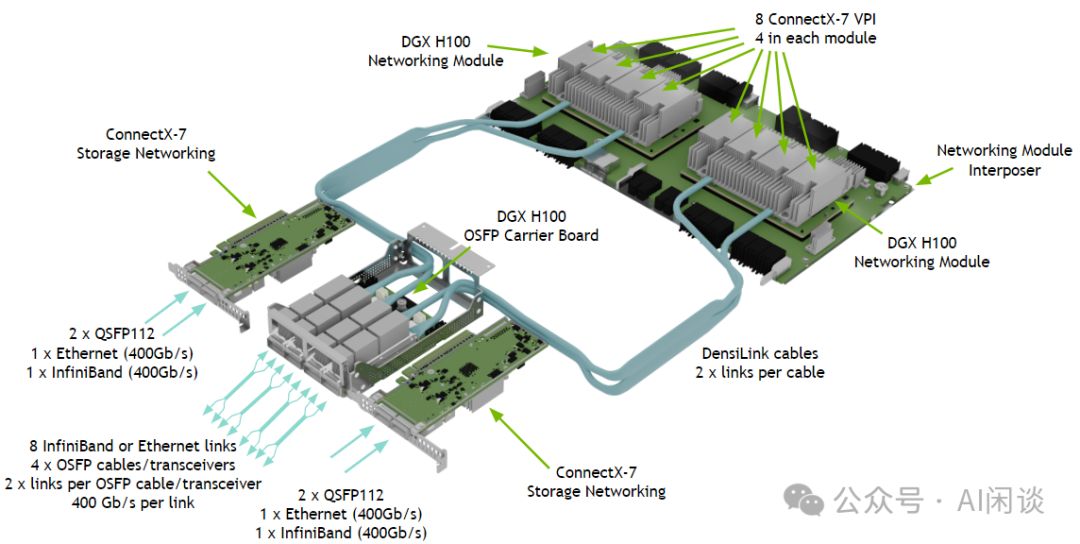
这款设备搭载8个GPU,经NVSwitch全互联,机内总带宽高达7.2TB/s,远超其3.2Tbps的网络带宽,性能差异显著,达22.5倍之差。
4.2 SuperPod SU
如图Figure 2所示,DGX-SuperPod-H100的基本构建单元为SuperPod SU(可扩展单元),展现其卓越的可扩展性和高效性。
- 每个Compute Rack集成4套DGX H100系统,配备3个PDU,共计搭载32个H100 GPU。扩展至一个完整的SU(Supercomputer Unit),您将拥有惊人的256个H100 GPU,展现无与伦比的计算实力。

4.3 Management Rack
H100 DGX SuperPod 配备NVIDIA Management Rack,与A100系列的Spine Rack和Storage Rack相似。如图3所示(配置因规模而异),它集成了一系列关键组件,确保系统的稳定运行和高效管理,为超级计算提供强大支持。
- 采用32个Leaf Compute Switch,搭载QM9700芯片,每台支持64个400Gbps端口。理论上,这些交换机可提供高达1024个400Gbps端口,其中一半用于连接node上的ConnectX-7网卡,另一半则连接16个Spine Compute Switch,实现1024 GPU的无阻塞网络架构。这一配置保证了数据传输的高效与稳定,满足大规模计算需求。
- 16台Spine Compute Switch均采用QM9700,完美对接32台Leaf Compute Switch的一半端口,高效连接,确保网络性能卓越。
