基本语法
库操作
Hive和MySQL类似,提供了针对database的操作。
1)创建库:
create database demo;
注意,每一个database在HDFS上都会对应一个目录,如果不指定,那么默认是放在/user/hive/warehouse/下。在Hive中,database的名字和存储位置一旦确定就不能修改。
2)创建库demo2,并且指定demo2在HDFS上的存储位置:
create database demo2 location '/demo2.db';
3)如果demo3库不存在,那么创建demo3:
create database if not exists demo3;
4)创建库的时候为其指定属性:
create database demo4 with dbproperties ('create_time' = '2023-07-20');
5)查询所有的库:
show databases;
6)利用正则表达式过滤符合规则的库:
show databases like 'demo*';
7)描述库的信息:
describe database demo;
-- 或者
desc database demo;
8)获取库的详细描述信息:
desc database extended demo;
9)切换/使用指定的库:
use demo;
10)修改指定库demo的属性信息:
alter database demo set dbproperties ('create_time' = '2023-07-20');
11)删除库demo4,注意,要求这个库为空:
drop database demo4;
12)判断库是否存在,如果存在,则删除:
drop database if exists demo3;
13)如果库非空,那么需要强制删除库:
drop database demo2 cascade;
表及数据操作
1)创建表:
create table person(id int, name string, age int);
需要注意的是,Hive中的每一个表在HDFS上同样对应了一个单独的目录。且在Hive中,没有主键的说法。
2)向表中添加数据:
insert into table person values (1, 'tom', 15);
Hive默认的执行引擎是MapReduce,所以所有的insert语句在底层都会转化为MapReduce任务来执行,因此效率相对较低。
3)查询数据:
select * from person;
4)将本地数据加载到Hive中:
load data local inpath '/opt/hivedata/person' into table person;
5)删除表:
drop table person;
6)在Hive中,建表的时候一般需要指定字段之间的间隔符号。当表建好之后,间隔符号就不能发生变化了:
create table person(id int, name string, age int) row format delimited fields terminated by ' ';
row format表示按行进行格式化处理,delimited表示对什么进行限制,fields表示属性,delimited fields就表示对属性进行限制,terminated by表示用什么符号作为间隔。
7)仿照person的表结构创建p2表:
create table p2 like person;
8)如果p3表不存在,那么仿照person的表结构创建p3表:
create table if not exists p3 like person;
9)创建p4表,并且复制person表的数据:
-- 复制表
create table p4 as select * from person;
-- 查询数据
select * from p4;
10)描述表的结构:
describe person;
-- 或者
desc person;
11)获取表的详细结构信息:
desc extended person;
-- 或者
desc formatted person;
12)从person表中查询age<18的数据,并且将查询出来的数据放到p2表中:
insert into table p2 select * from person where age < 18;
此处需要注意的是,如果使用的是insert into表示向表中追加数据。如果使用的是insert overwrite,则表示将表中原来的数据清空掉,覆盖写入新的数据。
13)从person表中查询数据,将id<5的数据查询出来覆盖到p2表中,将age≥18的数据查询出来追加到p3表中:
from person
insert overwrite table p2 select * where id < 5
insert into table p3 select * where age >= 18;
14) 从person表中查询数据,将查询出来age<18的数据放到本地目录下,字段之间用\t间隔:
insert overwrite local directory '/opt/hive_demo'
row format delimited fields terminated by '\t'
select * from person where age < 18;
注意,向文件中写入数据的时候只能使用insert overwrite,所以此时要求目标目录为空(即目标目录中没有子文件或者子目录,如果有子文件或者子目录,那么会被清理掉)。
15)从person表中查询数据,将查询出来age≥18的数据放到HDFS的指定目录下,字段之间用逗号间隔:
insert overwrite directory '/person_demo'
row format delimited fields terminated by ','
select * from person where age >= 18;
16)将HDFS上的指定文件加载到Hive中:
load data inpath '/person.txt' into table person;
17)将表person重命名为p1:
alter table person rename to p1;
18)修改列名:将p1表的id列名改为pid,数据类型不变:
alter table p1 change column id pid int;
19)修改列的类型:将p1表的pid列类型改为string:
alter table p1 change column pid pid string;
20)新增列:在p1表中新增一列gender:
alter table p1 add columns (gender string);
21)更换列的位置:将p1表中的name列调为第一列(注意:这种方式不更将数据更换了位置,只是列名更换了位置):
alter table p1 change column name name string first;
22)更换列的位置:将p1表中的name列放到gender列之后(注意:这种方式不更将数据更换了位置,只是列名更换了位置):
alter table p1 change column name name string after gender;
23)清空表中的数据:
truncate table p1;
24)覆盖加载:
load data local inpath '/opt/hivedata/person' overwrite into table p1;
表结构
内部表和外部表
在Hive中,所有的表都分为内部表(又叫管理表,Managed Table)和外部表(External Table)。一般而言,在Hive中手动建表手动添加数据(load或者insert)的表,大部分是内部表,而外部表是在Hive中建表来管理HDFS上已经存在的数据。
如果想要区分一个表是内部表还是外部表,可以通过命令:
desc extened tableName;
-- 或者
desc formatted tableName;
来描述这个表的详细信息,在详细信息中查看Table Type属性的值。如果是Table Type属性的值为Managed Table,就是内部表;如果是External Table,则表示外部表。
案例:建立外部表。
-- 将文件上传到HDFS的/orders目录下
-- 创建外部表
create external table orders (
name string, -- 用户名
order_date string, -- 订单日期
cost int -- 消费
) row format delimited fields terminated by ','
location '/orders';
-- 查询数据
select * from orders;
需要注意的是,外部表在删除的时候不会删除HDFS上对应的文件,但是内部表在删除的时候会删除对应的目录。
将外部表转化为内部表:
alter table orders set tblproperties ('EXTERNAL' = 'false');
将内部表转化为外部表:
alter table orders set tblproperties ('EXTERNAL' = 'true');
分区表
在Hive中,如果数据量特别大,需要对数据进行分类存储,那么要怎么处理呢?此时可以使用分区表。分区表最常见的作用就是对数据进行分类。
案例:创建分区表并加载数据。
-- 原始数据wei.txt
1 曹操
2 司马懿
3 张辽
4 荀彧
-- 原始数据shu.txt
1 刘备
2 诸葛亮
3 关羽
4 张飞
-- 原始数据wu.txt
1 孙权
2 周瑜
3 吕蒙
4 陆逊
-- 建立外部表
create table countries (
id int, -- 编号
name string -- 姓名
) partitioned by (country string) -- 以国家作为分类(分区)
row format delimited fields terminated by ' ';
-- 加载数据
load data local inpath '/opt/hivedata/wei.txt' into table countries partition (country = 'wei');
load data local inpath '/opt/hivedata/shu.txt' into table countries partition (country = 'shu');
load data local inpath '/opt/hivedata/wu.txt' into table countries partition (country = 'wu');
-- 查询数据
select * from countries;
查看HDFS会发现,每一个分区在HDFS上对应了一个单独的目录。在查询数据的时候,如果指定了分区作为查询条件,那么此时不需要读取整个表中所有的数据,而只需要读取对应分区目录下的数据即可,此时提高了查询效率;如果在查询数据的时候进行了跨分区查询,那么此时由于要读取多个文件,效率反而会有所降低。
如果在HDFS上手动创建了目录上传了文件,那么怎么让Hive知道这个新创建的目录是我们要增加的分区呢?
-- 原始数据hero.txt
1 董卓
2 吕布
3 袁术
4 袁绍
-- 在HDFS中创建目录
dfs -mkdir '/user/hive/warehouse/demo.db/countries/country=heroes';
-- 将文件传到这个目录下
dfs -put '/opt/hivedata/hero.txt' '/user/hive/warehouse/demo.db/countries/country=heroes';
-- 手动添加分区
alter table countries add partition (country = 'heroes')
location '/user/hive/warehouse/demo.db/countries/country=heroes';
-- 或者,可以选择修复分区
msck repair table countries;
注意,如果添加多个分区,那么分区之间用空格间隔:
alter table tableName add partition(partitionName = 'name1') partition(partitionName = 'name2') partition(partitionName = 'name3')...;
修改分区的名字:
alter table countries partition (country = 'heroes') rename to partition (country = 'other');
删除分区:
alter table countries drop partition (country = 'other');
注意,如果删除多个分区,那么分区之间用逗号隔开:
alter table tableName drop partition(partitionName = 'name1'), partition(partitionName = 'name2'), partition(partitionName = 'name3'), ...;
需要注意的是,在Hive中,分区表的分区字段要求在原始数据中不存在,可以认为分区字段就是要给伪劣。如果要是原始数据中存在了分区字段,那么此时就需要进行动态分区了。
动态分区案例:
-- 原始数据heroes.txt 1 wei 荀攸
2 wei 张辽
3 shu 孙乾
4 shu 马超
5 wu 张昭
6 wu 甘宁
7 wei 贾诩
8 wu 太史慈
9 shu 法正
10 shu 赵云
11 wei 程昱
12 wei 郭嘉
13 wu 黄盖
14 wu 鲁肃
15 shu 黄忠
-- 在Hive中创建临时表
create table countries_tmp ( cid int, c_country string, c_name string) row format delimited fields terminated by ' ';
-- 加载数据到临时表
load data local inpath '/opt/hivedata/heroes.txt' into table countries_tmp;
-- 查询数据
select * from countries_tmp tablesample (5 rows);
-- 开启动态分区 - 非严格模式
set hive.exec.dynamic.partition.mode=nonstrict;
-- 当有空分区生成时,是否报错
set hive.error.on.empty.partition=false;
-- 动态分区 - 从未分区表中查询数据放到已分区表中
insert into table countries partition (country)
select cid, c_name, c_country from countries_tmp distribute by c_country;
Hive也支持多字段分区。如果进行了多字段分区,那么此时前一个分区字段形成的目录会包含后一个分区字段形成的目录。多字段分区通常用于多级分类,例如省市县,学生的年级和班级,商品的一级二级三级分类等。
-- 原始数据students
1 1 1 tom
1 1 2 sam
1 1 3 bob
1 1 4 alex
1 2 1 bruce
1 2 2 cindy
1 2 3 jack
1 2 4 john
2 1 1 tex
2 1 2 helen
2 1 3 charles
2 1 4 frank
2 2 1 david
2 2 2 simon
2 2 3 lucy
2 2 4 lily
-- 建立临时表
create table students_tmp (
t_grade int, -- 年纪
t_class int, -- 班级
t_id int, -- 编号
t_name string -- 姓名
) row format delimited fields terminated by ' ';
-- 加载数据
load data local inpath '/opt/hivedata/students' into table students_tmp;
-- 查询数据
select *
from students_tmp tablesample (5 rows);
-- 开启动态分区
set hive.exec.dynamic.partition.mode=nonstric;
-- 当有空分区生成时,是否报错
set hive.error.on.empty.partition=false;
-- 创建分区表
create table students ( id int, name string) partitioned by (grade int, class int) row format delimited fields terminated by ' ';
-- 动态分区
insert into table students partition (grade, class)
select t_id, t_name, t_grade, t_class
from students_tmp distribute by t_grade, t_class;
-- 查询数据
select * from students;
分桶表
当数据量比较大,又需要对数据进行快速分析的时候,可以考虑从原始数据中抽取一部分数据来进行分析。需要注意的是,抽取的字段和要分析的字段之间不能有关联性,例如年龄和身高是有关联性的,但是姓名和身高就没有关联性。
分桶表的分桶规则是:先计算分桶字段的哈希值,然后对桶的个数进行取余,根据余数决定讲数据放入哪一个桶中。
需要注意的是,在老版本的Hive中,使用load方式加载数据不会对数据进行分桶,只能使用insert方式来回对数据进行分桶;最新版本的Hive(Hive3.1.3版本)中支持load方式分桶,但是会存在问题,所以依然建议使用insert方式来将数据放入分桶表中。
案例:
-- 开启分桶机制
set hive.enforce.bucketing = true;
-- 设置ReduceTask的个数,-1表示根据情况由Hive自己决定
set mapreduce.job.reduces = -1;
-- 建立分桶表,根据name字段的值,将数据分到4个桶中
create table students_bucket ( id int, name string ) clustered by (name) into 4 buckets row format delimited fields terminated by ' ';
-- 向分区表加载数据
insert overwrite table students_bucket select id, name from students;
数据类型
概述
Hive针对数据提供了非常丰富的数据类型,这些数据类型大致可以分为两类:基本类型和复杂类型。
Hive提供的基本类型主要包括:
表-1 基本数据类型
| Hive类型 | Java类型 |
| tinyint | byte |
| smallint | short |
| int | int |
| bigint | long |
| float | float |
| double | double |
| boolean | boolean |
| string | String |
| binary | byte[] |
| timestamp | Timestamp |
Hive提供的复杂类型主要是三个:array,map和struct类型。
复杂数据类型
array(数组)类型,对应了Java中的数组以及集合结构。
-- 原始数据
1 bob,alex lucy,lily,jack
2 tom,sam,smith rose,john
3 peter,bruce david,kathy
4 helen,eden,iran cindy,grace,mike
-- 建表
create table battles (
id int, -- 编号
group_a array<string>, -- A组
group_b array<string> -- B组
) row format delimited
fields terminated by ' ' -- 字段之间用空格间隔
collection items terminated by ','; -- 数组/集合元素之间用逗号间隔
-- 加载数据
load data local inpath '/opt/hivedata/battles' into table battles;
-- 查询数据
select * from battles tablesample (5 rows);
-- 查询A组的第一个成员
select group_a[0] from battles;
-- 非空查询
select group_a[2] from battles where group_a[2] is not null;
map(映射)类型,对应了Java中的Map类型。
-- 原始数据
1 alex,bruce
2 carl,duck
3 eden,fred
4 gill,hack
5 iran,jack
-- 建表
create table groups (
id int, -- 小组编号
members map<string, string> -- 小组成员
) row format delimited
fields terminated by ' ' -- 字段之间用空格间隔
map keys terminated by ','; -- 映射键值之间用逗号间隔
-- 加载数据
load data local inpath '/opt/hivedata/groups' into table groups;
-- 查询数据
select * from groups;
-- 非空查询
select members['carl'] from groups where members['carl'] is not null;
struct(结构体)类型,对应了Java中的对象,可以看作是将数据封装成了json串形式。
-- 原始数据
1 tom,19,male sam,20,male
2 lily,18,female lucy,19,female
3 charles,19,male mark,21,male
4 joan,18,female james,20,male
5 linda,20,female matin,21,male
-- 建表
create table infos
(
id int, -- 小组编号
member_a struct<name:string, age:int, gender:string>, -- 成员A
member_b struct<name:string, age:int, gender:string> -- 成员B
) row format delimited fields terminated by ' ' -- 字段之间用空格间隔
collection items terminated by ','; -- 属性之间用逗号间隔
-- 加载数据
load data local inpath '/opt/hivedata/infos' into table infos;
-- 查询数据
select * from infos tablesample (5 rows);
-- 查看成员A的名字
select member_a.name from infos;
运算符和函数
概述
Hive针对大量的数据,提供了非常丰富的运算符和函数用于进行数据的处理和分析。同时,为了提供更灵活的操作,Hive还允许用户自定义函数。
但是需要注意的是,在Hive中,所有的运算符和函数都不能直接使用,而是必须结合其他关键字构成语句,例如结合select构成查询语句等。
如果想要查看Hive中提供的所有运算符和函数,可以通过命令:
show functions;
如果想要查看某一个函数的介绍,可以通过命令:
desc function functionName;
-- 例如
desc function sum;
如果想要查看某一个函数的详细用户,可以通过命令:
desc function extended functionName;
-- 例如:
desc function extended trim;
入门案例
案例一:给定某一个日期,例如'2023-07-20',从中截取年份。
-- 方式一:通过-来切分日期,然后获取切分之后的第一个字段
select cast(split('2023-07-20', '-')[0] as int);
-- 方式二:通过year函数提取,但是这种方式要求年月日之间必须用-间隔
select year('2023-07-20');
案例二:给定某一个日期,例如'2023/07/20',从中截取年份。
-- 方式一:切分之后提取
select cast(split('2023/07/20', '/')[0] as int);
-- 方式二:先将日期中的/替换为-,再用year函数提取
select year(regexp_replace('2023/07/20', '/', '-'));
案例三:给定邮箱,例如'tom@test.com',从中提取邮箱后缀。
-- 方式一:切分之后提取
select split('tom@test.com', '@')[1];
-- 方式二:利用正则表达式提取
select regexp_extract('tom@test.com', '(.+)@(.+)', 2);
常用函数
nvl函数
nvl(v1, v2)函数,在使用的时候需要传入两个参数v1和v2。如果v1的值不为null,则返回v1;反之,如果v1的值为null,则返回v2;如果v1和v2的值都是null,则返回null。
案例:计算员工的平均奖金。
-- 原始数据
1 Bill 1000
2 Vincent 800
3 William 500
4 Henry
5 Betty 500
6 Fred 300
7 Karl
8 Lee 400
9 Thomas 600
10 Shirley 900
-- 建表
create table rewards (
id int, -- 员工编号
name string, -- 员工姓名
reward double -- 获得的奖金
) row format delimited fields terminated by ' ';
-- 加载数据
load data local inpath '/opt/hivedata/rewards' into table rewards;
-- 查询数据
select *
from rewards tablesample (5 rows);
-- 计算员工的平均奖金
-- 对于avg这一类聚合函数而言,当数据的值为null的时候,会自动跳过
select avg(reward) from rewards;
-- 如果员工没有发放奖金,那么奖金应该记为0
select avg(nvl(reward, 0)) from rewards;
case when函数
case when函数,类似于Java中的switch-case结构,用于对数据进行判断。
案例:统计每一个部门中男生和女生的人数。
-- 原始数据
1 财务 bill 男
2 技术 charles 男
3 技术 lucy 女
4 技术 lily 女
5 财务 helen 女
6 财务 jack 男
7 财务 john 男
8 技术 alex 男
9 技术 cindy 女
10 技术 david 男
-- 建表
create table employers (
id int, -- 员工编号
department string, -- 员工部门
name string, -- 员工姓名
gender string -- 性别
) row format delimited fields terminated by ' ';
-- 加载数据
load data local inpath '/opt/hivedata/employers' into table employers;
-- 查询每一个部门中男生和女生的人数分别是多少
-- if结构
select department as `部门`,
sum(if(gender = '男', 1, 0)) as `男生人数`,
sum(if(gender = '女', 1, 0)) as `女生人数`
from employers group by department;
-- case-when结构
select department as `部门`,
sum(case gender when '男' then 1 else 0 end) as `男生人数`,
sum(case gender when '女' then 1 else 0 end) as `女生人数`
from employers group by department;
explode函数
explode函数,在使用的时候需要传入一个数组或者映射类型的参数。如果传入的是数组,那么会将这个数组中的每一个元素提取出来形成单独的一行数据;如果传入的是一个映射,那么会将这个映射中的键值对提取出来形成两列元素。
案例:统计文件中每一个单词出现的次数。
-- 原始数据
hello tom hello bob david joy hello
hello rose joy hello rose
jerry hello tom hello joy
hello rose joy tom hello David
-- 建表
create table words (
line array<string>
) row format delimited collection items terminated by ' ';
-- 加载数据
load data local inpath '/opt/hivedata/words' into table words;
-- 查询数据
select * from words;
-- 统计文件中每一个单词出现的次数
select w as `word`, count(w) as `count` from (
select explode(line) as w from words
) ws group by w;
列转行
所谓列转行,顾名思义,指的是将一列的数据拆分成多行。在列转行的过程中,要使用的非常重要的函数就是explode。
案例:查询所有的恐怖片。
-- 原始数据
封神第一部:朝歌风云 动作/战争/奇幻/古装
芭比 喜剧/奇幻/冒险
长安三万里 动画/历史
超能一家人 喜剧/家庭/奇幻
茶啊二中 喜剧/动画/奇幻
祭屋出租 悬疑/惊悚/恐怖
东北警察故事2 剧情/动作/犯罪
触底反弹 剧情/运动
-- 建表
create table movies (
name string, -- 电影名
types array<string> -- 电影类型
) row format delimited fields terminated by ' '
collection items terminated by '/';
-- 加载数据
load data local inpath '/opt/hivedata/movies' into table movies;
-- 查询数据
select * from movies tablesample (5 rows);
-- 查询所有的动画片
-- 语法:lateral view functionName(expression) tableAlias as colAlias
-- 这个过程称之为'炸列'
select name, t from movies lateral view explode(types) ts as t where t = '动画';
同样,列转行,也支持对多列进行拆分:
-- 原始数据
Kevin 活泼/开朗 打篮球/看电影
Lisa 大方/活泼 看电影/听音乐
Carl 活泼/幽默 打篮球/打游戏
Joy 大方/文静 听音乐/看书
--建表
drop table students;
create table students (
name string, -- 姓名
characters array<string>, -- 性格
hobbies array<string> -- 爱好
) row format delimited fields terminated by ' '
collection items terminated by '/';
-- 加载数据
load data local inpath '/opt/hivedata/students' into table students;
-- 查询性格活泼,喜欢打篮球的学生
select name from students
lateral view explode(characters) cs as c lateral view explode(hobbies) hs as h
where c = '活泼' and h = '打篮球';
列转行
所谓列转行,顾名思义,是将多行的数据合并到一列上。这个过程中,一般需要使用函数collect_set或者collect_list,如果是转化为stuct结构,那么需要使用named_struct函数。
collect_set和collect_list都是将多个元素汇聚成一个数组,二者的区别是:collect_set不允许元素重复,collect_list允许元素重复。
案例:将同一个年级同一个班级的学生汇聚到一行。
-- 原始数据
1 1 burt
1 2 james
1 4 fred
1 2 bruce
1 1 carol
1 3 taylor
1 4 evan
1 3 grace
1 1 richard
1 3 adam
1 4 ben
1 1 ross
1 2 charles
1 4 cody
1 3 wendy
1 2 david
-- 建表
drop table students;
create table students (
grade int, -- 年纪
class int, -- 班级
name string -- 姓名
) row format delimited fields terminated by ' ';
-- 加载数据
load data local inpath '/opt/hivedata/students' into table students;
-- 查询数据
select * from students tablesample (5 rows);
-- 将同一个年级同一个班级的学生汇聚到一行
select grade, class, concat_ws(',', collect_list(name)) from students group by grade, class;
函数分类
在Hive中,函数可以分为UDF、UDAF、UDTF以及窗口函数。
UDF(User Defined Function):用户定义函数。特点是一进一出,即用户输入一行数据会获取到一行结果。例如year、length、regexp_replace、concat、split等。
UDAF(User Defined Aggration Function):用户定义聚合函数。特点是多进一出,即用户输入多行数据会获取到一行结果。例如min、max、sum、avg、collect_set、collect_list等。
UDTF(User Defined Table-generated Function):用户定义表生成函数。特点是一进多出,即用户输入一行数据会获取到多行结果。例如explode、posexplode、inline、stack、json_tuple、parse_url_tuple等。
Hive中提供的大部分函数都是UDF函数。
自定义函数
POM依赖
创建Maven工程,导入POM依赖:
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>3.1.3</version>
<exclusions>
<exclusion>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-metastore</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-common</artifactId>
<version>3.1.3</version>
</dependency>
</dependencies>
自定义UDF函数
如果需要自定义UDF函数,那么需要定义类继承父类。需要注意的是,Hive1.x和Hive2.x中需要继承的是UDF类,Hive3.x中需要继承的是GenericUDF。
package com.auth;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
public class AuthUDF extends GenericUDF {
// 初始化方法,这个方法的返回值决定了evaluate方法的返回值类型
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
if (arguments.length != 2)
throw new UDFArgumentException("参数个数必须是2个!");
return PrimitiveObjectInspectorFactory.javaIntObjectInspector;
}
// 函数实际的处理逻辑覆盖在这个方法中
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
// 获取原字符串
String str = arguments[0].get().toString();
// 获取子串
String sub = arguments[1].get().toString();
// 返回子串第一次出现的位置
return str.indexOf(sub);
}
@Override
public String getDisplayString(String[] children) {
return "";
}
}
自定义UDTF函数
在Hive3.x中,如果需要自定义UDTF函数,那么需要定义类继承GenericUDTF,覆盖其中的方法。
package com.auth;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.util.ArrayList;
import java.util.List;
// 根据指定符号,将字符串切分为多行数据
public class AuthUDTF extends GenericUDTF {
// 定义列表用于存储数据
private final List<String> values = new ArrayList<>();
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) {
// 定义列表,用于存储输出列名
List<String> fieldName = new ArrayList<>();
fieldName.add("strToLine");
// 定义数据输出的类型
List<ObjectInspector> fieldType = new ArrayList<>();
fieldType.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
// 返回
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldName, fieldType);
}
@Override
public void process(Object[] args) throws HiveException {
// 获取字符串
String str = args[0].toString();
// 判断是否指定了切分符号,如果没有指定,那么默认以-作为切分符号
String symbol = "-";
if (args.length > 1) symbol = args[1].toString();
// 拆分字段
String[] arr = str.split(symbol);
// 遍历,写出
for (String s : arr) {
// 集合复用
values.clear();
// 添加元素
values.add(s);
// 推出元素
forward(values);
}
}
@Override
public void close() {
}
}
无论是自定义UDF还是自定义UDTF函数,都需要将定义好的程序打成jar包。
创建函数
创建临时函数:
1)将jar包上传到Linux的目录下,例如/opt/hivedata目录。
2)在Hive中指定命令,添加jar包:
add jar /opt/hivedata/G_Hive-1.0-SNAPSHOT
3)创建临时函数:
create temporary function indexof as 'com.auth.AuthUDF';
create temporary function stringToLine as 'com.auth.AuthUDTF';
注意:临时函数只和会话有关。如果当前会话关闭,那么临时函数就会失效,下次连接之后如果想要使用只能重新add和create。
创建永久函数:
1)将jar包上传到HDFS上。
2)创建函数:
-- UDF函数
create function indexOf
as 'com.auth.AuthUDF'
using jar 'hdfs://hadoop01:9000/hive_function/G_Hive-1.0-SNAPSHOT.jar';
-- UDTF函数
create function strToLine
as 'com.auth.AuthUDTF'
using jar 'hdfs://hadoop01:9000/hive_function/G_Hive-1.0-SNAPSHOT.jar';
如果需要删除永久函数,那么命令为:
drop function functionName;
窗口函数
概述
窗口函数(over函数),又叫开窗函数,不同于之前函数的地方在于,它是针对每一行数据进行一次计算返回一个结果。实际过程中,需要灵活运用窗口函数来限定数据的处理范围。
窗口函数的基本语法结构为:
分析函数() over(partition by 字段 order by 字段 [asc/desc] rows between 起始行 and 结束行)
其中,rows between表示限定数据处理范围,需要用的关键字包含:preceding-向前,following-向后,unbounded-无边界,current row-当前行。例如:
1)2 preceding and current row表示当前行以及前两行。例如当前行为第5行,那么就表示处理3-5行的数据。
2)current row and 2 following表示当前行以及后两行。例如当前行为第5行,那么就表示处理5-7行的数据。
3)unbounded preceding and current row表示从开始处理到当前行。
4)current row and unbounded following表示从当前行开始处理到最后一行。
partition by表示对数据进行分区,order by表示对数据进行排序,asc表示升序,desc表示降序。需要注意的是,如果没有指定partition by,那么就是对数据进行整体排序;如果指定了partition by,那么则表示在每一个分区中对数据进行排序。
分析函数指的是对每一行数据进行处理的函数,可以总结为三大类函数:聚合函数、移位函数和排序函数:
1)聚合函数,对数据进行聚合处理,例如min、max、sum、avg等。
2)移位函数,包含lag、lead和ntile三个。
3)排序函数,包含row_number,rank和dense_rank三个。
聚合及移位案例
有原始数据如下:
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,94
建表:
create table orders (
name string, -- 顾客姓名
order_date string, -- 消费日期
cost double -- 消费金额
) row format delimited fields terminated by ',';
加载数据:
load data local inpath '/opt/hivedata/orders' into table orders;
需求一:查询每一个顾客的消费明细以及到当前日期为止的总计消费。
select *,
sum(cost) over (partition by name order by order_date rows between unbounded preceding and current row ) as total
from orders;
需求二:查询顾客上一次购买的时间。
-- lag(col, n):表示以当前行为基础,处理第前n行。例如当前行为第5行,那么lag(col, 2)就表示处理第三行数据
-- 上一次的购买时间,那么就是上一行数据
select name, order_date,
lag(order_date, 1) over (partition by name order by order_date) as last_date
from orders;
需求三:获取最早进店消费的前20%的顾客名单。
-- ntile(n):将数据排序之后,平均分发到指定的n个桶中
-- ntile会给每一个桶进行编号,编号从1开始,之后会将这个编号分发给这个桶中的每一个数据上
-- 如果数据不能平均分配,则会优先将较小的数据分配到较小的桶中,各个桶之间的行数只差不能超过1个
-- 获取前20%的数据,就是前1/5的数据,那么只需要将数据排序之后分到5个桶中,然后获取编号为1的桶即可
select name from (
select name, ntile(5) over (order by order_date ) as n from orders
) tmp where n = 1;
排序函数案例
有原始数据如下:
Charles Chinese 87
Charles Math 95
Charles English 68
Lily Chinese 94
Lily Math 56
Lily English 84
William Chinese 64
William Math 86
William English 84
Vincent Chinese 65
Vincent Math 85
Vincent English 78
建表语句如下:
create table scores (
name string, -- 姓名
subject string, -- 科目
score int -- 成绩
) row format delimited fields terminated by '\t';
加载数据:
load data local inpath '/opt/hivedata/scores' into table scores;
需求一:按照各科成绩对学生进行降序排序。
-- row_number:顺次编号,不产生空位。即使值一样,编号也是顺次的
-- rank:顺次编号,产生空位。即值一样,编号相同,但是会跳过后边几个编号
-- dense_rank:顺次编号,不产生空位。即值一样,编号相同,但是不会跳过编号
select *,
row_number() over (partition by subject order by score desc) as `row_number`,
rank() over (partition by subject order by score desc) as `rank`,
dense_rank() over (partition by subject order by score desc) as `dense_rank`
from scores;
需求二:获取各科考试成绩的前三名同学的姓名、科目和成绩。
select name, subject, score, n from (
select *, rank() over (partition by subject order by score desc) as n from scores
) tmp where n <= 3;
其他操作
join
同MySQL类似,Hive也提供了表之间的连接操作,包含内连接inner join,左外连接left join,右外连接right join,全外连接full outer join。同时,Hive中还提供了left semi join。

