©PaperWeekly 原创 · 作者 | 邵镇炜
单位 | 杭州电子科技大学
研究方向 | 跨模态学习
大规模语言模型(Large Language Model,LLM)无疑是时下最火热的 AI 概念,它不仅是人工智能领域近两年的研究热点,也在近期引发了全社会的广泛关注和讨论,OpenAI 的 GPT-3 和 ChatGPT 更是数次登上微博热搜。
LLM 强大的语言理解能力和知识储备,给大众留下了深刻的印象。LLM 所涌现的 in-context learning 能力,更是开启了新的 NLP 范式,并使其有望成为以自然语言进行交互的通用型任务助手(ChatGPT)。LLM 的出现也为跨模态深度学习领域的研究者们带来新的机遇和挑战。
通过收集自互联网的大规模语料进行预训练,GPT-3 等 LLM 蕴含了丰富的世界知识,这使其有希望解决知识驱动的多模态任务,例如基于外部知识的图像问答任务,OK-VQA [1]。但是,想要利用 LLM 的潜力解决多模态问题,有一个关键问题需要解决:LLM 以语言进行输入输出,如何使她能够理解其他模态的数据,如图片,并迁移到下游多模态任务呢?
PICa [2] 提出使用 Image Caption 模型将图片转化为文本描述,然后输入给 GPT-3 使其回答关于图片的问题,该方法在 OK-VQA 数据集上超越了传统方法。但是由于 caption 未必能覆盖图片的全部信息,因此这一方法存在性能瓶颈。另一个容易想到的解决方案是,在预训练的 LLM 基础上,增加用来对接另一个模态输入的网络参数,并通过微调来得到一个跨模态的大模型。
Deepmind 的 Flamingo [3] 模型采用了这一方案,训练了一个 800 万参数量的视觉-语言模型,并在 OK-VQA 上达到新的 SOTA。但是训练这样的模型往往需要消耗大量的计算资源,动辄上百上千块 GPU,这是学术界的大部分研究者难以负担的。那么,如何能够既享受到 LLM 的强大能力,又通过有限的计算资源在跨模态任务上达到先进的性能呢?
我们近期的论文给出了一个新的答案:用好小模型!论文 Prompting Large Language Models with Answer Heuristics for Knowledge-based Visual Question Answering 提出了名为 Prophet 的框架,通过在 LLM 上游引入一个可学习的、任务相关的视觉问答小模型,来更好地激发大模型的潜力。
Prophet 这个名字既是 Prompt with answer heuristics 的缩写,也契合了 Prophet 框架的精神,我们希望 GPT-3 如一个先知一般对预兆(来自小模型的答案启发)进行理解和阐释。Prophet 仅需要 1 块 3090 显卡和少量 OpenAI API 的调用,就可以实现超越 Flamingo 的性能,并在两个基于外部知识的视觉问答数据集 OK-VQA [1] 和 A-OKVQA [4] 上创造了新的 SOTA。该论文现已被 CVPR 2023 录用。