- 8 个 Leaf Storage Switch,同样使用 QM9700。
- 4 个 Spine Storage Switch,同样使用 QM9700。

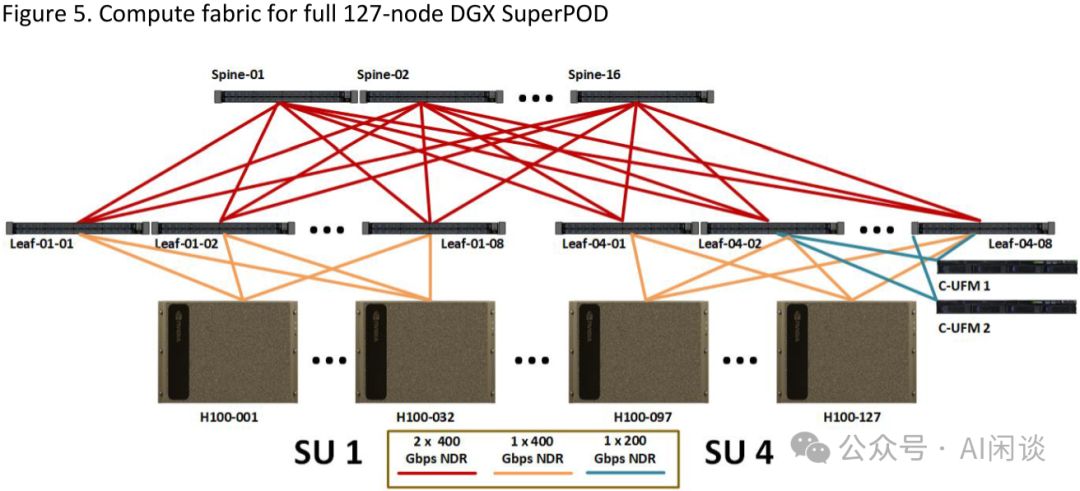
4.4 DGX SuperPod 127-node
如图Figure 5所示,DGX SuperPod由127个节点构成,包括4个SU和一个Management Rack。理论上,Management Rack能连接4个SU的128个节点。然而,由于Leaf Switch部分连接至UFM(统一织网管理器),实际节点数为127个。这一高效配置确保了资源的最优利用与管理的便捷性。
4.5 更多配置
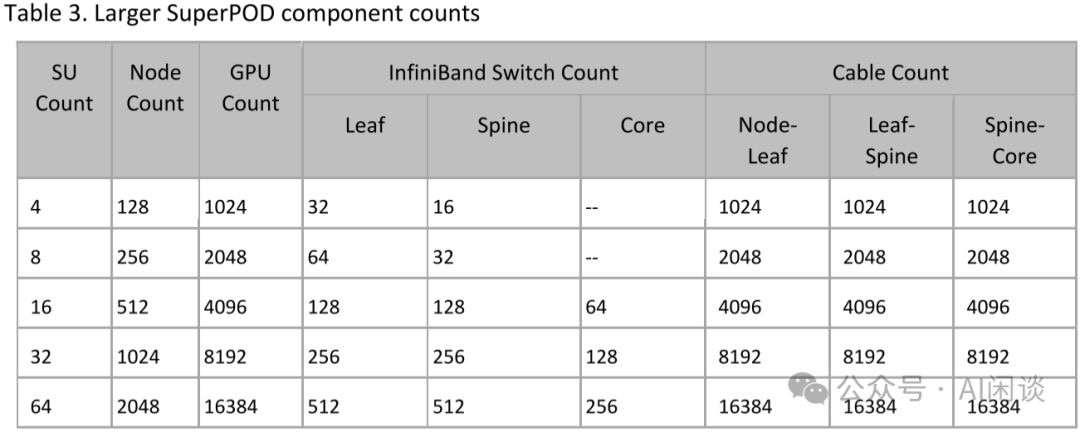
如Table 3所示,采用QM9700 Switch的2级Fat-Tree可构建2048 GPU无阻塞网络,支持8 SU;而3级Fat-Tree则能扩展至65536 GPU无阻塞网络。尽管潜力巨大,但本研究仅配置了64 SU,即16384 GPU,展示了技术的强大扩展性和实用性。
五、业内 GPU 训练集群方案
5.1 两层 Fat-Tree 拓扑
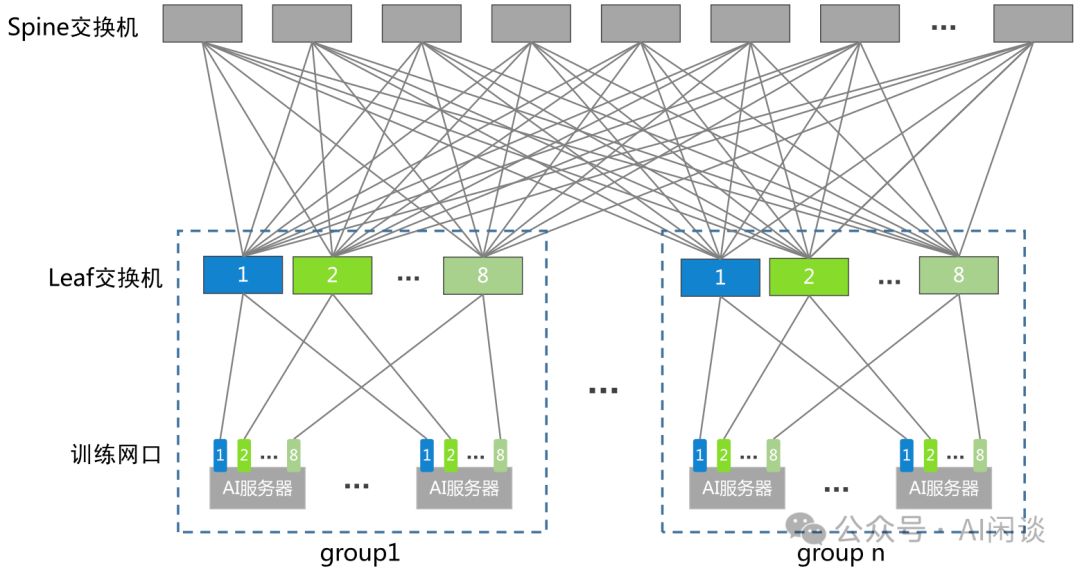
如图展示的是典型的两层无阻塞Fat-Tree(Spine-Leaf)拓扑结构。在训练中,常见的GPU机器配置8个GPU,通过NVLink+NVSwitch实现全互联,通信带宽远超网络。业内通常将同机8个GPU的网卡分散连接至不同交换机,确保高效互通。