图-19 join方式
案例:
-- 原始数据 - orders.txt
1001 20170710 4 2
1002 20170710 3 100
1003 20170710 2 40
1004 20170711 2 23
1005 20170711 4 55
1006 20170823 3 20
1007 20170823 2 3
1008 20170823 4 23
1009 20170912 2 10
1010 20170912 2 2
1011 20170914 3 14
1012 20170914 3 18
-- 原始数据 - products.txt
1 chuizi 3999
2 huawei 3999
3 xiaomi 2999
4 apple 5999
-- 建立orders表
drop table if exists orders;
create table orders (
order_id string, -- 订单号
order_date string, -- 订单日期
product_id string, -- 商品号
num int -- 售出数量
) row format delimited fields terminated by ' ';
-- 建立products表
drop table if exists products;
create table products (
product_id string, -- 商品编号
product_name string, -- 商品名
price double -- 单价
) row format delimited fields terminated by ' ';
-- 加载数据
load data local inpath '/opt/hivedata/orders' into table orders;
load data local inpath '/opt/hivedata/products' into table products;
-- 查询数据,确保数据正常加载
select * from orders tablesample (5 rows);
select * from products tablesample (5 rows);
-- 需求一:获取每天卖了多少钱
select o.order_date as order_date,
sum(o.num * p.price) as total
from orders o join products p on o.product_id = p.product_id
group by o.order_date;
-- 需求二:获取哪些商品被卖出去过
-- a left semi join b:表示a表中哪些数据在b表中出现过
-- 获取哪些商品被卖出去过,那么就是获取商品表中哪些数据在订单表中出现过
select p.product_id, p.product_name, p.price
from products p left semi join orders o on p.product_id = o.product_id;
having
having关键字,需要结合group by来使用,对分组之后的聚合结果进行过滤。having和where不同的地方在于:where是直接对已有字段进行查询过滤;having是对聚合函数的结果进行过滤。
案例:获取平均工资超过5000的员工。
-- 原始数据
1 Apollo 4900
1 Billy 5100
1 Cary 4700
1 Dylan 5000
1 Ford 4800
2 Apollo 5200
2 Billy 4700
2 Cary 4900
2 Dylan 5100
2 Ford 5000
3 Apollo 4900
3 Billy 5200
3 Cary 4700
3 Dylan 4600
3 Ford 5300
-- 建表
drop table if exists salaries;
create table salaris (
month int, -- 月份
name string, -- 员工姓名
salary double -- 员工薪资
) row format delimited fields terminated by ' ';
-- 加载数据
load data local inpath '/opt/hivedata/salaries' into table salaris;
-- 查询数据
select * from salaris tablesample (5 rows);
-- 需求:查询平均工资超过5000的员工
select name, avg(salary) as avg_sal from salaris group by name having avg_sal > 5000;
排序
在Hive中,针对数据提供了两种排序方式:
1)order by:全局排序。在排序的时候会忽略掉ReduceTask的数量,对所有的数据进行整体的排序,默认是升序排序。
2)sort by:局部排序。这种方式,会在每一个ReduceTask内部对数据进行排序。假设设置了3个ReduceTaks,那么默认情况下,会先根据数据的哈希码,将数据分发到3个ReduceTask中,然后每一个ReduceTask中对数据进行排序,默认是升序排序。
如果只有1个ReduceTask,那么order by和sort by效果相同。
案例演示:
-- 原始数据
3 Max 89
1 Eric 89
3 Paul 82
1 Hank 95
2 Larry 74
1 Henry 84
2 Justin 82
3 Tim 85
2 ken 84
1 Ivan 85
3 Nick 84
2 Leo 82
2 Mars 86
1 Jim 74
3 Reed 81
-- 建表
drop table if exists students;
create table students (
class int, -- 班级
name string, -- 姓名
score int -- 成绩
) row format delimited fields terminated by ' ';
-- 加载数据
load data local inpath '/opt/hivedata/students' into table students;
-- 查询数据
select * from students tablesample (5 rows);
-- 设置ReduceTask的数量为3
set mapred.reduce.tasks = 1;
-- 或者
set mapreduce.job.reduces = 3;
-- order by排序
insert overwrite local directory '/opt/hive_demo/order_by' row format delimited fields terminated by ' '
select * from students order by score desc;
-- sort by排序
insert overwrite local directory '/opt/hive_demo/sort_by' row format delimited fields terminated by ' '
select * from students sort by score desc;
实际过程中,sort by一般会结合distribute by来使用。distribute by是将数据进行分区(分类),而sort by是针对每一个分区中的数据进行排序。
-- 需求:按照班级,在每一个班级内按照学生的成绩降序排序
insert overwrite local directory '/opt/hive_demo/distribute_by' row format delimited fields terminated by ' '
select * from students distribute by class sort by score desc;
当distribyte by和sort by字段相同时,可以使用cluster by。不过需要注意的是cluster by只能升序排序,不能降序排序。
insert overwrite local directory '/opt/hive_demo/cluster_by' row format delimited fields terminated by ' '
select * from students cluster by score;
beeline
beeline是Hive提供的用于进行远程连接的一种方式,本质上底层是使用JDBC的方式来连接Hive。使用beeline的时候需要开启Hive的远程连接服务hiveserver2。
启动beeline的命令如下:
beeline -u jdbc:hive2://hadoop01:10000/demo -n root
其中,参数-u表示url连接地址,-n表示name连接用户名。
JDBC
Hive支持JDBC操作,语法与MySQL类似:
import java.sql.*;
public class HiveJDBCDemo {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
// 注册驱动
Class.forName("org.apache.hive.jdbc.HiveDriver");
// 获取连接
Connection con = DriverManager.getConnection("jdbc:hive2://hadoop01:10000/demo", "root", "root");
// 获取表述
Statement stat = con.createStatement();
// 执行查询,获取结果集
ResultSet set = stat.executeQuery("select * from products");
// 遍历结果集
while (set.next()) {
System.out.println(set.getString("product_name"));
}
// 关闭连接
set.close();
stat.close();
con.close();
}
}
SerDe
SerDe(Serializar/Deserializar)是Hive提供的一套用于对数据进行序列化和反序列化的机制。在使用SerDe的时候,需要指定正则表达式,然后利用正则表达式去解析数据。而正则表达式中的每一个捕获组对应Hive表中的一个字段。
案例:
-- 原始数据tomcat.log
192.168.120.23 -- [30/Apr/2018:20:25:32 +0800] "GET /asf.avi HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:32 +0800] "GET /bupper.png HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:32 +0800] "GET /bupper.css HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:33 +0800] "GET /bg-button HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:33 +0800] "GET /bbutton.css HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:33 +0800] "GET /asf.jpg HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:33 +0800] "GET /tomcat.css HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:33 +0800] "GET /tomcat.png HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:33 +0800] "GET /tbutton.png HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:33 +0800] "GET /tinput.png HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:33 +0800] "GET /tbg.css HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:34 +0800] "GET /tomcat.css HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:34 +0800] "GET /bg.css HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:34 +0800] "GET /bg-button.css HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:34 +0800] "GET /bg-input.css HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:34 +0800] "GET /bd-input.png HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:34 +0800] "GET /bg-input.png HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:34 +0800] "GET /music.mp3 HTTP/1.1" 304 -
-- 方式一:不使用SerDe
-- 建立临时表
create table logs_tmp ( log string);
-- 加载数据
load data local inpath '/opt/hivedata/tomcat.log' into table logs_tmp;
-- 查询数据
select * from logs_tmp tablesample (5 rows);
-- 建立日志表
create table logs (
host string, -- 主机名/ip
log_date string, -- 访问日期
timezone string, -- 时区
request_way string, -- 请求方式
resources string, -- 请求资源
protocol string, -- 请求协议
state_id int -- 状态码
) row format delimited fields terminated by '\t';
-- 解析数据,放入日志表中
insert into table logs
select arr[0], arr[1], arr[2], arr[3], arr[4], arr[5], cast(arr[6] as int) from (
select split(regexp_replace(log, '(.*) \-\- \\[(.*) (.*)\\] \"(.*) (.*) (.*)\" ([0-9]+) \-','$1 $2 $3 $4 $5 $6 $7'), ' ') as arr from logs_tmp
) tmp;
-- 查询数据
select * from logs tablesample (5 rows);
-- 方式二:使用SerDe
-- 建立日志表
create table logs2 (
host string, -- 主机名/ip
log_date string, -- 访问日期
timezone string, -- 时区
request_way string, -- 请求方式
resources string, -- 请求资源
protocol string, -- 请求协议
state_id int -- 状态码
) row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe'
with serdeproperties ('input.regex' = '(.*) \-\- \\[(.*) (.*)\\] \"(.*) (.*) (.*)\" ([0-9]+) \-')
stored as textfile;
-- 加载数据
load data local inpath '/opt/hivedata/tomcat.log' into table logs2;
-- 查询数据
select * from logs2 tablesample (5 rows);
视图
视图是对原表中部分字段进行抽取,可以看作是原表的一个子表,但是本质上是一个虚拟表。通过视图,可以展现基表中的部分数据。视图可以分为虚拟视图和物化视图,而Hive只支持虚拟视图。
在定义视图的时候,需要封装一个select语句,用于从基表中抽取数据,而封装的这个select语句在创建视图的时候并不执行,而是在第一次使用视图的时候才会真正执行。
视图的优点:
1)简单。使用视图的时候,完全不需要关心视图背后的基表结构、关联条件和筛选条件,对用户而言,视图就是过滤好的符合条件的结果集。
2)安全。使用试图的用户只能访问他们被允许查询的结果集,且视图只能查询不能修改,不影响之后基表数据。
3)数据独立。一旦视图的结构确定,那么就可以屏蔽表结构变化对用户的影响。例如基表中增添列,不会影响视图的操作。
创建视图:
create view logs_view as select host, log_date, resources from logs order by log_date;
查询视图:
select * from logs_view;
删除视图:
drop view logs_view;
Hive存储
文件存储格式
概述
在Hive中,主流的文件存储格式主要是6种:textfile,RCFile,avro,orc,parquet以及sequencefile形式。其中,textfile和sequencefile采用的是行存储形式,orc和parquet采用的是列存储形式。如果不指定,那么Hive默认采用textfile形式将数据落地到HDFS上。
textfile格式
Hive默认就是以textfile格式落地到HDFS上。默认情况下,textfile不对数据进行压缩,因此占用磁盘空间比较大,在进行数据分析的时候开销也相对较大。
textfile支持Gzip和Bzip2格式的压缩,但是Gzip格式不支持切片,因此使用Gzip格式就无法对数据进行并行操作。
orc格式
orc(Optimized Row Columnar,优化的行列)格式是Hive0.11版本中引入的一种文件格式,是以列存储的方式来存放数据。
每一个orc文件主要由1到多个Stripe,1个File Footer以及1个Postscript构成。每一个Stripe中包含了多条数据,这些数据按照列形式来独立存储。默认情况下,每一个Stripe大小为250M。

