前言
目的是要了解pytorch如何完成模型训练
https://github.com/TingsongYu/PyTorch-Tutorial-2nd参考的学习笔记
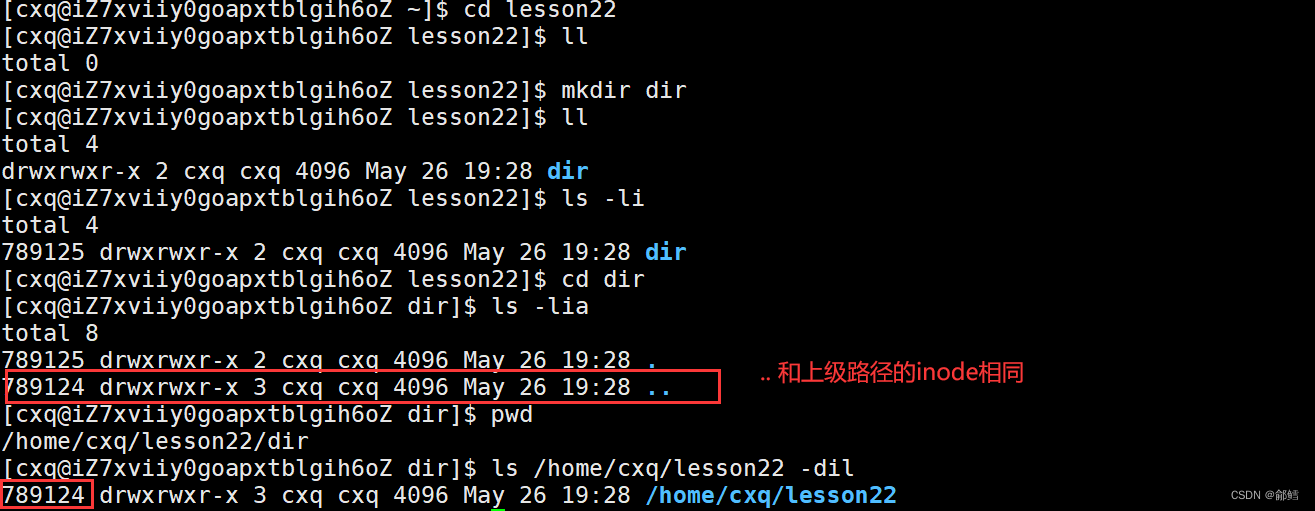
数据准备
由于本案例目的是pytorch流程学习,为了简化学习过程,数据仅选择了4张图片,分为2类,正常与新冠,训练集2张,
验证集2张。标签信息存储于TXT文件中。具体目录结构如下:
注意:
covid-19的图可以找到但是no-finding两张图没有找到
covid-19-1
covid-19-2
no-finding的图随便照两张看着正常的,别问我哪个是正常的,我也不知道(❍ᴥ❍ʋ),需要改名字为00001215_000.png,00001215_001.png
├─imgs
│ ├─covid-19
│ │ auntminnie-a-2020_01_28_23_51_6665_2020_01_28_Vietnam_coronavirus.jpeg
│ │ ryct.2020200028.fig1a.jpeg
│ │
│ └─no-finding
│ 00001215_000.png
│ 00001215_001.png
│
└─labelstrain.txtvalid.txt
创建标签文件:
创建 train.txt 和 valid.txt 文件,并填入图片路径和标签信息
- train.txt:
covid-19/auntminnie-a-2020_01_28_23_51_6665_2020_01_28_Vietnam_coronavirus.jpeg 1
no-finding/00001215_000.png 0- valid.txt:
covid-19/ryct.2020200028.fig1a.jpeg 1
no-finding/00001215_001.png 0
完整代码示例:
以下是准备数据集、定义模型和训练模型的完整代码示例:
import os
from PIL import Image
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F# 自定义数据集类
class COVID19Dataset(Dataset):def __init__(self, img_dir, label_file, transform=None):self.img_dir = img_dirself.transform = transformself.img_labels = []with open(label_file, 'r') as f:lines = f.readlines()for line in lines:self.img_labels.append(line.strip().split())def __len__(self):return len(self.img_labels)def __getitem__(self, idx):img_path, label = self.img_labels[idx]img_path = os.path.join(self.img_dir, img_path)image = Image.open(img_path).convert('RGB')label = int(label)if self.transform:image = self.transform(image)return image, label# 图像预处理
transform = transforms.Compose([transforms.Resize((8, 8)),transforms.ToTensor()
])# 创建数据集和数据加载器
train_dataset = COVID19Dataset(img_dir='imgs', label_file='labels/train.txt', transform=transform)
train_loader = DataLoader(train_dataset, batch_size=2, shuffle=True)valid_dataset = COVID19Dataset(img_dir='imgs', label_file='labels/valid.txt', transform=transform)
valid_loader = DataLoader(valid_dataset, batch_size=2, shuffle=False)# 定义简单卷积神经网络
class SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()self.conv1 = nn.Conv2d(3, 1, kernel_size=3) # 输入通道为3(RGB),输出通道为1,卷积核大小为3x3self.fc1 = nn.Linear(1 * 6 * 6, 2) # 全连接层,输入大小为6*6*1,输出大小为2(2类)def forward(self, x):x = self.conv1(x)x = F.relu(x)x = x.view(-1, 1 * 6 * 6) # 展平操作x = self.fc1(x)return xmodel = SimpleCNN()# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练函数
