消费者分区分配策略
- 目录
- 概述
- 需求:
- 设计思路
- 1.消费者分区分配策略
- 2. 消费者offset的存储
- 3. kafka消费者组案例
- 4. kafka高效读写&Zk作用
- 5. Ranger分区再分析
- 实现思路分析
- 参考资料和推荐阅读
Survive by day and develop by night.
talk for import biz , show your perfect code,full busy,skip hardness,make a better result,wait for change,challenge Survive.
happy for hardess to solve denpendies.
目录
概述
需求:
1.消费者分区分配策略
2. 消费者offset的存储
3. 消费者组案例
4. 高效读写&Zk作用
5. Ranger分区再分析
设计思路
1.消费者分区分配策略
消费者分区分配策略是指在一种分布式系统中,如何将消费者分配到不同的分区上,以实现负载均衡和高性能的目标。
以下是一些常见的消费者分区分配策略:
-
均匀分配:将消费者均匀地分配到不同的分区上。这种策略简单直接,适用于分区数据负载相对均衡的场景。
-
基于负载的分配:根据分区的负载情况,将消费者分配到负载较低的分区上。这种策略可以实现动态负载均衡,但需要实时监测分区的负载情况。
-
基于消费者偏好的分配:根据消费者的偏好,将其分配到对应的分区上。例如,根据消费者的兴趣领域或地理位置,将其分配到相应的分区上。
-
随机分配:随机将消费者分配到分区上。这种策略简单快速,但可能导致分区负载不均衡。
-
地理位置分配:根据消费者的地理位置,将其分配到距离最近的分区上。这种策略可以减少访问延迟,适用于地理分布广泛的系统。
-
基于消费者状态的分配:根据消费者的状态,如网络延迟、可用带宽等,将其分配到合适的分区上。这种策略可以优化系统性能,但需要实时监测消费者状态。
-
基于消费者容量的分配:根据消费者的处理能力或带宽限制,将其分配到适合的分区上。这种策略可以避免资源浪费,保证系统的稳定性。
不同的场景和需求可能适合不同的分区分配策略,可以根据实际情况选择合适的策略。
2. 消费者offset的存储
消费者offset是指消费者在一个特定分区上的消费位置,在消费者组中的每个消费者都会有一个对应的消费者offset来记录其消费的位置。消费者offset的存储通常由Kafka来管理。
Kafka提供了两种存储消费者offset的方式:内部存储和外部存储。
-
内部存储:Kafka使用一个内置的topic “__consumer_offsets” 来存储消费者offset。这个topic由Kafka自动创建和管理,可以通过配置文件指定该topic的分区数量和副本数量。
-
外部存储:除了内部存储,Kafka还支持将消费者offset存储在外部存储系统中,比如Apache ZooKeeper、MySQL、PostgreSQL等。这种方式需要使用相应的插件或者编写自定义代码来实现。
使用内部存储还是外部存储取决于具体的需求和场景。内部存储相对简单,不需要额外的配置和管理,而外部存储可以提供更多的灵活性和扩展性。
