note
在真实场景下,我们进行测试,多模态大模型在处理显著文本时表现尚可,但在处理细粒度文本时往往效果并不太好,why?
具体原因如下:
首先,视觉编码器的分辨率对于多模态大模型的性能影响较大,由于视觉信息往往包含大量的细节和复杂性,因此需要高分辨率的编码器来捕捉这些细节。但是,高分辨率编码器的计算成本也相应较高,这会限制模型的训练速度和效率。
其次,现有的模型主要依赖于大规模的预训练数据集进行训练,而这些数据集往往只包含一些大规模常规或者合成的图像和文本,比如论文arxiv。因此,这些模型可能无法很好地处理一些细粒度文本,因为它们没有在训练数据集中见过这些类型的文本。
最后,多模态模型主要关注图像和文本之间的跨模态对应关系,因此可能忽略了文本内部的一些细粒度信息。当然,正因为这些问题,多模态也存在所有大模型容易出现的问题,也就是幻觉问题,喜欢出现多字、少字甚至胡说八道的问题。
文章目录
- note
- 零、多模态LLM用于文档识别的可行性
- 一、RAG中图像的处理
- 二、RAG中表格的处理
- 三、微调文档图表理解LLM
- 1. 图表-数据对构造
- (1)mPLUG-DocOwl 1.5
- (2)OneChart中的数据工程
- (3)ChartAssisstant的图表数据生成
- 2. 微调图表理解-多模态LLM
- Reference
零、多模态LLM用于文档识别的可行性
