一、概念
MapReduce是一个 分布式运算程序 的编程框架,是用户开发“基于 Hadoop的数据分析
应用”的核心框架。
MapReduce核心功能是将 用户编写的业务逻辑代码 和 自带默认组件 整合成一个完整的
分布式运算程序 ,并发运行在一个 Hadoop集群上。
1、MapReduce是集群上的并行计算框架
2、平时开发中只需要基于MapReduce接口,编写业务逻辑代码即可。
二、优缺点
优点
1、易于编程
2、良好的扩展性
3、高容错性
4、适合PB级以上海量数据的离线处理
缺点
1、不擅长实时计算
Spark Streaming
2、不擅长流式计算
Spark Streaming、Flink
3、不擅长DAG(有向无环图)计算
Spark
三、算法思想
学过Java8的都知道MapReduce框架。
它是一款并发任务框架。
但是开发难度较大
在Hadoop中的MapReduce框架算法思想是一样的。
分两个阶段
第一阶段,任务分发阶段(Map阶段),并行计算数据,所有数据是互不相干。所有计算任务也是互不相干的。
第二阶段,结果汇总阶段(Reduce阶段),并行统计Map计算出的结果,汇总出最终结果,返回给用户。
如果,我们拿到的一批数据,并非是等价的,可能之间存在数据依赖,那么,我们就需要写多个MapReduce任务,分别计算各个层级的数据。
所以,开发MapReduce,首先要分析数据的依赖关系,然后,编写分多个MapReduce进行计算即可。
四、WordCount案例源码阅读
1、WordCount源码
package org.apache.hadoop.examples;import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;public class WordCount