图-20 orc文件
Stripe主要由三部分组成:Index Data,Row Data和Stripe Footer。
1)Index Data:轻量级的索引结构,默认是每10000行数据形成一次索引,会记录每一列的最小值、最大值以及每一列中的行索引。如果指定,还可能包含位域或者是布隆过滤器。
2)Row Data:存储数据。在存储的时候,先取部分行,然后将每一行数据的字段拆分之后以列形式存储。在存储的时候,会对每一个列进行编码,封装成一个个的Stream结构来存储。因为同一个列中的字段类型是一致的,所以可以更好的采用压缩机制来进行压缩。
3)Stripe Footer:存储每一个Stream的类型、长度等信息,实际上就是记录每一列的数据类型、存储的数据的大小等信息。
每一个文件尾部都会有一个File Footer,用于记录每一个Stripe中的行数,每一个列的数据类型信息。File Footer中还包含列级别的聚合结果,包含count、min、max、sum。
每一个文件末尾都是一个Postscript,这里面记录了整个文件的信息,例如文件是否压缩,压缩算法等信息,还记录了File Footer在orc文件中的其实位置。因此,在读取orc文件的时候,需要先读取文件末尾的Postscript,获取到File Footer在文件中的存储位置,然后再读取File Footer,获取到Stripe所在的偏移量(文件中的存储位置),之后读取Stripe中的Index Data,锁定数据在Row Data中的位置,最后读取Row Data中的数。

图-21 orc解析
parquet格式
parquet格式是从Hive0.10开始提供的一种文件格式,本身是一种二进制形式的文件,所以不能直接读取。parquet文件中包含了数据以及描述数据的元数据,所以parquet文件是自解析文件。
每一个parquet文件会包含四部分:1个Magic Code(魔数编码),1个Footer Length,1个Metastore,以及包含1个到多个行组(Row Group)。
其中,Magic Code用于确保当前文件是一个parquet文件;Footer Length记录了元数据的大小,通过这个值以及文件的大小可以计算出元数据在文件中的偏移量;Metastore是元数据,记录了当前parquet文件的文件信息,例如文件大小,Row Group的数量等。
Row Group是将数据从行方向上进行的物理切分。默认情况下,每一个Row Group和HDFS的Block是等大的。
每一个Row Group中包含一个到多个列块(Column Chunk)。列块是将数据按照列形式进行存储,每一列对应一个列块,因此每一个列块中数据的类型是相同的,不同列块之间可以使用不同的压缩算法。列块之间是连续存储在这个行组中的。
每一个Column Chunk中会包含一个到多个页(Page),Page是parquet文件中数据存储的最小单元,同一个列块的不同页可以使用不同的编码方式。
Page分为三种:数据页,字典页和索引页。
1)数据页用于存储当前列块中的数据;
2)字典页用于存储编码信息;
3)索引页用于存储数据在文件中偏移位置。每一个列块中最多只有一个字典页。
需要注意的是,Hive原生生成的parquet文件中不支持索引页。

图-22 parquet文件格式
Hive压缩
Hive支持对输出的数据进行压缩,根据文件格式不同,支持的压缩算法不同。其中,比较常用的是orc格式的文件压缩和parquet格式的文件压缩。
如果想要对orc格式的文件进行压缩,可以通过orc.compress属性进行配置,可以配置的属性值包含NONE,ZLIB,SNAPPY。其中NONE表示不压缩。
创建一个表,文件格式为orc格式,压缩格式为zlib:
create table orc_zlib (id int, name string)
row format delimited fields terminated by ' '
stored as orc tblproperties ("orc.compress" = "ZLIB");
创建一个表,文件格式为orc格式,压缩格式为snappy:
create table orc_snappy(id int, name string)
row format delimited fields terminated by ' '
stored as orc tblproperties ("orc.compress" = "SNAPPY");
如果想要对parquet格式的文件进行压缩,可以通过属性parquet.compression进行配置,经常使用的是SNAPPY。
create table parquet_snappy ( id int, name string)
row format delimited fields terminated by ' '
stored as parquet tblproperties ("parquet.compression" = "SNAPPY");
Hive结构及优化
结构
Hive结构如下图:

图-23 Hive结构
1)Client Interface主要分为两种:CLI(command-line interface,命令行方式)和JDBC/ODBC(beeline采用的就是JDBC方式)。
2)Metastore:用于存储元数据,维系在关系型数据库中,默认是Derby,实际过程中一般是使用MySQL。
3)Driver:驱动器,包含了四部分。SQL Parser(SQL解析器)会查询元数据,确认SQL语法是否正确,然后将SQL转化为抽象语法树AST。Physical Plan(编译器)会将抽象语法树AST编译生成要执行的逻辑执行计划。Query Optimizer(优化器)对逻辑计划进行优化。Execution(执行器)负责将逻辑计划转化为要实际执行的物理计划,例如MapReduce程序。
优化
列裁剪或者分区裁剪
在生产环境中,经常要处理大量数据,而此时如果使用select * from tableName的形式,会对整个表进行扫描,数据量越大效率月底。所以在实际过程中查询数据的时候,最好指定列或者指定分区;如果是按行查询,最好限定行数,例如使用limit或者tablesample(x rows)形式。
group by优化
在Hive中进行group by的时候,会将相同的key对应的值分发给同一个ReduceTask处理。此时如果某一个key对应的数据格外多,那么就会造成整个ReduceTaks效率较低,从而产生了数据倾斜。针对这个问题,有两种优化方式:map端聚合以及二阶段聚合(负载均衡机制)。
map端聚合,顾名思义,就是先将数据在Map端经过一次聚合计算,再将聚合结果发送给Reduce端处理。
-- 开启聚合机制
set hive.map.aggr = true;
-- 指定聚合条数
set hive.groupby.mapaggr.checkinterval = 10000;
二阶段聚合(负载均衡模式),顾名思义,是将Hive的执行过程拆分成两个MapReduce任务来执行:第一个MapReduce Job负责将数据大三,此时相同的键可以不会分布到同一个ReduceTask上,然后每一个ReduceTask对结果进行聚合;之后第二个MapReduce Job再读取上一次的聚合结果,按照指定分组处理数据,此时相同的键才会分不到同一个ReduceTask上。
-- 开启二阶段聚合
set hive.groupby.skewindata = true;
CBO
从Hive0.1.0开始,加入了CBO(Cost based Optimizer,基于成本的优化器)来对SQL执行计划进行优化。从Hive1.1.0版本开始,CBO默认是开启的,可以通过属性hive.cbo.enable来调节。
CBO,成本优化器,遵循的原则是:代价最小的执行计划就是最好的执行计划。在任务最终执行之前,CBO会优化每一个查询的执行逻辑和物理执行计划,在底层会根据查询成本执行优化,自动优化SQL中多个join的执行顺序,并选择合适的join算法。
谓词下推
所谓谓词下推,指的是在保证结果正确的前提下,将SQL语句中的where过滤(过滤条件就是谓词)尽可能的提前执行,以此来减少下游处理的数据量。通过谓词下推,过滤条件将在Map端提前执行,减少了Map端的输出,降低了数据的IO,从而提升了性能。
-- 开启谓词下推
-- 此选项默认为true,ppd全称为PredicatePushDown,预测/谓词下推
set hive.optimize.ppd = true;
Map join
Map join,指的是在两个表或者多个表进行join的时候,将较小的表直接分发到各个MapTask所在节点的内存中,在MapTask中进行join,从而避免了Reduce端的join操作。如果不指定Map join或者不符合Map join的条件,那么Hive解析器会将Join操作转化为Common Join(普通join),然后在Reduce端完成join,那么此时容易产生数据倾斜。
-- 开启map side join。Hive3.X中,这个属性默认为true
set hive.auto.convert.join = true;
-- 设置小表阈值,默认为25M
set hive.mapjoin.smalltable.filesize = 25000000
SMB join
SMB(sort merge bucket) join,是基于分桶机制和Map join实现的一种join方式,旨在用于解决大表和大表之间的join问题。当A表和B表都比较大的时候,那么此时两个表进行join,那么需要计算的数据量就会较大,相对效率较低,此时可以采用SMB join。
SMB join本质上就是将数据分到多个桶中,那么此时每一个桶就相当于是一个小表,那么在join的时候就是小表和大表的join,可以采用map join方式,所以本质上就是一种"分而治之"的思想。
SMB join的使用必须符合两个条件:
1)A表和B表必须是分桶表,且B表的桶数必须是A表桶数的整数倍。例如A表分了6个桶,那么B表的桶数必须是6n(n≥1)。
2)分桶条件和join条件必须一致。即对于select * from a join b on a.id = b.pid而言,由于join条件是a.id和b.pid,所以此时要求A表必须根据id字段分桶,B表必须根据pid字段分桶,根据其他字段分桶无效。
SMB join相关参数:
-- 开启SMB join
简介
概述
Hive是由Facebook(脸书)开发的后来贡献给了Apache的一套数据仓库管理工具,针对海量的结构化数据提供了读、写和管理的功能。

图-1 Hive图标
Hive本身是基于Hadoop,提供了类SQL(Hive Query Language,简称为HQL)语言来操作HDFS上的数据,而底层实际上是将用户书写的SQL转化为了MapReduce程序来执行,因此效率相对较低,更适合于离线批处理的场景。
之所以Facebook开发了Hive这个项目,是因为Facebook在使用Hadoop过程中发现了一些问题:
1)Hadoop只提供了MapReduce这一种用于数据处理方案,但是当需要大量的数据进行处理的时候,就需要编写大量的MapReduce,这种方式效率较低,逻辑复杂度较高,难度较大。
2)早期的时候,Hadoop只支持Java语言(即使现在,Hadoop也只支持C/C++,Java,Python,Scala这几门语言),那么就导致其他开发者如果想要使用Hadoop,尤其是MapReduce,那么需要学习Java语言,极大地增加了学习和使用成本。
所以在这种背景下,Facebook就想对Hive尤其是MapReduce模块进行封装,且封装好之后使用的结构最好与语言无关(即不绑定某一门编程语言的语法),所以最后选定了SQL作为封装结构,由此,Hive也就诞生了。
Hive VS 数据库
Hive和数据库的比较如下:
1) 查询语言:由于SQL的易学特性,因此被广泛的应用在数据仓库中。Hive专门设计了类SQL的查询语言HQL,使得熟悉SQL开发的开发者可以很方便的使用Hive进行开发。
2)数据存储位置:Hive是建立在Hadoop之上的,因此Hive中的数据是存储在HDFS上的。而数据库则可以将数据保存在块设备或者本地文件系统中。
3)数据更新:Hive一般是针对历史数据进行处理,因此数据一般是不可修改的。而数据库中的数据通常是需要经常进行修改的。
4)索引:Hive在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描,因此不会主动针对数据建立索引。Hive要访问数据中满足条件的特定值时,需要暴力扫描整个数据,因此访问延迟较高。由于MapReduce的引入,Hive可以并行访问数据,因此即使没有索引,对于大数据量的访问,Hive仍然可以体现出优势。而在数据库中,通常会针对一个或者几个列建立索引,因此对于少量的特定条件的数据的访问,数据库可以有很高的效率,较低的延迟。
5)执行引擎:默认情况下,Hive通过Hadoop提供的MapReduce来实现数据处理的,当然,Hive支持将执行引擎替换为Tez或者是Spark。而数据库通常有自己的执行引擎,例如MySQL的执行引擎为innodb。
6)执行延迟:Hive在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外一个导致Hive执行延迟高的因素是MapReduce框架。由于MapReduce本身就具有较高的延迟,因此在利用MapReduce执行Hive查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive的并行计算显然能体现出优势。
7)可扩展性:由于Hive是建立在Hadoop之上的,因此Hive的可扩展性是和Hadoop的可扩展性是一致的(现在很多公司的Hadoop集群的规模超过了10000个节点)。而数据库由于ACID语义的严格限制,扩展行非常有限。目前最先进的并行数据库Oracle在理论上的扩展能力也只有100台左右。
8)数据规模:由于Hive建立在集群上并可以利用MapReduce进行并行计算,因此可以支持很大规模的数据,实际开发过程中一般是GB起步,可以达到PB级别及以上;相应的,数据库由于规模较小,因此可以支持的数据规模较小,一般单张表中能存储百万条数据(最新版的MySQL经过优化,单表中可以存储千万条或者上亿条数据,即使是一亿条数据,也就10GB大小,且此时效率会非常低)。
特点
优点
1)操作接口采用类SQL语法,用户只要熟悉SQL语法即可快速转化(简单、学习成本低、容易上手);
2)避免书写MapReduce,减少开发人员的学习成本以及维护成本;
3)对于大量数据,Hive能够进行分布式处理,从而节省了数据的处理时间;
4)Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数,从而提高了灵活性,能够更好的应对复杂业务。
缺点
1)基于HQL的方式导致表达能力有限:首先Hive中迭代式算法无法表达;其次Hive不擅长数据挖掘,由于MapReduce数据处理流程的限制,效率更高的算法却无法实现。
2)Hive的效率比较低:首先Hive的执行延迟比较高,因此Hive常用离线分析,适用于对实时性要求不高的场合;其次HQL自动编译生成MapReduce作业,通常情况下不够智能化;然后,由于MapReduce本身的特点,导致Hive对小文件的处理不占优势。
3)Hive调优比较困难,粒度较粗。
4)Hive对于数据更新操作支持性不好:一般用Hive处理的是离线的历史数据,因此默认情况下Hive是不支持对数据进行修改的。而如果需要对数据进行修改(update、delete),那么需要改变Hive中数据文件的存储格式,且此时效率非常非常低。
编译和安装
编译
源码编译
步骤如下:
1) 上传或者下载Hive的源码包:
# 进入预安装目录
cd /opt/software/
# 下载Hive的源码包,官方下载地址:
wget https://dlcdn.apache.org/hive/hive-3.1.3/apache-hive-3.1.3-src.tar.gz
2)解压:
tar -xvf apache-hive-3.1.3-src.tar.gz -C /opt/source/
3) 进入Hive的源码包:
cd /opt/source/apache-hive-3.1.3-src/
4) 执行编译过程:
mvn -X package -Pdist,nativeN,docs -DskipTests -Dtar -Dmaven.skip.test=true -Dmaven.javadoc.skip=true -Denforcer.skip=true
如果出现Could not find artifact org.pentaho:pentaho-aggdesigner-algorithm,则上传或者下载对应的jar包之后执行命令:
mvn install:install-file \
-Dfile=pentaho-aggdesigner-algorithm-5.1.5-jhyde.jar \
-DgroupId=org.pentaho \
-DartifactId=pentaho-aggdesigner-algorithm \
-Dversion=5.1.5-jhyde \
-Dpackaging=jar
然后重新编译即可。
guava版本修改
Hive3.1.3默认使用的是guava19.0,而Hadoop3版本默认使用的是guava27.0-jre版本,因此会产生版本冲突问题,需要替换guava版本。
1) 由于需要修改一部分Hive的源码,所以此处先安装Centos的桌面,然后利用idea来修改:
# 安装桌面
yum groupinstall "GNOME Desktop"
# 启用桌面版
init 5
2) 上传或者下载idea的安装包,然后解压:
tar -xvf ideaIC-2023.1.2.tar.gz -C /opt/software/
3)启动idea:
sh /opt/software/idea-IC-231.9011.34/bin/idea.sh
4)导入Hive源码包,然后配置maven。
5) 打开POM文件,修改guava的版本(第147行):
<guava.version>27.0-jre</guava.version>
6) 修改hive-service模块的pom文件:
<dependency>
<groupId>org.apache.directory.server</groupId>
<artifactId>apacheds-server-integ</artifactId>
<version>${apache-directory-server.version}</version>
<scope>test</scope>
<!--添加如下内容-->
<exclusions>
<exclusion>
<groupId>org.apache.directory.client.ldap</groupId>
<artifactId>ldap-client-api</artifactId>
</exclusion>
</exclusions>
</dependency>
7) 修改DruidScanQueryRecordReader.java类源码:

图-2 DruidScanQueryRecordReader类
8)修改MReporter类源码:

图-3 AMReporter类
9)修改LlapTaskReporter类源码:

图-4 LlapTaskReporter类
10)修改SampleTezSessionState类源码:

图-5 SampleTezSessionState类
11) 修改TaskExecutorService类源码:

图-6 TaskExecutorService类
12) 修改WorkloadManager类源码:

图-7 WorkloadManager类
13) 修改LlapTaskSchedulerService类源码:

图-8 LlapTaskSchedulerService类
14) 修改AsyncPbRpcProxy类源码:

图-9 AsyncPbRpcProxy类
15) 编译Hive:
mvn -X package -Pdist,nativeN,docs -DskipTests -Dtar -Dmaven.skip.test=true -Dmaven.javadoc.skip=true -Denforcer.skip=true
集成Spark
1)Hive3默认支持的Spark版本为2.4而不是Spark3,所以如果需要使用Spark3作为Hive的执行引擎,那么需要修改Hive的pom文件(201行):
<spark.version>3.1.2</spark.version>
<scala.binary.version>2.12</scala.binary.version>
<scala.version>2.12.11</scala.version>
2)修改TestStatsUtils类的源码:

图-10 TestStatsUtils类
3) 修改ShuffleWriteMetrics类的源码:

图-11 ShuffleWriteMetrics类
4) 修改SparkCounter类的源码:

图-12 SparkCounter类
5) 重新编译Hive:
mvn -X package -Pdist,nativeN,docs -DskipTests -Dtar -Dmaven.skip.test=true -Dmaven.javadoc.skip=true -Denforcer.skip=true
6) 编译好的安装包在/opt/software/apache-hive-3.1.3-src/packaging/target/下。
安装
MySQL安装
1)卸载CentOS7自带的MySQL:
rpm -qa | grep -i mysql | xargs rpm -ev –nodeps
rpm -qa | grep -i mariadb | xargs rpm -ev –nodeps
2)删除MySQL可能残留的文件:
find / -name mysql | xargs rm -rf
find / -name my.cnf | xargs rm -rf
cd /var/lib/
rm -rf mysql/
3)进入软件预安装目录,上传MySQL的安装包:
# 进入预安装目录
cd /opt/presoftware/
# 选择MySQL安装包,上传
rz
4)解压:
tar -xvf mysql-5.7.33-1.el7.x86_64.rpm-bundle.tar
5)安装MySQL,注意安装顺序不能颠倒:
rpm -ivh mysql-community-common-5.7.33-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-5.7.33-1.el7.x86_64.rpm
rpm -ivh mysql-community-devel-5.7.33-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-compat-5.7.33-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-5.7.33-1.el7.x86_64.rpm
rpm -ivh mysql-community-server-5.7.33-1.el7.x86_64.rpm
6)启动MySQL:
systemctl start mysqld
7)查看MySQL的初始密码:
grep 'temporary password' /var/log/mysqld.log
8)登录MySQL,修改初始密码:
mysql -u root -p
# 回车后输入初始密码
默认情况下,MySQL的密码要求至少12个字符,至少包含1个小写字母,1个大写字母,1个数字以及1个特殊符号,在学习环境下,不需要如此复杂的密码,所以更改MySQL的密码策略:
-- 更改MySQL关于密码长度的要求
set global validate_password_length=4;
-- 更改MySQL关于密码字符类型的要求
set global validate_password_policy=0;
更改MySQL的密码:
SET PASSWORD FOR 'root'@'localhost'= "root";
9)配置MySQL远程登录:
-- 权限
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION;
-- 策略生效
FLUSH PRIVILEGES;
-- 退出MySQL
quit;
10)设置忽略MySQL的大小写:
# 编辑文件
vim /etc/my.cnf
# 在[mysqld]下添加
lower_case_table_names=1
11) 重启mysql:
systemctl restart mysqld
Hive安装
1)进入软件预安装目录,上传或者下载Hive的安装包:
# 进入预安装目录
cd /opt/presoftware/
# 上传或者下载Hive的安装包,官网下载地址为:
wget https://dlcdn.apache.org/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
# 注意:官网提供的Hive默认是不支持Spark3的,所以最好使用我们自己编译产生的Hive安装包
2)解压:
tar -xvf apache-hive-3.1.3-bin.tar.gz -C /opt/software/
3)重命名:
# 进入软件安装目录
cd /opt/software/
# 重命名
mv apache-hive-3.1.3-bin/ hive-3.1.3
4)配置环境变量:
# 编辑文件
vim /etc/profile.d/hivehome.sh
# 在文件中添加
export HIVE_HOME=/opt/software/hive-3.1.3
export PATH=$PATH:$HIVE_HOME/bin
# 保存退出,生效
source /etc/profile.d/hivehome.sh
# 测试
hive --version
5)解决Hive的日志jar包冲突问题:
# 进入Hive的lib目录
cd /opt/software/hive-3.1.3/lib/
# 重命名
mv log4j-slf4j-impl-2.17.1.jar log4j-slf4j-impl-2.17.1.jar.bak
6)给Hive添加MySQL的连接驱动:
# 选择驱动jar包,上传
rz
7)修改Hive的配置:
# 进入Hive的配置目录
cd ../conf
# 编辑文件
vim hive-site.xml
在文件中添加:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--Hive元数据库-->
<property>
<name>hive.metastore.db.type</name>
<value>mysql</value>
</property>
<!--MySQL连接地址-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop01:3306/hive?useSSL=false</value>
</property>
<!--MySQL驱动-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!--MySQL用户名-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!--MySQL密码-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<!--Hive元数据的存储位置-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!--Hive元数据的约束-->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!--Hive元数据的访问位置-->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop01:9083</value>
</property>
<!--Hive服务的访问端口-->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<!--Hive服务监听的主机-->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop01</value>
</property>
<!--Hive的自动认证-->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
</configuration>
8)初始化Hive的元数据库:
# 进入MySQL
mysql -u root -p
# 回车之后输入密码
建立Hive的元数据库:
-- 建库吗、,需要注意的是,Hive的元数据只能是西欧编码
create database hive character set latin1;
-- 退出MySQL
quit;
9)初始化元数据库:
schematool -initSchema -dbType mysql –verbose
10)启动Hadoop:
start-all.sh
11)启动Hive的元数据服务:
hive --service metastore &
12)启动Hive:
hive
其他
Hive的运行日志
Hive启动之后,其运行日志默认是放在/tmp/用户名/hive.log中。例如root用户就是/tmp/root/hive.log,tom用户就是/tmp/tom/hive.log。
由于/tmp目录的特殊性,所以一般需要修改hive运行日志的存储位置:
1)进入Hive的配置文件目录:
cd /opt/software/hive-3.1.3/conf/
2)复制文件:
cp hive-log4j2.properties.template hive-log4j2.properties
3)编辑文件,修改属性值:
# 编辑文件
vim hive-log4j2.properties
# 修改property.hive.log.dir的属性值:
property.hive.log.dir = /opt/software/hive-3.1.3/logs
4)创建日志目录:
# 回到Hive的安装目录
cd ..
# 创建日志目录
mkdir logs
Hive重启之后,就会在指定目录下生成hive.log文件了。
参数修改方式
Hive中提供了三种指定和修改参数的方式:
1)修改hive-site.xml。这种配置方式的特点是永久有效,并且对所有的Hive进程都有效果;
2)通过hive -hiveconf XXX来修改配置。这种方式仅对当前一次会话有效,不影响其他的Hive会话。例如:
hive -hiveconf mapred.reduce.tasks = 3;
3)进入Hive之后,通过set方式修改参数配置。这种方式也是仅对当前会话有效,不影响其他的Hive会话。
三种方式的优先级是:set方式>hiveconf>配置文件hive-site.xml。
Hive SQL的执行方式
Hive中提供了三种执行SQL的方式:
1)通过hive -e "xxx"来执行SQL,例如:
hive -e "select * from person;"
2)通过hive -f xxx.sql来执行指定的SQL脚本文件;
3)进入Hive命令行之后执行SQL。
Hive的访问方式
Hive提供了两种访问方式:cli方式和hiveserver2方式。
cli方式,顾名思义,通过Hive提供的客户端来访问Hive。执行命令
hive
就可以直接进入Hive的客户端。
cli方式的优势在于不需要额外启动其他的进程,也不需要额外安装,在安装了Hive的服务器上通过hive命令就能直接使用;劣势在于这种方式无法灵活的远程连接其他服务器。
hiveserver2方式,本质上就是通过JDBC(beeline)的方式来连接Hive,这种方式需要Hadoop中指定运行环境,且还需要启动hiveserver2进程:
hive --service hiveserver2 &
hiveserver2方式的优势在于可以远程连接其他节点,劣势在于安装了Hive的服务器上需要多启动线程,而且连接客户端需要有hive jdbc的支持。
Idea/Datagrip连接Hive
1)下载Hive的连接驱动:
# 进入Hive的jdbc目录
cd /opt/software/hive-3.1.3/jdbc/
# 下载Hive的连接驱动jar包
sz hive-jdbc-3.1.3-standalone.jar
2)启动Hive的元数据服务和远程连接服务:
hive --service metastore &
hive --service hiveserver &
3)启动idea或者Datagrip:
4)点击+,选择Data Source,选择Apache Hive:

图-13 选择Hive连接
5)给Hive起名,指定连接的主机和端口,指定用户以及连接的库:

图-14 Hive连接配置
6)点击Driver:

图-15 点击Driver
7) 指定驱动,然后返回:

图-16 指定驱动
8)测试连接:

图-17 测试连接
9)应用之后,确定连接:

图-18 确定连接
10)DataGrip/idea连接Hive的时候,容易出现java.lang.OutOfMemoryError: GC overhead limit exceeded。此时需要调节YARN给Hive分配的默认内存:
# 进入Hive的配置目录
cd /opt/software/hive-3.1.3/conf/
# 复制文件
cp hive-env.sh.template hive-env.sh
# 编辑文件
vim hive-env.sh
# 在文件中添加
export HADOOP_HEAPSIZE=1024
# 保存退出,生效
source hive-env.sh
# 重新启动Hive的metastore以及hiveserver2服务即可
hive --service metastore &
hive --service hiveserver2 &
基本语法
库操作
Hive和MySQL类似,提供了针对database的操作。
1)创建库:
create database demo;
注意,每一个database在HDFS上都会对应一个目录,如果不指定,那么默认是放在/user/hive/warehouse/下。在Hive中,database的名字和存储位置一旦确定就不能修改。
2)创建库demo2,并且指定demo2在HDFS上的存储位置:
create database demo2 location '/demo2.db';
3)如果demo3库不存在,那么创建demo3:
create database if not exists demo3;
4)创建库的时候为其指定属性:
create database demo4 with dbproperties ('create_time' = '2023-07-20');
5)查询所有的库:
show databases;
6)利用正则表达式过滤符合规则的库:
show databases like 'demo*';
7)描述库的信息:
describe database demo;
-- 或者
desc database demo;
8)获取库的详细描述信息:
desc database extended demo;
9)切换/使用指定的库:
use demo;
10)修改指定库demo的属性信息:
alter database demo set dbproperties ('create_time' = '2023-07-20');
11)删除库demo4,注意,要求这个库为空:
drop database demo4;
12)判断库是否存在,如果存在,则删除:
drop database if exists demo3;
13)如果库非空,那么需要强制删除库:
drop database demo2 cascade;
表及数据操作
1)创建表:
create table person(id int, name string, age int);
需要注意的是,Hive中的每一个表在HDFS上同样对应了一个单独的目录。且在Hive中,没有主键的说法。
2)向表中添加数据:
insert into table person values (1, 'tom', 15);
Hive默认的执行引擎是MapReduce,所以所有的insert语句在底层都会转化为MapReduce任务来执行,因此效率相对较低。
3)查询数据:
select * from person;
4)将本地数据加载到Hive中:
load data local inpath '/opt/hivedata/person' into table person;
5)删除表:
drop table person;
6)在Hive中,建表的时候一般需要指定字段之间的间隔符号。当表建好之后,间隔符号就不能发生变化了:
create table person(id int, name string, age int) row format delimited fields terminated by ' ';
row format表示按行进行格式化处理,delimited表示对什么进行限制,fields表示属性,delimited fields就表示对属性进行限制,terminated by表示用什么符号作为间隔。
7)仿照person的表结构创建p2表:
create table p2 like person;
8)如果p3表不存在,那么仿照person的表结构创建p3表:
create table if not exists p3 like person;
9)创建p4表,并且复制person表的数据:
-- 复制表
create table p4 as select * from person;
-- 查询数据
select * from p4;
10)描述表的结构:
describe person;
-- 或者
desc person;
11)获取表的详细结构信息:
desc extended person;
-- 或者
desc formatted person;
12)从person表中查询age<18的数据,并且将查询出来的数据放到p2表中:
insert into table p2 select * from person where age < 18;
此处需要注意的是,如果使用的是insert into表示向表中追加数据。如果使用的是insert overwrite,则表示将表中原来的数据清空掉,覆盖写入新的数据。
13)从person表中查询数据,将id<5的数据查询出来覆盖到p2表中,将age≥18的数据查询出来追加到p3表中:
from person
insert overwrite table p2 select * where id < 5
insert into table p3 select * where age >= 18;
14) 从person表中查询数据,将查询出来age<18的数据放到本地目录下,字段之间用\t间隔:
insert overwrite local directory '/opt/hive_demo'
row format delimited fields terminated by '\t'
select * from person where age < 18;
注意,向文件中写入数据的时候只能使用insert overwrite,所以此时要求目标目录为空(即目标目录中没有子文件或者子目录,如果有子文件或者子目录,那么会被清理掉)。
15)从person表中查询数据,将查询出来age≥18的数据放到HDFS的指定目录下,字段之间用逗号间隔:
insert overwrite directory '/person_demo'
row format delimited fields terminated by ','
select * from person where age >= 18;
16)将HDFS上的指定文件加载到Hive中:
load data inpath '/person.txt' into table person;
17)将表person重命名为p1:
alter table person rename to p1;
18)修改列名:将p1表的id列名改为pid,数据类型不变:
alter table p1 change column id pid int;
19)修改列的类型:将p1表的pid列类型改为string:
alter table p1 change column pid pid string;
20)新增列:在p1表中新增一列gender:
alter table p1 add columns (gender string);
21)更换列的位置:将p1表中的name列调为第一列(注意:这种方式不更将数据更换了位置,只是列名更换了位置):
alter table p1 change column name name string first;
22)更换列的位置:将p1表中的name列放到gender列之后(注意:这种方式不更将数据更换了位置,只是列名更换了位置):
alter table p1 change column name name string after gender;
23)清空表中的数据:
truncate table p1;
24)覆盖加载:
load data local inpath '/opt/hivedata/person' overwrite into table p1;
表结构
内部表和外部表
在Hive中,所有的表都分为内部表(又叫管理表,Managed Table)和外部表(External Table)。一般而言,在Hive中手动建表手动添加数据(load或者insert)的表,大部分是内部表,而外部表是在Hive中建表来管理HDFS上已经存在的数据。
如果想要区分一个表是内部表还是外部表,可以通过命令:
desc extened tableName;
-- 或者
desc formatted tableName;
来描述这个表的详细信息,在详细信息中查看Table Type属性的值。如果是Table Type属性的值为Managed Table,就是内部表;如果是External Table,则表示外部表。
案例:建立外部表。
-- 将文件上传到HDFS的/orders目录下
-- 创建外部表
create external table orders (
name string, -- 用户名
order_date string, -- 订单日期
cost int -- 消费
) row format delimited fields terminated by ','
location '/orders';
-- 查询数据
select * from orders;
需要注意的是,外部表在删除的时候不会删除HDFS上对应的文件,但是内部表在删除的时候会删除对应的目录。
将外部表转化为内部表:
alter table orders set tblproperties ('EXTERNAL' = 'false');
将内部表转化为外部表:
alter table orders set tblproperties ('EXTERNAL' = 'true');
分区表
在Hive中,如果数据量特别大,需要对数据进行分类存储,那么要怎么处理呢?此时可以使用分区表。分区表最常见的作用就是对数据进行分类。
案例:创建分区表并加载数据。
-- 原始数据wei.txt
1 曹操
2 司马懿
3 张辽
4 荀彧
-- 原始数据shu.txt
1 刘备
2 诸葛亮
3 关羽
4 张飞
-- 原始数据wu.txt
1 孙权
2 周瑜
3 吕蒙
4 陆逊
-- 建立外部表
create table countries (
id int, -- 编号
name string -- 姓名
) partitioned by (country string) -- 以国家作为分类(分区)
row format delimited fields terminated by ' ';
-- 加载数据
load data local inpath '/opt/hivedata/wei.txt' into table countries partition (country = 'wei');
load data local inpath '/opt/hivedata/shu.txt' into table countries partition (country = 'shu');
load data local inpath '/opt/hivedata/wu.txt' into table countries partition (country = 'wu');
-- 查询数据
select * from countries;
查看HDFS会发现,每一个分区在HDFS上对应了一个单独的目录。在查询数据的时候,如果指定了分区作为查询条件,那么此时不需要读取整个表中所有的数据,而只需要读取对应分区目录下的数据即可,此时提高了查询效率;如果在查询数据的时候进行了跨分区查询,那么此时由于要读取多个文件,效率反而会有所降低。
如果在HDFS上手动创建了目录上传了文件,那么怎么让Hive知道这个新创建的目录是我们要增加的分区呢?
-- 原始数据hero.txt
1 董卓
2 吕布
3 袁术
4 袁绍
-- 在HDFS中创建目录
dfs -mkdir '/user/hive/warehouse/demo.db/countries/country=heroes';
-- 将文件传到这个目录下
dfs -put '/opt/hivedata/hero.txt' '/user/hive/warehouse/demo.db/countries/country=heroes';
-- 手动添加分区
alter table countries add partition (country = 'heroes')
location '/user/hive/warehouse/demo.db/countries/country=heroes';
-- 或者,可以选择修复分区
msck repair table countries;
注意,如果添加多个分区,那么分区之间用空格间隔:
alter table tableName add partition(partitionName = 'name1') partition(partitionName = 'name2') partition(partitionName = 'name3')...;
修改分区的名字:
alter table countries partition (country = 'heroes') rename to partition (country = 'other');
删除分区:
alter table countries drop partition (country = 'other');
注意,如果删除多个分区,那么分区之间用逗号隔开:
alter table tableName drop partition(partitionName = 'name1'), partition(partitionName = 'name2'), partition(partitionName = 'name3'), ...;
需要注意的是,在Hive中,分区表的分区字段要求在原始数据中不存在,可以认为分区字段就是要给伪劣。如果要是原始数据中存在了分区字段,那么此时就需要进行动态分区了。
动态分区案例:
-- 原始数据heroes.txt 1 wei 荀攸
2 wei 张辽
3 shu 孙乾
4 shu 马超
5 wu 张昭
6 wu 甘宁
7 wei 贾诩
8 wu 太史慈
9 shu 法正
10 shu 赵云
11 wei 程昱
12 wei 郭嘉
13 wu 黄盖
14 wu 鲁肃
15 shu 黄忠
-- 在Hive中创建临时表
create table countries_tmp ( cid int, c_country string, c_name string) row format delimited fields terminated by ' ';
-- 加载数据到临时表
load data local inpath '/opt/hivedata/heroes.txt' into table countries_tmp;
-- 查询数据
select * from countries_tmp tablesample (5 rows);
-- 开启动态分区 - 非严格模式
set hive.exec.dynamic.partition.mode=nonstrict;
-- 当有空分区生成时,是否报错
set hive.error.on.empty.partition=false;
-- 动态分区 - 从未分区表中查询数据放到已分区表中
insert into table countries partition (country)
select cid, c_name, c_country from countries_tmp distribute by c_country;
Hive也支持多字段分区。如果进行了多字段分区,那么此时前一个分区字段形成的目录会包含后一个分区字段形成的目录。多字段分区通常用于多级分类,例如省市县,学生的年级和班级,商品的一级二级三级分类等。
-- 原始数据students
1 1 1 tom
1 1 2 sam
1 1 3 bob
1 1 4 alex
1 2 1 bruce
1 2 2 cindy
1 2 3 jack
1 2 4 john
2 1 1 tex
2 1 2 helen
2 1 3 charles
2 1 4 frank
2 2 1 david
2 2 2 simon
2 2 3 lucy
2 2 4 lily
-- 建立临时表
create table students_tmp (
t_grade int, -- 年纪
t_class int, -- 班级
t_id int, -- 编号
t_name string -- 姓名
) row format delimited fields terminated by ' ';
-- 加载数据
load data local inpath '/opt/hivedata/students' into table students_tmp;
-- 查询数据
select *
from students_tmp tablesample (5 rows);
-- 开启动态分区
set hive.exec.dynamic.partition.mode=nonstric;
-- 当有空分区生成时,是否报错
set hive.error.on.empty.partition=false;
-- 创建分区表
create table students ( id int, name string) partitioned by (grade int, class int) row format delimited fields terminated by ' ';
-- 动态分区
insert into table students partition (grade, class)
select t_id, t_name, t_grade, t_class
from students_tmp distribute by t_grade, t_class;
-- 查询数据
select * from students;
分桶表
当数据量比较大,又需要对数据进行快速分析的时候,可以考虑从原始数据中抽取一部分数据来进行分析。需要注意的是,抽取的字段和要分析的字段之间不能有关联性,例如年龄和身高是有关联性的,但是姓名和身高就没有关联性。
分桶表的分桶规则是:先计算分桶字段的哈希值,然后对桶的个数进行取余,根据余数决定讲数据放入哪一个桶中。
需要注意的是,在老版本的Hive中,使用load方式加载数据不会对数据进行分桶,只能使用insert方式来回对数据进行分桶;最新版本的Hive(Hive3.1.3版本)中支持load方式分桶,但是会存在问题,所以依然建议使用insert方式来将数据放入分桶表中。
案例:
-- 开启分桶机制
set hive.enforce.bucketing = true;
-- 设置ReduceTask的个数,-1表示根据情况由Hive自己决定
set mapreduce.job.reduces = -1;
-- 建立分桶表,根据name字段的值,将数据分到4个桶中
create table students_bucket ( id int, name string ) clustered by (name) into 4 buckets row format delimited fields terminated by ' ';
-- 向分区表加载数据
insert overwrite table students_bucket select id, name from students;
数据类型
概述
Hive针对数据提供了非常丰富的数据类型,这些数据类型大致可以分为两类:基本类型和复杂类型。
Hive提供的基本类型主要包括:
表-1 基本数据类型
| Hive类型 | Java类型 |
| tinyint | byte |
| smallint | short |
| int | int |
| bigint | long |
| float | float |
| double | double |
| boolean | boolean |
| string | String |
| binary | byte[] |
| timestamp | Timestamp |
Hive提供的复杂类型主要是三个:array,map和struct类型。
复杂数据类型
array(数组)类型,对应了Java中的数组以及集合结构。
-- 原始数据
1 bob,alex lucy,lily,jack
2 tom,sam,smith rose,john
3 peter,bruce david,kathy
4 helen,eden,iran cindy,grace,mike
-- 建表
create table battles (
id int, -- 编号
group_a array<string>, -- A组
group_b array<string> -- B组
) row format delimited
fields terminated by ' ' -- 字段之间用空格间隔
collection items terminated by ','; -- 数组/集合元素之间用逗号间隔
-- 加载数据
load data local inpath '/opt/hivedata/battles' into table battles;
-- 查询数据
select * from battles tablesample (5 rows);
-- 查询A组的第一个成员
select group_a[0] from battles;
-- 非空查询
select group_a[2] from battles where group_a[2] is not null;
map(映射)类型,对应了Java中的Map类型。
-- 原始数据
1 alex,bruce
2 carl,duck
3 eden,fred
4 gill,hack
5 iran,jack
-- 建表
create table groups (
id int, -- 小组编号
members map<string, string> -- 小组成员
) row format delimited
fields terminated by ' ' -- 字段之间用空格间隔
map keys terminated by ','; -- 映射键值之间用逗号间隔
-- 加载数据
load data local inpath '/opt/hivedata/groups' into table groups;
-- 查询数据
select * from groups;
-- 非空查询
select members['carl'] from groups where members['carl'] is not null;
struct(结构体)类型,对应了Java中的对象,可以看作是将数据封装成了json串形式。
-- 原始数据
1 tom,19,male sam,20,male
2 lily,18,female lucy,19,female
3 charles,19,male mark,21,male
4 joan,18,female james,20,male
5 linda,20,female matin,21,male
-- 建表
create table infos
(
id int, -- 小组编号
member_a struct<name:string, age:int, gender:string>, -- 成员A
member_b struct<name:string, age:int, gender:string> -- 成员B
) row format delimited fields terminated by ' ' -- 字段之间用空格间隔
collection items terminated by ','; -- 属性之间用逗号间隔
-- 加载数据
load data local inpath '/opt/hivedata/infos' into table infos;
-- 查询数据
select * from infos tablesample (5 rows);
-- 查看成员A的名字
select member_a.name from infos;
运算符和函数
概述
Hive针对大量的数据,提供了非常丰富的运算符和函数用于进行数据的处理和分析。同时,为了提供更灵活的操作,Hive还允许用户自定义函数。
但是需要注意的是,在Hive中,所有的运算符和函数都不能直接使用,而是必须结合其他关键字构成语句,例如结合select构成查询语句等。
如果想要查看Hive中提供的所有运算符和函数,可以通过命令:
show functions;
如果想要查看某一个函数的介绍,可以通过命令:
desc function functionName;
-- 例如
desc function sum;
如果想要查看某一个函数的详细用户,可以通过命令:
desc function extended functionName;
-- 例如:
desc function extended trim;
入门案例
案例一:给定某一个日期,例如'2023-07-20',从中截取年份。
-- 方式一:通过-来切分日期,然后获取切分之后的第一个字段
select cast(split('2023-07-20', '-')[0] as int);
-- 方式二:通过year函数提取,但是这种方式要求年月日之间必须用-间隔
select year('2023-07-20');
案例二:给定某一个日期,例如'2023/07/20',从中截取年份。
-- 方式一:切分之后提取
select cast(split('2023/07/20', '/')[0] as int);
-- 方式二:先将日期中的/替换为-,再用year函数提取
select year(regexp_replace('2023/07/20', '/', '-'));
案例三:给定邮箱,例如'tom@test.com',从中提取邮箱后缀。
-- 方式一:切分之后提取
select split('tom@test.com', '@')[1];
-- 方式二:利用正则表达式提取
select regexp_extract('tom@test.com', '(.+)@(.+)', 2);
常用函数
nvl函数
nvl(v1, v2)函数,在使用的时候需要传入两个参数v1和v2。如果v1的值不为null,则返回v1;反之,如果v1的值为null,则返回v2;如果v1和v2的值都是null,则返回null。
案例:计算员工的平均奖金。
-- 原始数据
1 Bill 1000
2 Vincent 800
3 William 500
4 Henry
5 Betty 500
6 Fred 300
7 Karl
8 Lee 400
9 Thomas 600
10 Shirley 900
-- 建表
create table rewards (
id int, -- 员工编号
name string, -- 员工姓名
reward double -- 获得的奖金
) row format delimited fields terminated by ' ';
-- 加载数据
load data local inpath '/opt/hivedata/rewards' into table rewards;
-- 查询数据
select *
from rewards tablesample (5 rows);
-- 计算员工的平均奖金
-- 对于avg这一类聚合函数而言,当数据的值为null的时候,会自动跳过
select avg(reward) from rewards;
-- 如果员工没有发放奖金,那么奖金应该记为0
select avg(nvl(reward, 0)) from rewards;
case when函数
case when函数,类似于Java中的switch-case结构,用于对数据进行判断。
案例:统计每一个部门中男生和女生的人数。
-- 原始数据
1 财务 bill 男
2 技术 charles 男
3 技术 lucy 女
4 技术 lily 女
5 财务 helen 女
6 财务 jack 男
7 财务 john 男
8 技术 alex 男
9 技术 cindy 女
10 技术 david 男
-- 建表
create table employers (
id int, -- 员工编号
department string, -- 员工部门
name string, -- 员工姓名
gender string -- 性别
) row format delimited fields terminated by ' ';
-- 加载数据
load data local inpath '/opt/hivedata/employers' into table employers;
-- 查询每一个部门中男生和女生的人数分别是多少
-- if结构
select department as `部门`,
sum(if(gender = '男', 1, 0)) as `男生人数`,
sum(if(gender = '女', 1, 0)) as `女生人数`
from employers group by department;
-- case-when结构
select department as `部门`,
sum(case gender when '男' then 1 else 0 end) as `男生人数`,
sum(case gender when '女' then 1 else 0 end) as `女生人数`
from employers group by department;
explode函数
explode函数,在使用的时候需要传入一个数组或者映射类型的参数。如果传入的是数组,那么会将这个数组中的每一个元素提取出来形成单独的一行数据;如果传入的是一个映射,那么会将这个映射中的键值对提取出来形成两列元素。
案例:统计文件中每一个单词出现的次数。
-- 原始数据
hello tom hello bob david joy hello
hello rose joy hello rose
jerry hello tom hello joy
hello rose joy tom hello David
-- 建表
create table words (
line array<string>
) row format delimited collection items terminated by ' ';
-- 加载数据
load data local inpath '/opt/hivedata/words' into table words;
-- 查询数据
select * from words;
-- 统计文件中每一个单词出现的次数
select w as `word`, count(w) as `count` from (
select explode(line) as w from words
) ws group by w;
列转行
所谓列转行,顾名思义,指的是将一列的数据拆分成多行。在列转行的过程中,要使用的非常重要的函数就是explode。
案例:查询所有的恐怖片。
-- 原始数据
封神第一部:朝歌风云 动作/战争/奇幻/古装
芭比 喜剧/奇幻/冒险
长安三万里 动画/历史
超能一家人 喜剧/家庭/奇幻
茶啊二中 喜剧/动画/奇幻
祭屋出租 悬疑/惊悚/恐怖
东北警察故事2 剧情/动作/犯罪
触底反弹 剧情/运动
-- 建表
create table movies (
name string, -- 电影名
types array<string> -- 电影类型
) row format delimited fields terminated by ' '
collection items terminated by '/';
-- 加载数据
load data local inpath '/opt/hivedata/movies' into table movies;
-- 查询数据
select * from movies tablesample (5 rows);
-- 查询所有的动画片
-- 语法:lateral view functionName(expression) tableAlias as colAlias
-- 这个过程称之为'炸列'
select name, t from movies lateral view explode(types) ts as t where t = '动画';
同样,列转行,也支持对多列进行拆分:
-- 原始数据
Kevin 活泼/开朗 打篮球/看电影
Lisa 大方/活泼 看电影/听音乐
Carl 活泼/幽默 打篮球/打游戏
Joy 大方/文静 听音乐/看书
--建表
drop table students;
create table students (
name string, -- 姓名
characters array<string>, -- 性格
hobbies array<string> -- 爱好
) row format delimited fields terminated by ' '
collection items terminated by '/';
-- 加载数据
load data local inpath '/opt/hivedata/students' into table students;
-- 查询性格活泼,喜欢打篮球的学生
select name from students
lateral view explode(characters) cs as c lateral view explode(hobbies) hs as h
where c = '活泼' and h = '打篮球';
列转行
所谓列转行,顾名思义,是将多行的数据合并到一列上。这个过程中,一般需要使用函数collect_set或者collect_list,如果是转化为stuct结构,那么需要使用named_struct函数。
collect_set和collect_list都是将多个元素汇聚成一个数组,二者的区别是:collect_set不允许元素重复,collect_list允许元素重复。
案例:将同一个年级同一个班级的学生汇聚到一行。
-- 原始数据
1 1 burt
1 2 james
1 4 fred
1 2 bruce
1 1 carol
1 3 taylor
1 4 evan
1 3 grace
1 1 richard
1 3 adam
1 4 ben
1 1 ross
1 2 charles
1 4 cody
1 3 wendy
1 2 david
-- 建表
drop table students;
create table students (
grade int, -- 年纪
class int, -- 班级
name string -- 姓名
) row format delimited fields terminated by ' ';
-- 加载数据
load data local inpath '/opt/hivedata/students' into table students;
-- 查询数据
select * from students tablesample (5 rows);
-- 将同一个年级同一个班级的学生汇聚到一行
select grade, class, concat_ws(',', collect_list(name)) from students group by grade, class;
函数分类
在Hive中,函数可以分为UDF、UDAF、UDTF以及窗口函数。
UDF(User Defined Function):用户定义函数。特点是一进一出,即用户输入一行数据会获取到一行结果。例如year、length、regexp_replace、concat、split等。
UDAF(User Defined Aggration Function):用户定义聚合函数。特点是多进一出,即用户输入多行数据会获取到一行结果。例如min、max、sum、avg、collect_set、collect_list等。
UDTF(User Defined Table-generated Function):用户定义表生成函数。特点是一进多出,即用户输入一行数据会获取到多行结果。例如explode、posexplode、inline、stack、json_tuple、parse_url_tuple等。
Hive中提供的大部分函数都是UDF函数。
自定义函数
POM依赖
创建Maven工程,导入POM依赖:
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>3.1.3</version>
<exclusions>
<exclusion>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-metastore</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-common</artifactId>
<version>3.1.3</version>
</dependency>
</dependencies>
自定义UDF函数
如果需要自定义UDF函数,那么需要定义类继承父类。需要注意的是,Hive1.x和Hive2.x中需要继承的是UDF类,Hive3.x中需要继承的是GenericUDF。
package com.auth;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
public class AuthUDF extends GenericUDF {
// 初始化方法,这个方法的返回值决定了evaluate方法的返回值类型
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
if (arguments.length != 2)
throw new UDFArgumentException("参数个数必须是2个!");
return PrimitiveObjectInspectorFactory.javaIntObjectInspector;
}
// 函数实际的处理逻辑覆盖在这个方法中
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
// 获取原字符串
String str = arguments[0].get().toString();
// 获取子串
String sub = arguments[1].get().toString();
// 返回子串第一次出现的位置
return str.indexOf(sub);
}
@Override
public String getDisplayString(String[] children) {
return "";
}
}
自定义UDTF函数
在Hive3.x中,如果需要自定义UDTF函数,那么需要定义类继承GenericUDTF,覆盖其中的方法。
package com.auth;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.util.ArrayList;
import java.util.List;
// 根据指定符号,将字符串切分为多行数据
public class AuthUDTF extends GenericUDTF {
// 定义列表用于存储数据
private final List<String> values = new ArrayList<>();
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) {
// 定义列表,用于存储输出列名
List<String> fieldName = new ArrayList<>();
fieldName.add("strToLine");
// 定义数据输出的类型
List<ObjectInspector> fieldType = new ArrayList<>();
fieldType.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
// 返回
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldName, fieldType);
}
@Override
public void process(Object[] args) throws HiveException {
// 获取字符串
String str = args[0].toString();
// 判断是否指定了切分符号,如果没有指定,那么默认以-作为切分符号
String symbol = "-";
if (args.length > 1) symbol = args[1].toString();
// 拆分字段
String[] arr = str.split(symbol);
// 遍历,写出
for (String s : arr) {
// 集合复用
values.clear();
// 添加元素
values.add(s);
// 推出元素
forward(values);
}
}
@Override
public void close() {
}
}
无论是自定义UDF还是自定义UDTF函数,都需要将定义好的程序打成jar包。
创建函数
创建临时函数:
1)将jar包上传到Linux的目录下,例如/opt/hivedata目录。
2)在Hive中指定命令,添加jar包:
add jar /opt/hivedata/G_Hive-1.0-SNAPSHOT
3)创建临时函数:
create temporary function indexof as 'com.auth.AuthUDF';
create temporary function stringToLine as 'com.auth.AuthUDTF';
注意:临时函数只和会话有关。如果当前会话关闭,那么临时函数就会失效,下次连接之后如果想要使用只能重新add和create。
创建永久函数:
1)将jar包上传到HDFS上。
2)创建函数:
-- UDF函数
create function indexOf
as 'com.auth.AuthUDF'
using jar 'hdfs://hadoop01:9000/hive_function/G_Hive-1.0-SNAPSHOT.jar';
-- UDTF函数
create function strToLine
as 'com.auth.AuthUDTF'
using jar 'hdfs://hadoop01:9000/hive_function/G_Hive-1.0-SNAPSHOT.jar';
如果需要删除永久函数,那么命令为:
drop function functionName;
窗口函数
概述
窗口函数(over函数),又叫开窗函数,不同于之前函数的地方在于,它是针对每一行数据进行一次计算返回一个结果。实际过程中,需要灵活运用窗口函数来限定数据的处理范围。
窗口函数的基本语法结构为:
分析函数() over(partition by 字段 order by 字段 [asc/desc] rows between 起始行 and 结束行)
其中,rows between表示限定数据处理范围,需要用的关键字包含:preceding-向前,following-向后,unbounded-无边界,current row-当前行。例如:
1)2 preceding and current row表示当前行以及前两行。例如当前行为第5行,那么就表示处理3-5行的数据。
2)current row and 2 following表示当前行以及后两行。例如当前行为第5行,那么就表示处理5-7行的数据。
3)unbounded preceding and current row表示从开始处理到当前行。
4)current row and unbounded following表示从当前行开始处理到最后一行。
partition by表示对数据进行分区,order by表示对数据进行排序,asc表示升序,desc表示降序。需要注意的是,如果没有指定partition by,那么就是对数据进行整体排序;如果指定了partition by,那么则表示在每一个分区中对数据进行排序。
分析函数指的是对每一行数据进行处理的函数,可以总结为三大类函数:聚合函数、移位函数和排序函数:
1)聚合函数,对数据进行聚合处理,例如min、max、sum、avg等。
2)移位函数,包含lag、lead和ntile三个。
3)排序函数,包含row_number,rank和dense_rank三个。
聚合及移位案例
有原始数据如下:
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,94
建表:
create table orders (
name string, -- 顾客姓名
order_date string, -- 消费日期
cost double -- 消费金额
) row format delimited fields terminated by ',';
加载数据:
load data local inpath '/opt/hivedata/orders' into table orders;
需求一:查询每一个顾客的消费明细以及到当前日期为止的总计消费。
select *,
sum(cost) over (partition by name order by order_date rows between unbounded preceding and current row ) as total
from orders;
需求二:查询顾客上一次购买的时间。
-- lag(col, n):表示以当前行为基础,处理第前n行。例如当前行为第5行,那么lag(col, 2)就表示处理第三行数据
-- 上一次的购买时间,那么就是上一行数据
select name, order_date,
lag(order_date, 1) over (partition by name order by order_date) as last_date
from orders;
需求三:获取最早进店消费的前20%的顾客名单。
-- ntile(n):将数据排序之后,平均分发到指定的n个桶中
-- ntile会给每一个桶进行编号,编号从1开始,之后会将这个编号分发给这个桶中的每一个数据上
-- 如果数据不能平均分配,则会优先将较小的数据分配到较小的桶中,各个桶之间的行数只差不能超过1个
-- 获取前20%的数据,就是前1/5的数据,那么只需要将数据排序之后分到5个桶中,然后获取编号为1的桶即可
select name from (
select name, ntile(5) over (order by order_date ) as n from orders
) tmp where n = 1;
排序函数案例
有原始数据如下:
Charles Chinese 87
Charles Math 95
Charles English 68
Lily Chinese 94
Lily Math 56
Lily English 84
William Chinese 64
William Math 86
William English 84
Vincent Chinese 65
Vincent Math 85
Vincent English 78
建表语句如下:
create table scores (
name string, -- 姓名
subject string, -- 科目
score int -- 成绩
) row format delimited fields terminated by '\t';
加载数据:
load data local inpath '/opt/hivedata/scores' into table scores;
需求一:按照各科成绩对学生进行降序排序。
-- row_number:顺次编号,不产生空位。即使值一样,编号也是顺次的
-- rank:顺次编号,产生空位。即值一样,编号相同,但是会跳过后边几个编号
-- dense_rank:顺次编号,不产生空位。即值一样,编号相同,但是不会跳过编号
select *,
row_number() over (partition by subject order by score desc) as `row_number`,
rank() over (partition by subject order by score desc) as `rank`,
dense_rank() over (partition by subject order by score desc) as `dense_rank`
from scores;
需求二:获取各科考试成绩的前三名同学的姓名、科目和成绩。
select name, subject, score, n from (
select *, rank() over (partition by subject order by score desc) as n from scores
) tmp where n <= 3;
其他操作
join
同MySQL类似,Hive也提供了表之间的连接操作,包含内连接inner join,左外连接left join,右外连接right join,全外连接full outer join。同时,Hive中还提供了left semi join。

