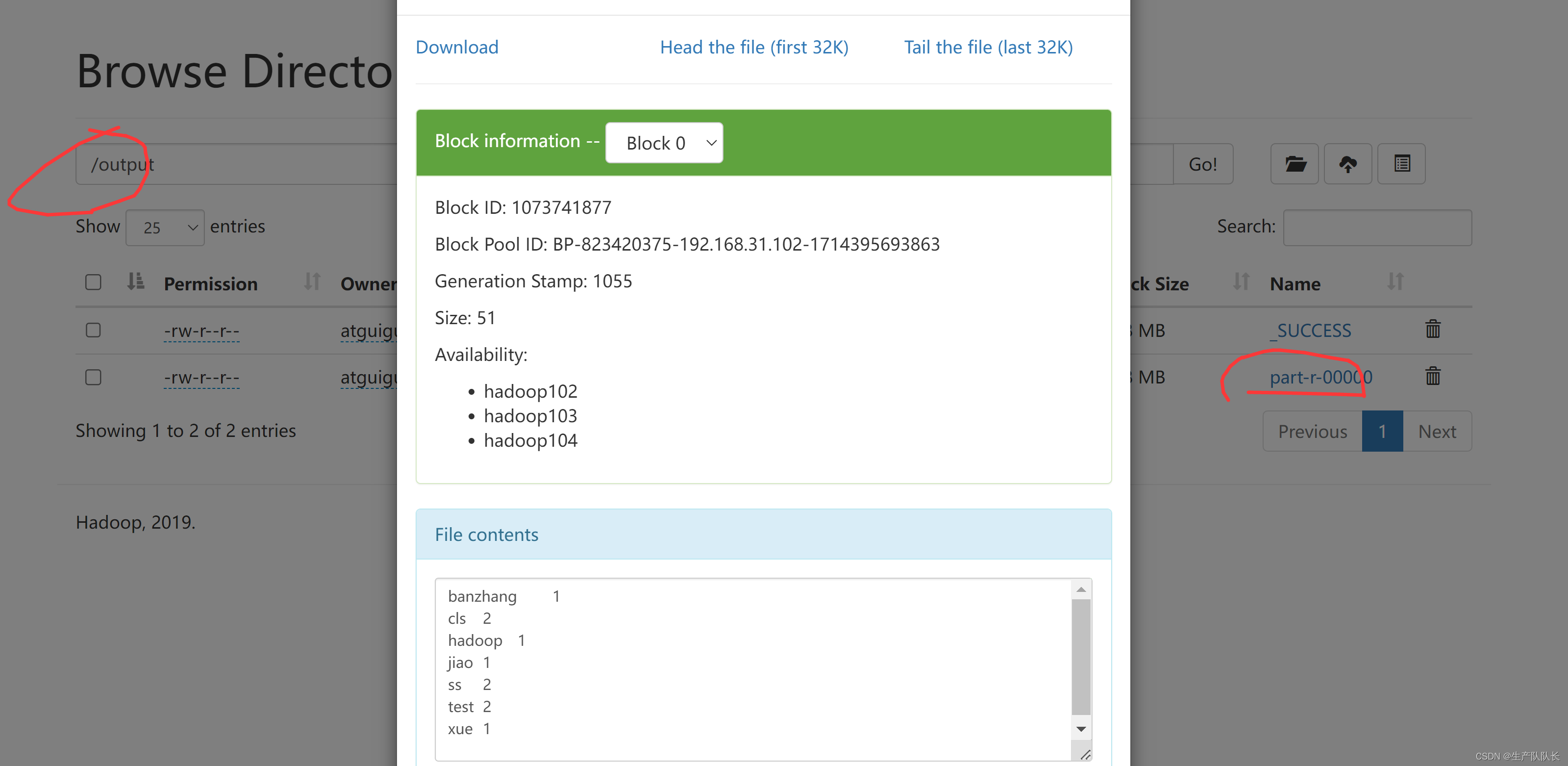
slam14讲(第9,10讲 后端)
- 后端分类
- 基于滤波器的后端
- 线性系统和卡尔曼滤波
- 非线性系统和扩展卡尔曼滤波
- BA优化
- H矩阵的稀疏性和边缘化
- H矩阵求解的总结
- 位姿图优化
- 公式推导
- 基于滑动窗口的后端
- 个人见解
- 旧关键帧的边缘化
后端分类
- 基于滤波器的后端。常见的扩展卡尔曼EKF,无迹卡尔曼UKF,粒子滤波PF,或者是fastlio2中使用的误差状态卡尔曼ESIKF(本质上迭代过程等效于高斯牛顿法,优化当前帧的状态)。还有许多其他滤波器,本质上是基于一阶马尔可夫性假设,就是认为当前的状态 x k x_k xk只与 x k − 1 x_{k-1} xk−1有关,与历史之前的状态无关,来简化卡尔曼滤波过程中预测更新的运算。
- 基于非线性优化的后端。这种方法就可以考虑第k帧之前所有历史帧的状态,类似一个全局的思维,通过构建全局状态的优化问题,来优化所有帧的状态(包括位姿和特征点),特别能够依靠回环检测来提高状态的全局一致性。
- 滑动窗口滤波和优化。
(1)滑动窗口滤波其实应该就是基于滤波器的后端的一个变种,认为一阶马尔可夫性假设太极端了,所以想选择一定数量的关键帧,共同考虑多个帧去解算出当前帧的状态。
(2)滑动窗口优化应该也是基于非线性优化的后端的一个变种,认为随着SLAM过程,关键帧增多,优化耗时会增加,所以想选择一些离当前时刻接近的关键帧而不是全部关键帧来一起优化
基于滤波器的后端
这里首先将状态的符号简化,状态包含相机位姿( x k x_k xk)和特征点( y m y_m ym)。
x k = def { x k , y 1 , … , y m } \boldsymbol{x}_k \stackrel{\text { def }}{=}\left\{\boldsymbol{x}_k, \boldsymbol{y}_1, \ldots, \boldsymbol{y}_m\right\} xk= def {xk,y1,…,ym}
那么经典的运动和观测方程就可以简化:(注意状态上的符号, x ^ \hat{\boldsymbol{x}} x^代表状态的后验, x ˇ \check{\boldsymbol{x}} xˇ代表状态的预测,这个定义是为了跟slam14讲ppt里一致)
{ x k = f ( x ^ k − 1 , u k ) + w k z k = h ( x k ) + v k k = 1 , … , N \left\{\begin{array}{l}\boldsymbol{x}_k=f\left(\hat{\boldsymbol{x}}_{k-1}, \boldsymbol{u}_k\right)+\boldsymbol{w}_k \\ \boldsymbol{z}_k=h\left(\boldsymbol{x}_k\right)+\boldsymbol{v}_k\end{array} \quad k=1, \ldots, N\right. {xk=f(x^k−1,uk)+wkzk=h(xk)+vkk=1,…,N
我们已知的是k-1时刻状态的后验 x ^ k − 1 \hat{x}_{k-1} x^k−1和输入 u k u_k uk,想求的是当前k时刻状态 x ^ k \hat{x}_{k} x^k的后验分布