{public static class TokenizerMapperextends Mapper<Object, Text, Text, IntWritable>{private static final IntWritable one = new IntWritable(1);private Text word = new Text();public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {StringTokenizer itr = new StringTokenizer(value.toString());while (itr.hasMoreTokens()) {this.word.set(itr.nextToken());context.write(this.word, one);}}}public static class IntSumReducerextends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}this.result.set(sum);context.write(key, this.result);}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();if (otherArgs.length < 2) {System.err.println("Usage: wordcount <in> [<in>...] <out>");System.exit(2);}Job job = Job.getInstance(conf, "word count");job.setJarByClass(WordCount.class);job.setMapperClass(TokenizerMapper.class);job.setCombinerClass(IntSumReducer.class);job.setReducerClass(IntSumReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);for (int i = 0; i < otherArgs.length - 1; i++) {FileInputFormat.addInputPath(job, new Path(otherArgs[i]));}FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));System.exit(job.waitForCompletion(true) ? 0 : 1);}
}
2、源码结构分析
主要三部分
1、程序入口,main函数
主要关注7个job配置
2、Mapper内部类
主要关注四个泛型配置
3、Reducer内部类
主要关注四个泛型配置
3、数据类型对应关系
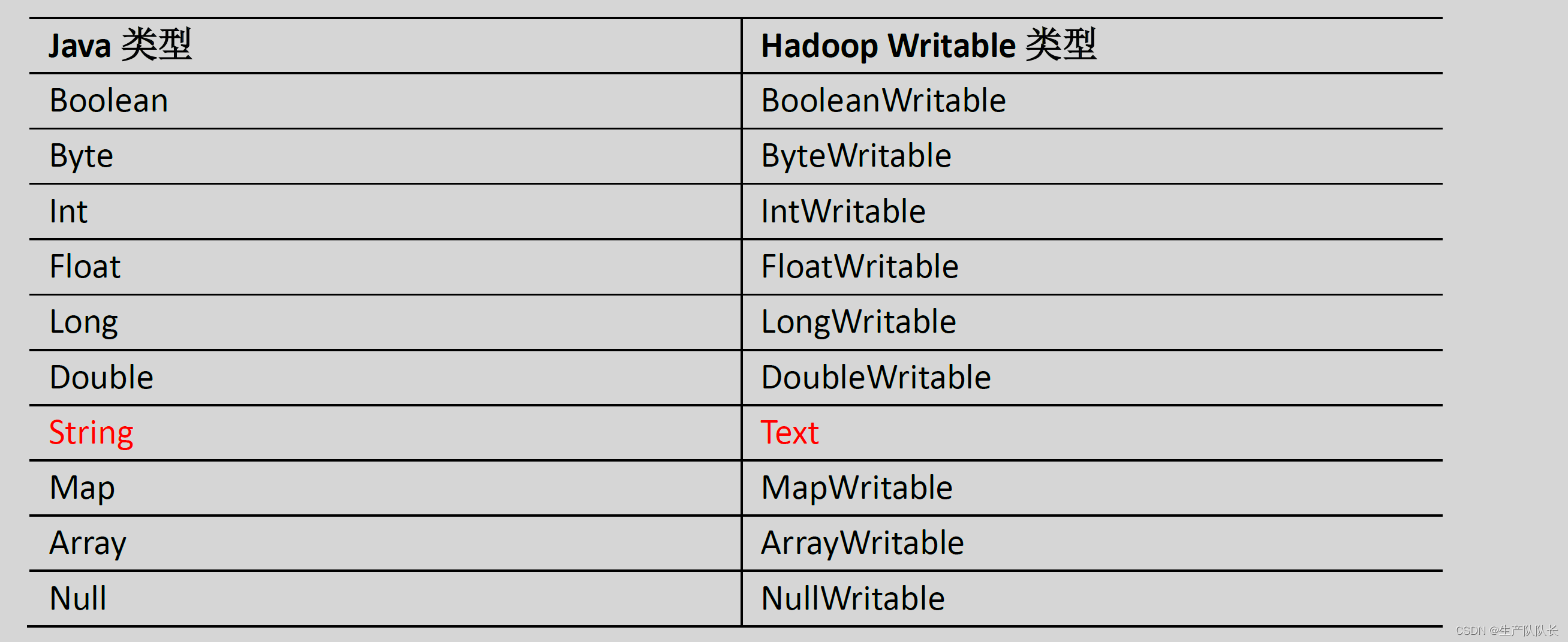
五、自定义开发WordCount
1、案例需求分析
从图中,我们需要注意的是:
Mapper阶段,数据结构的变化过程,最终输出的数据结构
Reducer阶段,收到的数据结构和输出的数据结构

2、Mapper类实现
package com.atguigu.mapreduce.wordcount;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/*** KEYIN, map阶段输入的key的类型:LongWritable,偏移量,可以理解为txt文本内容中,字符的下标。