如果是简单图表,使用OCR就能解决。如果是复杂图表,有几个难点,比如:假如图表中,不给出每个点的数值,只有x-y轴的刻度,以及每个点在这个刻度中的视觉坐标,就能估算出来其准确数值么?如果有,那么其就具备了从像素点到刻度值之间的复杂计算逻辑的能力,但这个估计会很难。
hard case1:

hard case2:给定一个饼图,不标注出比例,大模型是否可以补全?其涉及到每块区域角度的划分问题。下图希望根据已知的36%,多模态LLM是否可以根据对应区块与该区块大小的比例算出数值,并且保证整个比例图和为1?

像GPT-4V、GeminiPro、Qwen1.5-72B、Yi-VL-34B以及LLaVA-Next-34B等大模型,不管是闭源还是开源,语言模型还是多模态,可以只根据在多模态基准MMMU测试中的问题和选项文本,就能获得不错的成绩。
这其实也很自然,因为图片本身就是对语言的一种补充,图中所呈现的信息,通常都会有别处用文本进行了阐述,而多模态大模型M通常由一个vision encoder,一个语言模型,以及一个视觉-语言连接件组成,现有的多模态benchmark中有大量的评估样本是从单模态的文本语料中转化过来,因此,大语言模型的训练数据中无意间泄露了多模态benchmark中转化不充分的评估样本,所以自然会出现这种情况。
参考:多模态大模型到底理不理解文档图表?兼谈RAG如何解决全局摘要问答类问题
一、RAG中图像的处理
重点:文档理解前沿方案及版式分析开源数据:三种模式、九大数据集
重点:基于大模型的OCR-free方案
对于“图像”元素,利用“gpt-4-vision-preview”API,生成特定查询,提示GPT提供图像的详细文本描述,取代图像最初占据的位置。