P ( x ^ k ∣ x 0 , u 1 : k , z 1 : k ) P\left(\hat{\boldsymbol{x}}_k \mid \boldsymbol{x}_0, \boldsymbol{u}_{1: k}, \boldsymbol{z}_{1: k}\right) P(x^k∣x0,u1:k,z1:k)
根据贝叶斯法则,书上给出的式子是这样的:
P ( x ^ k ∣ x 0 , u 1 : k , z 1 : k ) ∝ P ( z k ∣ x ˇ k ) P ( x ˇ k ∣ x 0 , u 1 : k , z 1 : k − 1 ) P\left(\hat{\boldsymbol{x}}_k \mid \boldsymbol{x}_0, \boldsymbol{u}_{1: k}, \boldsymbol{z}_{1: k}\right) \propto P\left(\boldsymbol{z}_k \mid \check{\boldsymbol{x}}_k\right) P\left(\check{\boldsymbol{x}}_k \mid \boldsymbol{x}_0, \boldsymbol{u}_{1: k}, \boldsymbol{z}_{1: k-1}\right) P(x^k∣x0,u1:k,z1:k)∝P(zk∣xˇk)P(xˇk∣x0,u1:k,z1:k−1)
但是在我看来,假设了一阶马尔可夫性,直接都可以简化成最基本的贝叶斯滤波的形式。
P ( x ^ k ∣ x ^ k − 1 , u k , z k ) ∝ P ( z k ∣ x ˇ k ) P ( x ˇ k ∣ x ^ k − 1 , u k ) P\left(\hat{\boldsymbol{x}}_k \mid \hat{\boldsymbol{x}}_{k-1}, \boldsymbol{u}_{k}, \boldsymbol{z}_{k}\right) \propto P\left(\boldsymbol{z}_k \mid \check{\boldsymbol{x}}_k\right) P\left(\check{\boldsymbol{x}}_k \mid \hat{\boldsymbol{x}}_{k-1}, \boldsymbol{u}_{k}\right) P(x^k∣x^k−1,uk,zk)∝P(zk∣xˇk)P(xˇk∣x^k−1,uk)
很明显上面式子中左边的是当前k时刻状态 x ^ k \hat{x}_{k} x^k的后验分布,右边的第一项是似然分布,第二项是预测即先验分布。因为后验分布、似然分布和先验分布都属于高斯分布,所以就可以通过经典的卡尔曼滤波公式来求当前k时刻状态 x ^ k \hat{x}_{k} x^k的后验分布。
线性系统和卡尔曼滤波
如果考虑线性系统,那就是经典的卡尔曼滤波系统。运动方程和观测方程可以由下面的式子表示:
{ x k = A k x k − 1 + u k + w k z k = C k x k + v k k = 1 , … , N \left\{\begin{array}{l}\boldsymbol{x}_k=\boldsymbol{A}_k \boldsymbol{x}_{k-1}+\boldsymbol{u}_k+\boldsymbol{w}_k \\ \boldsymbol{z}_k=\boldsymbol{C}_k \boldsymbol{x}_k+\boldsymbol{v}_k\end{array} \quad k=1, \ldots, N\right. {xk=Akxk−1+uk+wkzk=Ckxk+vkk=1,…,N