图-19 join方式
案例:
-- 原始数据 - orders.txt
1001 20170710 4 2
1002 20170710 3 100
1003 20170710 2 40
1004 20170711 2 23
1005 20170711 4 55
1006 20170823 3 20
1007 20170823 2 3
1008 20170823 4 23
1009 20170912 2 10
1010 20170912 2 2
1011 20170914 3 14
1012 20170914 3 18
-- 原始数据 - products.txt
1 chuizi 3999
2 huawei 3999
3 xiaomi 2999
4 apple 5999
-- 建立orders表
drop table if exists orders;
create table orders (
order_id string, -- 订单号
order_date string, -- 订单日期
product_id string, -- 商品号
num int -- 售出数量
) row format delimited fields terminated by ' ';
-- 建立products表
drop table if exists products;
create table products (
product_id string, -- 商品编号
product_name string, -- 商品名
price double -- 单价
) row format delimited fields terminated by ' ';
-- 加载数据
load data local inpath '/opt/hivedata/orders' into table orders;
load data local inpath '/opt/hivedata/products' into table products;
-- 查询数据,确保数据正常加载
select * from orders tablesample (5 rows);
select * from products tablesample (5 rows);
-- 需求一:获取每天卖了多少钱
select o.order_date as order_date,
sum(o.num * p.price) as total
from orders o join products p on o.product_id = p.product_id
group by o.order_date;
-- 需求二:获取哪些商品被卖出去过
-- a left semi join b:表示a表中哪些数据在b表中出现过
-- 获取哪些商品被卖出去过,那么就是获取商品表中哪些数据在订单表中出现过
select p.product_id, p.product_name, p.price
from products p left semi join orders o on p.product_id = o.product_id;
having
having关键字,需要结合group by来使用,对分组之后的聚合结果进行过滤。having和where不同的地方在于:where是直接对已有字段进行查询过滤;having是对聚合函数的结果进行过滤。
案例:获取平均工资超过5000的员工。
-- 原始数据
1 Apollo 4900
1 Billy 5100
1 Cary 4700
1 Dylan 5000
1 Ford 4800
2 Apollo 5200
2 Billy 4700
2 Cary 4900
2 Dylan 5100
2 Ford 5000
3 Apollo 4900
3 Billy 5200
3 Cary 4700
3 Dylan 4600
3 Ford 5300
-- 建表
drop table if exists salaries;
create table salaris (
month int, -- 月份
name string, -- 员工姓名
salary double -- 员工薪资
) row format delimited fields terminated by ' ';
-- 加载数据
load data local inpath '/opt/hivedata/salaries' into table salaris;
-- 查询数据
select * from salaris tablesample (5 rows);
-- 需求:查询平均工资超过5000的员工
select name, avg(salary) as avg_sal from salaris group by name having avg_sal > 5000;
排序
在Hive中,针对数据提供了两种排序方式:
1)order by:全局排序。在排序的时候会忽略掉ReduceTask的数量,对所有的数据进行整体的排序,默认是升序排序。
2)sort by:局部排序。这种方式,会在每一个ReduceTask内部对数据进行排序。假设设置了3个ReduceTaks,那么默认情况下,会先根据数据的哈希码,将数据分发到3个ReduceTask中,然后每一个ReduceTask中对数据进行排序,默认是升序排序。
如果只有1个ReduceTask,那么order by和sort by效果相同。
案例演示:
-- 原始数据
3 Max 89
1 Eric 89
3 Paul 82
1 Hank 95
2 Larry 74
1 Henry 84
2 Justin 82
3 Tim 85
2 ken 84
1 Ivan 85
3 Nick 84
2 Leo 82
2 Mars 86
1 Jim 74
3 Reed 81
-- 建表
drop table if exists students;
create table students (
class int, -- 班级
name string, -- 姓名
score int -- 成绩
) row format delimited fields terminated by ' ';
-- 加载数据
load data local inpath '/opt/hivedata/students' into table students;
-- 查询数据
select * from students tablesample (5 rows);
-- 设置ReduceTask的数量为3
set mapred.reduce.tasks = 1;
-- 或者
set mapreduce.job.reduces = 3;
-- order by排序
insert overwrite local directory '/opt/hive_demo/order_by' row format delimited fields terminated by ' '
select * from students order by score desc;
-- sort by排序
insert overwrite local directory '/opt/hive_demo/sort_by' row format delimited fields terminated by ' '
select * from students sort by score desc;
实际过程中,sort by一般会结合distribute by来使用。distribute by是将数据进行分区(分类),而sort by是针对每一个分区中的数据进行排序。
-- 需求:按照班级,在每一个班级内按照学生的成绩降序排序
insert overwrite local directory '/opt/hive_demo/distribute_by' row format delimited fields terminated by ' '
select * from students distribute by class sort by score desc;
当distribyte by和sort by字段相同时,可以使用cluster by。不过需要注意的是cluster by只能升序排序,不能降序排序。
insert overwrite local directory '/opt/hive_demo/cluster_by' row format delimited fields terminated by ' '
select * from students cluster by score;
beeline
beeline是Hive提供的用于进行远程连接的一种方式,本质上底层是使用JDBC的方式来连接Hive。使用beeline的时候需要开启Hive的远程连接服务hiveserver2。
启动beeline的命令如下:
beeline -u jdbc:hive2://hadoop01:10000/demo -n root
其中,参数-u表示url连接地址,-n表示name连接用户名。
JDBC
Hive支持JDBC操作,语法与MySQL类似:
import java.sql.*;
public class HiveJDBCDemo {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
// 注册驱动
Class.forName("org.apache.hive.jdbc.HiveDriver");
// 获取连接
Connection con = DriverManager.getConnection("jdbc:hive2://hadoop01:10000/demo", "root", "root");
// 获取表述
Statement stat = con.createStatement();
// 执行查询,获取结果集
ResultSet set = stat.executeQuery("select * from products");
// 遍历结果集
while (set.next()) {
System.out.println(set.getString("product_name"));
}
// 关闭连接
set.close();
stat.close();
con.close();
}
}
SerDe
SerDe(Serializar/Deserializar)是Hive提供的一套用于对数据进行序列化和反序列化的机制。在使用SerDe的时候,需要指定正则表达式,然后利用正则表达式去解析数据。而正则表达式中的每一个捕获组对应Hive表中的一个字段。
案例:
-- 原始数据tomcat.log
192.168.120.23 -- [30/Apr/2018:20:25:32 +0800] "GET /asf.avi HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:32 +0800] "GET /bupper.png HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:32 +0800] "GET /bupper.css HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:33 +0800] "GET /bg-button HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:33 +0800] "GET /bbutton.css HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:33 +0800] "GET /asf.jpg HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:33 +0800] "GET /tomcat.css HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:33 +0800] "GET /tomcat.png HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:33 +0800] "GET /tbutton.png HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:33 +0800] "GET /tinput.png HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:33 +0800] "GET /tbg.css HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:34 +0800] "GET /tomcat.css HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:34 +0800] "GET /bg.css HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:34 +0800] "GET /bg-button.css HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:34 +0800] "GET /bg-input.css HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:34 +0800] "GET /bd-input.png HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:34 +0800] "GET /bg-input.png HTTP/1.1" 304 -
192.168.120.23 -- [30/Apr/2018:20:25:34 +0800] "GET /music.mp3 HTTP/1.1" 304 -
-- 方式一:不使用SerDe
-- 建立临时表
create table logs_tmp ( log string);
-- 加载数据
load data local inpath '/opt/hivedata/tomcat.log' into table logs_tmp;
-- 查询数据
select * from logs_tmp tablesample (5 rows);
-- 建立日志表
create table logs (
host string, -- 主机名/ip
log_date string, -- 访问日期
timezone string, -- 时区
request_way string, -- 请求方式
resources string, -- 请求资源
protocol string, -- 请求协议
state_id int -- 状态码
) row format delimited fields terminated by '\t';
-- 解析数据,放入日志表中
insert into table logs
select arr[0], arr[1], arr[2], arr[3], arr[4], arr[5], cast(arr[6] as int) from (
select split(regexp_replace(log, '(.*) \-\- \\[(.*) (.*)\\] \"(.*) (.*) (.*)\" ([0-9]+) \-','$1 $2 $3 $4 $5 $6 $7'), ' ') as arr from logs_tmp
) tmp;
-- 查询数据
select * from logs tablesample (5 rows);
-- 方式二:使用SerDe
-- 建立日志表
create table logs2 (
host string, -- 主机名/ip
log_date string, -- 访问日期
timezone string, -- 时区
request_way string, -- 请求方式
resources string, -- 请求资源
protocol string, -- 请求协议
state_id int -- 状态码
) row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe'
with serdeproperties ('input.regex' = '(.*) \-\- \\[(.*) (.*)\\] \"(.*) (.*) (.*)\" ([0-9]+) \-')
stored as textfile;
-- 加载数据
load data local inpath '/opt/hivedata/tomcat.log' into table logs2;
-- 查询数据
select * from logs2 tablesample (5 rows);
视图
视图是对原表中部分字段进行抽取,可以看作是原表的一个子表,但是本质上是一个虚拟表。通过视图,可以展现基表中的部分数据。视图可以分为虚拟视图和物化视图,而Hive只支持虚拟视图。
在定义视图的时候,需要封装一个select语句,用于从基表中抽取数据,而封装的这个select语句在创建视图的时候并不执行,而是在第一次使用视图的时候才会真正执行。
视图的优点:
1)简单。使用视图的时候,完全不需要关心视图背后的基表结构、关联条件和筛选条件,对用户而言,视图就是过滤好的符合条件的结果集。
2)安全。使用试图的用户只能访问他们被允许查询的结果集,且视图只能查询不能修改,不影响之后基表数据。
3)数据独立。一旦视图的结构确定,那么就可以屏蔽表结构变化对用户的影响。例如基表中增添列,不会影响视图的操作。
创建视图:
create view logs_view as select host, log_date, resources from logs order by log_date;
查询视图:
select * from logs_view;
删除视图:
drop view logs_view;
Hive存储
文件存储格式
概述
在Hive中,主流的文件存储格式主要是6种:textfile,RCFile,avro,orc,parquet以及sequencefile形式。其中,textfile和sequencefile采用的是行存储形式,orc和parquet采用的是列存储形式。如果不指定,那么Hive默认采用textfile形式将数据落地到HDFS上。
textfile格式
Hive默认就是以textfile格式落地到HDFS上。默认情况下,textfile不对数据进行压缩,因此占用磁盘空间比较大,在进行数据分析的时候开销也相对较大。
textfile支持Gzip和Bzip2格式的压缩,但是Gzip格式不支持切片,因此使用Gzip格式就无法对数据进行并行操作。
orc格式
orc(Optimized Row Columnar,优化的行列)格式是Hive0.11版本中引入的一种文件格式,是以列存储的方式来存放数据。
每一个orc文件主要由1到多个Stripe,1个File Footer以及1个Postscript构成。每一个Stripe中包含了多条数据,这些数据按照列形式来独立存储。默认情况下,每一个Stripe大小为250M。