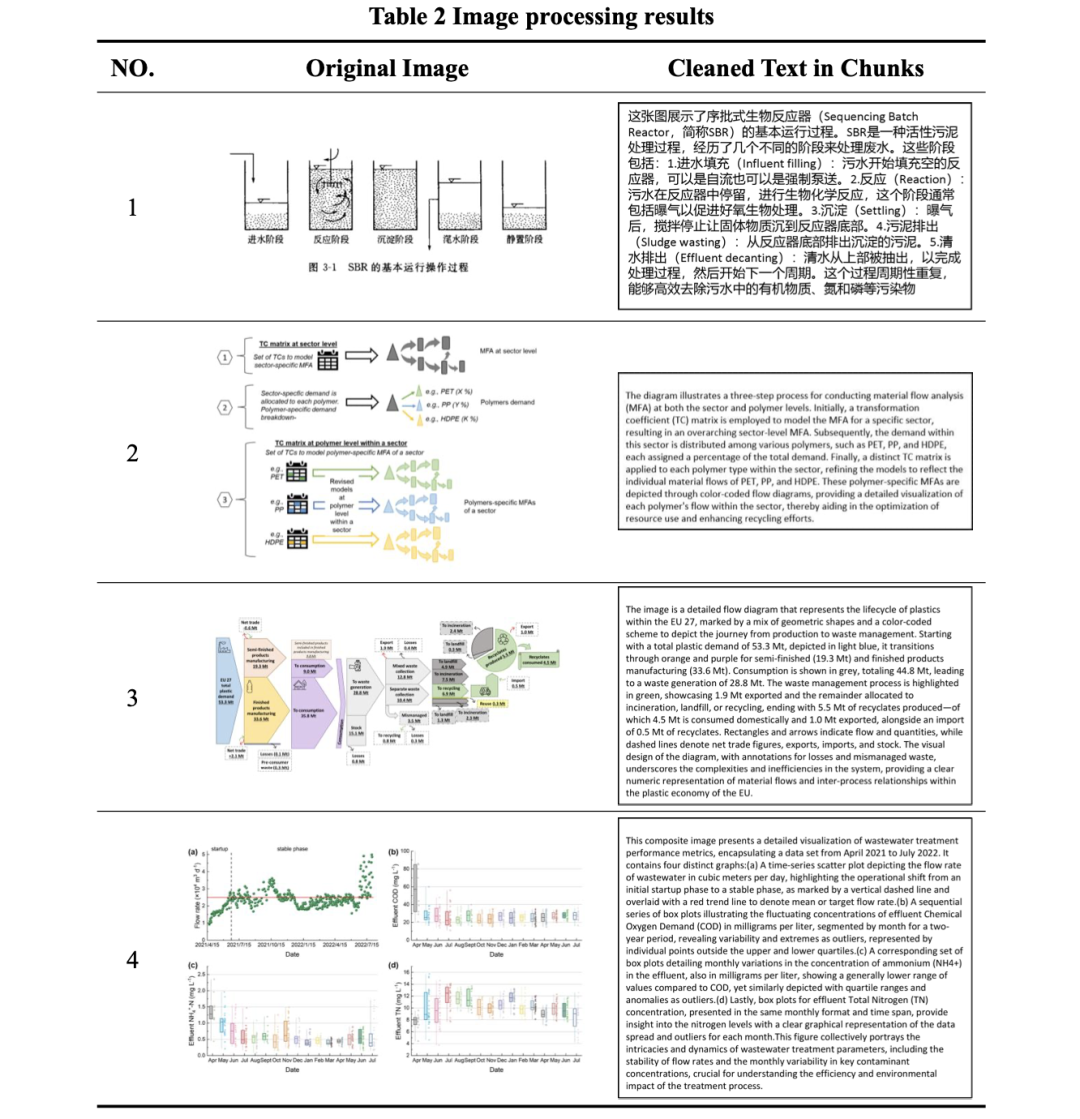
二、RAG中表格的处理
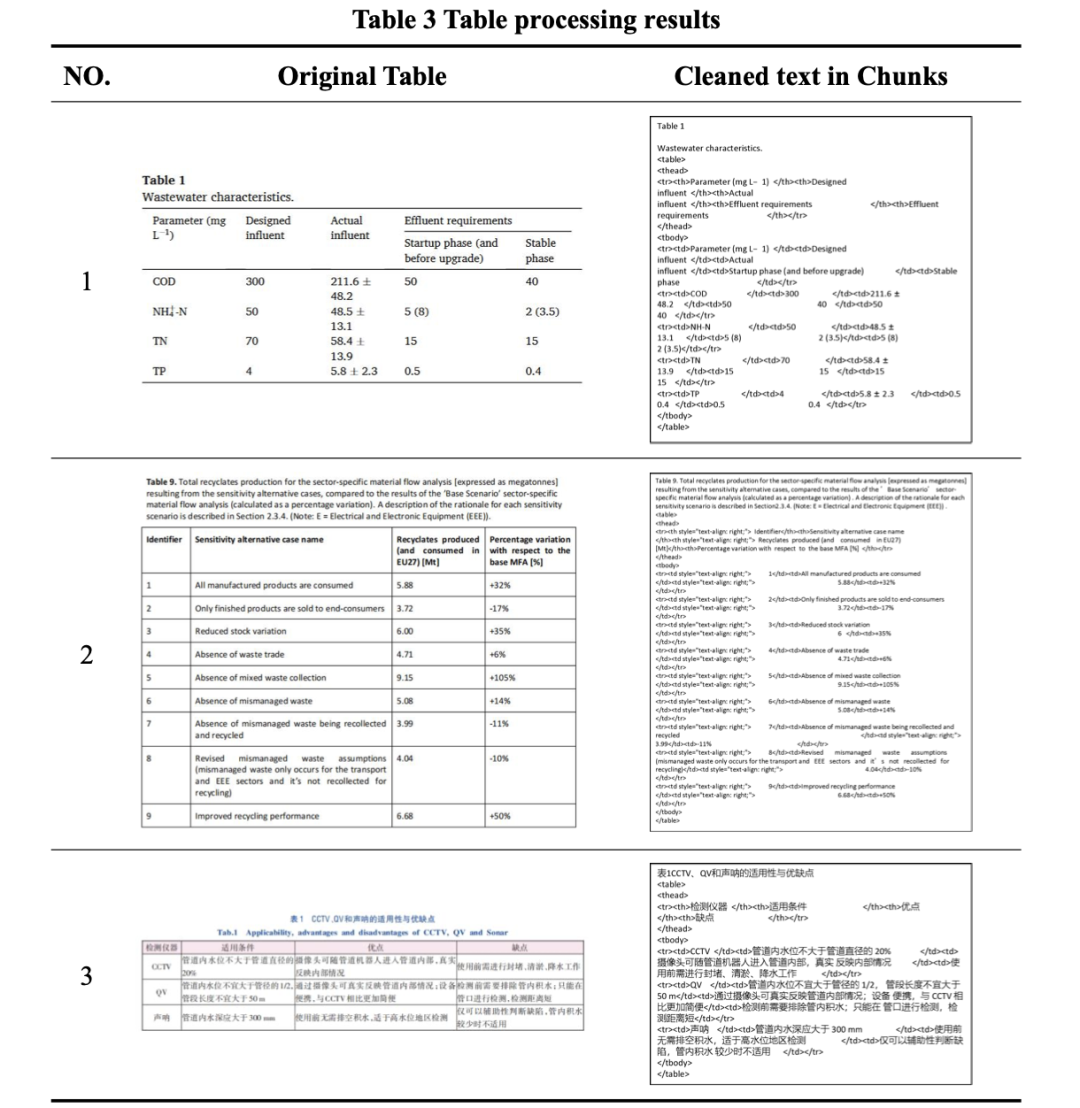
(1)为了表格的格式保真度,存储了其HTML表示,可以具象化如下:
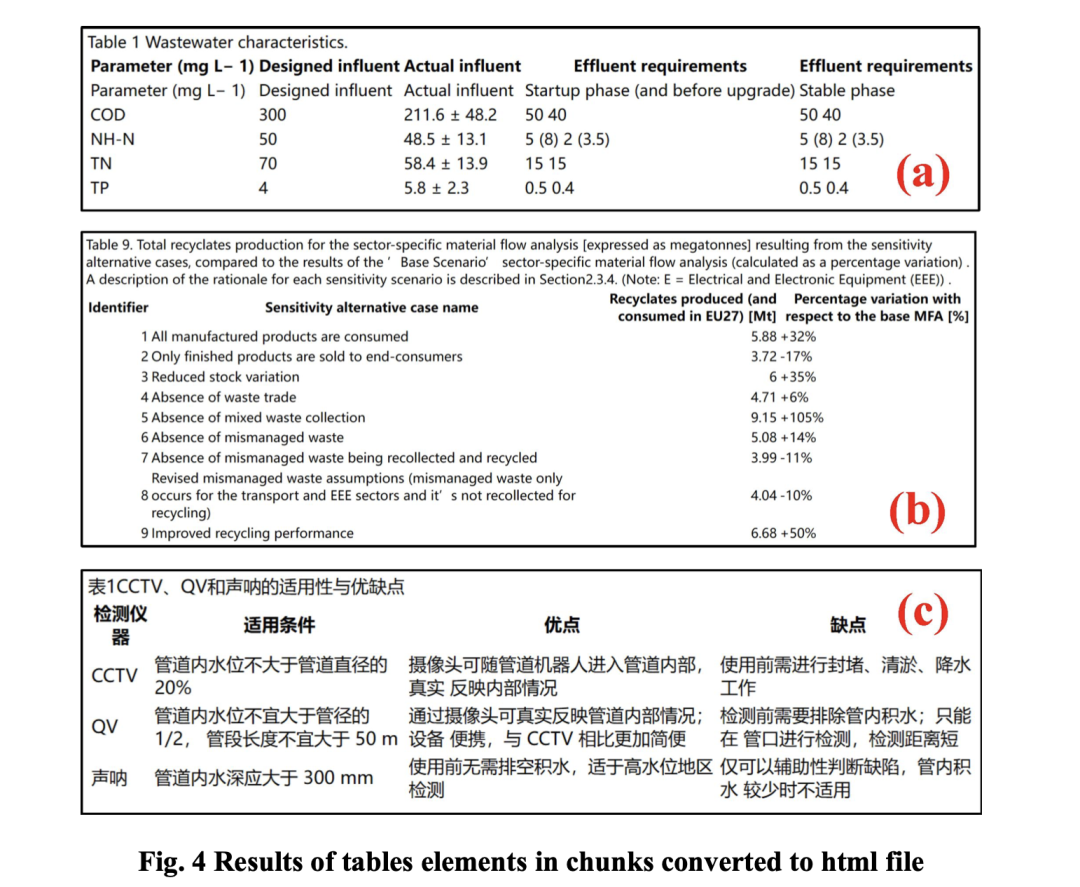
(2)这类数据也可以转成html格式进行渲染
(3)许多工具都已天然支持,例如llama_parse:https://docs.llamaindex.ai/en/stable/module_guides/loading/connector/llama_parse.html,以及ragflow(https://github.com/infiniflow/ragflow.git)

三、微调文档图表理解LLM
1. 图表-数据对构造
(1)mPLUG-DocOwl 1.5
阿里达摩院的工作。设计了视觉到文本模块H-Reducer,旨在保留布局信息的同时,还能通过卷积合并水平相邻的块来减少视觉特征的长度,从而使LLM更高效地理解高分辨率图像。
论文:《mPLUG-DocOwl 1.5: Unified Structure Learning for OCR-free Document Understanding》(https://arxiv.org/pdf/2403.12895.pdf)
项目:https://github.com/X-PLUG/mPLUG-DocOwl/tree/main/DocOwl1.5
