W...Y的主页 😊
代码仓库分享💕

目录
进程创建
fork函数初识
写时拷贝
fork常规用法
fork调用失败的原因
进程终止
进程退出场景
_exit函数
exit函数
return退出
进程创建
fork函数初识
在linux中fork函数时非常重要的函数,它从已存在进程中创建一个新进程。新进程为子进程,而原进程为父进程。
#include <unistd.h>
pid_t fork(void);
返回值:自进程中返回0,父进程返回子进程id,出错返回-1
进程调用fork,当控制转移到内核中的fork代码后,内核做:
分配新的内存块和内核数据结构给子进程
将父进程部分数据结构内容拷贝至子进程
添加子进程到系统进程列表当中
fork返回,开始调度器调度
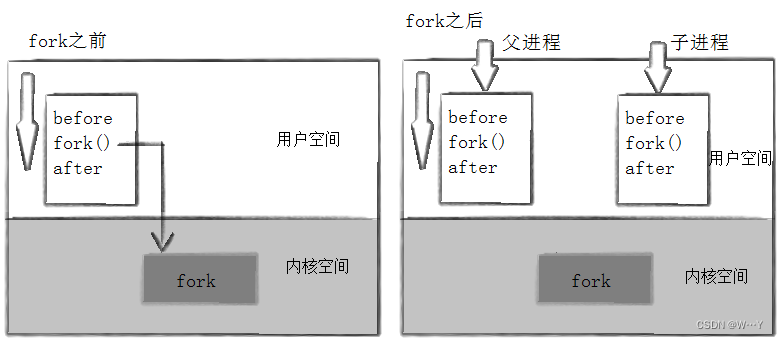 当一个进程调用fork之后,就有两个二进制代码相同的进程。而且它们都运行到相同的地方。但每个进程都将可以开始它们自己的进程,看如下程序:
当一个进程调用fork之后,就有两个二进制代码相同的进程。而且它们都运行到相同的地方。但每个进程都将可以开始它们自己的进程,看如下程序:
int main( void )
{
pid_t pid;
printf("Before: pid is %d\n", getpid());
if ( (pid=fork()) == -1 )perror("fork()"),exit(1);
printf("After:pid is %d, fork return %d\n", getpid(), pid);
sleep(1);
return 0;
}
运行结果:
[root@localhost linux]# ./a.out
Before: pid is 43676
After:pid is 43676, fork return 43677
After:pid is 43677, fork return 0这里看到了三行输出,一行before,两行after。进程43676先打印before消息,然后它有打印after。另一个after消息有43677打印的。注意到进程43677没有打印before,为什么呢?如下图所示

所以,fork之前父进程独立执行,fork之后,父子两个执行流分别执行。注意,fork之后,谁先执行完全由调度器决定。
子进程返回0,
父进程返回的是子进程的pid。
上面的fork函数我在前面的博客中已经提到过了,在这里就算一个复习。
写时拷贝
通常,父子代码共享,父子再不写入时,数据也是共享的,当任意一方试图写入,便以写时拷贝的方式各自一份副本。这不得不提到虚拟地址和物理地址映射关系了。
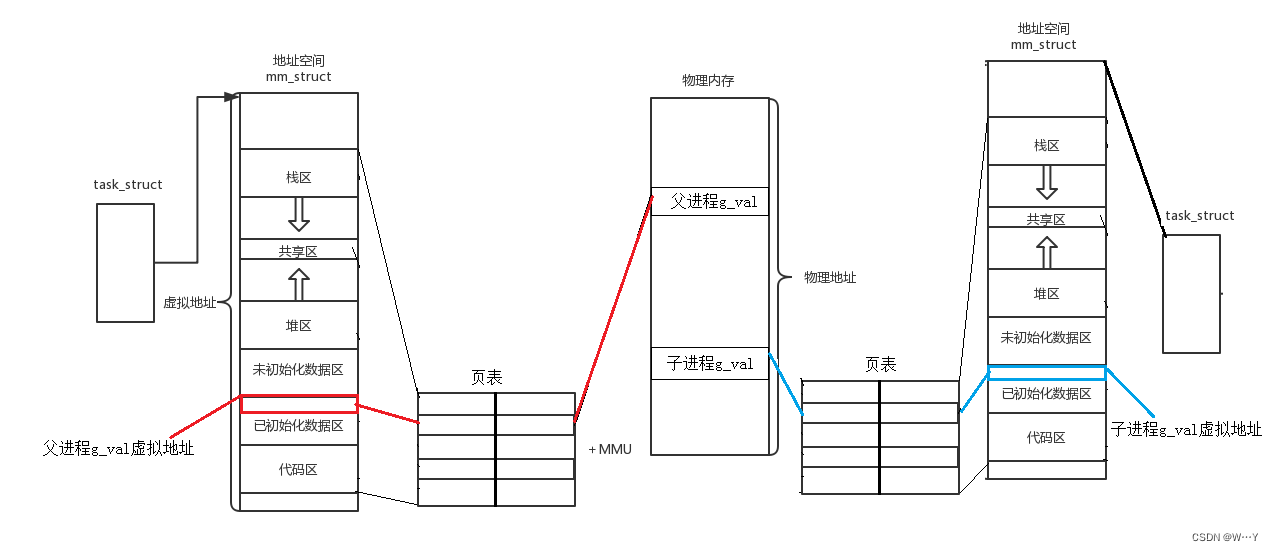
当父进程中创建一个子进程时,子进程会拷贝父进程的代码与数据,然后由页表进行映射,映射的位置是相同的。当我们修改子进程中的数据时,操作系统会在物理内存中写时拷贝出一个新空间并重新建立页表映射。

为什么要写时拷贝呢?因为我们说过物理内存是有限的,当数据存入物理内存时,操作系统并不知道你是否要对数据进行修改,所以为了提高利用率,父子进程就会指向同一个物理空间。并且可以提高fork函数的效率。
写时拷贝?为什么要拷贝呢?直接开辟一块一样大的空间不就好了!!!因为我们对数据无非就是增删查改,不一定对数据有大的改动,所以当我们对数据进行操作时,我们进行拷贝后就可以知道这个数据,方便我们进行操作。
如何做到写时拷贝呢?