其中过程噪声 w k ∼ N ( 0 , R ) \boldsymbol{w}_k \sim N(\mathbf{0}, \boldsymbol{R}) wk∼N(0,R) 和观测噪声 v k ∼ N ( 0 , Q ) \quad \boldsymbol{v}_k \sim N(\mathbf{0}, \boldsymbol{Q}) vk∼N(0,Q) 都服从高斯分布。然后就是根据卡尔曼滤波的5个步骤,求出后验估计 x ^ k \hat{x}_{k} x^k。
x ˇ k = A k x ^ k − 1 + u k (1) \check{\boldsymbol{x}}_k=\boldsymbol{A}_k \hat{\boldsymbol{x}}_{k-1}+\boldsymbol{u}_k \tag{1} xˇk=Akx^k−1+uk(1)
P ˇ k = A k P ^ k − 1 A k T + R (2) \quad \check{\boldsymbol{P}}_k=\boldsymbol{A}_k \hat{\boldsymbol{P}}_{k-1} \boldsymbol{A}_k^{\mathrm{T}}+\boldsymbol{R} \tag{2} Pˇk=AkP^k−1AkT+R(2)
K = P ˇ k C k T ( C k P ˇ k C k T + Q k ) − 1 (3) \boldsymbol{K}=\check{\boldsymbol{P}}_k \boldsymbol{C}_k^{\mathrm{T}}\left(\boldsymbol{C}_k \check{\boldsymbol{P}}_k \boldsymbol{C}_k^{\mathrm{T}}+\boldsymbol{Q}_k\right)^{-1} \tag{3} K=PˇkCkT(CkPˇkCkT+Qk)−1(3)
x ^ k = x ˇ k + K ( z k − C k x ˇ k ) (4) \hat{\boldsymbol{x}}_k=\check{\boldsymbol{x}}_k+\boldsymbol{K}\left(\boldsymbol{z}_k-\boldsymbol{C}_k \check{\boldsymbol{x}}_k\right) \tag{4} x^k=xˇk+K(zk−Ckxˇk)(4)
P ^ k = ( I − K C k ) P ˇ k (5) \hat{\boldsymbol{P}}_k=\left(\boldsymbol{I}-\boldsymbol{K} \boldsymbol{C}_k\right) \check{\boldsymbol{P}}_k \tag{5} P^k=(I−KCk)Pˇk(5)
于是这就得到了后验 x ^ k \hat{x}_{k} x^k的均值和协方差,用于k+1时刻的预测。
非线性系统和扩展卡尔曼滤波
本质上是在卡尔曼滤波基础上对运动方程和观测方程进行线性化(一阶泰勒展开),在此基础上也是经过5个公式推出 x k x_k xk的后验分布。这里就不展开了,公式都是大同小异。
BA优化
主要就是通过Bundle Adjustment(BA),来构建最小二乘问题,通过非线性优化的方法优化相机位姿和特征点的位置。
下面这个图就很好描述了相机的观测方程:
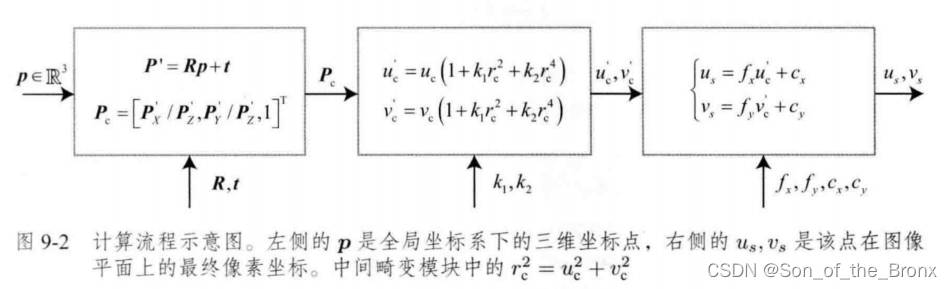