(1)mPLUG-DocOwl 1.5:
- DocOwl1.5由mPLUG-Owl2初始化,使用ViT/L-14作为视觉编码器,并使用带有模态自适应模块的7B大模型作为解码器。根据长宽比和分辨率,每幅图像最多裁剪成9幅子图像,分辨率固定为448x448。每个子图像由ViT/L-14编码为1,024个特征,然后由H-Reducer缩减为256个特征。
- 两阶段训练如下图(a),整体模型架构如下图(b),全局图像和裁剪图像由视觉编码器和H-Reducer独立处理。< rowx-coly >是一种特殊的文本标记,用于表示裁剪后的图像在原始图像中的位置是第x行和第x列。
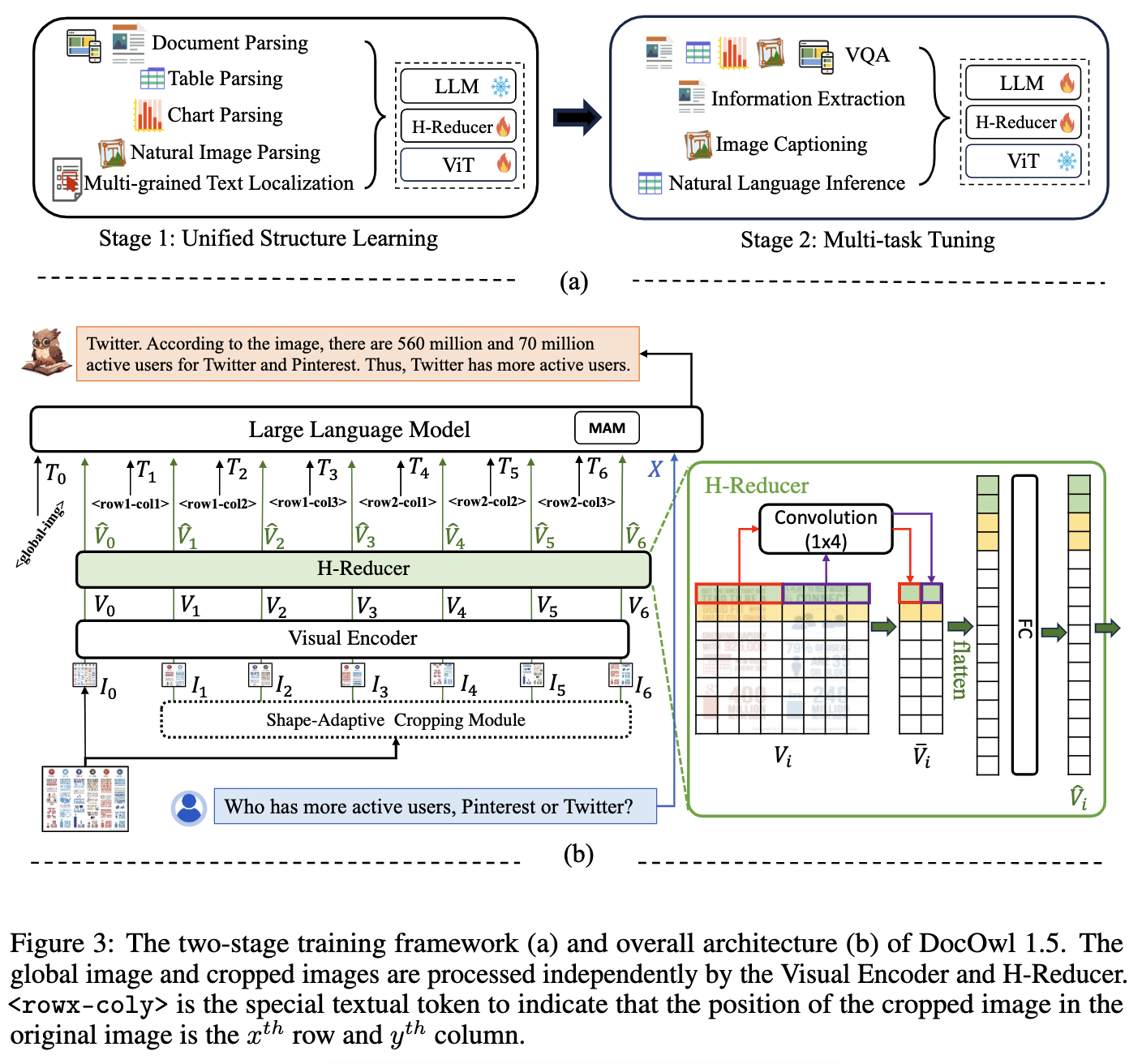
(2)Unified Structure Learning of DocOwl 1.5:
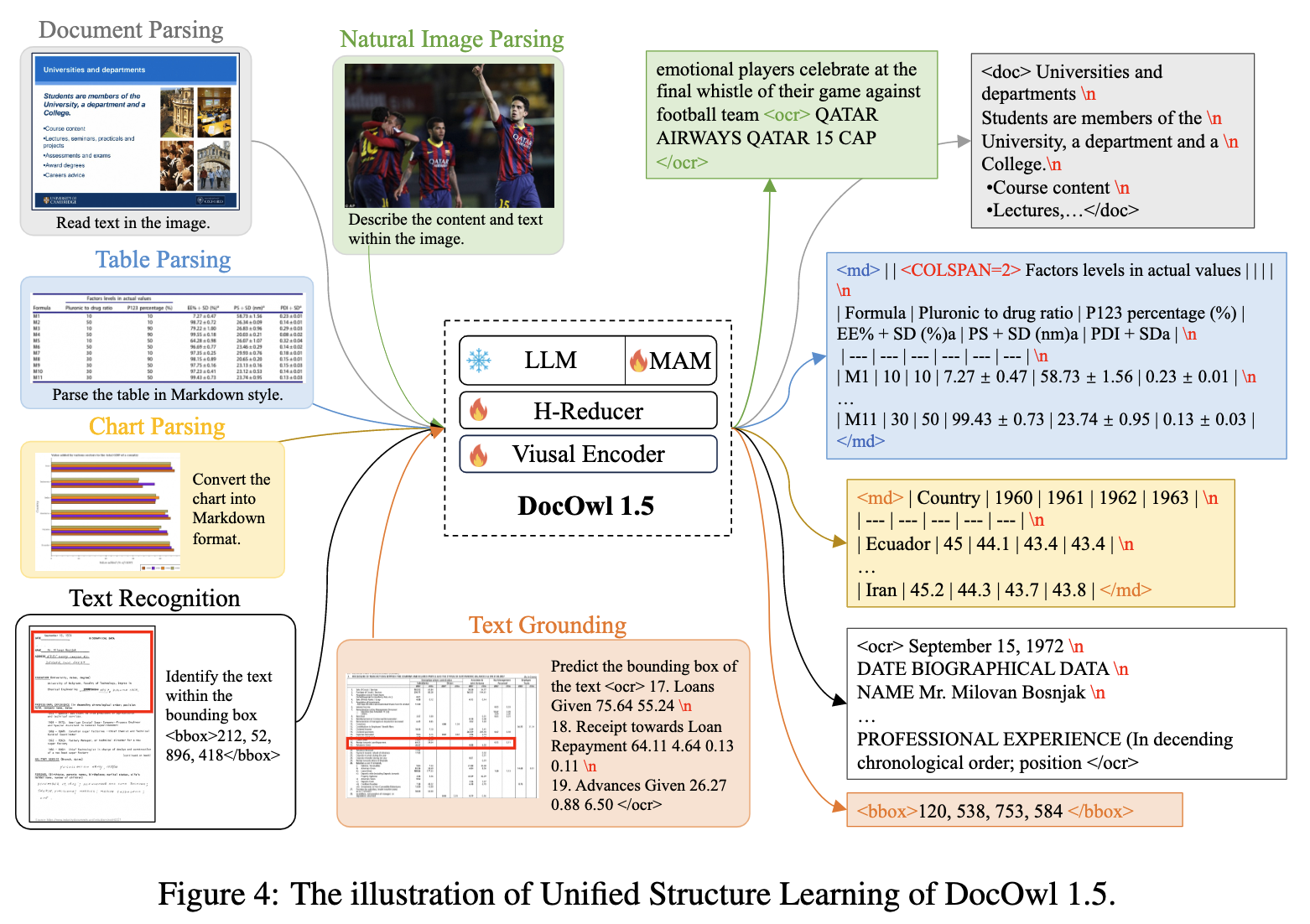
数据:构建DocStruct4M数据集(图文数据集),该工作设计了一个跨5个领域的统一结构学习,包括自然图像、文档、表格、图表和网页。它包括结构感知解析任务和多粒度文本本地化任务。
- 文档分析(Document Parsing):为了表示结构信息,Pix2Struct使用压缩的HTML DOM树解析网页截图,这些树是基于HTML源代码构建的,不适用于其他格式的文档或网页截图,例如PDF。
- 表分析(Table Parsing):与文档或网页不同,表的结构更加标准化,其中行和列的对应关系表示键值对。HTML和Markdown代码主要是用于表示表的两种文本序列。