论文链接:
https://arxiv.org/abs/2303.01903
开源代码:
https://github.com/MILVLG/prophet

方法介绍
该论文着眼于基于外部知识的图像问答任务(Knowledge-based VQA),它要求模型不仅能够分析图片和问题,还需要结合图像外部的知识(生活常识、科学知识等世界知识)来推理得到答案。例如,如果问一张狮子图片“这种动物最喜欢吃什么?”,那么模型就需要知道狮子是食肉动物,它们通常捕食羚羊、斑马等。
早期的研究使用显式的知识库来检索相关知识,但这样做往往会引入过多的噪声,影响模型的训练和最终性能。近期的工作,如 PICa [2],则尝试使用 GPT-3 作为隐式的知识引擎来获取所需知识。PICa 通过将图像转化为文本描述(Image Caption)来让 GPT-3 理解图像,并使用 few-shot in-context learning 的范式,即提供少量问答示例,使 GPT-3 理解视觉问答任务并作出回答。
尽管 PICa 取得了令人鼓舞的结果,但我们认为它没有充分激发 GPT-3 的潜能,因为它输入 GPT-3 的关于图片的信息往往不够充分。如下图所示,当我们问“what fruit comes from these trees?”,由于 caption 只提到了图片的主要内容“a group of people walk in a city square”而忽略了图中有一颗椰子树的细节,GPT-3 未能得到回答问题所需要的关键信息,于是只能“瞎猜”一个答案。
后续的工作 KAT [5] 和 REVIVE [6] 在 PICa 输出基础上,增加了一个基于显式知识检索的 VQA 模型,进一步提高了性能,但依然没有解决上述问题,未能充分挖掘出 GPT-3 的潜力。
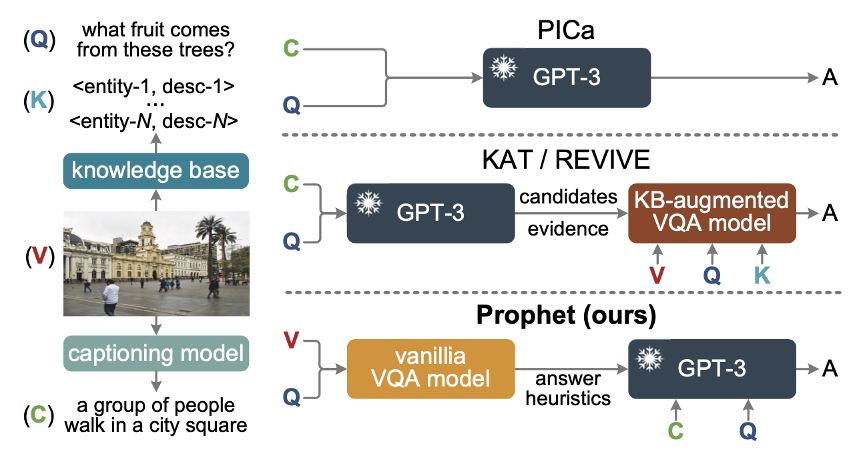
▲ Prophet框架与之前的基于GPT-3的方法的对比
为解决 PICa 的瓶颈问题,我们提出了 Prophet,它利用答案启发(answer heuristics)来帮助 GPT-3 更好的解决基于外部知识的 VQA 任务。所谓答案启发,是指写入 prompt 文本中的,和视觉问题的正确答案相似或相关的答案(当然也包括正确答案本身),我们相信这些具有潜力的答案可以提供丰富的、并且任务相关的视觉信息,可以有效帮助 GPT-3 理解图像和视觉问答任务。
具体的,论文定义了两种答案启发: 1)答案候选(answer candidates): 问题的候选答案及其置信度;2)答案感知示例(answer-aware examples): 选择答案相近的标注样本(来自训练集)作为 prompt 中的例子。有趣的是,这两种答案启发可以使用同一个简单的 VQA 模型同时产生。
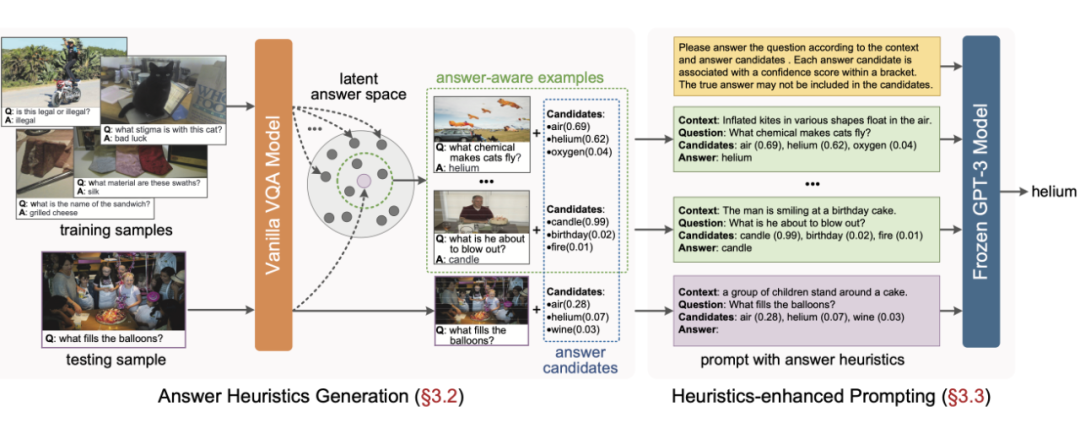
▲ Prophet的总体框架图
Prophet 的完整流程分为两个阶段,如上图所示。在第一阶段,我们首先针对特定的外部知识 VQA 数据集训练一个普通的 VQA 模型(在具体实现中,我们采用了一个改进的 MCAN [7] 模型),注意该模型不使用任何外部知识,但是在这个数据集的测试集上已经可以达到一个较弱的性能。然后我们从模型中提取两种答案启发:答案候选和答案感知示例。
具体的,我们以模型分类层输出的置信度(模型输出的 sigmoid 值)为依据对答案进行排序,抽取其中的 top 10 作为答案候选,并记录每个答案的置信度分数;同时,我们将模型分类层之前的特征作为样本的潜在答案特征(latent answer feature),在它表示的潜在特征空间中搜索最相近的标注样本作为答案感知示例。
在第二阶段,我们拓展了 PICa 的 prompt 格式,将答案启发组织到 prompt 之中(如上图所示的 prompt 例子),然后将 prompt 输入给 GPT-3,提示其完成视觉问题的回答。
值得一提的是,虽然我们给出了答案候选,但是我们并未要求 GPT-3 必须从中选择答案,一方面,prompt 中给出的示例可能就包含了正确答案不包含在答案候选中的情况,另一方面,如果所有候选的置信度都很低,也会暗示 GPT-3 生成一个全新的答案。这一设计不仅给予了 GPT-3 更多的自由,并且使 GPT-3 对前置 VQA 模型所可能引入的负面效应更加鲁棒,即 GPT-3 有权不相信 VQA 模型的不合理“猜测”。