下标按行累加* VALUEIN,map阶段输入value类型:Text* KEYOUT,map阶段输出的Key类型:Text* VALUEOUT,map阶段输出的value类型:IntWritable*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {private Text outK = new Text();private IntWritable outV = new IntWritable(1);@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//可以看出,这个案例中,key偏移量没有起作用// 1 获取一行// atguigu atguiguString line = value.toString();// 2 切割// atguigu// atguiguString[] words = line.split(" ");// 3 循环写出for (String word : words) {// 封装outkoutK.set(word);// 写出context.write(outK, outV);}}
}
3、Reducer类实现
package com.atguigu.mapreduce.wordcount;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/*** KEYIN, reduce阶段输入的key的类型:Text* VALUEIN,reduce阶段输入value类型:IntWritable* KEYOUT,reduce阶段输出的Key类型:Text* VALUEOUT,reduce阶段输出的value类型:IntWritable*/
public class WordCountReducer extends Reducer<Text, IntWritable,Text,IntWritable> {private IntWritable outV = new IntWritable();@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int sum = 0;// atguigu, (1,1)// 累加for (IntWritable value : values) {sum += value.get();}outV.set(sum);// 写出context.write(key,outV);}
}
4、WordCountDriver类实现
这里需要注意的是,这里的4和5两步骤。
4步骤,确定Mapper的输入类型,Mapper的输出类型要和Reducer的输入类型一致。
5步骤,确定Reducer的输出类型。
package com.atguigu.mapreduce.wordcount;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class WordCountDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {// 1 获取jobConfiguration conf = new Configuration();Job job = Job.getInstance(conf);// 2 设置jar包路径job.setJarByClass(WordCountDriver.class);// 3 