- 图表分析(Chart Parsing):为了与表解析任务保持一致,该工作还使用Markdown代码来表示图表的数据表,该工作采用PlotQA、FigureQA、DVQA和ChartQA来支持结构感知的图表解析任务。图表类型包括竖线、水平线、直线、点线和饼图。图表的源数据以JSON或CSV格式提供,两者都可以方便地转换为Markdown代码。
- 自然图像分析(Natural Image Parsing):利用OCR-CC来支持自然图像解析任务,OCR-CC是概念标题的一个子集,它包含由Microsoft Azure OCR系统检测到的带有场景文本的图像。
- 多粒度文本本地化(Multi-grained Text Localization)
(3)相关数据集:
数据集已经开源,可以在huggingface以及modelscope中下载:
- DocStruct4M:https://huggingface.co/datasets/mPLUG/DocStruct4M
- DocDownstream-1.0:https://huggingface.co/datasets/mPLUG/DocDownstream-1.0
- DocReason25K:https://huggingface.co/datasets/mPLUG/DocReason25K
- DocLocal4K:https://huggingface.co/datasets/mPLUG/DocLocal4K
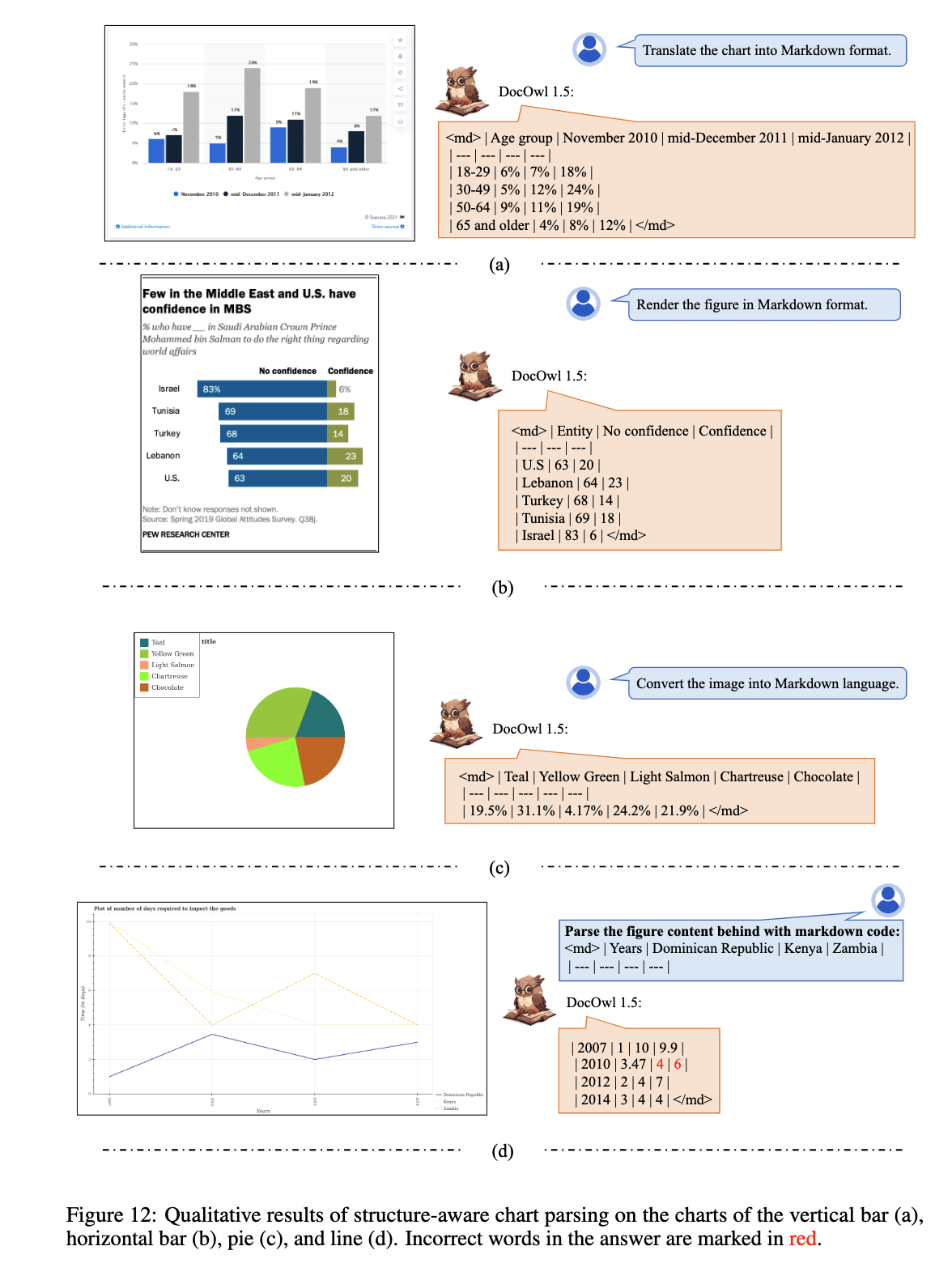
(4)模型效果,将图表转为markdown,最后一个example的红色数字是错误数字:
(2)OneChart中的数据工程
论文:《OneChart: Purify the Chart Structural Extraction via One Auxiliary Token》
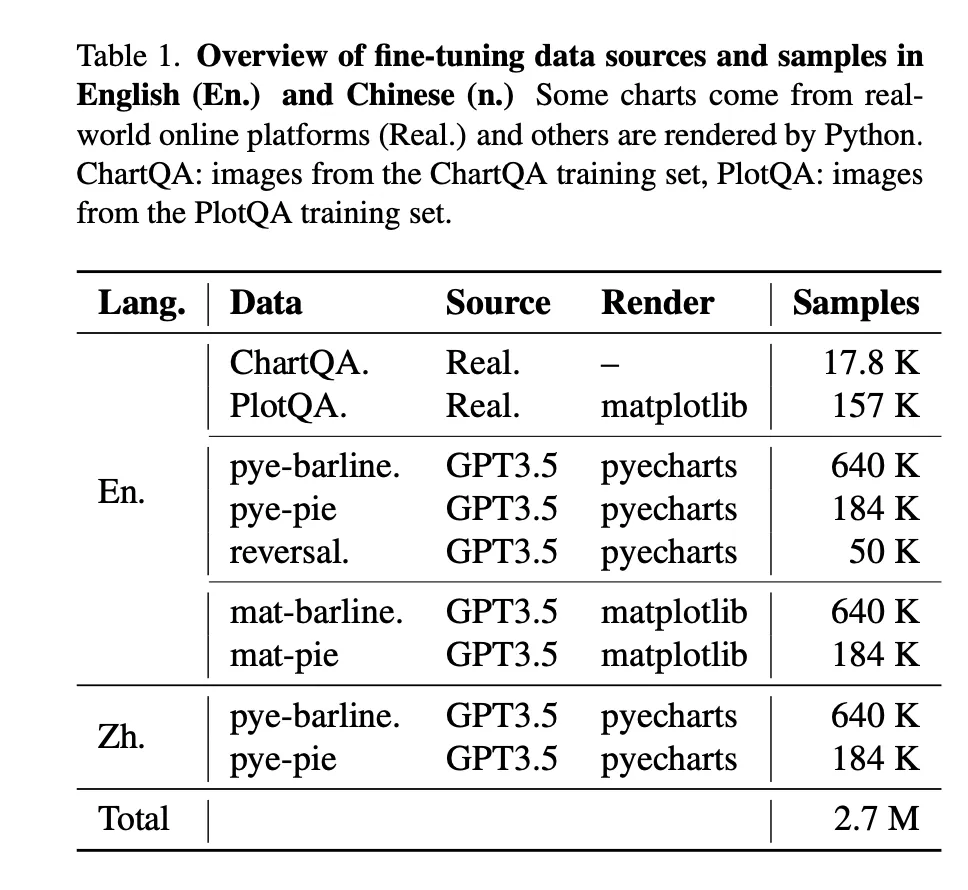
工作:在图表数据生成方面,除了来自ChartQA等在线平台的图表数据外,大多数图表数据都是通过Matplotlib和Pyecharts等工具生成的。共产生1000万个图表图像,生成的数据主要分为两大类:柱状图和饼状图。其中,柱状线图分为五种不同类型:单柱图、多柱图、单线图、多线图和组合图(混合图)。每种类型都平均分为具有数字标签和不具有数字标签的可视化图表。
(3)ChartAssisstant的图表数据生成
论文:《ChartAssisstant: A Universal Chart Multimodal Language Model via Chart-to-Table Pre-training and Multitask Instruction Tuning》
链接:https://arxiv.org/pdf/2401.02384.pdf