然后就是根据其他时刻的相机与特征点,构建出全局的重投影误差
1 2 ∑ i = 1 m ∑ j = 1 n ∥ e i j ∥ 2 = 1 2 ∑ i = 1 m ∑ j = 1 n ∥ z i j − h ( T i , p j ) ∥ 2 \frac{1}{2} \sum_{i=1}^m \sum_{j=1}^n\left\|\boldsymbol{e}_{i j}\right\|^2=\frac{1}{2} \sum_{i=1}^m \sum_{j=1}^n\left\|\boldsymbol{z}_{i j}-h\left(\boldsymbol{T}_i, \boldsymbol{p}_j\right)\right\|^2 21i=1∑mj=1∑n∥eij∥2=21i=1∑mj=1∑n zij−h(Ti,pj) 2
其中i是相机位姿的序号,j就是相机位姿i看到的特征点。
为了优化这个目标函数,需要求目标函数对相机位姿和特征点的雅可比,然后通过高斯牛顿来优化相机位姿和特征点:
1 2 ∥ f ( x + Δ x ) ∥ 2 ≈ 1 2 ∑ i = 1 m ∑ j = 1 n ∥ e i j + F i j Δ ξ i + E i j Δ p j ∥ 2 \frac{1}{2}\|f(\boldsymbol{x}+\Delta \boldsymbol{x})\|^2 \approx \frac{1}{2} \sum_{i=1}^m \sum_{j=1}^n\left\|\boldsymbol{e}_{i j}+\boldsymbol{F}_{i j} \Delta \boldsymbol{\xi}_i+\boldsymbol{E}_{i j} \Delta \boldsymbol{p}_j\right\|^2 21∥f(x+Δx)∥2≈21i=1∑mj=1∑n eij+FijΔξi+EijΔpj 2
其中状态x定义成所有待优化的变量:
x = [ T 1 , … , T m , p 1 , … , p n ] T \boldsymbol{x}=\left[\boldsymbol{T}_1, \ldots, \boldsymbol{T}_m, \boldsymbol{p}_1, \ldots, \boldsymbol{p}_n\right]^{\mathrm{T}} x=[T1,…,Tm,p1,…,pn]T
F i j \boldsymbol{F}_{i j} Fij和 E i j \boldsymbol{E}_{i j} Eij分别是误差对相机位姿和特征点的偏导。
最后的优化问题也可以简化成:
1 2 ∥ f ( x + Δ x ) ∥ 2 = 1 2 ∥ e + F Δ x c + E Δ x p ∥ 2 \frac{1}{2}\|f(\boldsymbol{x}+\Delta \boldsymbol{x})\|^2=\frac{1}{2}\left\|\boldsymbol{e}+\boldsymbol{F} \Delta \boldsymbol{x}_c+\boldsymbol{E} \Delta \boldsymbol{x}_p\right\|^2 21∥f(x+Δx)∥2=21∥e+FΔxc+EΔxp∥2
最后根据高斯牛顿法,都是需要求解一个增量方程
H Δ x = g \boldsymbol{H} \Delta \boldsymbol{x}=\boldsymbol{g} HΔx=g
对于高斯牛顿法,H矩阵就是
