决策树
决策树是一种强大的机器学习算法,它通过模拟人类决策过程来解决分类和回归问题。这种算法的核心在于它如何将数据集细分,直至每个子集足够“纯净”,即包含的实例都属于同一类别或具有相似的数值范围。
- 开始于根节点:决策过程始于包含整个数据集的根节点。
- 特征选择:算法评估每个特征,以确定哪个特征的分割能够最大化数据集的“纯度”。这通常通过计算信息增益、基尼不纯度或熵来实现。
- 分割数据:根据所选特征的最佳分割点,数据集被划分为两个或多个更小的子集。
- 递归过程:对每个子集重复上述过程,继续分割直至满足停止条件,如达到预设的最小样本量、最大树深度或当子集内所有实例属于同一类别。
- 叶节点生成:当停止条件满足时,当前节点成为叶节点,该节点代表了一个决策结果或预测类别。
决策树的应用场景:
- 分类任务:决策树可以用来预测离散的输出变量,如判断一封电子邮件是否为垃圾邮件。
- 回归任务:决策树也适用于预测连续的输出变量,如房价预测。
- 数据探索:它们提供了数据的洞察,帮助理解不同特征是如何影响输出的。
- 可视化:决策树易于可视化,使得模型的决策过程对非技术用户也易于理解。
决策树的优势:
- 易于理解和解释:决策树的结构清晰,可以直观地展示特征与结果之间的关系。
- 处理各种数据:可以处理数值型和类别型数据,且不需要太多的数据预处理。
- 避免过拟合:通过剪枝等技术,可以控制决策树的复杂度,减少过拟合的风险。
决策树的局限性:
- 对噪声敏感:决策树可能对训练数据中的噪声过于敏感,导致模型在新数据上表现不佳。
- 可能产生偏见:如果某些特征在训练数据中分布不均,决策树可能会产生偏见。
- 依赖于特征选择:模型的性能很大程度上取决于特征选择的策略。
在机器学习项目中,决策树是一个多功能的工具,适用于从简单的问题到复杂的预测任务。然而,为了获得最佳性能,通常需要结合其他算法或集成方法,如随机森林或梯度提升决策树,以提高模型的准确性和鲁棒性。
决策树的格式
决策树是 很像流程图。 要使用流程图,从图表的起点或根开始,然后根据您如何回答该起始节点的过滤条件,移动到下一个可能的节点之一。 重复这个过程直到到达终点。
决策树的运行方式基本相同,树中的每个内部节点都是某种测试/过滤标准。 外部的节点,即树的端点,是相关数据点的标签,它们被称为“叶子”。 从内部节点通向下一个节点的分支是特征或特征的合取。 用于对数据点进行分类的规则是从根到叶的路径。
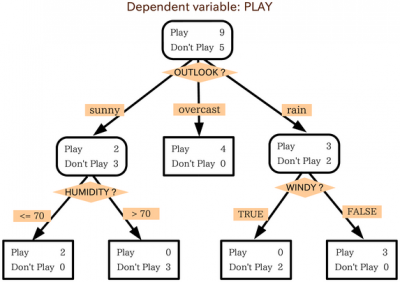
决策树算法
决策树是一种精巧的算法,它通过一系列基于数据特征的分割,将整个数据集细分至单独的数据点。这一过程利用了数据集中的多个变量或特征,以实现精准的分类或回归。
在决策树的构建中,"递归二元分割"是一种核心机制。该机制始于根节点,通过数据集中的特征数量来确定潜在的分割点。分割策略旨在最小化准确度损失,确保每次分割都尽可能地保持数据的纯净性。这一过程以递归方式执行,不断应用相同的策略来形成子集。
决策树的分裂成本由特定的成本函数确定。对于回归问题,通常采用均方误差(MSE)作为成本函数,其公式为:
c o s t = ∑ ( y − prediction ) 2 cost = \sum (y - \text{prediction})^2 cost=∑(y−prediction)2
该预测是基于特定数据点组内训练数据响应的平均值。对于分类问题,则使用基尼不纯度(Gini impurity)作为成本函数,表达式如下:
G = ∑ ( p k × ( 1 − p k ) ) G = \sum (p_k \times (1 - p_k)) G=∑(pk×(1−pk))
基尼分数衡量了分割后各组的混合程度,其中( p_k )代表分割产生的组中第( k )类的实例比例。理想情况下,每个分割产生的组仅包含单一类别的输入,此时基尼分数达到最优。
决策树的分裂过程在所有数据点均被归类为叶子时终止。然而,为了预防过拟合,通常需要在树生长到一定规模时采取措施停止其扩展。这可以通过设定最小数据点数量或限制树的最大深度来实现。
决策树的剪枝是提升模型性能的另一关键步骤。通过剪除那些对模型预测能力贡献不大的分支,可以降低树的复杂性,减少过拟合的风险,从而提高模型的预测效能。
剪枝过程可以自上而下或自下而上进行。一种简便的剪枝方法是从叶子节点开始,尝试移除那些包含最常见类别的节点。如果这样的操作不会降低模型的准确性,则可以保留这一更改。此外,还有多种剪枝技术可供选择,但减少错误剪枝通常是最常用的方法。
使用决策树的注意事项
决策树 经常有用 当需要进行分类但计算时间是主要限制时。 决策树可以清楚地表明所选数据集中的哪些特征最具预测能力。 此外,与许多用于对数据进行分类的规则可能难以解释的机器学习算法不同,决策树可以呈现可解释的规则。 决策树还能够利用分类变量和连续变量,这意味着与只能处理这些变量类型之一的算法相比,需要更少的预处理。
当用于确定连续属性的值时,决策树往往表现不佳。 决策树的另一个限制是,在进行分类时,如果训练样本很少但类别很多,则决策树往往不准确。