- 使用ChartQA和PlotQA中的表格的各种可视化工具重新绘制图表:利用Python中的5个API,包括gg-plot、plotly、matplotlib、seaborn和pyecharts,以及颜色、大小、字体类型、背景等参数的20多个变体,风格增强后,分别创建220050条图表文本数据,用于从PlotQA进行图表到表格的转换。
- 还利用arXiv论文中的表格,为了收集更多真实的表格数据以增加主题多样性,因此从arXiv平台抓取了1301932篇涉及计算机科学、生物学、金融等各个主题的论文。对于每篇论文,从源LaTeX代码中提取表格,其中表格数据可以在表格环境中本地化。
- 使用ChatGPT将Latex表转换为Markdown表
2. 微调图表理解-多模态LLM
论文:From Pixels to Insights: A Survey on Automatic Chart Understanding in the Era of Large Foundation Models
链接:https://arxiv.org/pdf/2403.12027
2024年3月的论文,比较新。
训练方式:小模型就多任务pretrain和微调,大模型直接SFT和推理。
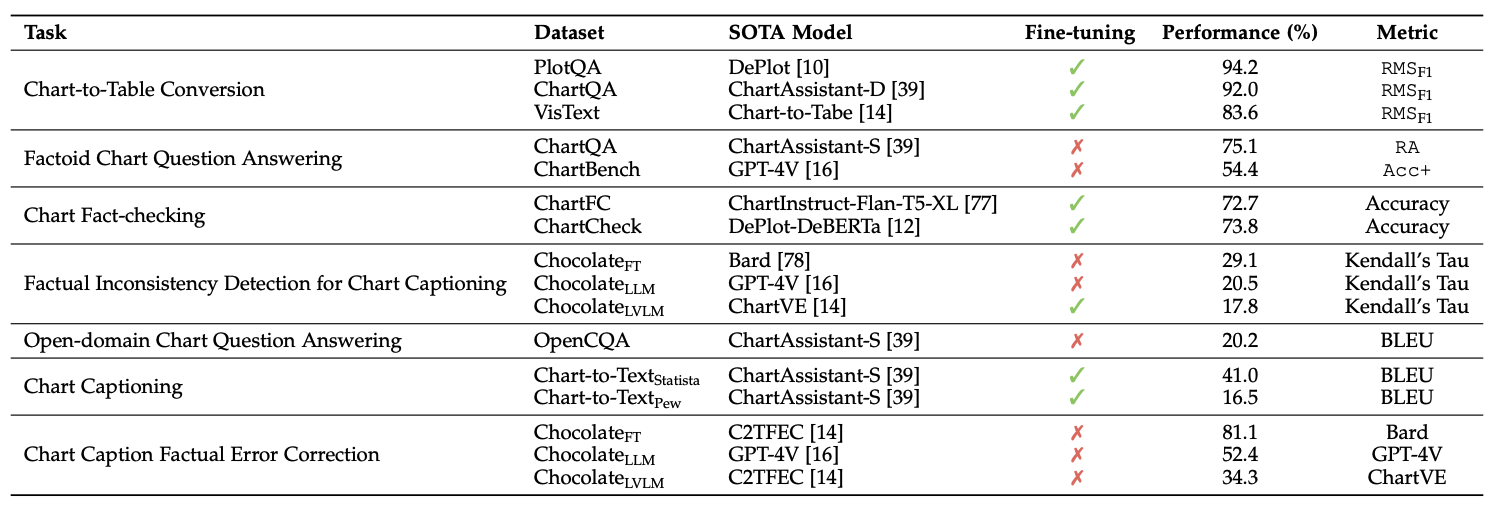
当前各任务的sota模型的performance和评估指标:
Reference
[1] 多模态大模型到底理不理解文档图表?兼谈RAG如何解决全局摘要问答类问题
[2] 也看跨模态大模型文档图表理解的数据工程:UniChar、MATCHA等代表模型的数据构造方案
[3] 如何运用大模型进行文档图表Chart理解:兼看20240321年大模型进展早报
[4] 也看跨模态大模型遇见文档理解:mPLUG-DocOwl1.5及TextMonkey方案中的数据工程
[5] 2023 第十二届中国智能产业高峰论坛 - 文档大模型的未来展望
[6] 跨模态大模型遇见文档理解:mPLUG-DocOwl1.5及TextMonkey方案中的数据工程
[7] 四个Llama3中文微调版本的衍生:继续看文档图表理解大模型中的图表-数据对构造方案
[8] 文档图表理解的数据工程:UniChar、MATCHA等代表模型的数据构造方案
[9] 再看文档理解跨模态大模型中的数据工程:UniDoc、DocPedia及TGDoc
[10] 文档图表理解的思路及若干问题?,里面还有其他内容。
OCR大一统模型前沿研究速览:
1、Donut:无需 OCR 的用于文档理解的 Transformer模型:https://link.springer.com/chapter/10.1007/978-3-031-19815-1_29,https://github.com/clovaai/donut
2、NouGAT:实现文档图像到文档序列输出:https://arxiv.org/abs/2308.13418,https://github.com/facebookresearch/nougat
3、SPTS v3基于SPTS的OCR大一统模型:https://arxiv.org/abs/2112.07917,https://github.com/shannanyinxiang/SPTS