H = J T J = [ F T F F T E E T F E T E ] \boldsymbol{H}=\boldsymbol{J}^{\mathrm{T}} \boldsymbol{J}=\left[\begin{array}{ll}\boldsymbol{F}^{\mathrm{T}} \boldsymbol{F} & \boldsymbol{F}^{\mathrm{T}} \boldsymbol{E} \\ \boldsymbol{E}^{\mathrm{T}} \boldsymbol{F} & \boldsymbol{E}^{\mathrm{T}} \boldsymbol{E}\end{array}\right] H=JTJ=[FTFETFFTEETE]
实际上这个H矩阵由于特征点的个数往往很多,所以H矩阵规模很大,直接求逆会很耗时,但是H矩阵是有一定的结构,利用这个结构可以加速优化过程。
H矩阵的稀疏性和边缘化
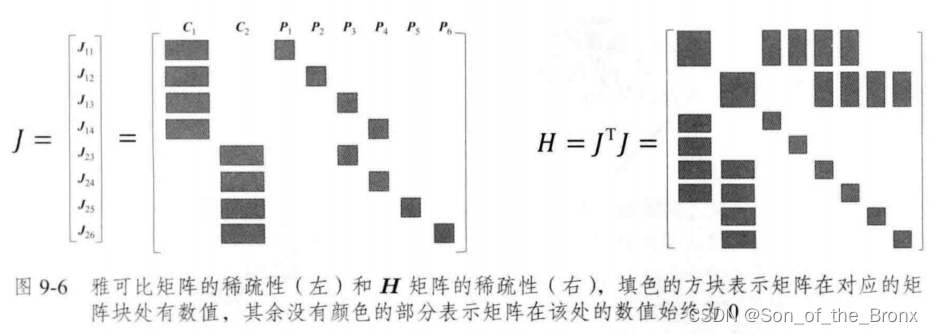
首先这里书本举一个例子说明:
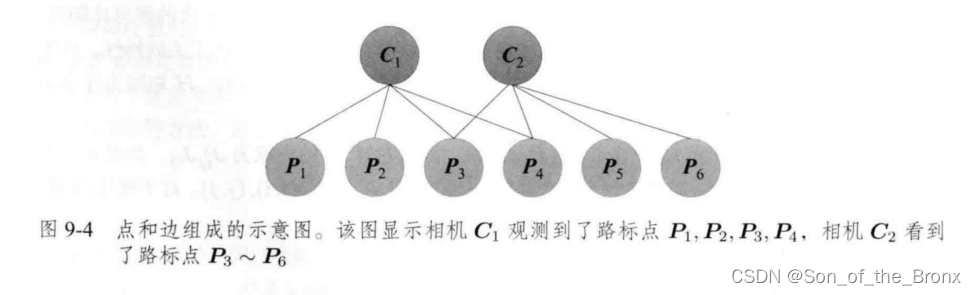
其中图中有 C 1 C_1 C1和 C 2 C_2 C2两个相机位姿和六个特征点,连线代表有观测关系。
这时全局重投影的目标函数为
1 2 ( ∥ e 11 ∥ 2 + ∥ e 12 ∥ 2 + ∥ e 13 ∥ 2 + ∥ e 14 ∥ 2 + ∥ e 23 ∥ 2 + ∥ e 24 ∥ 2 + ∥ e 25 ∥ 2 + ∥ e 26 ∥ 2 ) \frac{1}{2}\left(\left\|\boldsymbol{e}_{11}\right\|^2+\left\|\boldsymbol{e}_{12}\right\|^2+\left\|\boldsymbol{e}_{13}\right\|^2+\left\|\boldsymbol{e}_{14}\right\|^2+\left\|\boldsymbol{e}_{23}\right\|^2+\left\|\boldsymbol{e}_{24}\right\|^2+\left\|\boldsymbol{e}_{25}\right\|^2+\left\|\boldsymbol{e}_{26}\right\|^2\right) 21(∥e11∥2+∥e12∥2+∥e13∥2+∥e14∥2+∥e23∥2+∥e24∥2+∥e25∥2+∥e26∥2)
首先以 e 11 e_{11} e11对状态x求偏导,可以得到下面的雅可比
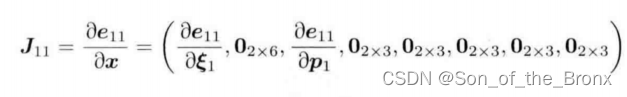
同理其他误差的雅可比都会有这种形式: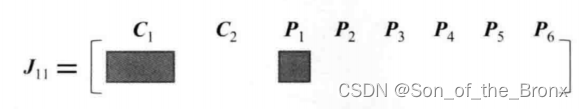
整体的雅可比J和H矩阵就会如同下图所示
然后对H矩阵进行下图的划分:
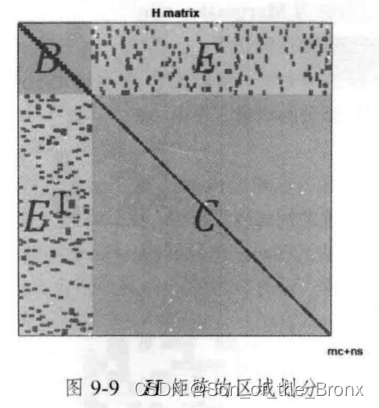
增量方程也可以按照划分,变成下面的形式
[ B E E T C ] [ Δ x c Δ x p ] = [ v w ] \left[\begin{array}{ll}\boldsymbol{B} & \boldsymbol{E} \\ \boldsymbol{E}^{\mathrm{T}} & \boldsymbol{C}\end{array}\right]\left[\begin{array}{l}\Delta \boldsymbol{x}_{\mathrm{c}} \\ \Delta \boldsymbol{x}_p\end{array}\right]=\left[\begin{array}{l}\boldsymbol{v} \\ \boldsymbol{w}\end{array}\right] [BETEC][ΔxcΔxp]=[vw]