我们看到上面这张图,这是一个父子进程的页表,里面存着虚拟内存与物理内存的映射。但是我们发现数据与代码的权限都是只读,代码不可修改我们可以理解,为什么数据我们也不能修改呢?
不是不能修改,而是操作系统故意为之。当我们修改数据时,但是数据的权限为只读。这时就会发现缺页中断,操作系统就会出现进行判断发现时数据进行操作,这个操作是正常的,然后操作系统就会触发写时拷贝!!!
fork常规用法
一个父进程希望复制自己,使父子进程同时执行不同的代码段。例如,父进程等待客户端请求,生成子进程来处理请求。
一个进程要执行一个不同的程序。例如子进程从fork返回后,调用exec函数。
fork调用失败的原因
系统中有太多的进程
实际用户的进程数超过了限制
进程终止
当我们在写程序时,好像固定在程序结尾要写一个return 0,为什么不能是return 1 或其他数字呢?main函数的返回值我们叫做退出码,一般0表示进程执行成功,非零表示失败。非零的数字都代表失败的退出的原因。
可以通过 echo $? 查看最近一次进程的退出码,当我们连续进行echo $? 前面是什么都无所谓后面都会变成0,因为当第二次使用echo $? 最近的进程就是其本身。
![]()
用户并不知道退出码的具体含义,所以要把错误码转换成错误描述,或者自定义进行。
怎么转换呢:
 我们可以使用程序查看一下:
我们可以使用程序查看一下:
1 #include<stdio.h>2 #include<stdlib.h>3 #include<unistd.h>4 #include<string.h>5 int main()6 {7 for(int i = 0; i < 200; i++) 8 {9 printf("%d: %s\n",i,strerror(i));10 11 }12 return 0;13 }


我们可以看出来系统给出的错误码有133个,我只截取了首尾,其余自行查看。
我们也可以自己进行枚举:
enum {success=0,open_err,malloc_err};const char* errorToDesc(int code){switch(code){case success:return "success";case open_err:return "file open error";case malloc_err:return "malloc error";default:return "unknown error";}但是我们函数也是有返回值的,当我们在函数后写一个return 0,返回后主函数也是会执行的。函数退出我们怎么知道函数的执行情况呢?函数程序被我们称为子程序,主程序有退出码作为退出反馈,函数也有退出码。
进程退出场景
代码运行完毕,结果正确
代码运行完毕,结果不正确
代码异常终止
代码没有执行完,进程出异常是进程收到了异常信号!!!异常信号我们Linux中也有具体实例:

我们使用kill -l可以查看各种异常信号,每个信号有不同的信号编号,不同的信号编号表明异常原因。
所以任何进程最终执行的情况我们可以使用两个数字表明具体的执行情况:
| signumber | exit_code | 情况 |
| 0 | 0 | 正常退出 |
| !0 | 0 | 退出码无意义 |
| 0 | !0 | 代码跑完,结果不正确 |
| !0 | !0 | 退出码无意义 |
_exit函数

这个函数是系统调用接口,因为他存在man(2)中。_exit与exit的调用方式一模一样。
exit函数
这个函数不是程序退出,而是进程终止。status是进程退出时的退出码。在我们代码的任何位置使用exit函数都表示进程退出。
那exit与_exit有什么区别呢?
int main()
{
printf("hello");
exit(0);
}
运行结果:
[root@localhost linux]# ./a.out
hello[root@localhost linux]#
int main()
{
printf("hello");
_exit(0);
}
运行结果:
[root@localhost linux]# ./a.out
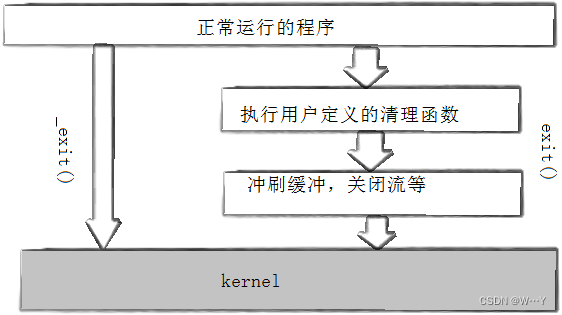
[root@localhost linux]#exit函数会支持刷新缓冲区,反之_exit不会刷新缓冲区。其实就是_exit是操作系统为用户提供的系统调用接口,而exit是C语言将_exit进行封装的,为了更好的跨平台性!!!
return退出
eturn是一种更常见的退出进程方法。执行return n等同于执行exit(n),因为调用main的运行时函数会将main的返回值当做 exit的参数。
以上就是本次的全部内容,感谢大家观看!!!