实验分析
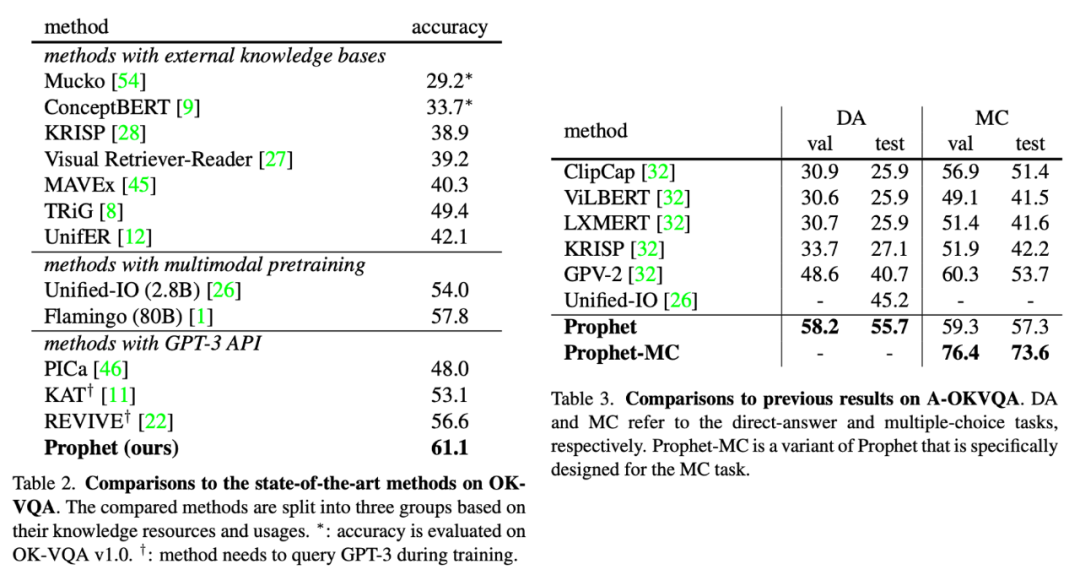
▲ Prophet论文主要实验结果
上方两表展示了 Prophet 在两个基于外部知识的图像问答数据集 OK-VQA 和 A-OKVQA 上的实验结果,及其和以往方法的性能对比。实验表明,Prophet 达到了先进的性能,显著超越了以往的方法。在 OK-VQA 数据集上,Prophet 达到了 61.1% 的准确率,大幅超越了 Deepmind 的 80B 大模型 Flamingo。
值得一提的是,Prophet 不仅在分数上超越了 Flamingo,在所需的(线下)计算资源上也更为“亲民”,更容易在有限的计算资源下进行复现。Flamingo-80B 需要在 1,536 块 TPUv4 显卡上训练 15 天,而 Prophet 只需要一块 RTX-3090 显卡训练 VQA 模型 4 天,再调用一定次数的 OpenAI API 即可。
在 A-OKVQA 上,Prophet 也达到了新的 SOTA,在测试集上取得 55.7% 的准确率。不仅如此,我们还为 A-OKVQA 的多选项测评模式设计了一个专门的变体(详见论文),命名为 Prophet-MC,该变体的 MC 准确率达到了 73.6% 的优秀水平。