- 每个Group包含8个Leaf Switch,每台机器配备8个GPU。若Leaf交换机拥有128个Port,为实现无阻塞,64个Port将直接连接至GPU网卡。因此,每个Group总计拥有512个GPU(64*8)。Leaf Switch 1专门连接所有Node的1号GPU网卡,以此类推。这一设计特性在分布式训练策略中可发挥巨大优势,为高效计算提供坚实基础。
- 为达成Spine Switch与Leaf Switch的全网状连接,每个Leaf Switch需与一个Spine Switch相连,共需64个Spine Switch。同时,每个Spine Switch需连接全部128个Leaf Switch。基于这一架构,共需构建16个连接组。这一设计确保了网络的高效性与稳定性,实现了全面覆盖的连接网络。
- 综合以上信息,系统支持高达192个128端口的交换机,并能连接最多8192个GPU,满足大规模数据处理需求。
5.2 FS 两层 Fat-Tree 拓扑
FS上展示的两层Fat-Tree标准解决方案,采用RoCE网络强化高性能计算,其拓扑与我们所知一致,仅以64端口交换机为核心。这一配置有效保障数据处理能力,是高效计算网络的理想之选。
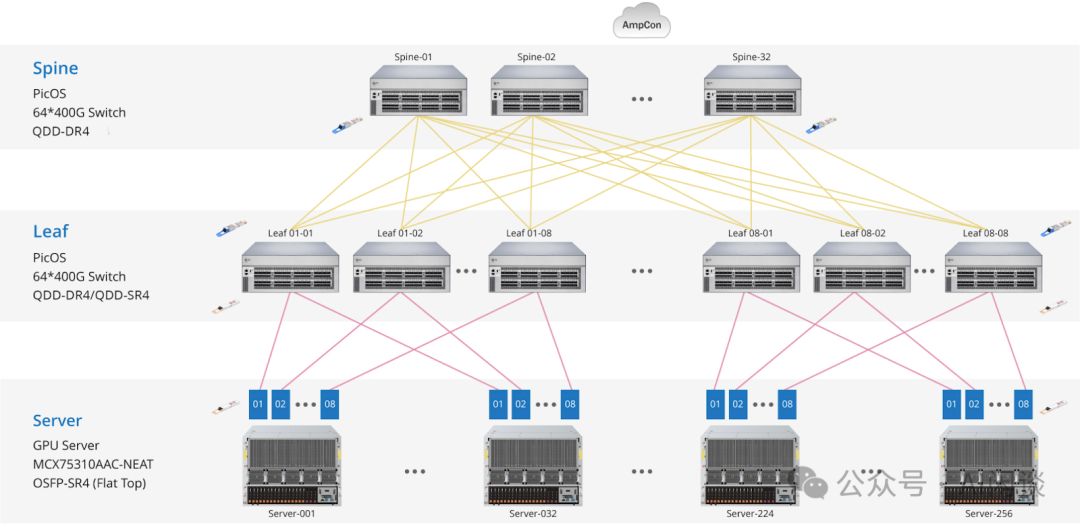
由于其采用的是 64 Port 400Gbps Switch,因此:
- Leaf,Spine Switch 都会减半,分别为 64 和 32
- 支持 GPU 数减到 1/4,为 2*(64/2)*(64/2)=2048
- 光模块总数为Switch端口数与网卡数(GPU数)之和,计算得(64+32)×64+2048=8192,实现高效数据传输与处理能力。