对这个线性方程组的求解可以通过边缘化(可通过schur消元进行边缘化,也就是书中的方法。当然也有其他方法进行边缘化,本质都是加快增量方程的求解速度)。边缘化的过程如下:
[ I − E C − 1 0 I ] [ B E E T C ] [ Δ x c Δ x p ] = [ I − E C − 1 0 I ] [ v w ] \left[\begin{array}{cc}\boldsymbol{I} & -\boldsymbol{E} \boldsymbol{C}^{-1} \\ 0 & \boldsymbol{I}\end{array}\right]\left[\begin{array}{cc}\boldsymbol{B} & \boldsymbol{E} \\ \boldsymbol{E}^{\mathrm{T}} & \boldsymbol{C}\end{array}\right]\left[\begin{array}{c}\Delta \boldsymbol{x}_{\mathrm{c}} \\ \Delta \boldsymbol{x}_p\end{array}\right]=\left[\begin{array}{cc}\boldsymbol{I} & -\boldsymbol{E} \boldsymbol{C}^{-1} \\ 0 & \boldsymbol{I}\end{array}\right]\left[\begin{array}{c}\boldsymbol{v} \\ \boldsymbol{w}\end{array}\right] [I0−EC−1I][BETEC][ΔxcΔxp]=[I0−EC−1I][vw]
最终整理得到:
[ B − E C − 1 E T 0 E T C ] [ Δ x c Δ x p ] = [ v − E C − 1 w w ] \left[\begin{array}{cc}\boldsymbol{B}-\boldsymbol{E} \boldsymbol{C}^{-1} \boldsymbol{E}^{\mathrm{T}} & 0 \\ \boldsymbol{E}^{\mathrm{T}} & \boldsymbol{C}\end{array}\right]\left[\begin{array}{l}\Delta \boldsymbol{x}_{\mathrm{c}} \\ \Delta \boldsymbol{x}_p\end{array}\right]=\left[\begin{array}{c}\boldsymbol{v}-\boldsymbol{E} \boldsymbol{C}^{-1} \boldsymbol{w} \\ \boldsymbol{w}\end{array}\right] [B−EC−1ETET0C][ΔxcΔxp]=[v−EC−1ww]
因为右上角为0,就可以先把 Δ x c \Delta \boldsymbol{x}_{\mathrm{c}} Δxc计算出来,因为c是对角块矩阵,所以它的求逆相对简单。将求出 Δ x c \Delta \boldsymbol{x}_{\mathrm{c}} Δxc后再带入原方程就可以解出 Δ x p \Delta \boldsymbol{x}_{\mathrm{p}} Δxp。