▲ 对答案候选和答案感知示例的消融实验
论文对 Prophet 方法进行了充分、细致的消融实验,上方两表展示了其中最重要的两个结果。在左表中我们尝试调节答案候选的数量,可以观察到该参数显著影响方法的最终性能,说明答案候选在 Prophet 方法中起着至关重要的作用。在右表中,我们尝试了其他策略来选择 prompt 中的示例,其中的 fused 一行即对应了我们基于潜在答案特征来搜索答案感知示例的方式,实验结果表明该方式是最优的。
更详尽的实现细节和实验分析请参考论文原文。

后记
Prophet 具有诸多优势,方法思路简单,性能优越,在实现上也更为简单、经济,因此我们决定分享我们的工作。在该工作完成后不久,跨模态大模型 PaLI [8] 和 PaLM-E [9] 相继提出,他们在 OK-VQA 数据集上超越了 Prophet,但是我们相信 Prophet 依然有其独特的价值:
1. 实现 Prophet 所需的计算资源更小,是大部分学术界的研究者能够承担的,我们相信 Prophet 为这些研究者们创造出了更大的研究空间,Prophet 作为基于外部知识图像问答任务的一个新的基线(baseline),还有许多值得挖掘的地方;
2. Prophet 不仅是 GPT-3 等 LLM 可以迁移到多种下游任务并取得优良性能的又一例证,更拓展了原本基于 few-shot in-context learning 的迁移范式,引出了一个新的范式,“小模型+LLM”。用任务相关的小模型作为 LLM 适配下游任务的适配器(Adapter),将增强 LLM 的通用性和针对性。我们相信 Prophet 的思路将启发其他领域的工作。
如果您对我们的工作有任何疑问,欢迎来信探讨,或者在 GitHub 上提交 issue。

参考文献
1. Kenneth Marino, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi. Ok-vqa: A visual question answering benchmark requiring external knowledge.
2. Zhengyuan Yang, Zhe Gan, Jianfeng Wang, Xiaowei Hu, Yumao Lu, Zicheng Liu, and Lijuan Wang. An empirical study of gpt-3 for few-shot knowledge-based vqa.
3. Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.
4. Dustin Schwenk, Apoorv Khandelwal, Christopher Clark, Kenneth Marino, and Roozbeh Mottaghi. A-okvqa: A benchmark for visual question answering using world knowledge.
5. Liangke Gui, Borui Wang, Qiuyuan Huang, Alex Haupt- mann, Yonatan Bisk, and Jianfeng Gao. Kat: A knowledge augmented transformer for vision-and-language.
6. Yuanze Lin, Yujia Xie, Dongdong Chen, Yichong Xu, Chenguang Zhu, and Lu Yuan. REVIVE: Regional visual representation matters in knowledge-based visual question answering.
7. Zhou Yu, Jun Yu, Yuhao Cui, Dacheng Tao, and Qi Tian. Deep modular co-attention networks for visual question answering.
8. Xi Chen, Xiao Wang, Soravit Changpinyo, A. J. Piergiovanni, Piotr Padlewski, Daniel Salz, Sebastian Goodman et al. Pali: A jointly-scaled multilingual language-image model.
9. Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid et al. PaLM-E: An Embodied Multimodal Language Model.
关于作者
论文第一作者邵镇炜是杭州电子科技大学计算机学院媒体智能实验室硕士研究生。邵镇炜同学患有“进行性脊肌萎缩症”,肢体一级残疾,没有生活自理能力,生活和学习需要母亲的全程照顾。2017年高考考入杭州电子科技大学计科专业,本科期间获得2018年中国大学生自强之星、国家奖学金和浙江省优秀毕业生等荣誉。2021年通过研究生推免,加入余宙教授课题组攻读硕士研究生。
论文通讯作者为杭州电子科技大学计算机学院余宙教授。余宙教授是杭电计算机学院最年轻的教授,教育部“复杂系统建模与仿真”实验室副主任。长期从事多模态智能方向研究,曾带领研究团队多次获得国际视觉问答挑战赛VQA Challenge 的冠亚军。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·

![[算法前沿]--000-大模型LLaMA在docker环境搭建以及运行教程(含模型压缩)](https://img-blog.csdnimg.cn/img_convert/daa618dbd0d8b529afdfa84120b9bbea.gif)