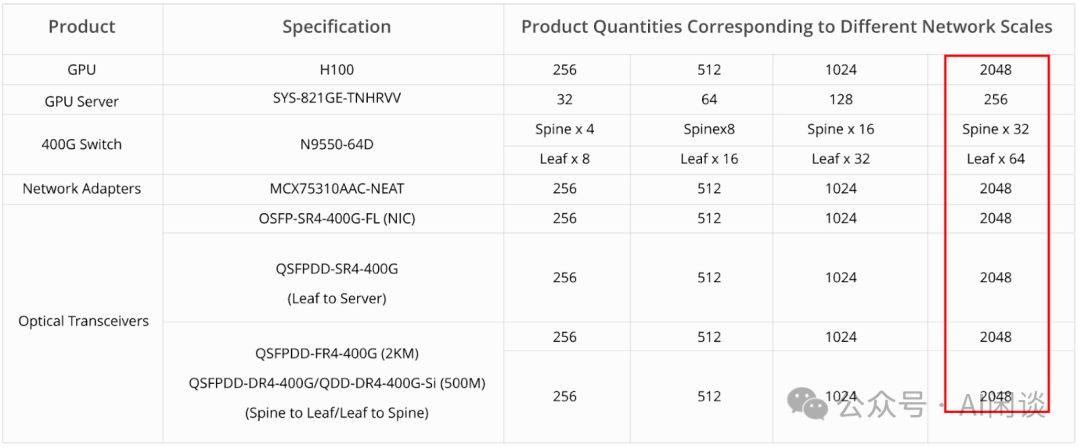
5.3 三层 Fat-Tree 拓扑
星融元发布的星智AI网络解决方案,专为LLM大模型承载网设计,采用三层无阻塞Fat-Tree拓扑(SuperSpine-Spine-Leaf),其中两层Spine-Leaf构成一个Pod,实现高效、稳定的数据传输。
- Spine Switch需半数Port连接SuperSpine,导致Group数减半。一Pod含64个Spine Switch,对应8个Group,进而拥有64个Leaf Switch,总计支持高达4096个GPU。这一配置高效利用资源,确保网络性能与扩展性的完美结合。
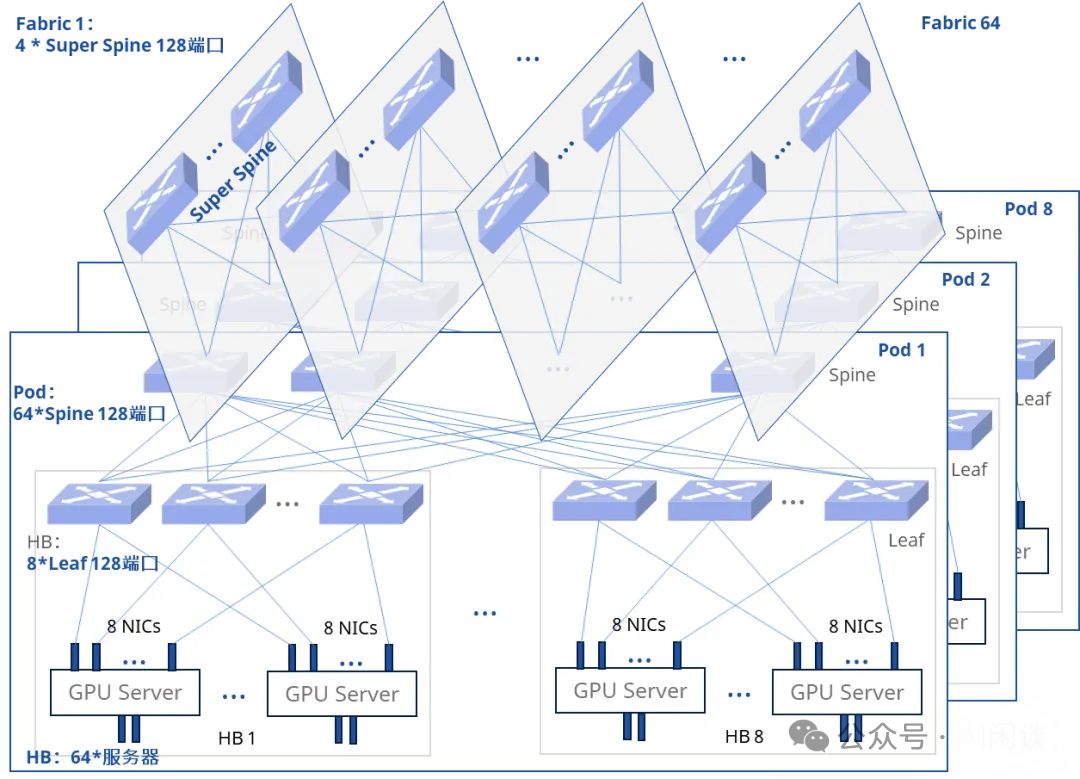
- 有了多个 Pod,可以进一步构建 64 个 SuperSpine Fabric,每一个 Fabric 要与不同 Pod 中的 Spine Switch 实现全互联。这里以 8 个 Pod 为例,将 8 个 Pod 里的第 i 个 Spine Switch 与 Fabric i 中的 SuperSpine Switch 实现 Full Mesh,这里有 8 个 Pod,因此一个 Fabric 中只需要 4 个 128 Port 的 SuperSpine Switch 即可。
- 以上配置 8 个 Pod 对应:
- 总的 GPU:4096*8=32768
- SuperSpine Switch:64*4=256
- Spine Switch:64*8=512
- Leaf Switch:64*8=512