H矩阵求解的总结
这个边缘化的概念是从概率论的角度来看的。实际上这个求解步骤就是固定 Δ x p \Delta \boldsymbol{x}_{\mathrm{p}} Δxp,然后求解 Δ x c \Delta \boldsymbol{x}_{\mathrm{c}} Δxc,最后再算出 Δ x p \Delta \boldsymbol{x}_{\mathrm{p}} Δxp。从概率公式上:
P ( x c , x p ) = P ( x c ∣ x p ) P ( x p ) P\left(\boldsymbol{x}_{\mathrm{c}}, \boldsymbol{x}_p\right)=P\left(\boldsymbol{x}_{\mathrm{c}} \mid \boldsymbol{x}_p\right) P\left(\boldsymbol{x}_p\right) P(xc,xp)=P(xc∣xp)P(xp)
最终是求得了 x c \boldsymbol{x}_\mathrm{c} xc的条件概率分布,和 x p \boldsymbol{x}_\mathrm{p} xp的边缘分布,所以称边缘化。在消元的时候实际上是将特征点的部分信息融入了求解 x c \boldsymbol{x}_\mathrm{c} xc的过程,所以 x c \boldsymbol{x}_\mathrm{c} xc是条件概率分布。
需要注意的是,这个边缘化在滑动窗口的方法中也有所应用。
位姿图优化
位姿图优化在视觉SLAM中可以看成是BA优化的简化版。因为BA优化需要将特征点考虑进去,优化的变量包括相机位姿和特征点的位置,大部分是放在特征点优化上了,所以位姿图的意义在于构建一个只有轨迹的图优化问题,特征点看成是一帧相机位姿中确定的点,不再去优化特征点的位置,省去了大量特征点优化的计算。
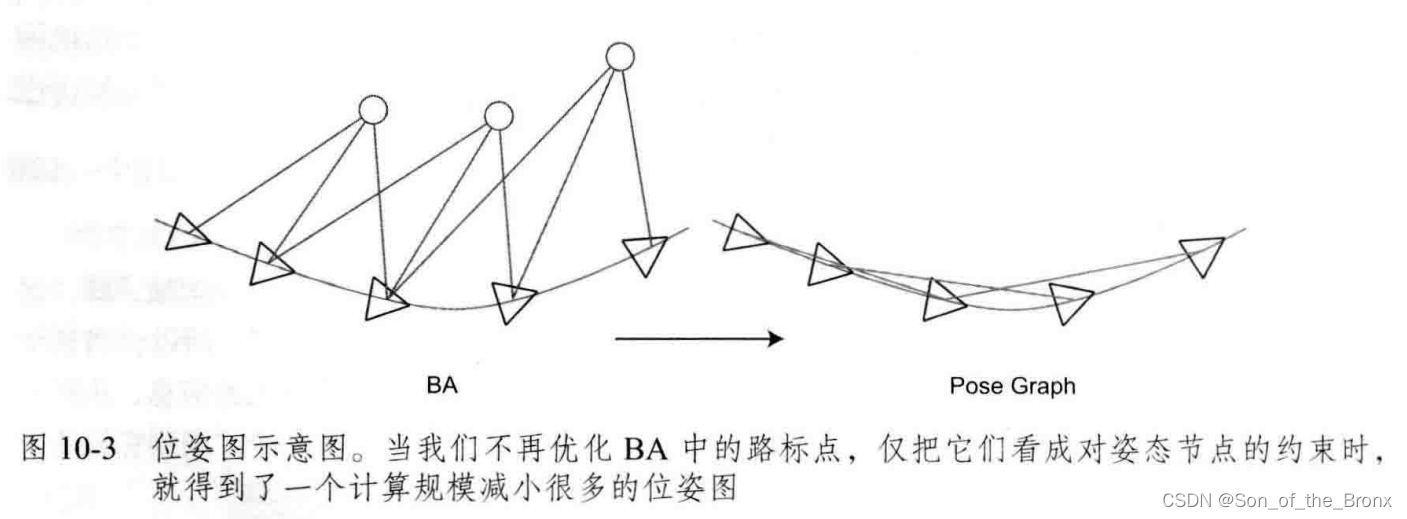
公式推导
假设通过IMU积分或者视觉slam估计了 T i T_i Ti和 T j T_j Tj之间的一个运动 Δ T i j \Delta \boldsymbol{T}_{i j} ΔTij,然后取他们李群之间的差值对应的李代数为误差:
e i j = Δ ξ i j = ln ( T i j − 1 T i − 1 T j ) ∨ \boldsymbol{e}_{i j}=\Delta \boldsymbol{\xi}_{i j} = \ln \left(\boldsymbol{T}_{i j}^{-1} \boldsymbol{T}_i^{-1} \boldsymbol{T}_j\right)^{\vee} eij=Δξij=ln(Tij−1Ti−1Tj)∨
紧接着就是经典的对 T i T_i Ti和 T j T_j Tj加左扰动对扰动求导
e ^ i j = ln ( T i j − 1 T i − 1 exp ( ( − δ ξ i ) ∧ ) exp ( δ ξ j ∧ ) T j ) ∨ \hat{\boldsymbol{e}}_{i j}=\ln \left(\boldsymbol{T}_{i j}^{-1} \boldsymbol{T}_i^{-1} \exp \left(\left(-\boldsymbol{\delta} \boldsymbol{\xi}_i\right)^{\wedge}\right) \exp \left(\delta \boldsymbol{\xi}_j^{\wedge}\right) \boldsymbol{T}_j\right)^{\vee} e^ij=ln(Tij−1Ti−1exp((−δξi)∧)exp(δξj∧)Tj)∨