无论是内部存储还是外部存储,消费者offset的存储都是持久化的,以确保在重启或者发生故障的情况下能够恢复到之前的消费位置,避免重复消费或者丢失消息。
3. kafka消费者组案例
以下是一个简单的Kafka消费者组案例:
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;public class KafkaConsumerExample {private static final String TOPIC = "test_topic";private static final String BOOTSTRAP_SERVERS = "localhost:9092";private static final String GROUP_ID = "test_group";public static void main(String[] args) {Properties props = new Properties();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);props.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);consumer.subscribe(Arrays.asList(TOPIC));while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord<String, String> record : records) {System.out.println("Received message: key = " + record.key() + ", value = " + record.value());}}}
}
这个例子中,我们创建了一个Kafka消费者,使用了一个消费者组。首先,我们设置了Kafka集群的地址BOOTSTRAP_SERVERS、消费者组的idGROUP_ID以及key和value的反序列化类。然后,我们创建一个KafkaConsumer对象,并订阅了一个主题TOPIC。接下来,我们使用一个无限循环来轮询Kafka集群,获取新的消息记录。在每一次循环迭代中,我们遍历所有接收到的消息记录,并输出它们的key和value。
这个消费者组的特点是,当多个消费者属于同一个消费者组时,它们会协调从各个主题分区中消费消息,确保每个主题分区中的消息只被一个消费者处理。这样可以实现负载均衡和高可用性。
注意:在使用这个例子之前,确保你已经创建了一个名为test_topic的Kafka主题,并向其中发送了一些消息。
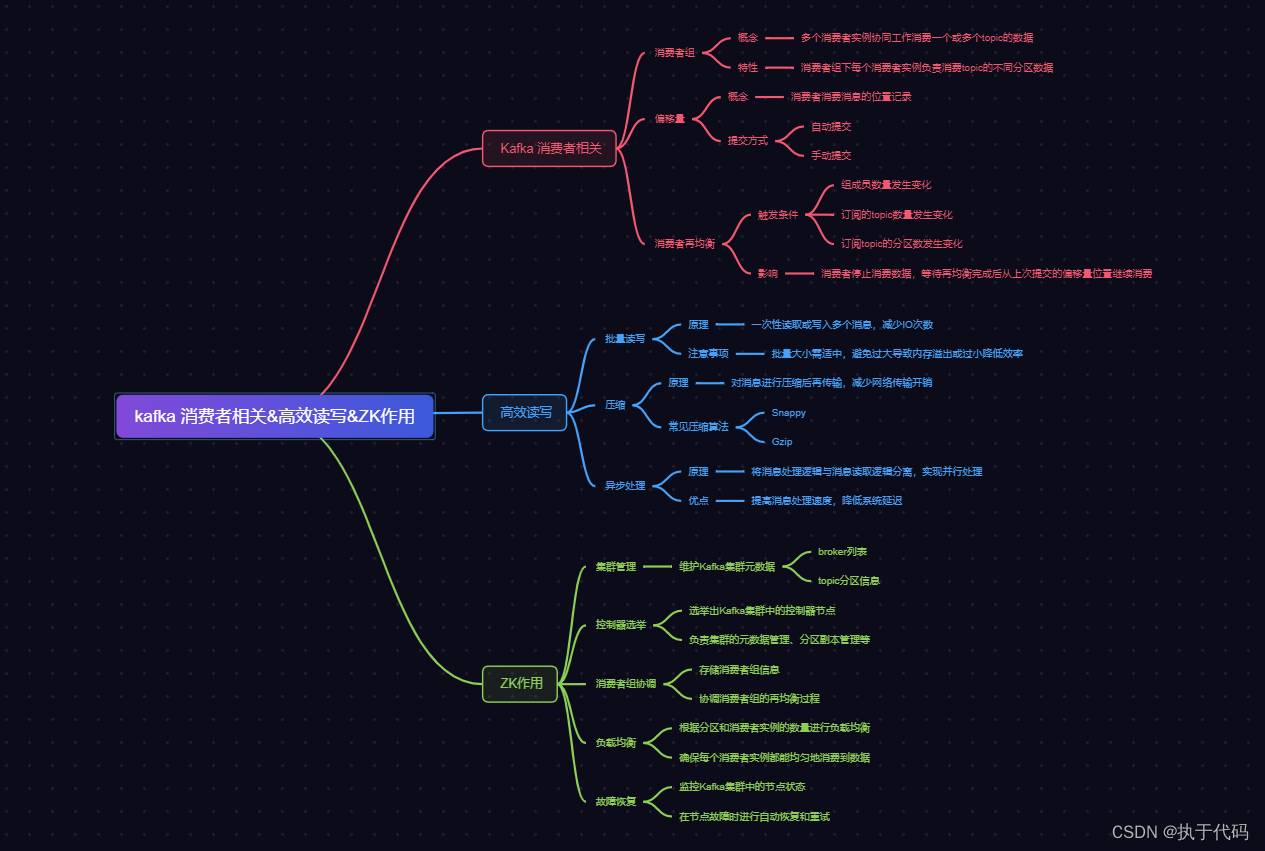
4. kafka高效读写&Zk作用
Kafka是一个分布式的消息队列系统,其设计目标是为了实现高效的读写操作。具体来说,Kafka在以下几个方面体现了高效的特点:
-
高吞吐量:Kafka通过将消息分区存储在多个broker上,并支持水平扩展来实现高吞吐量。每个分区都可以并行读写,多个分区之间可以并行处理,从而提高整体的处理能力。
-