图-20 orc文件
Stripe主要由三部分组成:Index Data,Row Data和Stripe Footer。
1)Index Data:轻量级的索引结构,默认是每10000行数据形成一次索引,会记录每一列的最小值、最大值以及每一列中的行索引。如果指定,还可能包含位域或者是布隆过滤器。
2)Row Data:存储数据。在存储的时候,先取部分行,然后将每一行数据的字段拆分之后以列形式存储。在存储的时候,会对每一个列进行编码,封装成一个个的Stream结构来存储。因为同一个列中的字段类型是一致的,所以可以更好的采用压缩机制来进行压缩。
3)Stripe Footer:存储每一个Stream的类型、长度等信息,实际上就是记录每一列的数据类型、存储的数据的大小等信息。
每一个文件尾部都会有一个File Footer,用于记录每一个Stripe中的行数,每一个列的数据类型信息。File Footer中还包含列级别的聚合结果,包含count、min、max、sum。
每一个文件末尾都是一个Postscript,这里面记录了整个文件的信息,例如文件是否压缩,压缩算法等信息,还记录了File Footer在orc文件中的其实位置。因此,在读取orc文件的时候,需要先读取文件末尾的Postscript,获取到File Footer在文件中的存储位置,然后再读取File Footer,获取到Stripe所在的偏移量(文件中的存储位置),之后读取Stripe中的Index Data,锁定数据在Row Data中的位置,最后读取Row Data中的数。

图-21 orc解析
parquet格式
parquet格式是从Hive0.10开始提供的一种文件格式,本身是一种二进制形式的文件,所以不能直接读取。parquet文件中包含了数据以及描述数据的元数据,所以parquet文件是自解析文件。
每一个parquet文件会包含四部分:1个Magic Code(魔数编码),1个Footer Length,1个Metastore,以及包含1个到多个行组(Row Group)。
其中,Magic Code用于确保当前文件是一个parquet文件;Footer Length记录了元数据的大小,通过这个值以及文件的大小可以计算出元数据在文件中的偏移量;Metastore是元数据,记录了当前parquet文件的文件信息,例如文件大小,Row Group的数量等。
Row Group是将数据从行方向上进行的物理切分。默认情况下,每一个Row Group和HDFS的Block是等大的。
每一个Row Group中包含一个到多个列块(Column Chunk)。列块是将数据按照列形式进行存储,每一列对应一个列块,因此每一个列块中数据的类型是相同的,不同列块之间可以使用不同的压缩算法。列块之间是连续存储在这个行组中的。
每一个Column Chunk中会包含一个到多个页(Page),Page是parquet文件中数据存储的最小单元,同一个列块的不同页可以使用不同的编码方式。
Page分为三种:数据页,字典页和索引页。
1)数据页用于存储当前列块中的数据;
2)字典页用于存储编码信息;
3)索引页用于存储数据在文件中偏移位置。每一个列块中最多只有一个字典页。
需要注意的是,Hive原生生成的parquet文件中不支持索引页。

图-22 parquet文件格式
Hive压缩
Hive支持对输出的数据进行压缩,根据文件格式不同,支持的压缩算法不同。其中,比较常用的是orc格式的文件压缩和parquet格式的文件压缩。
如果想要对orc格式的文件进行压缩,可以通过orc.compress属性进行配置,可以配置的属性值包含NONE,ZLIB,SNAPPY。其中NONE表示不压缩。
创建一个表,文件格式为orc格式,压缩格式为zlib:
create table orc_zlib (id int, name string)
row format delimited fields terminated by ' '
stored as orc tblproperties ("orc.compress" = "ZLIB");
创建一个表,文件格式为orc格式,压缩格式为snappy:
create table orc_snappy(id int, name string)
row format delimited fields terminated by ' '
stored as orc tblproperties ("orc.compress" = "SNAPPY");
如果想要对parquet格式的文件进行压缩,可以通过属性parquet.compression进行配置,经常使用的是SNAPPY。
create table parquet_snappy ( id int, name string)
row format delimited fields terminated by ' '
stored as parquet tblproperties ("parquet.compression" = "SNAPPY");
Hive结构及优化
结构
Hive结构如下图:

图-23 Hive结构
1)Client Interface主要分为两种:CLI(command-line interface,命令行方式)和JDBC/ODBC(beeline采用的就是JDBC方式)。
2)Metastore:用于存储元数据,维系在关系型数据库中,默认是Derby,实际过程中一般是使用MySQL。
3)Driver:驱动器,包含了四部分。SQL Parser(SQL解析器)会查询元数据,确认SQL语法是否正确,然后将SQL转化为抽象语法树AST。Physical Plan(编译器)会将抽象语法树AST编译生成要执行的逻辑执行计划。Query Optimizer(优化器)对逻辑计划进行优化。Execution(执行器)负责将逻辑计划转化为要实际执行的物理计划,例如MapReduce程序。
优化
列裁剪或者分区裁剪
在生产环境中,经常要处理大量数据,而此时如果使用select * from tableName的形式,会对整个表进行扫描,数据量越大效率月底。所以在实际过程中查询数据的时候,最好指定列或者指定分区;如果是按行查询,最好限定行数,例如使用limit或者tablesample(x rows)形式。
group by优化
在Hive中进行group by的时候,会将相同的key对应的值分发给同一个ReduceTask处理。此时如果某一个key对应的数据格外多,那么就会造成整个ReduceTaks效率较低,从而产生了数据倾斜。针对这个问题,有两种优化方式:map端聚合以及二阶段聚合(负载均衡机制)。
map端聚合,顾名思义,就是先将数据在Map端经过一次聚合计算,再将聚合结果发送给Reduce端处理。
-- 开启聚合机制
set hive.map.aggr = true;
-- 指定聚合条数
set hive.groupby.mapaggr.checkinterval = 10000;
二阶段聚合(负载均衡模式),顾名思义,是将Hive的执行过程拆分成两个MapReduce任务来执行:第一个MapReduce Job负责将数据大三,此时相同的键可以不会分布到同一个ReduceTask上,然后每一个ReduceTask对结果进行聚合;之后第二个MapReduce Job再读取上一次的聚合结果,按照指定分组处理数据,此时相同的键才会分不到同一个ReduceTask上。
-- 开启二阶段聚合
set hive.groupby.skewindata = true;
CBO
从Hive0.1.0开始,加入了CBO(Cost based Optimizer,基于成本的优化器)来对SQL执行计划进行优化。从Hive1.1.0版本开始,CBO默认是开启的,可以通过属性hive.cbo.enable来调节。
CBO,成本优化器,遵循的原则是:代价最小的执行计划就是最好的执行计划。在任务最终执行之前,CBO会优化每一个查询的执行逻辑和物理执行计划,在底层会根据查询成本执行优化,自动优化SQL中多个join的执行顺序,并选择合适的join算法。
谓词下推
所谓谓词下推,指的是在保证结果正确的前提下,将SQL语句中的where过滤(过滤条件就是谓词)尽可能的提前执行,以此来减少下游处理的数据量。通过谓词下推,过滤条件将在Map端提前执行,减少了Map端的输出,降低了数据的IO,从而提升了性能。
-- 开启谓词下推
-- 此选项默认为true,ppd全称为PredicatePushDown,预测/谓词下推
set hive.optimize.ppd = true;
Map join
Map join,指的是在两个表或者多个表进行join的时候,将较小的表直接分发到各个MapTask所在节点的内存中,在MapTask中进行join,从而避免了Reduce端的join操作。如果不指定Map join或者不符合Map join的条件,那么Hive解析器会将Join操作转化为Common Join(普通join),然后在Reduce端完成join,那么此时容易产生数据倾斜。
-- 开启map side join。Hive3.X中,这个属性默认为true
set hive.auto.convert.join = true;
-- 设置小表阈值,默认为25M
set hive.mapjoin.smalltable.filesize = 25000000
SMB join
SMB(sort merge bucket) join,是基于分桶机制和Map join实现的一种join方式,旨在用于解决大表和大表之间的join问题。当A表和B表都比较大的时候,那么此时两个表进行join,那么需要计算的数据量就会较大,相对效率较低,此时可以采用SMB join。
SMB join本质上就是将数据分到多个桶中,那么此时每一个桶就相当于是一个小表,那么在join的时候就是小表和大表的join,可以采用map join方式,所以本质上就是一种"分而治之"的思想。
SMB join的使用必须符合两个条件:
1)A表和B表必须是分桶表,且B表的桶数必须是A表桶数的整数倍。例如A表分了6个桶,那么B表的桶数必须是6n(n≥1)。
2)分桶条件和join条件必须一致。即对于select * from a join b on a.id = b.pid而言,由于join条件是a.id和b.pid,所以此时要求A表必须根据id字段分桶,B表必须根据pid字段分桶,根据其他字段分桶无效。
SMB join相关参数:
-- 开启SMB join
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.input.format = org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
启用严格模式
将hive.strict.checks.no.partition.filter设置为true之后,对于分区表,除非where语句中含有分区字段过滤条件来限制范围,否则不允许执行。换句话说,就是用户不允许扫描所有分区。进行这个限制的原因是,通常分区表都拥有非常大的数据集,而且数据增加迅速。没有进行分区限制的查询可能会消耗令人不可接受的巨大资源来处理这个表。
将hive.strict.checks.orderby.no.limit设置为true时,对于使用了order by语句的查询,要求必须使用limit语句。因为order by为了执行排序过程会将所有的结果数据分发到同一个Reducer中进行处理,强制要求用户增加这个LIMIT语句可以防止Reducer额外执行很长一段时间。
将hive.strict.checks.cartesian.product设置为true时,会限制笛卡尔积的查询。对关系型数据库非常了解的用户可能期望在执行JOIN查询的时候不使用ON语句而是使用where语句,这样关系数据库的执行优化器就可以高效地将WHERE语句转化成那个ON语句。不幸的是,Hive并不会执行这种优化,因此,如果表足够大,那么这个查询就会出现不可控的情况。
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.input.format = org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
启用严格模式
将hive.strict.checks.no.partition.filter设置为true之后,对于分区表,除非where语句中含有分区字段过滤条件来限制范围,否则不允许执行。换句话说,就是用户不允许扫描所有分区。进行这个限制的原因是,通常分区表都拥有非常大的数据集,而且数据增加迅速。没有进行分区限制的查询可能会消耗令人不可接受的巨大资源来处理这个表。
将hive.strict.checks.orderby.no.limit设置为true时,对于使用了order by语句的查询,要求必须使用limit语句。因为order by为了执行排序过程会将所有的结果数据分发到同一个Reducer中进行处理,强制要求用户增加这个LIMIT语句可以防止Reducer额外执行很长一段时间。
将hive.strict.checks.cartesian.product设置为true时,会限制笛卡尔积的查询。对关系型数据库非常了解的用户可能期望在执行JOIN查询的时候不使用ON语句而是使用where语句,这样关系数据库的执行优化器就可以高效地将WHERE语句转化成那个ON语句。不幸的是,Hive并不会执行这种优化,因此,如果表足够大,那么这个查询就会出现不可控的情况。

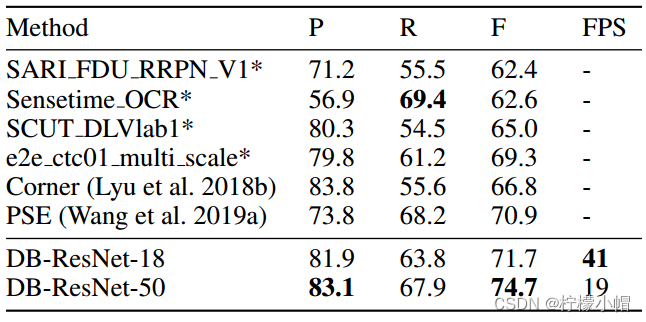





![[Java EE] 网络编程与通信原理(三):网络编程Socket套接字(TCP协议)](https://img-blog.csdnimg.cn/direct/2134483135724da79384d3108ab49a86.png)