def train(model, train_loader, criterion, optimizer, epoch):model.train()running_loss = 0.0for batch_idx, (data, target) in enumerate(train_loader):optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()running_loss += loss.item()if batch_idx % 10 == 9:print(f'Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)}] Loss: {running_loss / 10:.6f}')running_loss = 0.0# 验证函数
def validate(model, valid_loader, criterion):model.eval()validation_loss = 0.0correct = 0with torch.no_grad():for data, target in valid_loader:output = model(data)validation_loss += criterion(output, target).item()pred = output.argmax(dim=1, keepdim=True)correct += pred.eq(target.view_as(pred)).sum().item()validation_loss /= len(valid_loader.dataset)print(f'\nValidation set: Average loss: {validation_loss:.4f}, Accuracy: {correct}/{len(valid_loader.dataset)} ({100. * correct / len(valid_loader.dataset):.0f}%)\n')# 训练和验证
for epoch in range(1, 11):train(model, train_loader, criterion, optimizer, epoch)validate(model, valid_loader, criterion)
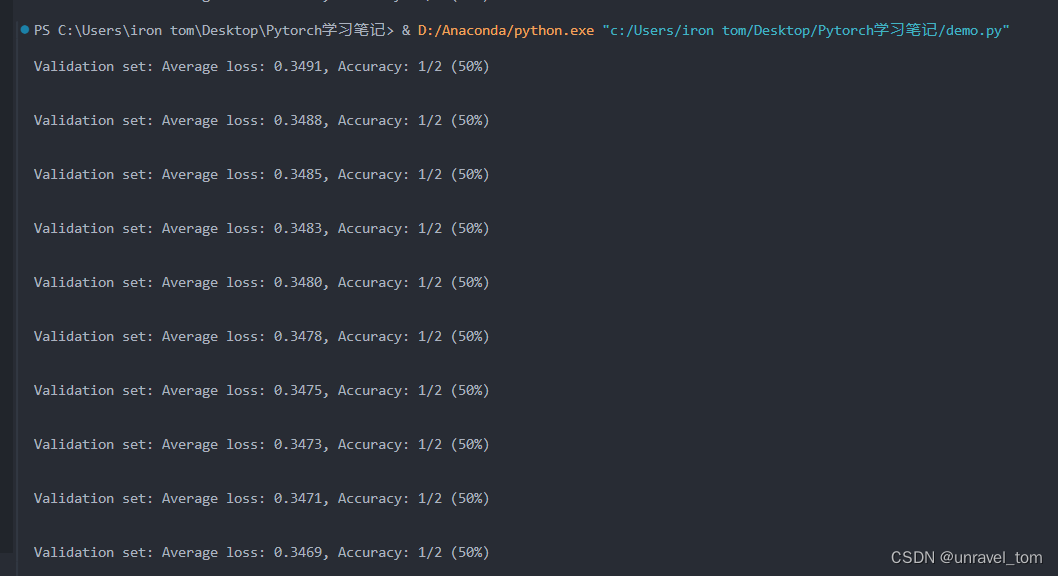
效果展示:
由于数据量少,随机性非常大,大家多运行几次,观察结果。不过本案例结果完全不重要!)可以观看Average loss变化,Accuracy由于训练数据过少几乎不会变化
知识点总结
1. 数据
- Q:要知道pytorch需要模型的格式
A:需要编写代码完成数据的读取,转换成模型能够读取的格式。在 PyTorch 中,读取数据通常通过自定义 Dataset 类和内置的 DataLoader 来实现。这种方法既灵活又高效,适用于各种类型的数据集。 - Q:自己如何编写Dataset?
A:编写一个自定义的 Dataset 类,需要继承 torch.utils.data.Dataset 并实现三个方法:__init__、__len__和__getitem__。
2. 模型
可参考:
从“卷积”、到“图像卷积操作”、再到“卷积神经网络”,“卷积”意义的3次改变_哔哩哔哩_bilibili
- Q: 卷积层,全连接层的作用是什么?
A: 卷积层提取特征,全连接层进行分类。- 卷积层:
- 卷积层的作用是提取输入图像的特征。
- 使用
3x3的卷积核进行卷积操作,可以捕捉到局部的空间特征。 - 卷积操作后的输出会产生一个新的特征图,这个特征图是卷积层提取到的特征表示。
- 全连接层:
- 全连接层的作用是将卷积层提取到的特征进行进一步的处理,最终输出分类结果。
- 在这个例子中,全连接层有两个神经元,分别输出两个分类的概率。
- 全连接层的输入被限制在
8x8,这意味着输入的特征图经过扁平化(flatten)后被映射到一个8x8的向量。
3. 优化
- Q:根据什么规则对模型的参数进行更新学习呢?
A:常用的方法:交叉熵损失函数(CrossEntropyLoss)、随机梯度下降法(SGD)和按固定步长下降学习率策略(StepLR)
4. 迭代
- Q:怎么进行模型迭代?
A: 有了模型参数更新的必备组件,接下来需要一遍又一遍地给模型喂数据,监控模型训练状态,这时候就需要for循环,不断地从dataloader里取出数据进行前向传播,反向传播,参数更新,观察loss、acc,周而复始。
总结
详细内容https://github.com/TingsongYu/PyTorch-Tutorial-2nd可查看,这是一篇读书笔记,与代码实现的分享。后续的笔记会以Q-A解决一些问题





![[Algorihm][简单多状态DP问题][买卖股票的最佳时机含冷冻期][买卖股票的最佳时机含手续费]详细讲解](https://img-blog.csdnimg.cn/direct/05f6e39d6ed2412f9876add4ce3e6342.png)