零拷贝技术:Kafka使用零拷贝技术来减少数据在内存中的复制次数,从而提高了读写操作的效率。在读取消息时,Kafka通过将消息直接从磁盘读取到内存中,避免了数据在内存之间的拷贝。在写入消息时,Kafka将消息写入操作系统的页缓存中,再由操作系统负责将数据写入磁盘,也避免了数据在内存之间的拷贝。
-
批量处理:Kafka支持批量处理消息,即可以一次性读取或写入多条消息。这样可以减少网络传输和磁盘IO的次数,提高了读写操作的效率。
-
数据压缩:Kafka支持对消息数据进行压缩,可以减少数据的传输量,提高了读写操作的效率。Kafka支持多种压缩算法,可以根据实际需求选择合适的算法。
至于Zookeeper(简称Zk),它在Kafka中扮演着重要的角色,主要有以下几个作用:
-
配置管理:Kafka使用Zk来存储和管理集群的配置信息。包括broker的配置、主题(topic)的配置、消费者(consumer)的配置等。通过Zk,Kafka能够动态地更新和同步配置信息,从而实现集群的自动管理和配置。
-
分布式协调:Kafka使用Zk来实现分布式协调和一致性。例如,在Kafka集群中,Zk负责选举一个leader节点来处理读写请求,当leader节点失效时,Zk会进行重新选举。Zk还可以用于实现分布式锁、分布式队列等功能,帮助Kafka实现高效的分布式消息传递。
-
心跳监测:Kafka使用Zk来进行心跳监测,以检测和管理集群中的各个组件(如broker、consumer)的状态。通过Zk,Kafka可以及时地发现和处理故障,保证集群的可用性和稳定性。
总之,Kafka通过高效的读写操作和Zk的配置管理、分布式协调等作用,实现了高吞吐量和可扩展性的分布式消息队列系统。
5. Ranger分区再分析
Ranger分区再分析是指针对Ranger分区进行进一步的研究和分析。Ranger分区是一种针对多样性和平衡的分区算法,用于解决大规模数据分区的问题。其主要思想是通过将数据分成多个小的数据块,以便更高效地存储和处理数据。
Ranger分区再分析可以包括以下几个方面的内容:
-
分区质量评估:对已有的Ranger分区进行评估,看其是否能够满足实际应用中的需求。可以使用一些评估指标,比如分区的平衡性、分区的多样性等。
-
分区策略优化:针对已有的分区策略,进行进一步的优化。可以考虑使用一些启发式的算法,比如遗传算法、模拟退火算法等,来搜索更优的分区策略。
-
分区算法改进:可以提出一些新的分区算法,用于改进Ranger分区的性能和效果。可以考虑使用一些机器学习算法,比如聚类算法、分类算法等,来进行数据分区。
-
分区应用场景研究:通过对Ranger分区在不同应用场景下的应用进行研究,可以了解Ranger分区在不同领域的适用性和局限性。可以结合具体的应用需求,提出针对性的分区方案。
实现思路分析
参考资料和推荐阅读
参考资料
官方文档
开源社区
博客文章
书籍推荐
1.暂无
欢迎阅读,各位老铁,如果对你有帮助,点个赞加个关注呗!同时,期望各位大佬的批评指正~,如果有兴趣,可以加文末的交流群,大家一起进步哈
![[Java EE] 网络编程与通信原理(三):网络编程Socket套接字(TCP协议)](https://img-blog.csdnimg.cn/direct/2134483135724da79384d3108ab49a86.png)