- 总的 Switch:256+512+512=1280
- 总的光模块数:1280*128+32768=196608
- 实际上理论最多可以支持 128 个 Pod,对应的设备数为:
- GPU:4096*128=524288=2*(128/2)^3
- SuperSpine Switch:64*64=4096=(128/2)^2
- Spine Switch:64*128=8192=2*(128/2)^2
- Leaf Switch:64*128=8192=2*(128/2)^2
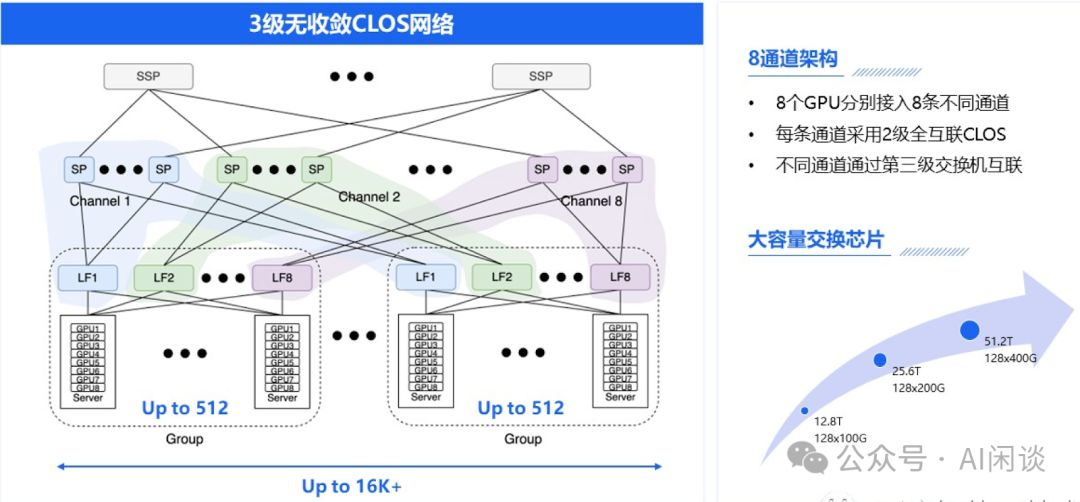
5.4 百度三层 Fat-Tree 拓扑
如下图所示为百度智能云(大规模AI 高性能网络的设计与实践)上介绍的三层 Fat-Tree 无阻塞网络。可以看出与上述介绍的稍有不同,Spine Switch 和 Leaf Switch 之间采用了分组 Full Mesh,也就是所有 Group 中的第 i 个 Leaf Switch 与 Channel i 中的 Spine Switch 实现 Full Mesh(和上面介绍的 SuperSpine 与 Spine 的连接方式类似)。然后在 SuperSpine 和 Spine 之间继续采用分组 Full Mesh。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-















![[C语言]自定义类型详解:结构体、联合体、枚举](https://img-blog.csdnimg.cn/direct/98e2b0b2dcc444b59dabcd1a48b1830b.png)