关联mapper和reducerjob.setMapperClass(WordCountMapper.class);job.setReducerClass(WordCountReducer.class);// 4 设置map输出的kv类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);// 5 设置最终输出的kV类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);// 6 设置输入路径和输出路径
// FileInputFormat.setInputPaths(job, new Path("E:\\workspace\\data\\input\\inputword"));
// FileOutputFormat.setOutputPath(job, new Path("E:\\workspace\\data\\ouputword"));FileInputFormat.setInputPaths(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));// 7 提交jobboolean result = job.waitForCompletion(true);System.exit(result ? 0 : 1);}
}
六、运行验证
1、本地运行
直接IDEA中,运行main函数即可

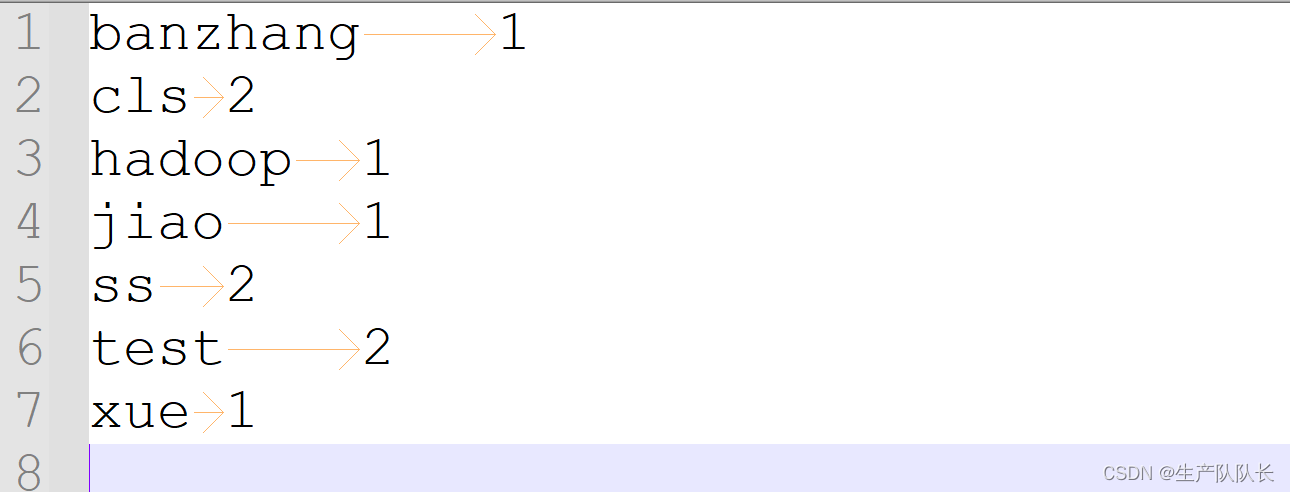
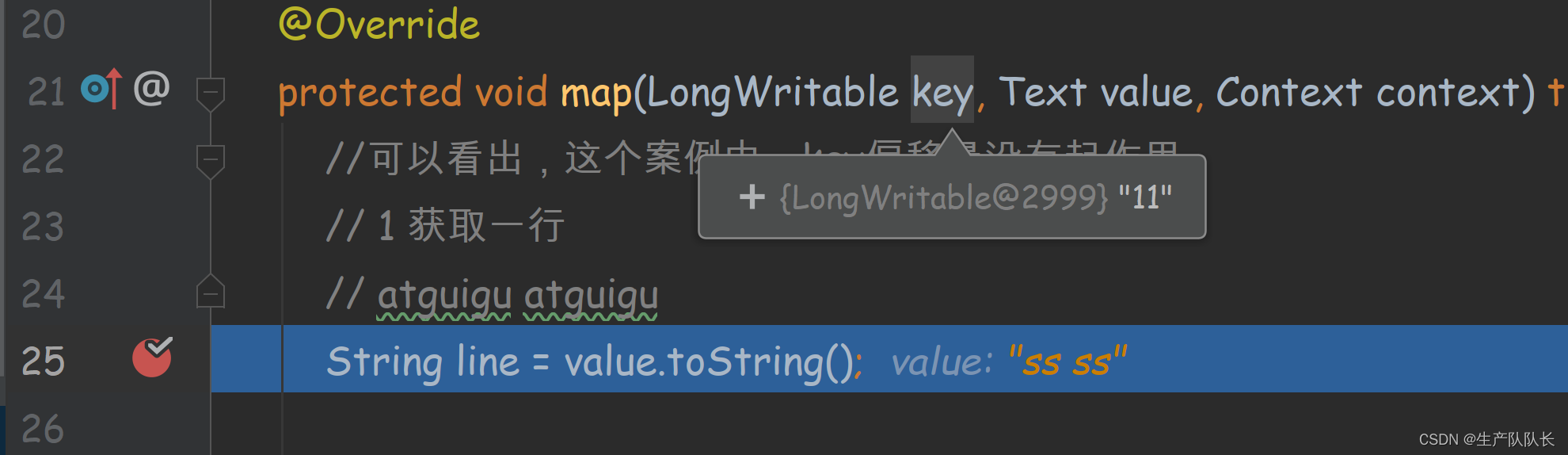
debug查看偏移量
可以发现,第二行的偏移量是11,因为,第一行2个test,一个空格,一个换行刚好10个
第二行的s就是11开始
可能出现的错误