因为上式扰动项被夹在中间,所以可以通过下面的伴随性质:
exp ( ξ ∧ ) T = T exp ( ( Ad ( T − 1 ) ξ ) ∧ ) \exp \left(\boldsymbol{\xi}^{\wedge}\right) \boldsymbol{T}=\boldsymbol{T} \exp \left(\left(\operatorname{Ad}\left(\boldsymbol{T}^{-1}\right) \boldsymbol{\xi}\right)^{\wedge}\right) exp(ξ∧)T=Texp((Ad(T−1)ξ)∧)
将扰动挪到最右边,最终得到下面的式子:
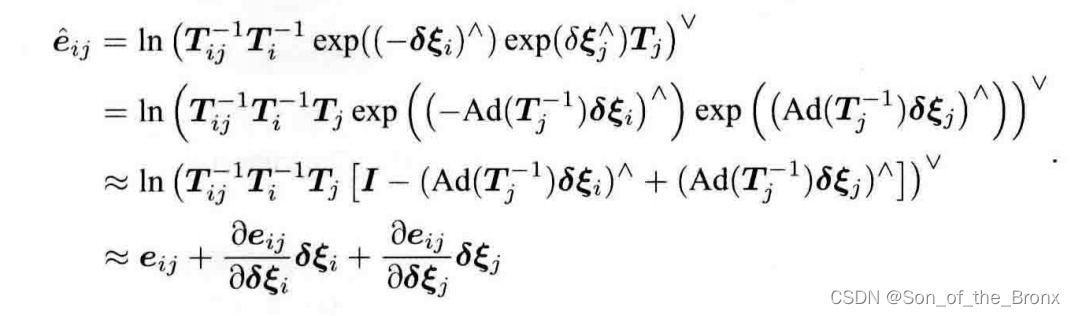
其实对于这个式子我不是很能理解从第三个式子到第四个式子的转变,经过与其他人的交流,得知还需要借助ln(1+x)的泰勒展开结合se(3)的BCH近似来化简,下面就是自己手写的推导过程(从第三个式子开始推导):

对于一开始的公式,我想的是直接从第二个式子展开,忽略了se(3)的BCH近似,结果雅可比跟书上那个是类似的,只不过书上多了一个可以忽略的 J r J_r Jr:
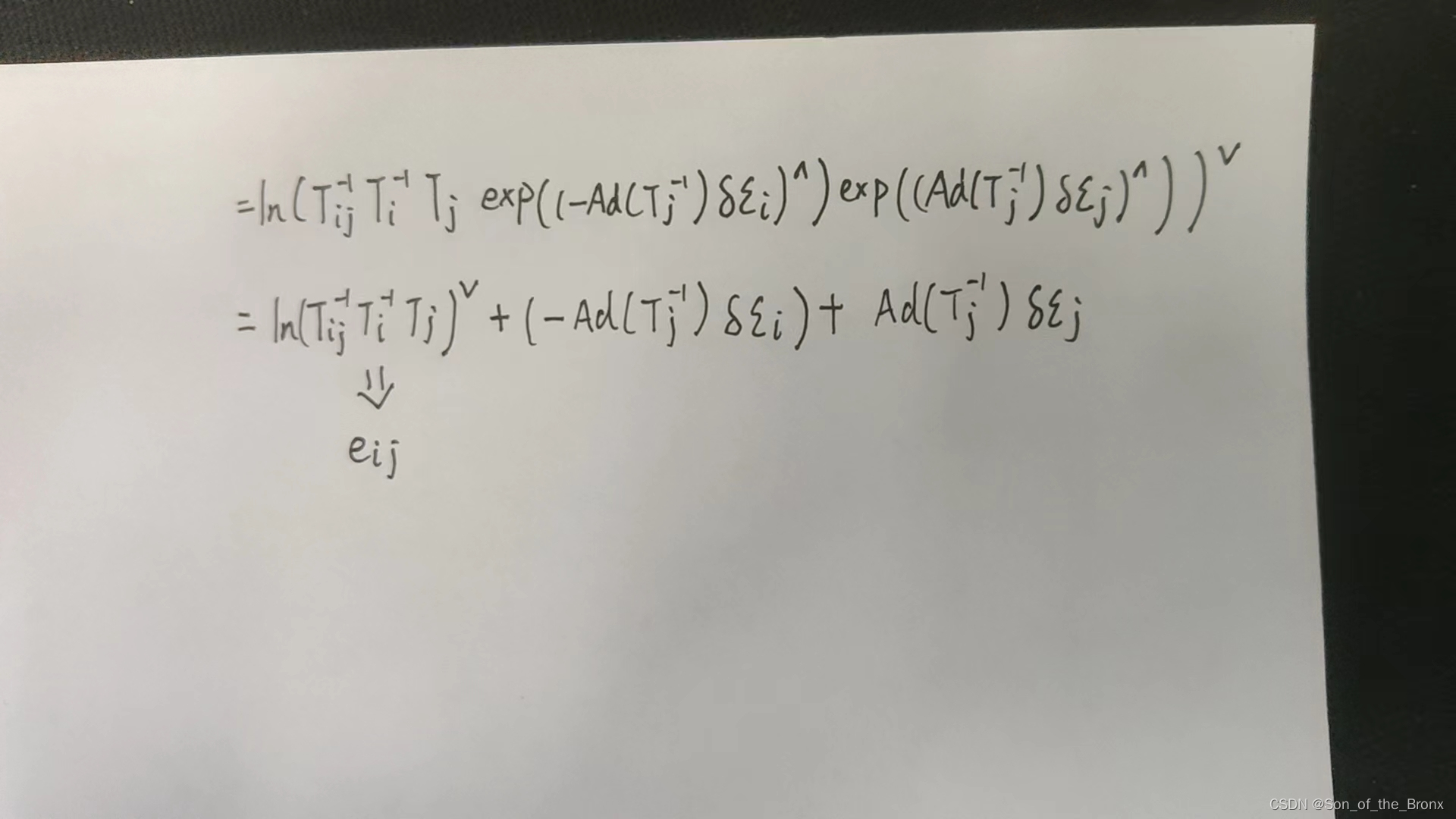
后续的过程就是根据雅可比去求增量方程,求解增量方程优化相机位姿,高斯牛顿的剧情又来了。
基于滑动窗口的后端
这里只考虑滑动窗口BA优化,因为书上对滑动窗口这部分介绍的东西比较少。
个人见解
为什么会想用滑动窗口的方式?就是因为在slam的过程中,图像来了就算一帧,一帧需要优化一个相机位姿和几百个特征点。时间一长,特征点数量就飞速增长,虽然可以采用关键帧的策略,但是关键帧的数量也是会随着slam的过程逐渐增多。所以就产生控制BA规模的想法,最简单的方法就是仅仅保存离当前帧时间最近的N个关键帧,依靠这些关键帧做BA优化。在新增关键帧和关键点的时候是比较好操作的,但是在删除一个旧的关键帧时,就需要边缘化的操作。
旧关键帧的边缘化
具体其实可以参考一篇博客,写的非常清晰:边缘化中矩阵运算的一点细节
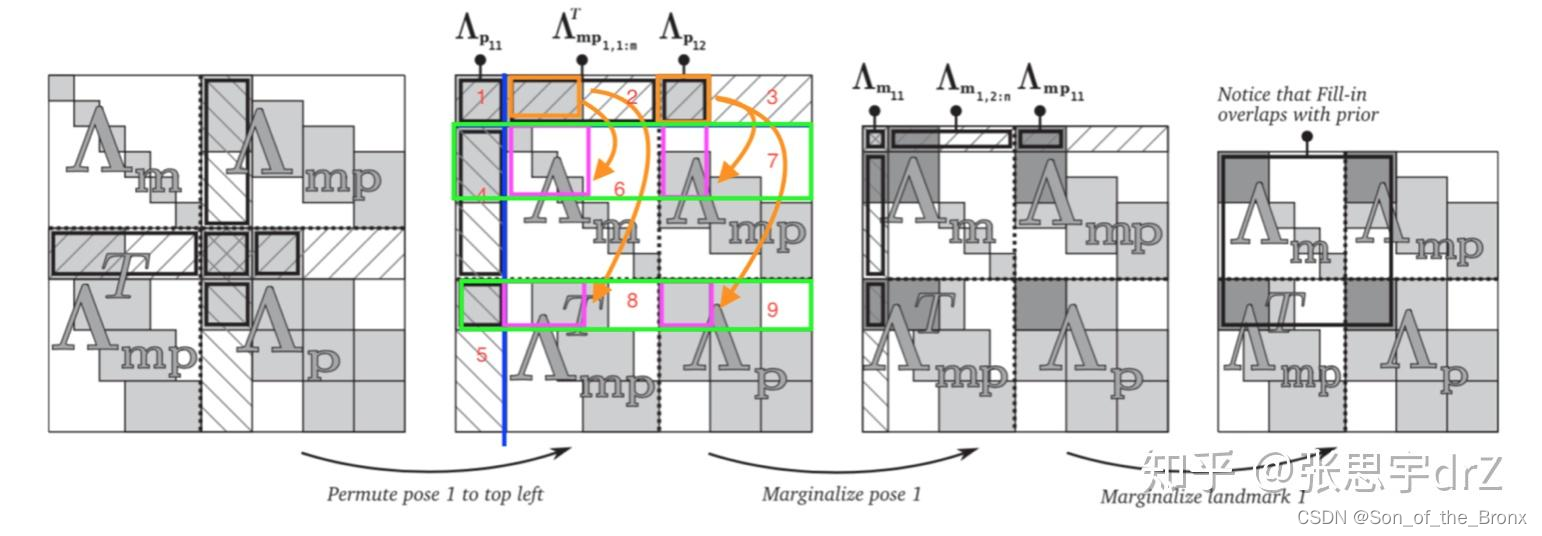
边缘化的过程可以简要的由上面的图片来表示。这个就是整个滑动窗口的BA优化中H矩阵, A m A_m Am代表的是特征点的部分, A p A_p Ap代表相机位姿的部分。先边缘化相机位姿,这时候有关这个相机位姿的信息就会在schur消元的过程中 Fill-in A m A_m Am中,然后就是边缘化这个相机位姿的特征点,也是通过schur消元中 Fill-in A m A_m Am中,但是Fill-in的范围是一致的,不会有新的空白区域被 Fill-in ,最终就可以得到边缘化后的H矩阵。
其实看到最后的H矩阵, A m A_m Am没法保证自身是对角块矩阵,所以在后续优化求解的时候,就无法通过之前稀疏方式去迭代求解了。这个问题应该也会有一些SLAM框架去解决,采取其他边缘化策略保证 A m A_m Am对角块矩阵的特性。