java.lang.ClassNotFoundException: Class org.apache.hadoop.hdfs.DistributedFileSystem
我的完整pom
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.atguigu</groupId><artifactId>MapReduceDemo</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target></properties><dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.3</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-app</artifactId><version>3.1.3</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-yarn-server-resourcemanager</artifactId><version>3.1.3</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.30</version></dependency></dependencies><build><plugins><plugin><artifactId>maven-compiler-plugin</artifactId><version>3.6.1</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin><plugin><artifactId>maven-assembly-plugin</artifactId><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build>
</project>
2、集群中运行
集群中运行,我们需要将代码制成jar包
然后,上传到器群中,运行即可。
1、生成jar包
打jar包有两种情况
1、不将相关依赖包生成到jar包中
这个情况比较常用,因为,集群上都有相关环境,所以,这样可以节省jar大小,从而上传快。
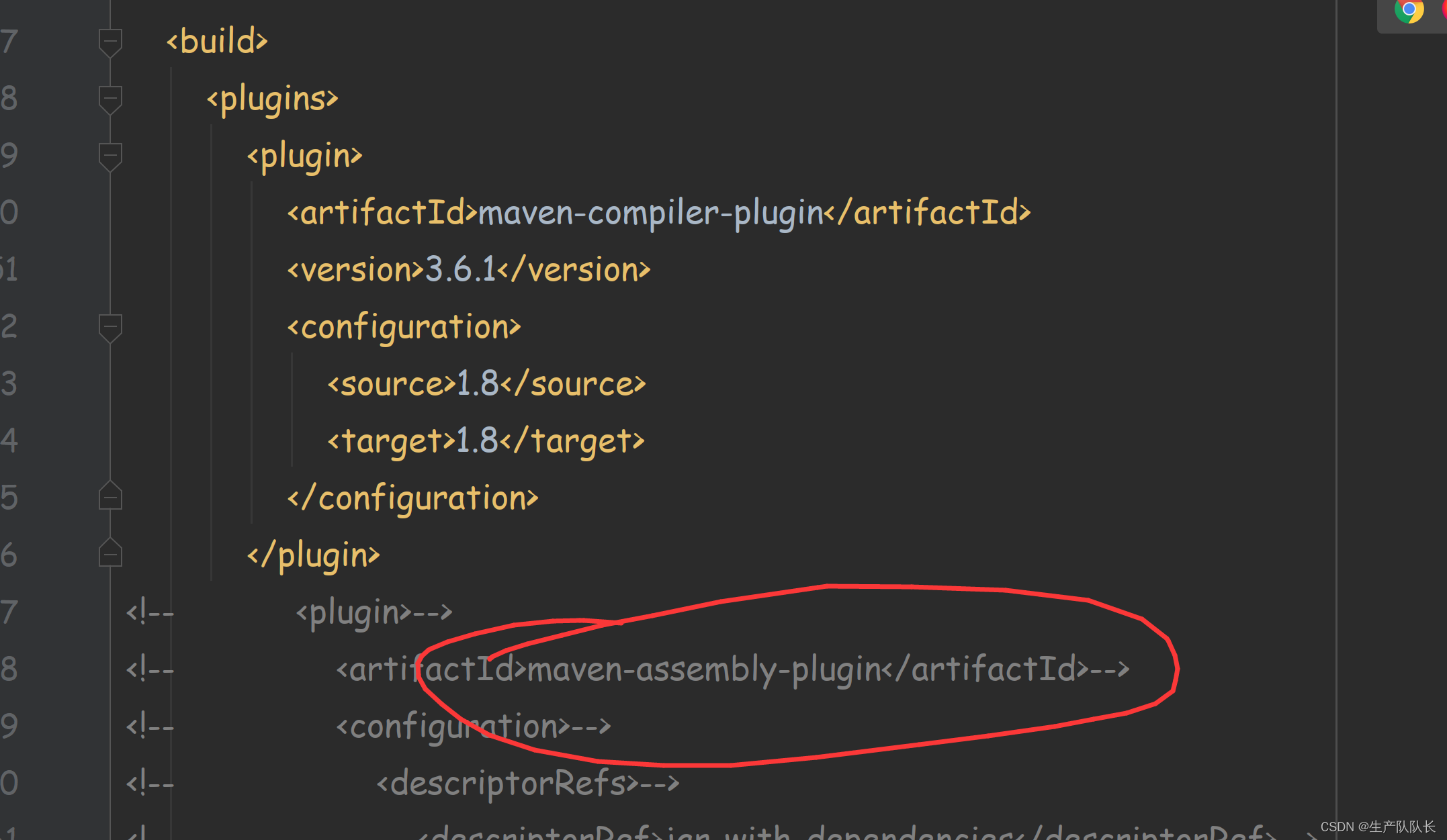
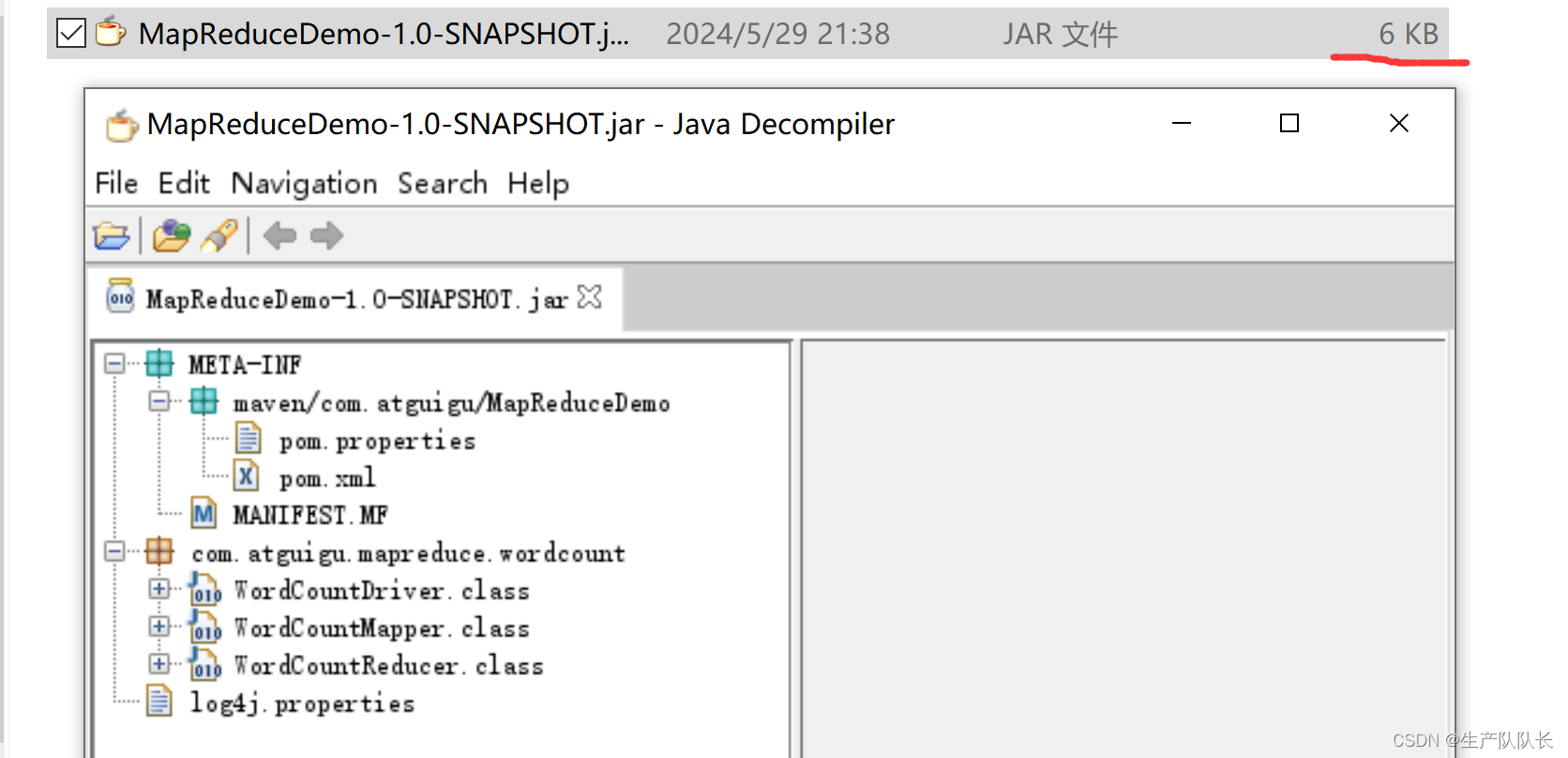
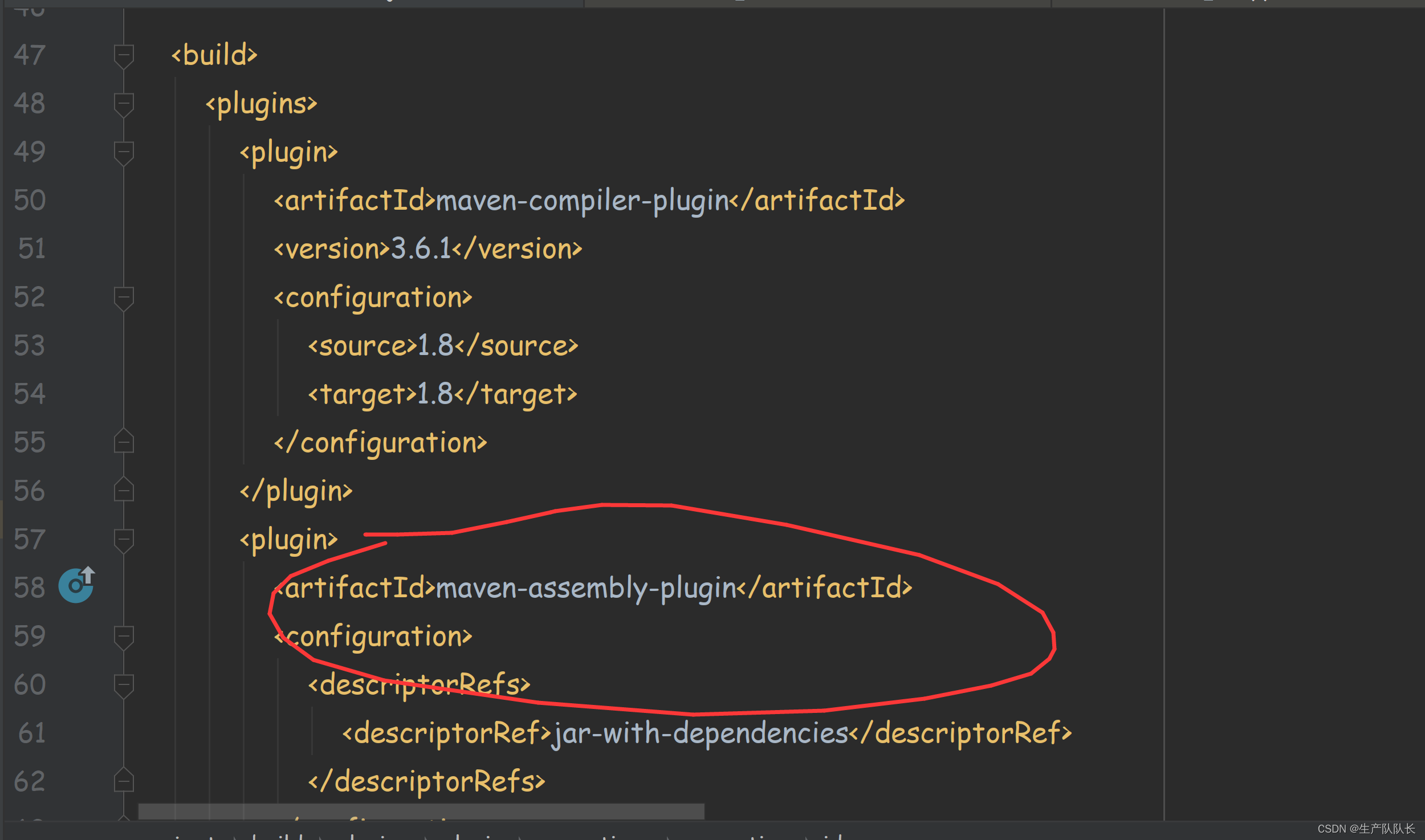
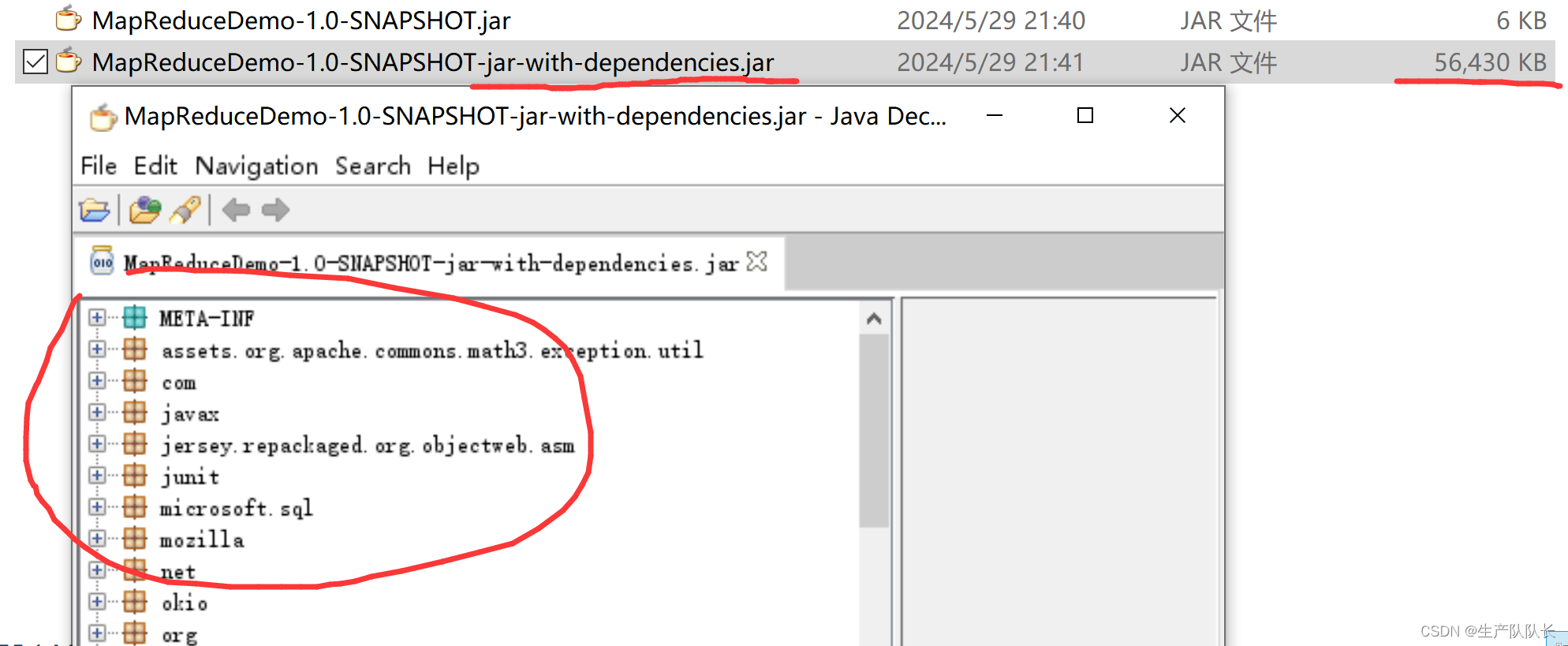
2、将相关依赖包生成到jar包中
这种,比较少用。
2、器群中测试jar包
Driver类修改如下

上传jar包
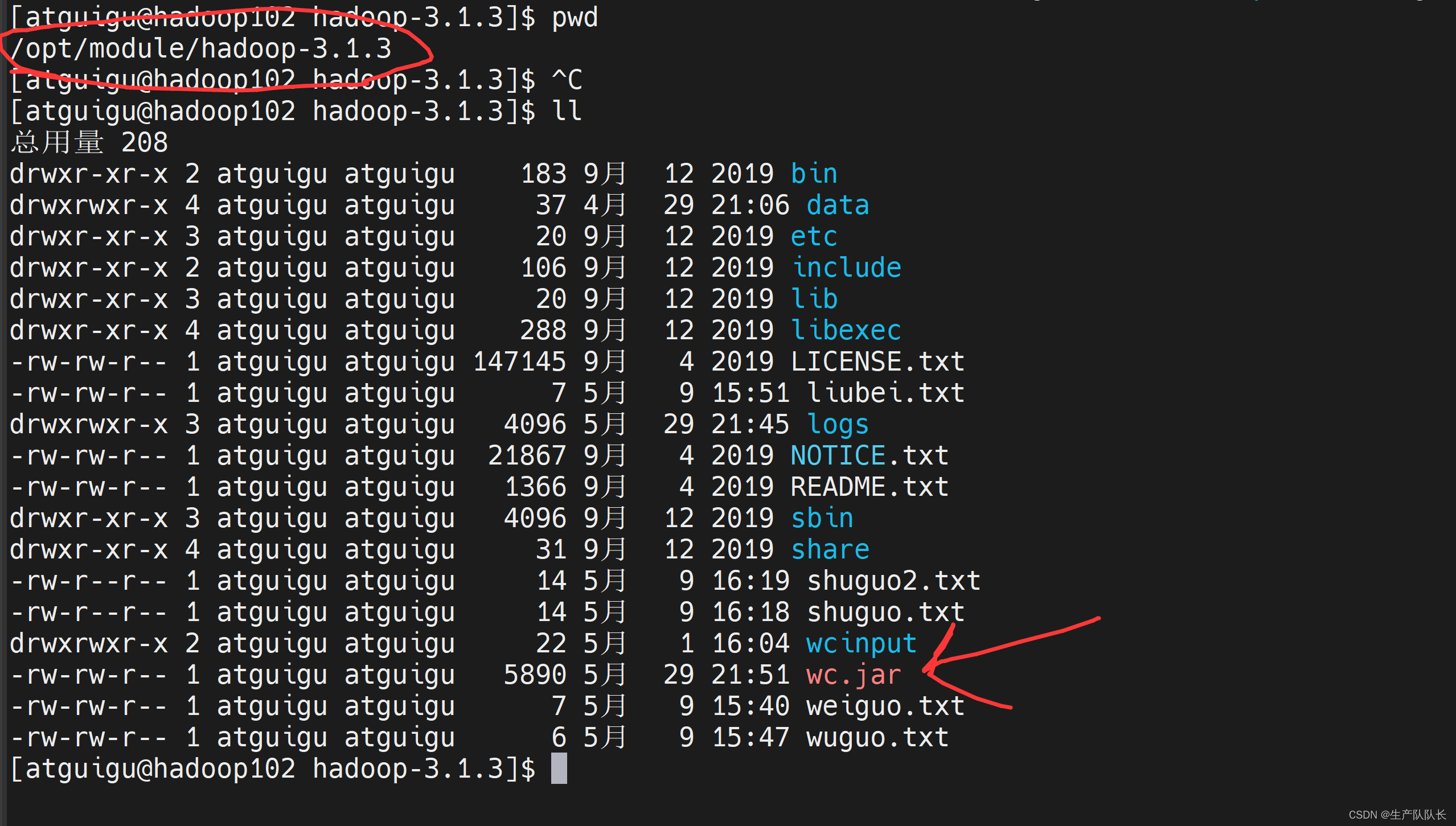
在集群中找可用文件
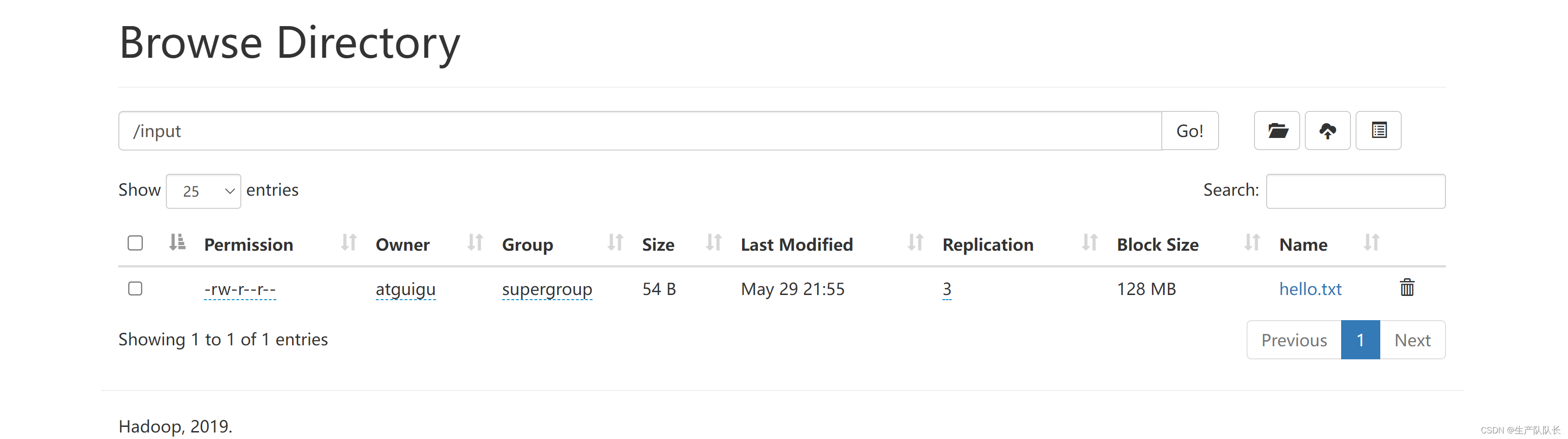
执行wc.jar任务
hadoop jar wc.jar com.atguigu.mapreduce.wordcount.WordCountDriver /input/hello.txt /output
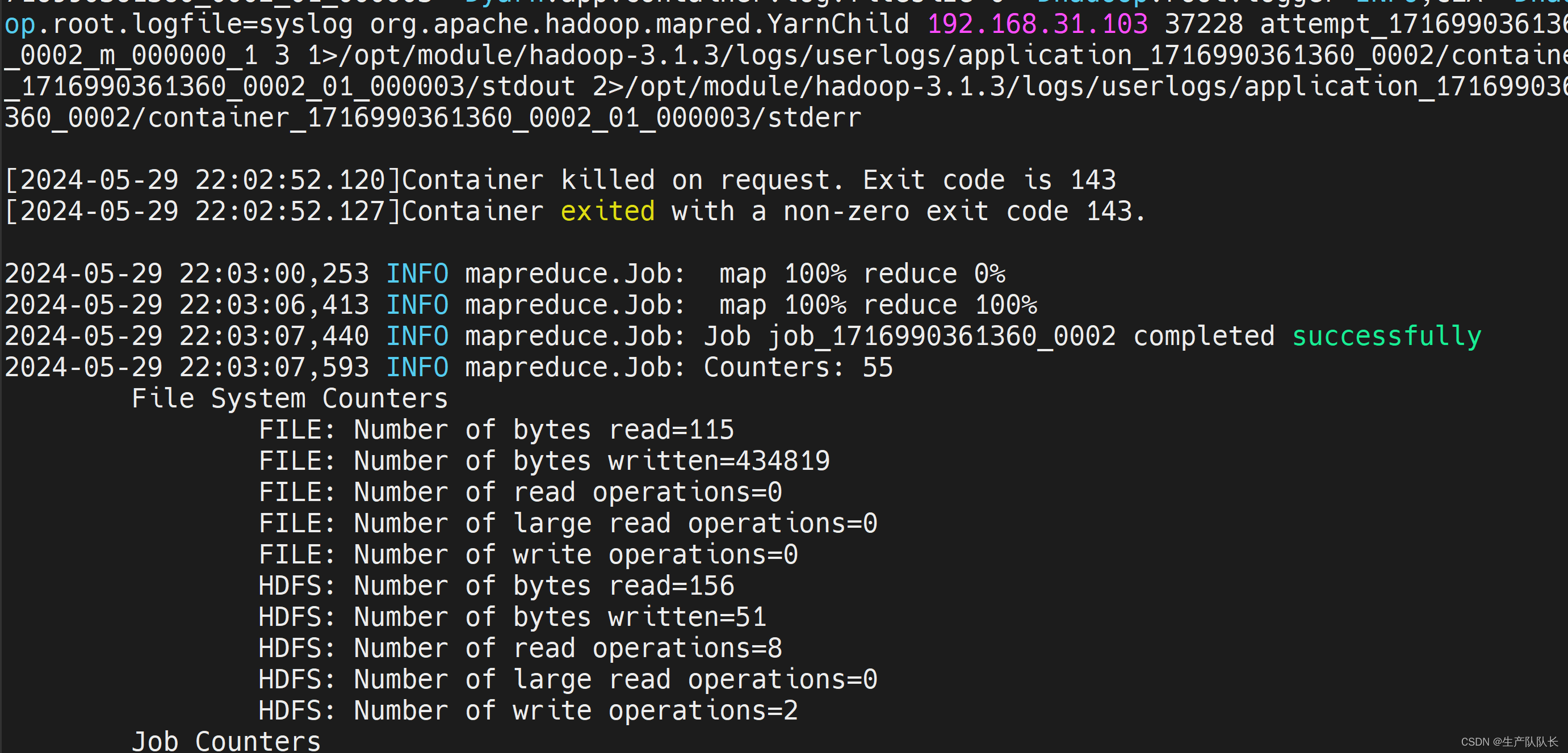
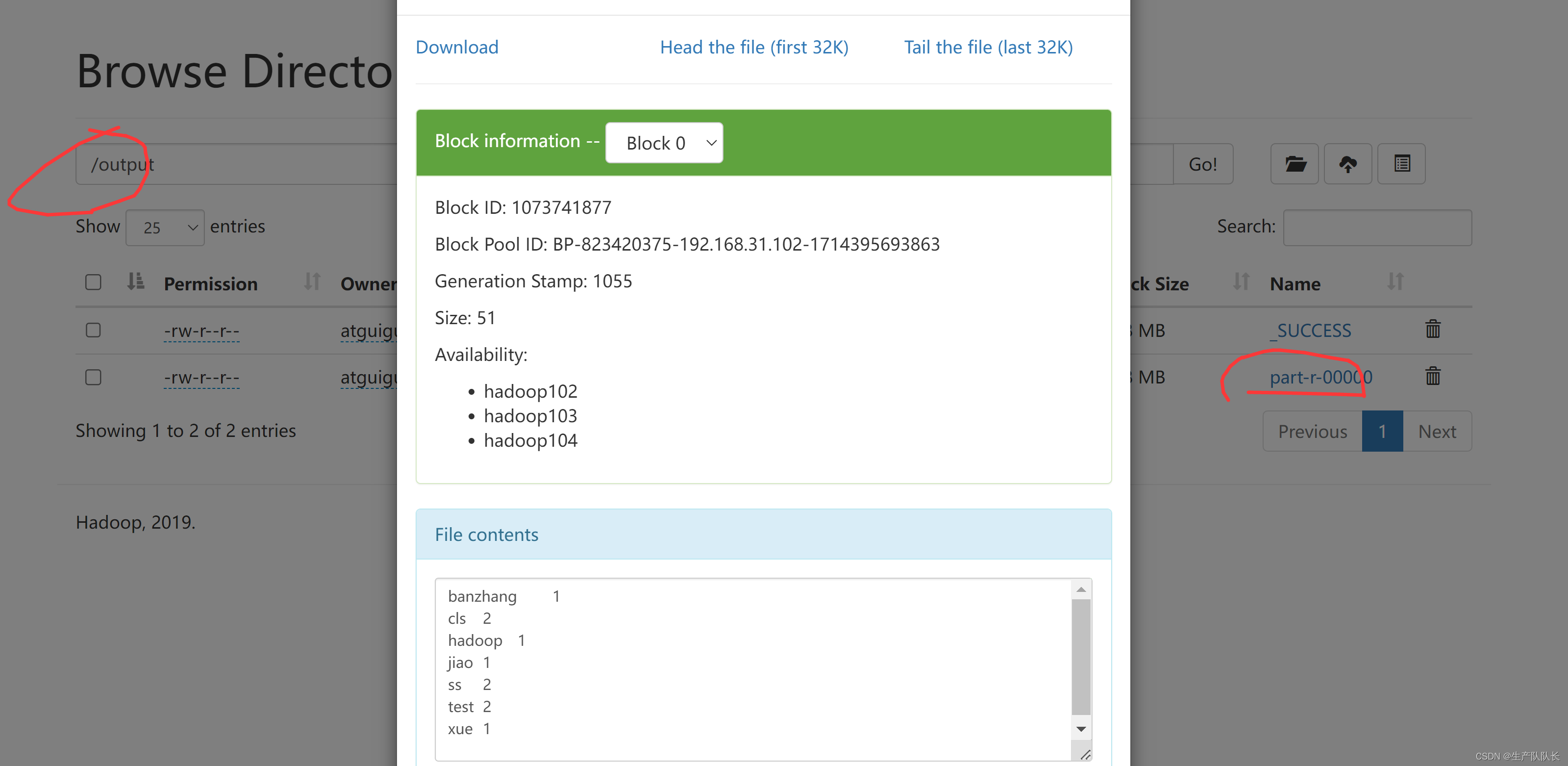
在企业中,差不多也是这样
本地搭建Hadoop的开发环境
分析数据的依赖关系,然后,编写MapReduce业务代码
上传集群,执行